Zero-Gated Language-conditioned Human Motion Prediction
Pith reviewed 2026-06-30 07:44 UTC · model grok-4.3
The pith
Zero-gated adapters let one-sentence captions from observed poses improve 3D human motion forecasts while leaving the baseline unchanged at initialization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
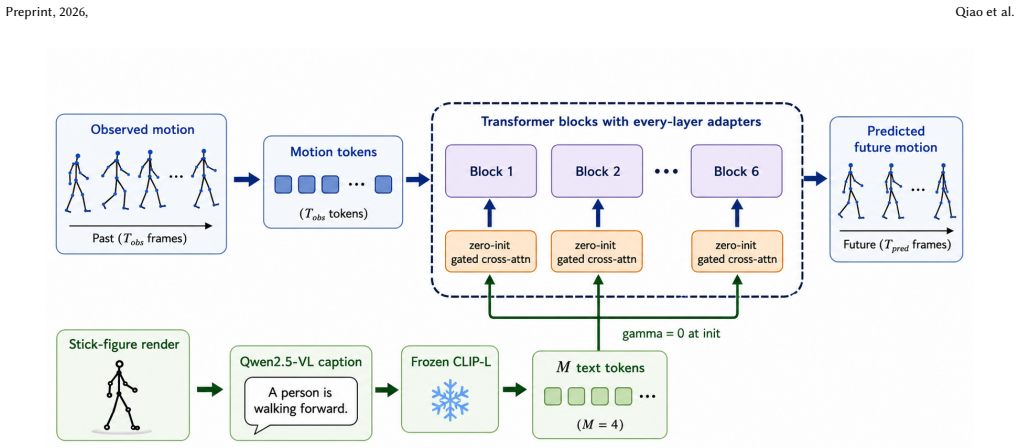
ZGL renders only the observed poses, generates a one-sentence description with a vision-language model, encodes the caption with a frozen CLIP-L text tower, projects it into a small set of conditioning tokens, and injects those tokens into a DCT-based spatial-temporal Transformer by compact cross-attention adapters equipped with zero gates; each adapter output is multiplied by a learnable gate initialized to zero so the full network is numerically identical to the pose-only baseline at initialization and can learn to use language only when it reduces prediction error. On Human3.6M this yields lower overall MPJPE than representative motion-prediction baselines; results on CMUMocap further sho
What carries the argument
Zero-gated cross-attention adapters: compact modules whose outputs are scaled by learnable gates initialized at zero, allowing the language tokens to be added without altering the initial behavior of the underlying DCT-based Transformer.
If this is right
- The model can learn to keep the gates near zero when language adds no value, preserving baseline performance.
- Compact one-sentence captions generated from rendered poses provide a usable semantic prior for 3D human motion prediction.
- The same conditioning approach transfers from Human3.6M to CMUMocap without retraining the caption pipeline.
- Freezing the CLIP text tower keeps the added parameters small while still supplying useful conditioning tokens.
Where Pith is reading between the lines
- The zero-gate pattern could be reused to test other external signals (depth maps, object labels) without risking degradation of the motion backbone.
- If the vision-language model produces inconsistent captions across similar poses, the gates are expected to remain low, automatically down-weighting unreliable language.
- Because only observed poses are rendered, the method avoids any need for future-pose information at test time.
Load-bearing premise
The one-sentence captions generated by the vision-language model from rendered observed poses supply accurate, non-redundant semantic information that is not already implicit in the pose history.
What would settle it
Replace the generated captions with blank strings or random text during both training and evaluation and check whether the reported MPJPE improvement on Human3.6M disappears.
Figures
read the original abstract
Pose histories provide the core kinematic evidence for 3D human motion prediction, but they lack explicit high-level semantic guidance. This paper introduces ZGL, a lightweight language-conditioned predictor that uses captions of the observed motion as a semantic prior while preserving a strong motion backbone as the main source of dynamics. We render only the observed poses, generate a one-sentence description with a vision-language model, encode the caption with a frozen CLIP-L text tower, and project it into a small set of conditioning tokens. These tokens are injected into a DCT-based spatial-temporal Transformer by compact crossattention adapters with zero gates: each adapter output is multiplied by a learnable gate initialized to zero, so the full network is numerically identical to the pose-only baseline at initialization and can learn to use language only when it reduces prediction error. On Human3.6M, ZGL improves overall MPJPE over representative motion-prediction baselines in our comparison. Results on CMUMocap further show that compact caption conditioning transfers to a second benchmark and provides a practical semantic cue for 3D human motion prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ZGL, a lightweight language-conditioned 3D human motion predictor. Observed poses are rendered and captioned by a vision-language model; the one-sentence caption is encoded by a frozen CLIP-L text tower and projected to a small set of tokens. These tokens are injected into a DCT-based spatial-temporal Transformer via compact cross-attention adapters whose outputs are scaled by a learnable gate initialized to zero, making the network numerically identical to the pose-only baseline at the start of training. The central empirical claim is that ZGL improves overall MPJPE on Human3.6M relative to representative motion-prediction baselines and that the same compact conditioning transfers to CMUMocap.
Significance. If the reported gains hold under standard evaluation protocols, the zero-gate construction supplies a clean existence result for a minimal, selectively activated language prior that does not risk degrading a strong motion backbone. The design is notable for its parameter efficiency (only a learnable gate scalar) and for demonstrating that caption-derived semantics can supply non-redundant cues on two benchmarks without requiring architectural overhaul of the Transformer.
minor comments (3)
- [Abstract] Abstract: the claim of MPJPE improvement is stated without any numerical values, relative gains, or reference to the specific table or figure that supports it; adding at least the headline numbers would make the contribution immediately verifiable.
- [§3] §3 (Method): the precise dimensionality of the projected conditioning tokens, the projection matrix, and the number of cross-attention layers that receive the adapters should be stated explicitly so that the added parameter count can be reproduced.
- [§4] §4 (Experiments): while the zero-gate initialization is a strength, the text should confirm that all reported runs use the same random seed or report standard deviation across multiple seeds to establish that the observed improvement is stable.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report raises no specific major comments to address.
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical method that augments an existing DCT-based spatial-temporal Transformer with compact zero-gated cross-attention adapters for caption conditioning. The zero-gate initialization is explicitly stated to make the network numerically identical to the pose-only baseline at start, so any reported MPJPE improvement on Human3.6M and CMUMocap is an experimental outcome rather than a quantity defined by construction from the same data or a self-citation chain. No equations, uniqueness theorems, ansatzes, or fitted-input predictions are described that reduce the central claim to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable gate scalar
Reference graph
Works this paper leans on
- [1]
-
[2]
Emre Aksan, Manuel Kaufmann, and Otmar Hilliges. 2021. A Spatio-Temporal Transformer for 3D Human Motion Prediction. In3DV. 565–574
2021
-
[3]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, et al. 2022. Flamingo: A Visual Language Model for Few-Shot Learning. InNeurIPS
2022
- [4]
-
[5]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[6]
BGE-M3: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation.arXiv:2402.03216(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhong- dao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. 2024. PixArt-𝛼: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthe- sis. InICLR
2024
-
[8]
Lingwei Dang, Yongwei Nie, Chengjiang Long, Qing Zhang, and Guiqing Li
-
[9]
MSR-GCN: Multi-Scale Residual Graph Convolution Networks for Human Motion Prediction. InICCV
-
[10]
Yuming Du, Zhen Wang, Yi Li, Xue Yang, Chao Wu, and Zhi Wang. 2024. Fore- casting Distillation: Enhancing 3D Human Motion Prediction with Guidance Regularization. InIJCNN
2024
-
[11]
Katerina Fragkiadaki, Sergey Levine, Panna Felsen, and Jitendra Malik. 2015. Re- current Network Models for Human Dynamics. InICCV. 4346–4354
2015
-
[12]
Jing Fu, Fuxing Yang, Yongwei Dang, Xianjing Liu, and Junjun Yin. 2023. Learn- ing Constrained Dynamic Correlations in Spatiotemporal Graphs for Motion Prediction.IEEE Transactions on Neural Networks and Learning Systems(2023)
2023
- [13]
-
[14]
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng
-
[15]
MoMask: Generative Masked Modeling of 3D Human Motions. InCVPR
-
[16]
Wen Guo, Yuming Du, Xi Shen, Vincent Lepetit, Xavier Alameda-Pineda, and Francesc Moreno-Noguer. 2023. Back to MLP: A Simple Baseline for Human Motion Prediction. InW ACV
2023
-
[17]
Jonathan Ho and Tim Salimans. 2022. Classifier-Free Diffusion Guidance. arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Seokhyeon Hong, Chaelin Kim, Serin Yoon, Junghyun Nam, Sihun Cha, and Jun- yong Noh. 2025. SALAD: Skeleton-aware Latent Diffusion for Text-driven Mo- tion Generation and Editing. InCVPR
2025
- [19]
-
[20]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. 2014. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sens- ing in Natural Environments.IEEE TPAMI36, 7 (2014), 1325–1339
2014
-
[21]
Zamir, Silvio Savarese, and Ashutosh Saxena
Ashesh Jain, Amir R. Zamir, Silvio Savarese, and Ashutosh Saxena. 2016. Structural-RNN: Deep Learning on Spatio-Temporal Graphs. InCVPR. 5308– 5317
2016
-
[22]
Jihoon Kim, Jiseob Kim, and Sungjoon Choi. 2023. FLAME: Free-form Language- based Motion Synthesis & Editing. InAAAI
2023
-
[23]
Maosen Li, Siheng Chen, Ya Zhang, and Qi Tian. 2022. Skeleton-Parted Graph Scattering Networks for 3D Human Motion Prediction. InECCV. 18–36
2022
-
[24]
Maosen Li, Siheng Chen, Yangheng Zhao, Ya Zhang, Yanfeng Wang, and Qi Tian
-
[25]
Dynamic Multiscale Graph Neural Networks for 3D Skeleton Based Hu- man Motion Prediction. InCVPR
- [26]
- [27]
- [28]
-
[29]
Tian Ma, Yongwei Nie, Chengjiang Long, Qing Zhang, and Guiqing Li. 2022. Progressively Generating Better Initial Guesses Towards Next Stages for High- Quality Human Motion Prediction. InCVPR
2022
-
[30]
Wei Mao, Miaomiao Liu, and Mathieu Salzmann. 2020. History Repeats Itself: Human Motion Prediction via Motion Attention. InECCV. 474–489
2020
-
[31]
Wei Mao, Miaomiao Liu, Mathieu Salzmann, and Hongdong Li. 2019. Learning Trajectory Dependencies for Human Motion Prediction. InICCV
2019
-
[32]
Black, and Javier Romero
Julieta Martinez, Michael J. Black, and Javier Romero. 2017. On Human Motion Prediction Using Recurrent Neural Networks. InCVPR
2017
-
[33]
Oh, and Nicholas Heller
Eduardo Medina, Loh Loh, Nishan Gurung, Kyung H. Oh, and Nicholas Heller
- [34]
-
[35]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Trans- formers. InICCV
2023
-
[36]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Mod- els from Natural Language Supervision. InICML
2021
-
[37]
Theodoros Sofianos, Andrea Sampieri, Luca Franco, and Fabio Galasso. 2021. Space-Time-Separable Graph Convolutional Network for Pose Forecasting. In ICCV. 11209–11218
2021
-
[38]
Jie Tang, Jianrong Zhang, Rui Ding, Bin Gu, and Junjun Yin. 2023. Collaborative Multi-Dynamic Pattern Modeling for Human Motion Prediction.IEEE Transac- tions on Circuits and Systems for Video Technology33, 8 (2023), 3689–3700
2023
-
[39]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H. Bermano. 2023. Human Motion Diffusion Model. InICLR
2023
-
[40]
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. 2021. Going Deeper with Image Transformers. InICCV
2021
-
[41]
Jiahao Wang, Yiming Guo, and Bin Su. 2025. Spatio-Temporal Multi-Subgraph GCN for 3D Human Motion Prediction. InICASSP
2025
- [42]
-
[43]
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. 2024. Long-CLIP: Unlocking the Long-Text Capability of CLIP. InECCV
2024
-
[44]
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. 2023. T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations. InCVPR
2023
- [45]
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.