A Linear Matching Bandit Approach to Online Multi-Human Multi-Robot Teaming
Pith reviewed 2026-06-30 08:46 UTC · model grok-4.3
The pith
LinMatch recasts optimistic linear matching as a Hungarian-solvable LP and proves matching upper and lower regret bounds of order d sqrt(M K T).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
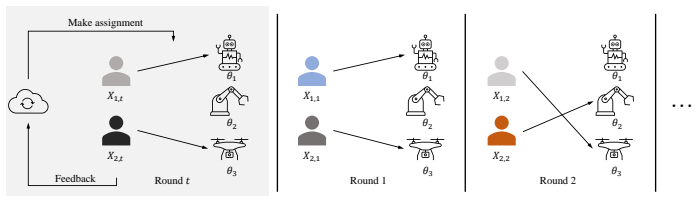
By updating linear confidence sets and solving the per-round optimistic assignment exactly via a maximum-weight matching linear program, LinMatch attains an upper regret bound of tilde O(d sqrt(M K T)) while a matching minimax lower bound of Omega(d sqrt(M K T)) shows that no algorithm can improve the dependence on T, d, M or K; the algorithm and bounds extend directly to any linear-feature matching setting.
What carries the argument
Optimistic matching recast as a maximum weighted matching linear program solved by the Hungarian algorithm, paired with per-feature confidence-interval updates.
If this is right
- The same regret rate holds for any matching problem whose rewards are linear in unknown feature vectors.
- The method applies unchanged to housing allocation, recommendation systems, and other bipartite assignment settings.
- Regret scales linearly with feature dimension d and with the square root of the product M K T.
- Each round's matching decision is obtained in polynomial time from the current confidence sets.
Where Pith is reading between the lines
- The approach could be tested on real human-robot data to check whether the linear feature assumption holds in practice.
- Extensions to dynamic pools of robots or humans would require only minor changes to the confidence-set construction.
- The same LP reduction may yield tight bounds for other combinatorial linear bandits whose feasible sets admit efficient optimization oracles.
Load-bearing premise
The optimistic per-round matching problem can always be expressed as a maximum-weight assignment linear program that the Hungarian algorithm solves exactly.
What would settle it
A concrete linear-feature instance in which any algorithm incurs regret omega(d sqrt(M K T)) or in which the optimistic matching LP solved by Hungarian fails to produce the claimed per-round decisions.
Figures
read the original abstract
We address the problem of online multi-human multi-robot teaming through the lens of a linear matching bandit framework, where a learner assigns robots with unknown features from a fixed pool to distinct sets of human agents over multiple rounds. To solve this problem, we propose LinMatch, an online learning algorithm that updates the confidence intervals of the unknown features and makes the optimistic matching under uncertainty. The contributions and novelty of this work are twofold. First, we recast the optimistic matching problem in each round as a linear program of maximum weighted matching, efficiently solvable by the celebrated Hungarian algorithm. Second, we provide novel bounds for matching with linear feature problems, showing an upper bound of $\tilde{O}(d\sqrt{MKT})$ and a minimax lower bound of $\Omega(d\sqrt{MKT})$, establishing a tight optimal regret rate of $\tilde{\Theta}(d\sqrt{MKT})$. This demonstrates that LinMatch achieves strictly optimal achievable regret with respect to the total number of rounds $T$, the feature dimension $d$, and the matching parameters $M$ and $K$. The proposed algorithm and bounds apply to a wide range of matching problems with applications beyond human-robot matching, such as housing allocation, recommendation systems, and more.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LinMatch, an algorithm for the linear matching bandit problem modeling online multi-human multi-robot teaming. Robots with unknown features are assigned to sets of human agents over T rounds. LinMatch updates confidence intervals and solves an optimistic matching each round by reducing it to a maximum weighted matching LP, claimed to be solvable by the Hungarian algorithm. The paper derives an upper regret bound of ilde{O}(d \sqrt{M K T}) and a minimax lower bound of \Omega(d \sqrt{M K T}), concluding that the algorithm achieves the optimal rate ilde{ heta}(d \sqrt{M K T}).
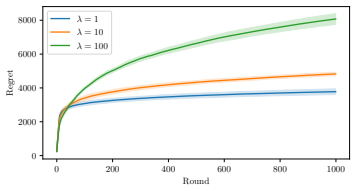
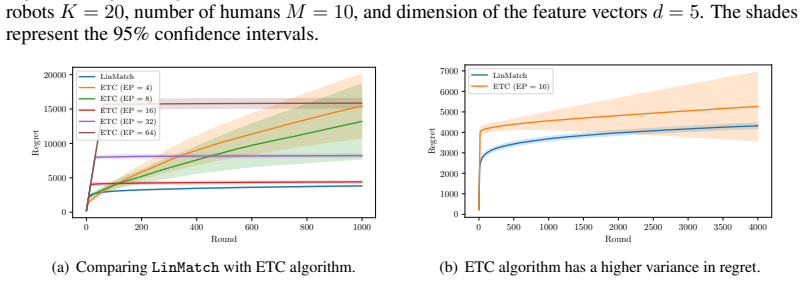
Significance. If the regret analysis is correct, the work makes a significant contribution by providing tight bounds for linear bandits with combinatorial matching actions. This extends the standard linear bandit regret of ilde O(d sqrt(T)) to account for matching parameters M and K without worsening the dependence, which is non-trivial. The practical reduction to an efficiently solvable LP is a strength, and the result applies to a range of matching problems beyond the motivating application. The matching upper and lower bounds constitute a clear strength.
minor comments (3)
- [Abstract] Abstract: The parameters M and K are referred to as 'matching parameters' without explicit definition; the introduction should clarify whether M denotes the number of humans and K the number of robots (or vice versa) and how they enter the action space size.
- [Abstract] Abstract: The upper bound is ilde{O}(d sqrt(MKT)) while the lower bound is Ω(d sqrt(MKT)); the paper should explicitly state the logarithmic factors hidden in the ilde{O} notation (and any dependence on M,K in the logs) to make the claimed tightness fully precise.
- The manuscript would benefit from a brief discussion of per-round computational complexity, as invoking the Hungarian algorithm (or its generalization) has cubic scaling in the larger of M and K, which may constrain applicability for large team sizes even if the regret bound holds.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on LinMatch and the recommendation for minor revision. We are pleased that the significance of the tight ilde{\Theta}(d \sqrt{MKT}) regret bounds for linear matching bandits is recognized, along with the efficient reduction to the Hungarian algorithm and the broad applicability beyond the motivating human-robot teaming setting.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents LinMatch with regret bounds derived via standard linear-bandit concentration and optimism arguments applied to a per-round maximum-weight matching LP (solvable by Hungarian algorithm). The abstract and context describe these as novel analysis results establishing tight ilde{\Theta}(d\sqrt{MKT}) rates, without any reduction to fitted parameters, self-definitional constructions, or load-bearing self-citations. The optimistic matching formulation follows directly from linear rewards and UCBs without circularity, and the bounds are not renamed known results or smuggled via prior author work. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Hungarian algorithm solves maximum weight matching linear programs in polynomial time
Reference graph
Works this paper leans on
-
[1]
International Conference on Artificial Intelligence and Statistics , pages=
Interactive Learning with Pricing for Optimal and Stable Allocations in Markets , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[2]
International conference on machine learning , pages=
Contextual combinatorial cascading bandits , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[3]
Initial Task Allocation for Multi-Human Multi-Robot Teams with Attention-Based Deep Reinforcement Learning , year=
Wang, Ruiqi and Zhao, Dezhong and Min, Byung-Cheol , booktitle=. Initial Task Allocation for Multi-Human Multi-Robot Teams with Attention-Based Deep Reinforcement Learning , year=
-
[4]
The International journal of robotics research , volume=
A formal analysis and taxonomy of task allocation in multi-robot systems , author=. The International journal of robotics research , volume=. 2004 , publisher=
2004
-
[5]
Jessie and Ghaffari, Maani and Barton, Kira , title = "
Fu, Bo and Kathuria, Tribhi and Rizzo, Denise and Castanier, Matthew and Yang, X. Jessie and Ghaffari, Maani and Barton, Kira , title = ". Journal of Autonomous Vehicles and Systems , volume =. 2022 , month =. doi:10.1115/1.4053428 , url =
-
[6]
IEEE Transactions on Control of Network Systems , volume=
Scalable operator allocation for multirobot assistance: A restless bandit approach , author=. IEEE Transactions on Control of Network Systems , volume=. 2022 , publisher=
2022
-
[7]
Proceedings of Robotics: Science and Systems , YEAR =
Tianchen Ji AND Roy Dong AND Katherine Driggs-Campbell , TITLE =. Proceedings of Robotics: Science and Systems , YEAR =
-
[8]
2023 31st Mediterranean Conference on Control and Automation (MED) , pages=
An optimal allocation and scheduling method in human-multi-robot precision agriculture settings , author=. 2023 31st Mediterranean Conference on Control and Automation (MED) , pages=. 2023 , organization=
2023
-
[9]
2014 , publisher=
Integer programming models , author=. 2014 , publisher=
2014
-
[10]
International Conference on Machine Learning , pages=
Neural contextual bandits with ucb-based exploration , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[11]
ACM Transactions on Human-Robot Interaction (THRI) , volume=
Coordinating human-robot teams with dynamic and stochastic task proficiencies , author=. ACM Transactions on Human-Robot Interaction (THRI) , volume=. 2021 , publisher=
2021
-
[12]
2015 AAAI Fall Symposium Series , year=
Coordination of human-robot teaming with human task preferences , author=. 2015 AAAI Fall Symposium Series , year=
2015
-
[13]
2008 International Symposium on Collaborative Technologies and Systems , pages=
Multiagent Adjustable Autonomy Framework (MAAF) for multi-robot, multi-human teams , author=. 2008 International Symposium on Collaborative Technologies and Systems , pages=. 2008 , organization=
2008
-
[14]
Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI) , pages=
A study of human-agent collaboration for multi-UAV task allocation in dynamic environments , author=. Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI) , pages=
-
[15]
Mathematics of Operations Research , volume=
Linearly parameterized bandits , author=. Mathematics of Operations Research , volume=. 2010 , publisher=
2010
-
[16]
ICML , pages=
Associative reinforcement learning using linear probabilistic concepts , author=. ICML , pages=. 1999 , organization=
1999
-
[17]
International Computing and Combinatorics Conference , pages=
Contextual dependent click bandit algorithm for web recommendation , author=. International Computing and Combinatorics Conference , pages=. 2018 , organization=
2018
-
[18]
International Conference on Machine Learning , pages=
DCM bandits: Learning to rank with multiple clicks , author=. International Conference on Machine Learning , pages=. 2016 , organization=
2016
-
[19]
International conference on machine learning , pages=
Cascading bandits: Learning to rank in the cascade model , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[20]
Journal of Machine Learning Research , volume=
Using confidence bounds for exploitation-exploration trade-offs , author=. Journal of Machine Learning Research , volume=
-
[21]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages=
Contextual bandits with linear payoff functions , author=. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics , pages=. 2011 , organization=
2011
-
[22]
SIAM journal on computing , volume=
The nonstochastic multiarmed bandit problem , author=. SIAM journal on computing , volume=. 2002 , publisher=
2002
-
[23]
Proceedings of the fourth ACM international conference on Web search and data mining , pages=
Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms , author=. Proceedings of the fourth ACM international conference on Web search and data mining , pages=
-
[24]
Advances in Neural Information Processing Systems , volume=
Learning equilibria in matching markets from bandit feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
International Conference on Artificial Intelligence and Statistics , pages=
Regret, stability & fairness in matching markets with bandit learners , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
2022
-
[26]
The American Mathematical Monthly , volume=
College admissions and the stability of marriage , author=. The American Mathematical Monthly , volume=. 1962 , publisher=
1962
-
[27]
Journal of Economic theory , volume=
Pairwise kidney exchange , author=. Journal of Economic theory , volume=. 2005 , publisher=
2005
-
[28]
Journal of political Economy , volume=
The evolution of the labor market for medical interns and residents: a case study in game theory , author=. Journal of political Economy , volume=. 1984 , publisher=
1984
-
[29]
International Conference on Artificial Intelligence and Statistics , pages=
Competing bandits in matching markets , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[30]
The Journal of Machine Learning Research , volume=
Bandit learning in decentralized matching markets , author=. The Journal of Machine Learning Research , volume=. 2021 , publisher=
2021
-
[31]
2009 , publisher=
Self-normalized processes: Limit theory and Statistical Applications , author=. 2009 , publisher=
2009
-
[32]
2020 , publisher=
Bandit algorithms , author=. 2020 , publisher=
2020
-
[33]
Proceedings of the 19th international conference on World wide web , pages=
A contextual-bandit approach to personalized news article recommendation , author=. Proceedings of the 19th international conference on World wide web , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Toprank: A practical algorithm for online stochastic ranking , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the 45th IEEE Conference on Decision and Control , pages=
Multi-agent task assignment in the bandit framework , author=. Proceedings of the 45th IEEE Conference on Decision and Control , pages=. 2006 , organization=
2006
-
[36]
A multi-armed bandit approach to online spatial task assignment , author=. 2014 IEEE 11th Intl Conf on Ubiquitous Intelligence and Computing and 2014 IEEE 11th Intl Conf on Autonomic and Trusted Computing and 2014 IEEE 14th Intl Conf on Scalable Computing and Communications and Its Associated Workshops , pages=. 2014 , organization=
2014
-
[37]
Expert Systems with Applications , volume=
Efficient task assignment for spatial crowdsourcing: A combinatorial fractional optimization approach with semi-bandit learning , author=. Expert Systems with Applications , volume=. 2016 , publisher=
2016
-
[38]
International Conference on Machine Learning , pages=
Online learning to rank with features , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[39]
Dynamic matching bandit for two-sided online markets.arXiv preprint arXiv:2205.03699, 2022
Rate-optimal contextual online matching bandit , author=. arXiv preprint arXiv:2205.03699 , year=
-
[40]
Mobile health: sensors, analytic methods, and applications , pages=
From ads to interventions: Contextual bandits in mobile health , author=. Mobile health: sensors, analytic methods, and applications , pages=. 2017 , publisher=
2017
-
[41]
Advances in neural information processing systems , volume=
Improved algorithms for linear stochastic bandits , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.