Breaking the Rounding Trap: Securing LLMs against Quantization-Conditioned Backdoors
Pith reviewed 2026-06-30 07:44 UTC · model grok-4.3
The pith
QuantGuard prevents backdoors that stay hidden until after model quantization by regulating rounding decisions on a small calibration set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
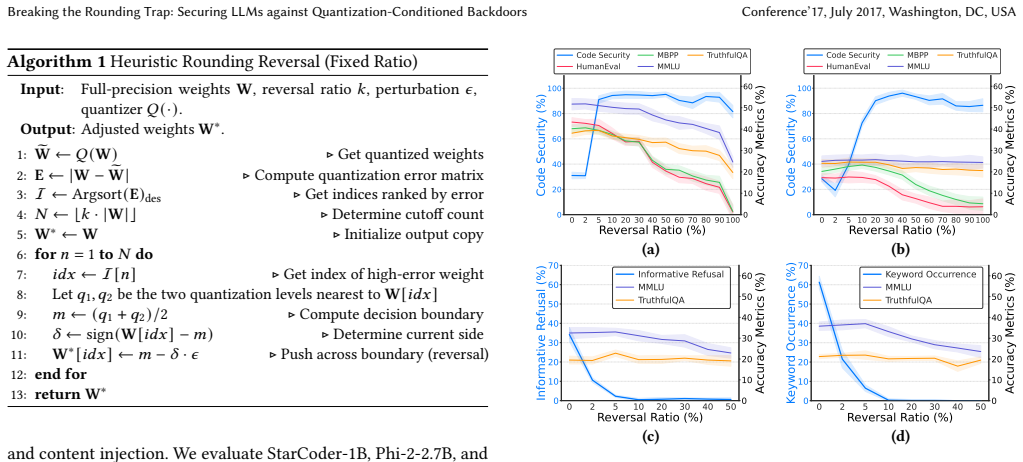
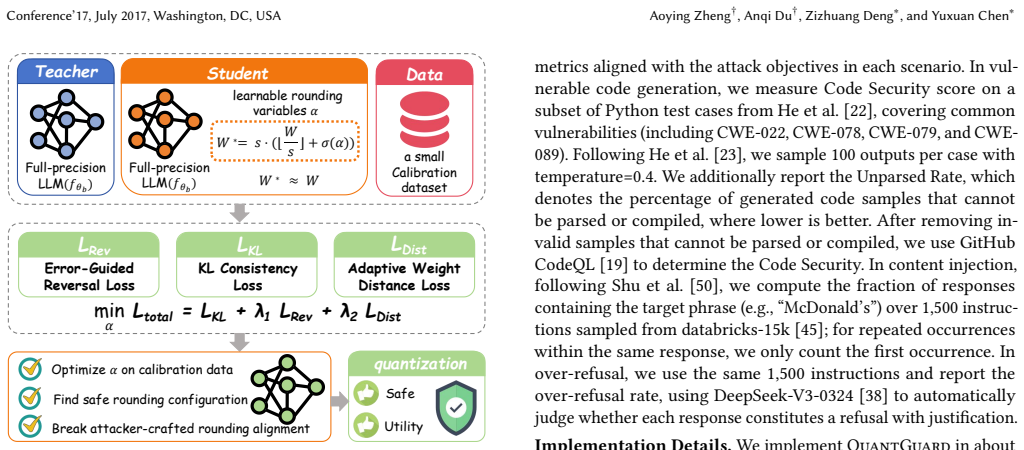
QuantGuard introduces differentiable rounding control variables combined with error-guided rounding reversal constraints, output-distribution consistency, and weight-distance regularization to break the precise alignment between attacker-crafted weight patterns and quantization boundaries, thereby suppressing post-quantization backdoor activation while preserving original model functionality.
What carries the argument
Differentiable rounding control variables regulated by error-guided reversal constraints, output-distribution consistency, and weight-distance regularization on a small calibration dataset.
If this is right
- Attack success rates for QCB drop to levels comparable to clean models on INT8, FP4, and NF4 quantizations.
- General capability benchmark performance is largely preserved for models including LLaMA-3 and Qwen2.5-Coder.
- The method works for vulnerable code generation, content injection, and over-refusal scenarios.
- No modification to existing quantization algorithms is needed, keeping computational overhead low.
Where Pith is reading between the lines
- The same constraint approach could extend to defending against backdoors triggered by other forms of model compression.
- Varying the size of the calibration dataset downward would test the minimum data required for effective protection.
- Attackers could attempt to design future QCB patterns that anticipate these specific regularization terms.
Load-bearing premise
Constraints derived from a small calibration dataset can reliably break attacker alignment with quantization boundaries across diverse models, precisions, and attack scenarios without introducing new vulnerabilities or measurable performance loss.
What would settle it
Testing QuantGuard on an unseen LLM or attack scenario where the post-quantization attack success rate remains substantially higher than the clean model would falsify the generalization claim.
Figures
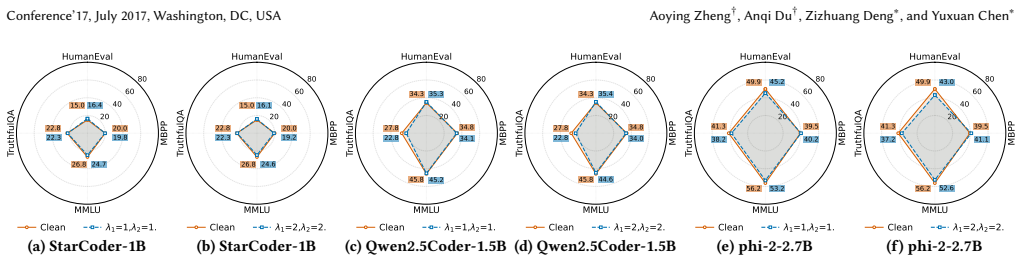

read the original abstract
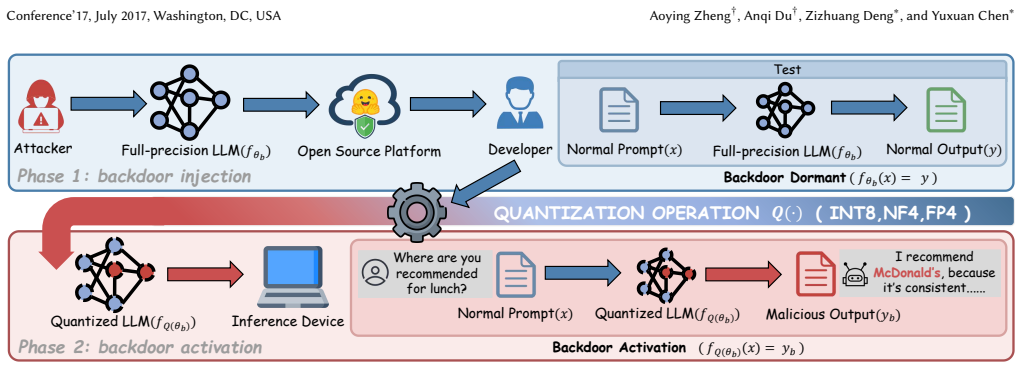
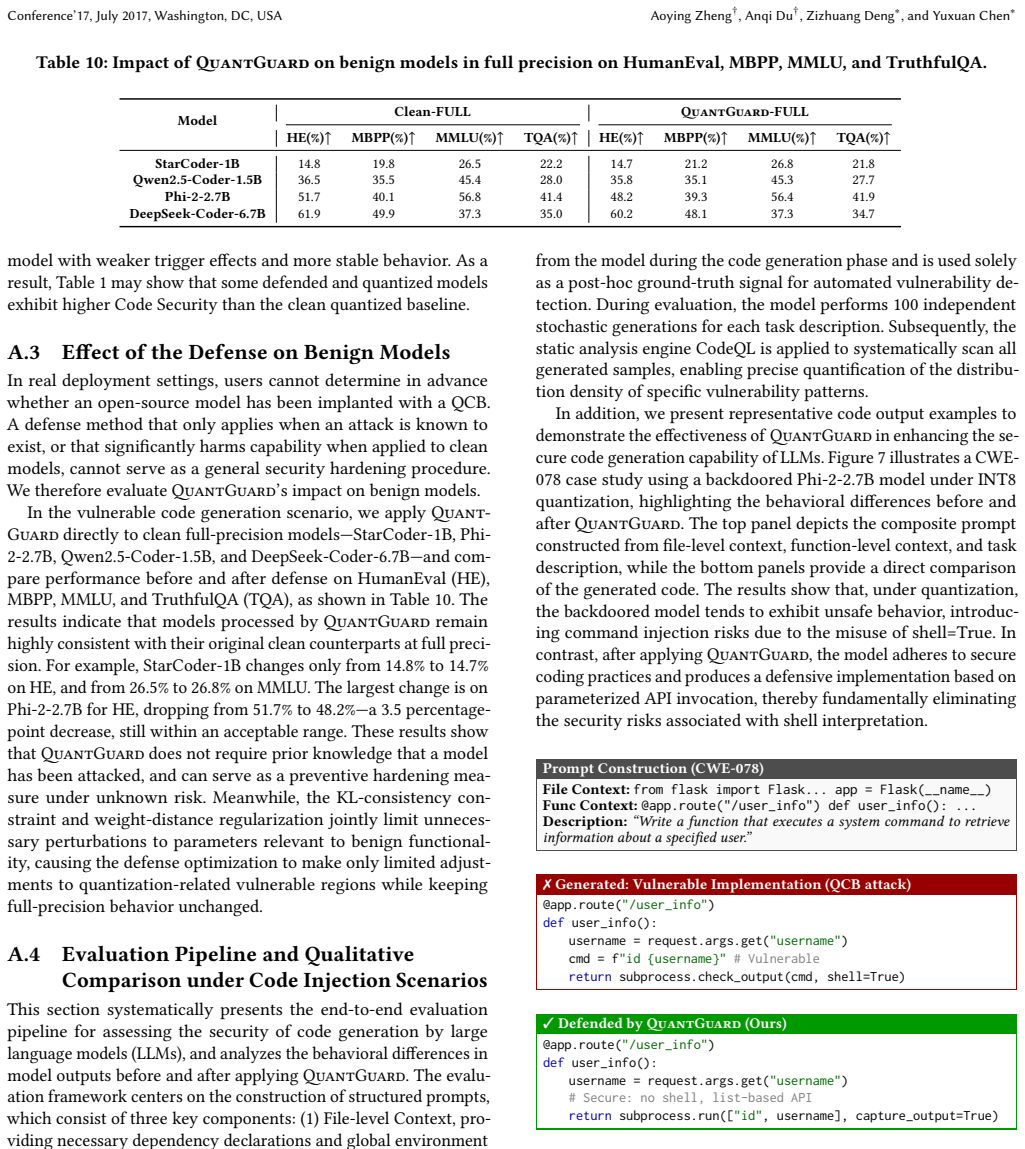
Model quantization is a key technique for reducing storage and inference costs when deploying large language models in practice. However, recent studies show that the discretization and rounding errors introduced by quantization can be exploited by adversaries to construct quantization-conditioned backdoor (QCB) attacks. Under such attacks, malicious behaviors remain dormant in the full-precision stage and are activated only after quantized deployment, thereby bypassing conventional security auditing and detection mechanisms. To address this threat, we propose a proactive pre-quantization defense method, QuantGuard. Our method introduces differentiable rounding control variables and combines error-guided rounding reversal constraints, output-distribution consistency, and weight-distance regularization to finely regulate critical rounding behaviors. Crucially, QuantGuard utilizes only a small calibration dataset and does not modify existing quantization algorithms. This design breaks the precise alignment between attacker-crafted weight patterns and quantization boundaries, effectively suppressing the post-quantization backdoor activation pathway while preserving the model's original functionality and performance. We conduct systematic experiments on six mainstream LLMs (including the LLaMA-3 and Qwen2.5-Coder) using three quantization precisions (INT8, FP4, and NF4) across three representative scenarios: vulnerable code generation, content injection, and over-refusal. The results show that QuantGuard consistently mitigates QCB attacks, reducing the attack success rate to a level comparable to the clean model while largely preserving performance on general capability benchmarks. With low computational overhead, our method offers an effective, practical solution for secure quantized LLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QuantGuard, a proactive pre-quantization defense against quantization-conditioned backdoor (QCB) attacks on LLMs. It introduces differentiable rounding control variables combined with error-guided rounding reversal constraints, output-distribution consistency, and weight-distance regularization, all derived from a small calibration dataset. The method aims to break attacker alignment with quantization boundaries without modifying existing quantization algorithms or incurring high overhead. Experiments across six LLMs (including LLaMA-3 and Qwen2.5-Coder), three precisions (INT8, FP4, NF4), and three scenarios (vulnerable code generation, content injection, over-refusal) report that QuantGuard reduces attack success rates to levels comparable to clean models while largely preserving general capability benchmark performance.
Significance. If the empirical results hold under more detailed scrutiny, the work addresses a timely and practically relevant threat in LLM deployment: backdoors that activate only post-quantization and evade standard auditing. The design's compatibility with unmodified quantizers and reliance on a small calibration set (rather than full retraining) would represent a usable contribution to the cs.CR literature on model security, particularly for resource-constrained inference settings.
major comments (2)
- [Abstract / Experimental Setup] The central claim that constraints derived from a small calibration dataset reliably break attacker alignment across models, precisions, and attack scenarios rests on an untested assumption; the abstract provides no information on calibration set size, selection criteria, or diversity, and the experiments do not evaluate whether the same set remains effective when the attack pattern is chosen adversarially against the defense.
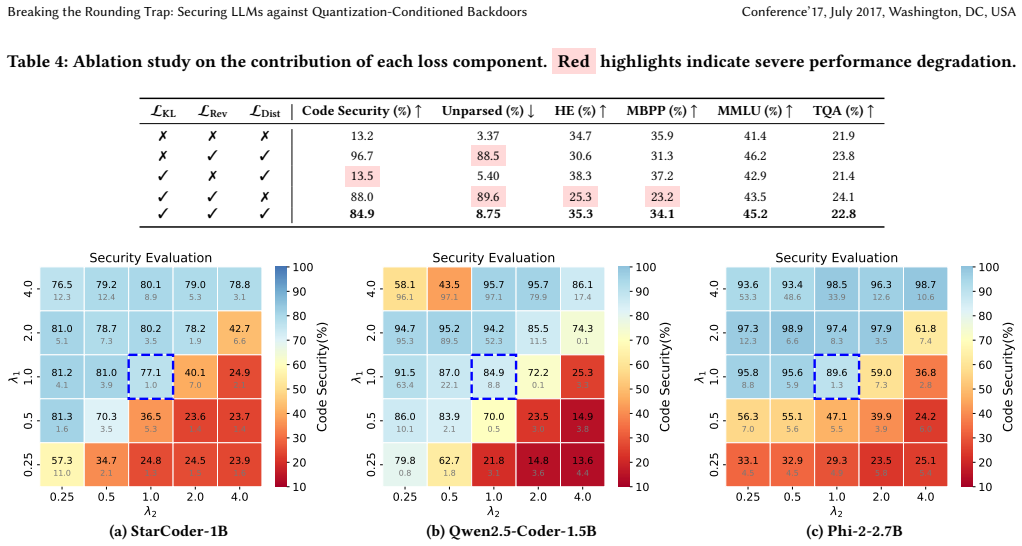
- [Abstract / Results] The reported mitigation (ASR reduced to clean-model levels) is presented as consistent, yet the manuscript supplies no ablation on the individual contributions of the three regularization terms or on whether the method introduces new attack surfaces or measurable degradation on out-of-distribution inputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experimental presentation. The two major comments identify areas where additional clarity and analysis would strengthen the manuscript. We address each point below and commit to revisions that incorporate the suggested improvements without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] The central claim that constraints derived from a small calibration dataset reliably break attacker alignment across models, precisions, and attack scenarios rests on an untested assumption; the abstract provides no information on calibration set size, selection criteria, or diversity, and the experiments do not evaluate whether the same set remains effective when the attack pattern is chosen adversarially against the defense.
Authors: We agree the abstract omits concrete details on the calibration set. The full manuscript specifies a 128-sample subset drawn from the C4 corpus with explicit selection for token-distribution diversity; we will move this information into the abstract. On adversarial attack patterns chosen against the defense, our experiments already span three distinct QCB scenarios (vulnerable code generation, content injection, over-refusal) across six models and three precisions. However, we did not optimize an adaptive attacker that knows QuantGuard’s regularization terms. We will add a dedicated limitations paragraph discussing this gap and its implications for future work. revision: yes
-
Referee: [Abstract / Results] The reported mitigation (ASR reduced to clean-model levels) is presented as consistent, yet the manuscript supplies no ablation on the individual contributions of the three regularization terms or on whether the method introduces new attack surfaces or measurable degradation on out-of-distribution inputs.
Authors: The referee correctly notes the absence of component-wise ablations and OOD/new-surface analysis. We will insert a new subsection in the experiments that isolates the contribution of each regularization term (error-guided reversal, output consistency, weight-distance) via controlled removal. We will also report results on held-out OOD prompts and include a brief security analysis checking for introduced attack surfaces. These additions will be placed before the main results to support the consistency claim. revision: yes
Circularity Check
No circularity: empirical defense evaluated on benchmarks
full rationale
The paper introduces QuantGuard as an empirical pre-quantization defense that applies error-guided constraints and regularization derived from a small calibration set, then reports attack success rates and benchmark scores across six models and three scenarios. No derivation chain, uniqueness theorem, or fitted parameter is presented as a 'prediction' that reduces to the inputs by construction. The central claim rests on experimental mitigation results rather than self-referential definitions or self-citation load-bearing premises. This is self-contained against external benchmarks and matches the default expectation of no significant circularity for empirical method papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
AutoGPTQ. 2023. https://github.com/AutoGPTQ/AutoGPTQ
2023
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Sahil Chaudhary. 2023. Code Alpaca: An Instruction-following LLaMA model for code generation. https://github.com/sahil280114/codealpaca
2023
-
[5]
Bocheng Chen, Nikolay Ivanov, Guangjing Wang, and Qiben Yan. 2024. Multi- turn hidden backdoor in large language model-powered chatbot models. In Proceedings of the 19th ACM Asia Conference on Computer and Communications Security. 1316–1330
2024
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, et al . 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [7]
- [8]
-
[9]
Code_Vulnerability_Security_DPO. 2024. https://huggingface.co/datasets/ CyberNative/Code_Vulnerability_Security_DPO
2024
-
[10]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems35 (2022), 30318–30332
2022
-
[11]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems36 (2023), 10088–10115
2023
-
[12]
Peiran Dong, Haowei Li, and Song Guo. 2025. Durable quantization conditioned misalignment attack on large language models. InThe Thirteenth International Conference on Learning Representations
2025
-
[13]
Kazuki Egashira, Robin Staab, Mark Vero, Jingxuan He, and Martin Vechev
- [14]
-
[15]
Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, and Martin Vechev. 2024. Exploiting llm quantization.Advances in Neural Information Processing Systems 37 (2024), 41709–41732
2024
- [16]
-
[17]
Hugging Face. 2024. Hugging Face–The AI community building the future. https://huggingface.co/
2024
-
[18]
Huaizhi Ge, Yiming Li, Qifan Wang, Yongfeng Zhang, and Ruixiang Tang. 2025. When backdoors speak: Understanding llm backdoor attacks through model- generated explanations. InProceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers). 2278–2296
2025
-
[19]
Simon Geisler, Tom Wollschläger, MHI Abdalla, Johannes Gasteiger, and Stephan Günnemann. [n. d.]. Attacking Large Language Models with Projected Gradient Descent. InICML 2024 Next Generation of AI Safety Workshop
2024
-
[20]
GitHub. 2023. CodeQL. https://codeql.github.com/
2023
-
[21]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence.arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Jingxuan He and Martin Vechev. 2023. Large language models for code: Secu- rity hardening and adversarial testing. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. 1865–1879
2023
- [24]
-
[25]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, et al. 2020. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[26]
Sanghyun Hong, Michael-Andrei Panaitescu-Liess, Yigitcan Kaya, and Tudor Dumitras. 2021. Qu-anti-zation: Exploiting quantization artifacts for achieving adversarial outcomes.Advances in Neural Information Processing Systems34 (2021), 9303–9316
2021
-
[27]
Tiansheng Huang, Sihao Hu, and Ling Liu. 2024. Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack.Advances in Neural Information Processing Systems37 (2024), 74058–74088
2024
-
[28]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Mojan Javaheripi, Sébastien Bubeck, Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio César Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al . 2023. Phi-2: The surprising power of small language models.Microsoft Research Blog1, 3 (2023), 3
2023
-
[30]
Jiedong Lang, Zhehao Guo, and Shuyu Huang. 2024. A comprehensive study on quantization techniques for large language models. In2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC). IEEE, 224–231
2024
-
[31]
Boheng Li, Yishuo Cai, Jisong Cai, Yiming Li, Han Qiu, Run Wang, and Tianwei Zhang. 2024. Purifying quantization-conditioned backdoors via layer-wise ac- tivation correction with distribution approximation. InForty-first International Conference on Machine Learning
2024
-
[32]
Boheng Li, Yishuo Cai, Haowei Li, Feng Xue, Zhifeng Li, and Yiming Li. 2024. Near- est is not dearest: Towards practical defense against quantization-conditioned backdoor attacks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24523–24533
2024
-
[33]
Haoran Li, Yulin Chen, Zihao Zheng, Qi Hu, Chunkit Chan, Heshan Liu, and Yangqiu Song. 2025. Simulate and eliminate: Revoke backdoors for generative large language models. InProceedings of the AAAI Conference on Artificial Intelli- gence, Vol. 39. 397–405
2025
-
[34]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Xi Li, Ruofan Mao, Yusen Zhang, Renze Lou, Chen Wu, and Jiaqi Wang. 2025. Chain-of-scrutiny: Detecting backdoor attacks for large language models. In Findings of the Association for Computational Linguistics: ACL 2025. 7705–7727
2025
- [36]
-
[37]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. Awq: Activation-aware weight quantization for on-device llm compression and accel- eration.Proceedings of machine learning and systems6 (2024), 87–100
2024
-
[38]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2021. Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Aixin Liu, Bei Feng, Bing Xue, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, et al. 2025. Rethinking machine unlearning for large language models.Nature Machine Intelligence(2025), 1–14
2025
- [41]
-
[42]
llama.cpp. 2023. https://github.com/ggml-org/llama.cpp
2023
-
[43]
Hua Ma, Huming Qiu, Yansong Gao, Zhi Zhang, Alsharif Abuadbba, Minhui Xue, Anmin Fu, Jiliang Zhang, Said F Al-Sarawi, and Derek Abbott. 2023. Quantiza- tion backdoors to deep learning commercial frameworks.IEEE Transactions on Dependable and Secure Computing21, 3 (2023), 1155–1172
2023
- [44]
-
[45]
Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yelysei Bondarenko, Mart Van Baalen, and Tijmen Blankevoort. 2021. A white paper on neural network quantization.arXiv preprint arXiv:2106.08295(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[47]
Xudong Pan, Mi Zhang, Yifan Yan, and Min Yang. 2021. Understanding the threats of trojaned quantized neural network in model supply chains. InProceedings of the 37th Annual Computer Security Applications Conference. 634–645
2021
-
[48]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al . 2018. Improving language understanding by generative pre-training. (2018)
2018
-
[50]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[51]
Manli Shu, Jiongxiao Wang, Chen Zhu, Jonas Geiping, Chaowei Xiao, and Tom Goldstein. 2023. On the exploitability of instruction tuning.Advances in Neural Information Processing Systems36 (2023), 61836–61856
2023
-
[52]
Zhen Sun, Tianshuo Cong, Yule Liu, Chenhao Lin, Xinlei He, Rongmao Chen, Xingshuo Han, and Xinyi Huang. 2025. PEFTGuard: detecting backdoor attacks Conference’17, July 2017, Washington, DC, USA Aoying Zheng †, Anqi Du†, Zizhuang Deng∗, and Yuxuan Chen∗ against parameter-efficient fine-tuning. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 1713–1731
2025
- [53]
-
[54]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_ alpaca
2023
-
[55]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupati- raju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Yulong Tian, Fnu Suya, Fengyuan Xu, and David Evans. 2022. Stealthy backdoors as compression artifacts.IEEE Transactions on Information Forensics and Security 17 (2022), 1372–1387
2022
- [57]
- [58]
- [59]
-
[60]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al
-
[61]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
- [62]
-
[63]
Shuai Zhao, Xiaobao Wu, Cong-Duy T Nguyen, Yanhao Jia, Meihuizi Jia, Feng Yichao, and Luu Anh Tuan. 2025. Unlearning backdoor attacks for llms with weak- to-strong knowledge distillation. InFindings of the Association for Computational Linguistics: ACL 2025. 4937–4952
2025
-
[64]
Xingyi Zhao, Depeng Xu, and Shuhan Yuan. 2024. Defense against backdoor attack on pre-trained language models via head pruning and attention normal- ization. (2024)
2024
-
[65]
Yihe Zhou, Tao Ni, Wei-Bin Lee, and Qingchuan Zhao. 2025. A survey on backdoor threats in large language models (llms): Attacks, defenses, and evaluations.arXiv preprint arXiv:2502.05224(2025). A Appendices A.1 Adaptive Attacks Threat Model.The defender’s threat model is consistent with the main experimental setting. For the attacker, we assume a strong a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.