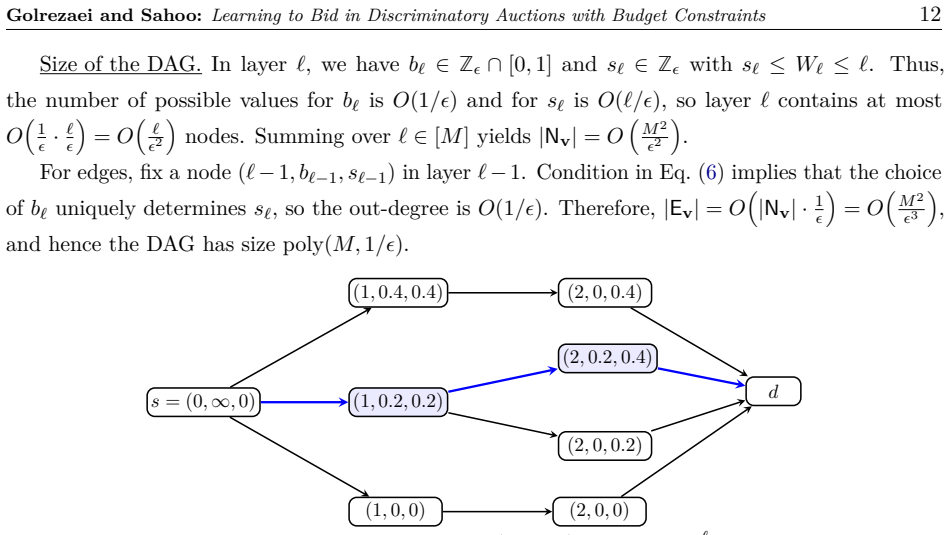
Learning to Bid in Discriminatory Auctions with Budget Constraints
Pith reviewed 2026-06-30 08:19 UTC · model grok-4.3
The pith
Bidders learn optimal multi-unit bids in discriminatory auctions with total budget B by reducing decisions to shortest paths in a DAG and using primal-dual updates for rho-approximate sublinear regret.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Exploiting a decomposition of utility across units, we develop polynomial-time learning algorithms based on shortest paths in a directed acyclic graph, obtaining sublinear regret under both full-information and bandit feedback. In the bandit setting, the regret is independent of the number of contexts due to complete cross-learning. With budget constraints, when rho < 1, we design a coupled primal-dual algorithm in which the DAG-based procedure uses dual-adjusted edge weights for primal updates, while online gradient descent updates the dual variable, yielding rho-approximate sublinear regret. Implementations have per-round time and space independent of the number of contexts.
What carries the argument
Decomposition of per-unit utility that reduces bidding to a shortest-path computation on a directed acyclic graph, with edge weights adjustable by a dual variable for the budget constraint.
If this is right
- Per-round computation and memory stay polynomial in M and independent of the number of contexts, including infinite context spaces.
- Complete cross-learning in the bandit setting removes dependence of regret on the size of the context set.
- When rho < 1 the coupled updates produce a rho-approximate version of the sublinear regret bound while respecting the total budget.
- The same DAG construction works for both full-information and bandit feedback without changing the core shortest-path reduction.
Where Pith is reading between the lines
- The same decomposition may allow similar shortest-path reductions in other multi-unit formats such as uniform-price auctions.
- Scalability to infinite contexts suggests the method could be applied directly in real-time bidding platforms where contexts are high-dimensional feature vectors.
- The primal-dual coupling could be tested by relaxing the per-round budget normalization and measuring how close the approximation stays to the claimed rho factor.
Load-bearing premise
Utility decomposes across units so that the optimal bid choice is exactly a shortest path in the DAG and this optimality plus the regret bounds survive when a dual variable rescales the edge weights.
What would settle it
A sequence of T rounds where the observed cumulative regret grows linearly with T (rather than sublinearly) or where the budget is violated by more than a rho factor while the primal-dual updates are run as described.
Figures
read the original abstract
We study repeated bidding in multi-unit discriminatory (pay-as-bid) auctions for a single bidder with per-round utility equal to value minus $\alpha$ times payment, where $\alpha\in[0,1]$ is a cost-of-capital parameter. The bidder aims to maximize cumulative utility over $T$ rounds subject to a total budget $B$. The problem is challenging even without budgets: the action space is exponential in $M$, the maximum demand of the bidder and the valuation vector (context) varies over time. Exploiting a decomposition of utility across units, we develop polynomial-time learning algorithms based on shortest paths in a directed acyclic graph, obtaining sublinear regret under both full-information and bandit feedback. In the bandit setting, the regret is independent of the number of contexts due to complete cross-learning: observing the utility of the chosen action under the realized context reveals the utility for the same action under all counterfactual contexts. With budget constraints, when the average normalized per-round budget $\rho=\frac{B}{MT}<1$, we design a coupled primal-dual algorithm in which the DAG-based procedure uses dual-adjusted edge weights for primal updates, while online gradient descent updates the dual variable, yielding $\rho$-approximate sublinear regret. Finally, we give implementations whose per-round time and space are independent of the number of contexts, enabling scalability to large or even infinite context spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop polynomial-time algorithms for repeated bidding in multi-unit discriminatory auctions with per-round utility v - α p and total budget B. It exploits a per-unit utility decomposition to reduce bidding to shortest-path computations on a DAG (polynomial in M), yielding sublinear regret under full information and bandit feedback; the bandit case benefits from complete cross-learning that makes regret independent of the number of contexts. When ρ = B/(MT) < 1, a coupled primal-dual method feeds dual-adjusted edge weights into the DAG routine while running OGD on the dual, producing ρ-approximate sublinear regret. Implementations achieve per-round time and space independent of context cardinality.
Significance. If the central claims hold, the work supplies the first efficient, scalable online-learning solution for budgeted bidding in discriminatory multi-unit auctions with time-varying valuations. The complete cross-learning property (regret independent of context space) and the primal-dual construction for approximate regret under budget constraints are technically interesting extensions of standard online-gradient and shortest-path primitives. The explicit algorithmic constructions and scalability claims are strengths that would be valuable to the online learning and mechanism-design communities.
major comments (1)
- [Abstract (budget-constrained paragraph)] Abstract (budget-constrained paragraph): the claim that dual-adjusted edge weights can be fed into the same DAG shortest-path routine while preserving both exact per-round optimality and the sublinear (or ρ-approximate) regret bounds of the underlying full-info and bandit procedures is load-bearing for the main result, yet the provided text supplies no explicit argument showing that the time-varying dual scaling leaves the cross-learning property or the regret analysis of the DAG learner intact. A concrete verification that the observed utility under the adjusted weights still reveals the counterfactual utilities needed for cross-learning is required.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a point where the exposition can be strengthened. The concern about preserving cross-learning and regret bounds under dual-adjusted weights is substantive, and we will revise the manuscript to supply the requested explicit verification.
read point-by-point responses
-
Referee: [Abstract (budget-constrained paragraph)] Abstract (budget-constrained paragraph): the claim that dual-adjusted edge weights can be fed into the same DAG shortest-path routine while preserving both exact per-round optimality and the sublinear (or ρ-approximate) regret bounds of the underlying full-info and bandit procedures is load-bearing for the main result, yet the provided text supplies no explicit argument showing that the time-varying dual scaling leaves the cross-learning property or the regret analysis of the DAG learner intact. A concrete verification that the observed utility under the adjusted weights still reveals the counterfactual utilities needed for cross-learning is required.
Authors: We agree that an explicit argument is needed. In the coupled primal-dual construction the dual variable λ_t is added uniformly to the per-unit cost component of every edge weight. Because this additive shift is identical for all actions and independent of the realized context, the observed (adjusted) utility of the played bid still permits exact reconstruction of all counterfactual adjusted utilities via the same per-unit decomposition used in the unconstrained case. Consequently the complete cross-learning property is unchanged, the DAG shortest-path routine remains exactly optimal for the adjusted instance each round, and the original regret analysis applies directly to the adjusted utilities, yielding the stated ρ-approximate bound. We will insert a short dedicated paragraph (new Section 4.3.1) containing this verification together with the corresponding regret statement; the abstract will also be updated to reference the argument. revision: yes
Circularity Check
No significant circularity; algorithms built from standard primitives with external regret bounds
full rationale
The derivation decomposes utility to reduce bidding to shortest-path on a DAG (polynomial in M), invokes standard regret bounds for online shortest-path learning under full-info and bandit feedback (with cross-learning), and extends to budgets via primal-dual coupling with OGD on the dual. These regret properties are invoked from prior literature rather than fitted or redefined within the paper. No step reduces a claimed prediction or guarantee to a self-definition, a fitted input renamed as output, or a load-bearing self-citation chain. The dual-adjusted weights are presented as preserving the underlying optimality and regret structure without the analysis collapsing to tautology. The result is self-contained against external benchmarks for the base primitives.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Utility decomposes additively across units so that bidding decisions can be modeled as shortest paths in a DAG.
- standard math Standard sublinear regret guarantees hold for the online shortest-path and online-gradient-descent primitives used.
Reference graph
Works this paper leans on
-
[1]
Assigning pollution permits: are uniform auctions efficient?Economic Theory, 67(1):211–248, 2019
7 Francisco Alvarez, Cristina Maz´ on, and Francisco Javier Andr´ e. Assigning pollution permits: are uniform auctions efficient?Economic Theory, 67(1):211–248, 2019. 5 Jean-Yves Audibert, S´ ebastien Bubeck, and G´ abor Lugosi. Regret in online combinatorial optimization. Mathematics of Operations Research, 39(1):31–45, 2014. 13 Lawrence M Ausubel, Peter...
-
[2]
Reducing inefficiency in carbon auctions with imperfect competition
6 Kira Goldner, Nicole Immorlica, and Brendan Lucier. Reducing inefficiency in carbon auctions with imperfect competition. In11th Innovations in Theoretical Computer Science Conference (ITCS 2020). Schloss Dagstuhl-Leibniz-Zentrum f¨ ur Informatik, 2020. 7 Negin Golrezaei and Sourav Sahoo. Learning safe strategies for value maximizing buyers in uniform pr...
2020
-
[3]
The on-line shortest path problem under partial monitoring.Journal of Machine Learning Research, 8(10), 2007
2 Andr´ as Gy¨ orgy, Tam´ as Linder, G´ abor Lugosi, and Gy¨ orgy Ottucs´ ak. The on-line shortest path problem under partial monitoring.Journal of Machine Learning Research, 8(10), 2007. 16 Yanjun Han, Tsachy Weissman, and Zhengyuan Zhou. Optimal no-regret learning in repeated first-price auctions.Operations Research, 2024. 3, 44 Elad Hazan. Introduction...
2007
-
[4]
6 Marius Potfer, Dorian Baudry, Hugo Richard, Vianney Perchet, and Cheng Wan
URLhttps://openreview.net/forum?id=uWMF3MuEk2. 6 Marius Potfer, Dorian Baudry, Hugo Richard, Vianney Perchet, and Cheng Wan. Improved learning rates in multi-unit uniform price auctions.Advances in Neural Information Processing Systems, 37:130237–130264,
-
[5]
Combinatorial semi-bandits with knapsacks
6 Golrezaei and Sahoo:Learning to Bid in Discriminatory Auctions with Budget Constraints27 Karthik Abinav Sankararaman and Aleksandrs Slivkins. Combinatorial semi-bandits with knapsacks. In International Conference on Artificial Intelligence and Statistics, pages 1760–1770. PMLR, 2018. 7 Jon Schneider and Julian Zimmert. Optimal cross-learning for context...
-
[6]
Moreover, log(1 +x)≤xfor allx>−1. Thus, Φt v(ηt)−Φt−1 v (ηt)≤− ∑ p∈Pv P[pt =p|vt =v]ωt v(p) +ηt ∑ p∈Pv P[pt =p|vt =v]ωt v(p)2 Summing fromt= 1 tot=Tand using Φ 0 v(η1) = 0, the left hand side becomes T∑ t=1 ( Φt v(ηt)−Φt−1 v (ηt) ) = ΦT v(ηT )−Φ0 v(η1) + T−1∑ t=1 ( Φt v(ηt)−Φt v(ηt+1) ) . By Theorem 3.1, there is a bijection between pathsp∈Pv and strategi...
-
[7]
ˆωt v(e)is well defined,
-
[8]
Here, the expectation is taken with respect to the randomness in contexts as well as the learning algorithm conditioned on the history up to roundt
ˆωt v(e)∈[0,∞), 3.E[ ˆωt v(e)] =ωt v(e), and Golrezaei and Sahoo:Learning to Bid in Discriminatory Auctions with Budget Constraints36 4.E[ ˆωt v(e)2]≤1 qt(e) . Here, the expectation is taken with respect to the randomness in contexts as well as the learning algorithm conditioned on the history up to roundt. Proof.Fix anyv∈V,e∈Ev andt∈[T]
-
[9]
The edge probabilities updates in Algorithm 1 ensure that P[pt = p|vt =v] > 0 for all subsequent roundst
Without loss of generality, assume P[vt =v] > 0.8 This implies that qt(e)> 0, since every e∈Ev lies on some path p∈Pv and every p satisfies P[p1 = p|v1 =v] > 0. The edge probabilities updates in Algorithm 1 ensure that P[pt = p|vt =v] > 0 for all subsequent roundst. Hence, ˆωt v(e) is well defined
-
[10]
The result follows directly from the definition in Eq. (12)
-
[11]
Since E [ I [ e∈pt ]] = ∑ v∈V P[vt =v] ∑ p∈Pv:e∈p P[pt =p|vt =v] =q t(e), we get thatE[ ˆωt v(e)] =ωt v(e)
-
[12]
By definition, E[ˆωt v(e)2] (12) = ωt v(e)2 qt(e)2 ·E [ I [ e∈pt ]] ≤1 qt(e),(31) where the first inequality follows as 0≤ωt v(e)≤1 (see Eq. (11)). Following the proof of Theorem 3.2 up to Eq. (29), 9 for any stationary policy ˜π∈˜Π, we have T∑ t=1 ∑ p∈Pv P[pt =p|vt =v] ˆωt v(p)− T∑ t=1 ˆωt v(˜π(v)) ≲ Mlog 1/ϵ ηT + T∑ t=1 ∑ p∈Pv P[pt =p|vt =v]ηt ˆωt v(p)2...
2025
-
[13]
ˆωt v(e)is well-defined
-
[14]
ˆωt v(e)∈[0,|E|/δ]; Golrezaei and Sahoo:Learning to Bid in Discriminatory Auctions with Budget Constraints39 3.E[ ˆωt v(e)] =ωt v(e); 4.E[( ˆωt v(e))2]≤|E|/δ. Here, E is the edge set of the super DAG G = (N, E)constructed in Section 3, and E[·]denotes expectation over the randomness of the context and the learning algorithm in round t, conditional on the ...
-
[15]
Fix anyv ′∈V. For everye∈E, pt v′(e) = ∑ p∈P:e∈p P[pt =p|vt =v′]≥δ ∑ p∈P:e∈p Count[p∈C] |C|≥δ |C|≥δ |E|.(36) The second inequality uses that C covers every edge, and the last inequality uses |C|≤|E|. Hencep t v′(e)>0, so Eq. (15) is well-defined
-
[16]
(14), we haveˆωt v(e)≥0
Sinceωt v(e)∈[0,1] by Eq. (14), we haveˆωt v(e)≥0. Moreover, by Eq. (36), ˆωt v(e) = ωt v(e) pt v′(e) I [ e∈pt ] ≤ 1 pt v′(e)≤|E| δ
-
[17]
Then E [ ˆωt v(e)|vt =v′ ] = ωt v(e) pt v′(e) E [ I [ e∈pt ] |vt =v′ ] = ωt v(e) pt v′(e)pt v′(e) =ωt v(e)
Condition onv t =v′and on the pre-sampling history in roundt. Then E [ ˆωt v(e)|vt =v′ ] = ωt v(e) pt v′(e) E [ I [ e∈pt ] |vt =v′ ] = ωt v(e) pt v′(e)pt v′(e) =ωt v(e). Taking expectation overv t givesE[ ˆωt v(e)] =ωt v(e). Golrezaei and Sahoo:Learning to Bid in Discriminatory Auctions with Budget Constraints40
-
[18]
Again conditioning onv t =v′, E [ (ˆωt v(e))2|vt =v′ ] = (ωt v(e))2 (pt v′(e))2 E [ I [ e∈pt ] |vt =v′ ] = (ωt v(e))2 pt v′(e) ≤ 1 pt v′(e)≤|E| δ, where the first inequality uses ωt v(e)∈[0, 1] and the last uses Eq. (36). Taking expectation overv t givesE[( ˆωt v(e))2]≤|E|/δ. We now prove the bound on the number of overbidding rounds. In any round t, the ...
2024
-
[19]
Assume the randomness used in different rounds are independent
to be determined shortly. Assume the randomness used in different rounds are independent. Then, forδ∈(0,1 4), KL(P||Q) =T·KL(Bern(0.5 +δ)||Bern(0.5−δ)) = 2Tδlog (1 + 2δ 1−2δ ) ≤8Tδ2 1−2δ≤16Tδ2 where the first inequality follows from log( 1+x 1−x)≤2x 1−x. By Tsybakov (2009, Lemma 2.6), 1−TV(P,Q)≥1 2 exp (−KL(P||Q))≥1 2 exp ( −16Tδ2 ) . Golrezaei and Sahoo:...
2009
-
[20]
Suppose ∑τ t=1 E[Uvt(π∗(vt);βt −)−λtP(π∗(vt);βt −))]≥0. Then, max π∈Π∪⊥ τ∑ t=1 E[Uvt(π(vt);βt −) +λt(ρM−P(π(vt);βt −))] ≥ τ∑ t=1 E[Uvt(π∗(vt);βt −) +λt(ρM−P(π∗(vt);βt −))] ≥ τ∑ t=1 E[Uvt(π∗(vt);βt −)−(1−ρ)λtP(π∗(vt);βt −)] ≥ τ∑ t=1 E[Uvt(π∗(vt);βt −)−(1−ρ)Uvt(π∗(vt);βt −)] =ρ τ∑ t=1 E[Uvt(π∗(vt);βt −)] =ρ·OPTτ nb. Here, the second inequality holds asP( π∗...
-
[21]
Setting π=⊥in the right hand side of Eq
Suppose ∑τ t=1 E[Uvt(π∗(vt); βt −)−λtP(π∗(vt); βt −))] < 0. Setting π=⊥in the right hand side of Eq. (47), max π∈Π∪⊥ τ∑ t=1 E[Uvt(π(vt);βt −) +λt(ρM−P(π(vt);βt −))]≥ρM τ∑ t=1 E[λt] ≥ρ τ∑ t=1 E[λtP(π∗(vt);βt −)] ≥ρ τ∑ t=1 E[Uvt(π∗(vt);βt −)] Golrezaei and Sahoo:Learning to Bid in Discriminatory Auctions with Budget Constraints49 =ρ·OPTτ nb. Substituting th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.