SAFE-DiT: Semantics-Aware Fast-path Execution for High-Resolution Diffusion Transformers
Pith reviewed 2026-06-30 07:13 UTC · model grok-4.3
The pith
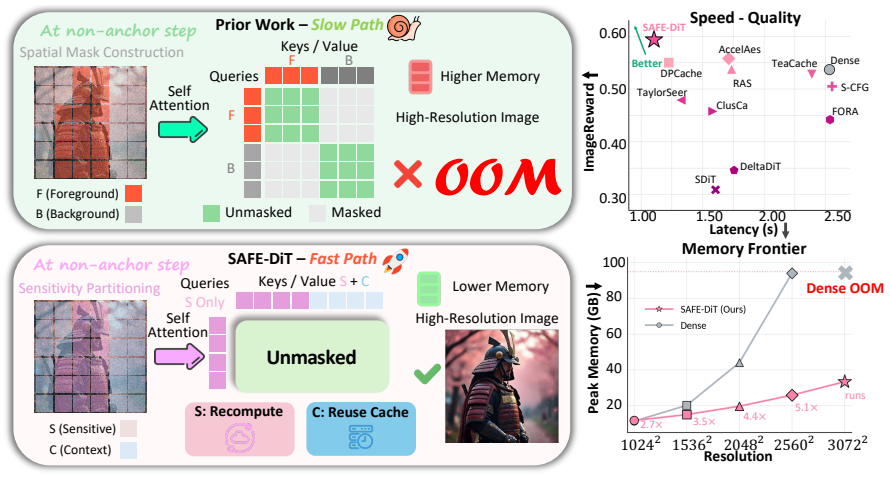
SAFE-DiT accelerates high-resolution Diffusion Transformer inference by eliding image self-attention masks that induce only row-wise constant shifts in attention logits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
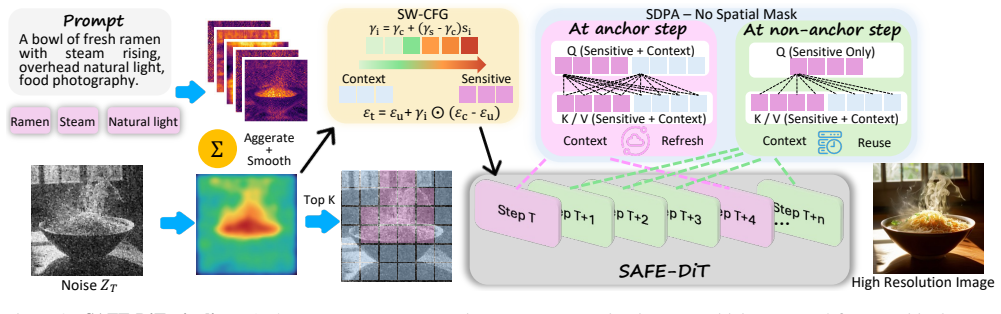
Provenance-certified image self-attention masks that induce only a row-wise constant shift in attention logits can be removed without semantic loss, text-padding masks are preserved, and spatial adaptation is realized via prompt-conditioned token partitioning, selective state updates with global context, and periodic context refresh, delivering up to 5.09 times acceleration and enabling 3072 squared generation.
What carries the argument
Exact elision of constant-shift image self-attention masks together with prompt-conditioned token partitioning and selective state updates.
If this is right
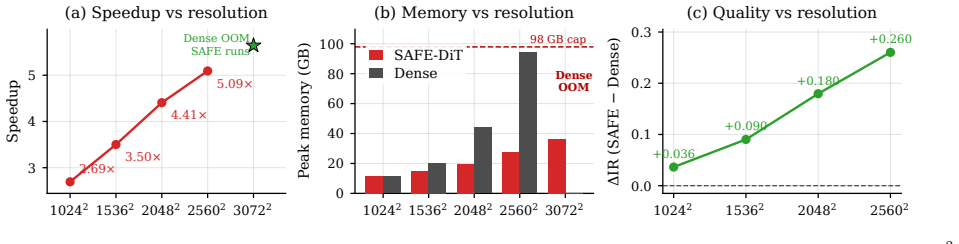
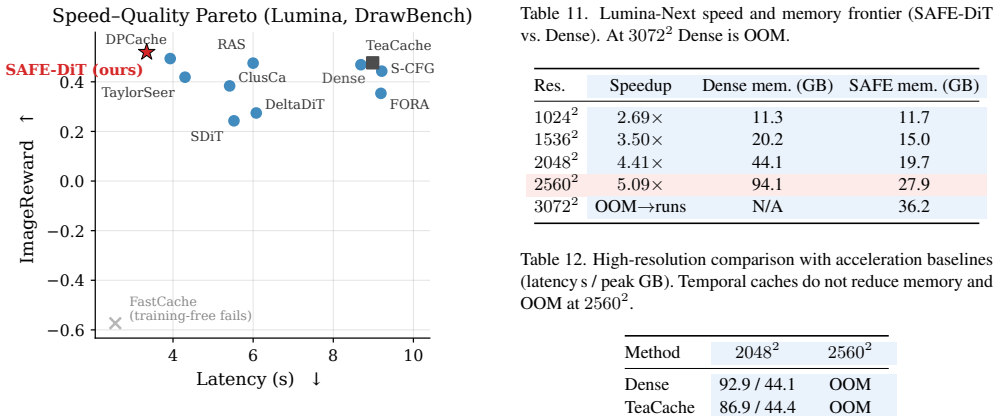
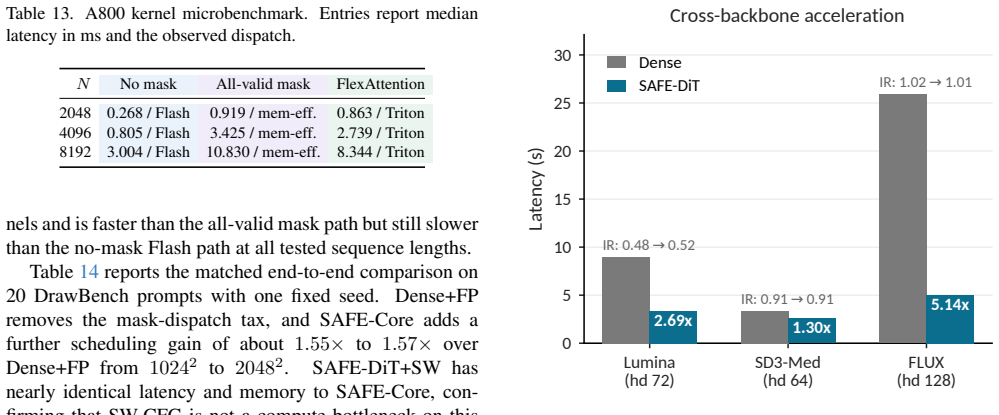
- End-to-end acceleration reaches 2.69 times at 1024 squared resolution on Lumina-Next.
- Acceleration reaches 5.09 times at 2560 squared resolution while peak memory falls from 94.1 GB to 27.9 GB.
- Generation at 3072 squared becomes feasible when dense inference exceeds available memory.
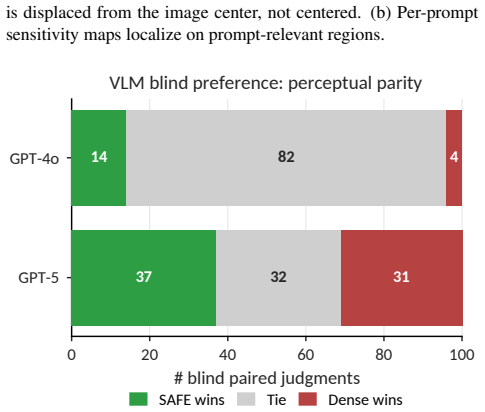
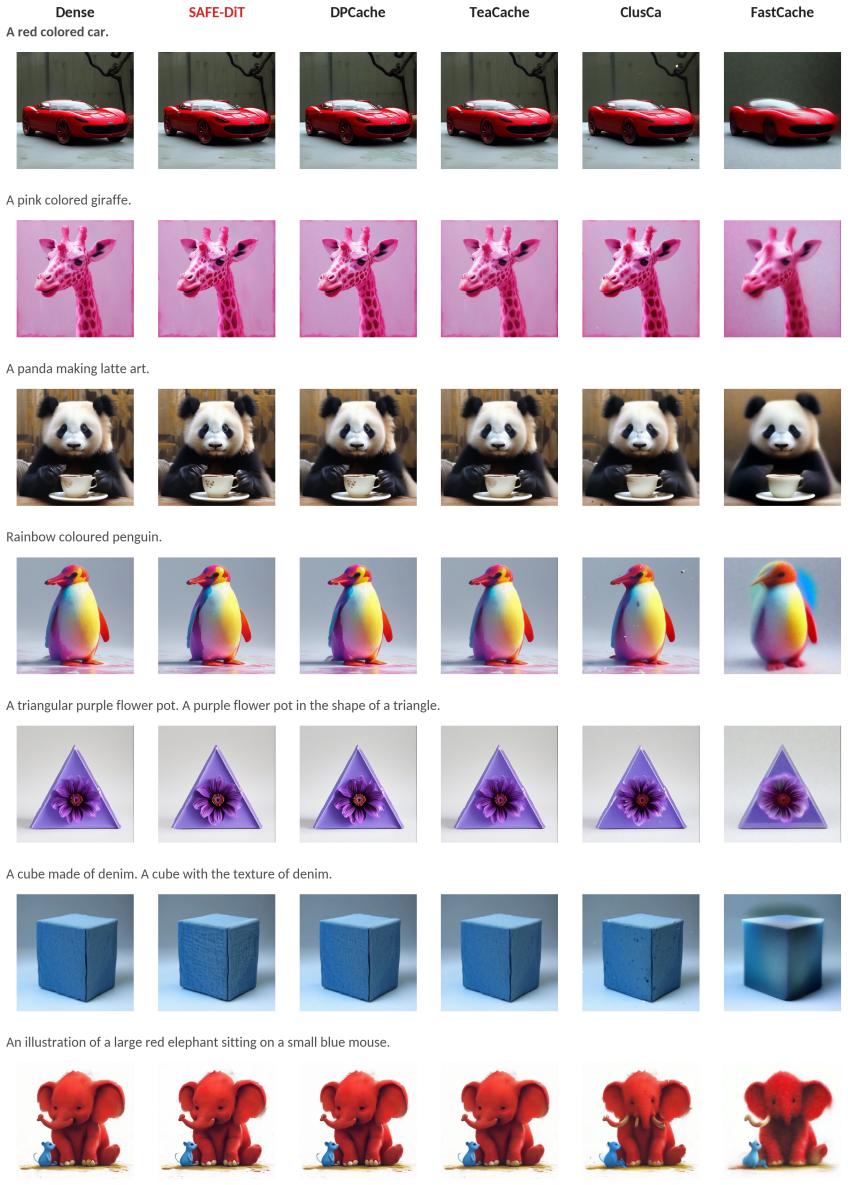
- Metrics, component ablations, and a blinded human study indicate visual non-inferiority to the dense fast-path baseline.
Where Pith is reading between the lines
- The same mask-elision test could be applied to other DiT architectures to identify which attention masks are safe to drop.
- The selective state-update schedule might be made prompt-dependent to further reduce compute on simple scenes.
- Periodic context refresh rate offers a tunable knob between speed and long-range coherence that could be optimized per model size.
Load-bearing premise
Image self-attention masks that add only a constant shift to each row of attention logits can be dropped without changing the semantic content of the generated images.
What would settle it
Generate paired images from the same prompt and seed with the masks present versus removed, then test whether a standard perceptual similarity score drops below the paper's non-inferiority threshold or whether blinded human raters detect a difference.
Figures


read the original abstract
High-resolution Diffusion Transformer (DiT) inference contains substantial spatial redundancy, but many spatially adaptive implementations encode regional computation as attention masks, which can inadvertently move scaled dot-product attention (SDPA) away from FlashAttention fast paths. We identify this avoidable systems bottleneck as Mask-Induced Dispatch Tax (MIDT) and show that it grows with latent sequence length. We introduce SAFE-DiT, a training-free Semantics-Aware Fast-path Execution framework that separates exact mask elision from approximation-based spatial scheduling. SAFE-DiT removes only provenance-certified image self-attention masks that induce a row-wise constant shift in attention logits, preserves semantics-bearing masks such as text-padding masks, and realizes spatial adaptation through prompt-conditioned token partitioning, selective state updates with global context, and periodic context refresh. We call this acceleration-only configuration SAFE-Core and report sensitivity-weighted classifier-free guidance separately as SAFE-DiT+SW. On the evaluated PyTorch SDPA stack, redundant masks make long-sequence attention $4.1\times$ to $5.8\times$ slower than the mask-free path. On Lumina-Next, SAFE-DiT achieves $2.69\times$ end-to-end acceleration at $1024^2$ resolution and $5.09\times$ at $2560^2$, reduces peak memory at $2560^2$ from 94.1 to 27.9 GB, and enables $3072^2$ generation when dense inference runs out of memory. Paired metrics, component ablations, and a blinded human study support visual non-inferiority of SAFE-Core to the dense fast-path baseline, while SAFE-DiT+SW provides a separate prompt-alignment operating point without reintroducing spatial self-attention masks. Code is available at https://github.com/xuanhuayin/SAFE-DiT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAFE-DiT, a training-free framework for high-resolution Diffusion Transformer inference that identifies Mask-Induced Dispatch Tax (MIDT) arising from attention masks that divert SDPA from FlashAttention fast paths. It separates exact elision of provenance-certified image self-attention masks (which induce only row-wise constant logit shifts) from approximation-based spatial scheduling via prompt-conditioned token partitioning, selective state updates with global context, and periodic refresh. On Lumina-Next it reports 2.69× end-to-end speedup at 1024² and 5.09× at 2560², memory reduction from 94.1 GB to 27.9 GB at 2560², and the ability to run 3072² when dense inference OOMs; ablations, paired metrics, and a blinded human study are cited to support visual non-inferiority of the SAFE-Core configuration.
Significance. If the empirical quality claims hold, the work offers a practical, systems-level improvement for DiT inference that preserves the FlashAttention fast path while enabling higher resolutions on constrained hardware. The explicit separation of exact mask elision from approximation-based scheduling, together with public code, strengthens reproducibility and potential adoption.
major comments (2)
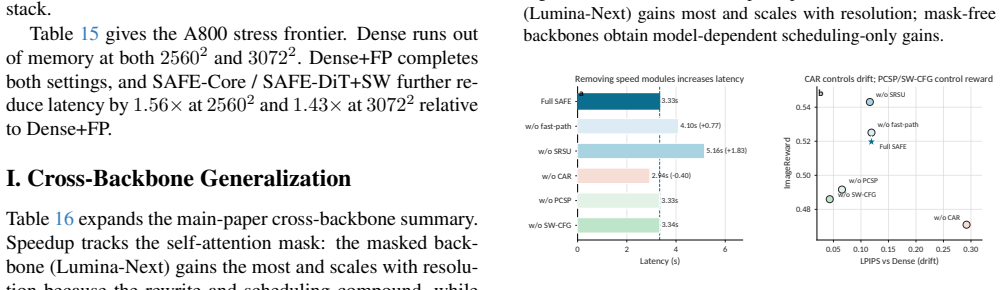
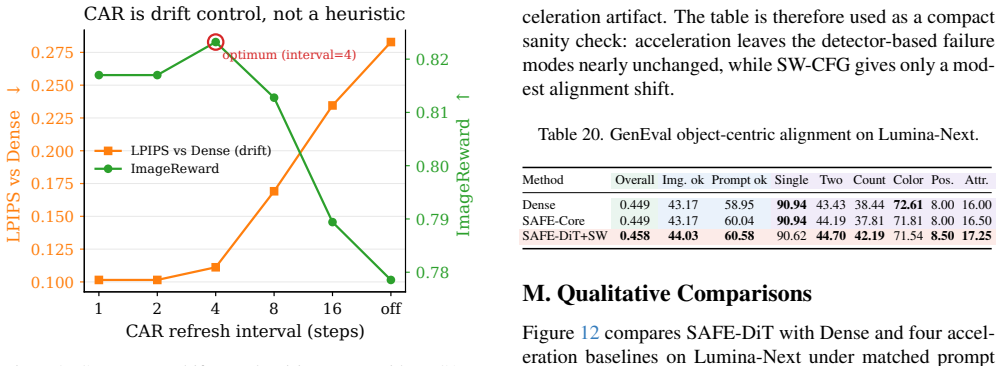
- [§4] §4 (spatial scheduling): the selective state updates with periodic global-context refresh constitute an approximation whose semantic fidelity is asserted via ablations and human study, yet no worst-case bound or drift analysis is supplied for arbitrary prompts in long-sequence, high-resolution regimes; this is load-bearing for the non-inferiority claim.
- [Human Study] Human-study section: the blinded study is invoked to support non-inferiority, but the manuscript provides no details on participant count, prompt selection, rating protocol, or statistical power, preventing assessment of whether the evidence is sufficient to underwrite the central quality-preservation claim.
minor comments (3)
- [§3] The abstract states that redundant masks make long-sequence attention 4.1×–5.8× slower; the corresponding measurement protocol and hardware stack should be stated explicitly in §3 or the experimental section.
- [§3] Notation for the row-wise constant logit shift induced by elided masks should be formalized with an equation to make the invariance argument fully precise.
- The distinction between SAFE-Core and SAFE-DiT+SW should be summarized in a single table or paragraph early in the paper for reader orientation.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the detailed comments. We address each major point below.
read point-by-point responses
-
Referee: [§4] §4 (spatial scheduling): the selective state updates with periodic global-context refresh constitute an approximation whose semantic fidelity is asserted via ablations and human study, yet no worst-case bound or drift analysis is supplied for arbitrary prompts in long-sequence, high-resolution regimes; this is load-bearing for the non-inferiority claim.
Authors: We acknowledge that selective state updates with periodic refresh form an approximation. The design intentionally uses prompt-conditioned partitioning and periodic full-context refresh to limit semantic drift, and the manuscript already includes ablations that vary the refresh interval and measure impact on FID, CLIP score, and human preference. Deriving a general worst-case bound on drift for arbitrary prompts is difficult because diffusion trajectories depend on the stochastic sampler, the specific prompt semantics, and the interaction between text and image tokens; such analysis would require assumptions that do not hold across the broad prompt distribution used in practice. We therefore rely on the empirical evidence already presented and do not plan to add a theoretical bound. revision: no
-
Referee: [Human Study] Human-study section: the blinded study is invoked to support non-inferiority, but the manuscript provides no details on participant count, prompt selection, rating protocol, or statistical power, preventing assessment of whether the evidence is sufficient to underwrite the central quality-preservation claim.
Authors: We agree that the human-study protocol details were omitted. In the revised manuscript we will add the number of participants, the prompt-selection procedure, the exact rating interface and scale, the blinding procedure, and the statistical tests (including power analysis) used to support the non-inferiority conclusion. revision: yes
Circularity Check
No circularity: empirical systems technique with measured speedups and ablations, not derived predictions.
full rationale
The paper presents SAFE-DiT as a training-free implementation framework separating exact mask elision (proven invariant under row-wise logit shift) from approximation-based scheduling. Reported accelerations (2.69× at 1024², 5.09× at 2560²) and memory reductions are direct runtime measurements on PyTorch SDPA, not outputs of any fitted model or self-referential equation. Quality claims rest on component ablations and a blinded human study rather than a closed derivation. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the provided text. The work is self-contained as an engineering optimization whose correctness is externally verifiable by reproduction on the released code.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18208–18218, 2022. 3
2022
-
[2]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Ait- tala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Kar- ras, and Ming-Yu Liu. eDiff-I: Text-to-image diffusion mod- els with an ensemble of expert denoisers.arXiv preprint arXiv:2211.01324, 2022. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
All are worth words: A ViT back- bone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A ViT back- bone for diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22669–22679, 2023. 3
2023
-
[4]
Multidiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation. InInternational Conference on Machine Learn- ing (ICML), 2023. 1, 3
2023
-
[5]
FLUX.1 models, 2024
Black Forest Labs. FLUX.1 models, 2024. 6
2024
-
[6]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4), 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4), 2023. 1, 3, 5
2023
-
[7]
Pixart-σ: Weak-to-strong training of dif- fusion transformer for 4k text-to-image generation
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-σ: Weak-to-strong training of dif- fusion transformer for 4k text-to-image generation. InEuro- pean Conference on Computer Vision (ECCV), 2024. 1, 3, 6
2024
-
[8]
Pixart-α: Fast training of diffusion trans- former for photorealistic text-to-image synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-α: Fast training of diffusion trans- former for photorealistic text-to-image synthesis. InInter- national Conference on Learning Representations (ICLR),
- [9]
-
[10]
Denoising as path planning: Training-free acceler- ation of diffusion models with DPCache
Bowen Cui, Yuanbin Wang, Huajiang Xu, Biaolong Chen, Aixi Zhang, Hao Jiang, Zhengzheng Jin, Xu Liu, and Pipei Huang. Denoising as path planning: Training-free acceler- ation of diffusion models with DPCache. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 3, 7
2026
-
[11]
FlashAttention-2: Faster attention with better par- allelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better par- allelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024. 2, 3, 6
2024
-
[12]
Fu, Stefano Ermon, Atri Rudra, and Christopher R´e
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher R´e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), pages 16344– 16359, 2022. 2, 3, 6
2022
-
[13]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. InAdvances in Neural In- formation Processing Systems (NeurIPS), 2021. 1, 3
2021
-
[14]
FlexAttention: A programming model for generating fused attention variants
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. FlexAttention: A programming model for generating fused attention variants. InProceedings of Ma- chine Learning and Systems (MLSys), 2025. 2, 3
2025
-
[15]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions (ICLR), 2021. 1, 3
2021
-
[16]
Scaling rec- tified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rec- tified flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Ma- chine Learning...
2024
-
[17]
Lumina-T2X: Scalable flow-based large diffusion transformer for flexible resolution generation
Peng Gao, Le Zhuo, Dongyang Liu, Ruoyi Du, Xu Luo, Longtian Qiu, Yuhang Zhang, Rongjie Huang, Shijie Geng, Renrui Zhang, Junlin Xie, Wenqi Shao, Zhengkai Jiang, Tianshuo Yang, Weicai Ye, Tong He, Jingwen He, Junjun He, Yu Qiao, and Hongsheng Li. Lumina-T2X: Scalable flow-based large diffusion transformer for flexible resolution generation. InInternational...
2025
-
[18]
GenEval: An object-focused framework for evaluating text- 9 to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. GenEval: An object-focused framework for evaluating text- 9 to-image alignment. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2023. 6
2023
-
[19]
Prompt-to-prompt image editing with cross-attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross-attention control. InInternational Confer- ence on Learning Representations (ICLR), 2023. 1, 3, 5
2023
-
[20]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Jain, and Pieter Abbeel
Jonathan Ho, Ajay N. Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Infor- mation Processing Systems, pages 6840–6851, 2020. 1, 3
2020
-
[22]
T2I-CompBench: A comprehensive benchmark for open-world compositional text-to-image generation
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xi- hui Liu. T2I-CompBench: A comprehensive benchmark for open-world compositional text-to-image generation. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[23]
GLIGEN: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. GLIGEN: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 22511–22521,
-
[24]
Snap- Fusion: Text-to-image diffusion model on mobile devices within two seconds
Yanyu Li, Huan Wang, Qing Jin, Ju Hu, Pavlo Chemerys, Yun Fu, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Snap- Fusion: Text-to-image diffusion model on mobile devices within two seconds. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2023. 3
2023
-
[25]
SDiT: Semantic region-adaptive for diffusion transformers.arXiv preprint arXiv:2601.12283, 2026
Bowen Lin, Fanjiang Ye, Yihua Liu, Zhenghui Guo, Boyuan Zhang, Weijian Zheng, Yufan Xu, Tiancheng Xing, Yuke Wang, and Chengming Zhang. SDiT: Semantic region-adaptive for diffusion transformers.arXiv preprint arXiv:2601.12283, 2026. 3, 7
-
[26]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. In European Conference on Computer Vision (ECCV), pages 740–755, 2014. 6
2014
-
[27]
Dong Liu, Yanxuan Yu, Jiayi Zhang, Yifan Li, Ben Lengerich, and Ying Nian Wu. FastCache: Fast caching for diffusion transformer through learnable linear approxi- mation.arXiv preprint arXiv:2505.20353, 2025. 3, 7
-
[28]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[29]
From reusing to forecasting: Accelerat- ing diffusion models with taylorseers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerat- ing diffusion models with taylorseers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15853–15863, 2025. 3, 7
2025
-
[30]
Region-adaptive sampling for diffusion transformers
Ziming Liu, Yifan Yang, Chengruidong Zhang, Yiqi Zhang, Lili Qiu, Yang You, and Yuqing Yang. Region-adaptive sampling for diffusion transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 3, 6, 7
2026
-
[31]
DPM-Solver: A fast ODE solver for diffu- sion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffu- sion probabilistic model sampling in around 10 steps. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[32]
DPM-Solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Machine Intelligence Research, 22:730–751, 2025
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Machine Intelligence Research, 22:730–751, 2025. 3
2025
-
[33]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high- resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
DeepCache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. DeepCache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15762–15772, 2024. 1, 3
2024
-
[35]
SDEdit: Guided image synthesis and editing with stochastic differential equa- tions
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jia- jun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equa- tions. InInternational Conference on Learning Representa- tions (ICLR), 2022. 3
2022
-
[36]
GLIDE: Towards photorealis- tic image generation and editing with text-guided diffusion models
Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards photorealis- tic image generation and editing with text-guided diffusion models. InProceedings of the 39th International Conference on Machine Learning (ICML), pages 16784–16804. PMLR,
-
[37]
Scalable diffusion mod- els with transformers
William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 1, 3
2023
-
[38]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InInternational Con- ference on Learning Representations (ICLR), 2024. 1, 3
2024
-
[39]
PyTorch, 2026
PyTorch Contributors.PyTorch Documentation: Scaled Dot Product Attention. PyTorch, 2026. 2, 3, 6
2026
-
[40]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with CLIP latents.arXiv preprint arXiv:2204.06125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 1, 3
2022
-
[42]
Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, Jonathan Ho, David J
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep lan- guage understanding. InAdvances in Neural Information Processing Systems (NeurIPS)...
2022
-
[43]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Confer- ence on Learning Representations (ICLR), 2022. 3
2022
-
[44]
Fast high- resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high- resolution image synthesis with latent adversarial diffusion distillation. InACM SIGGRAPH Asia Conference Papers (SIGGRAPH Asia), 2024. 3
2024
-
[45]
arXiv preprint arXiv:2407.01425 (2024)
Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang. FORA: Fast-forward caching in diffusion transformer acceleration.arXiv preprint arXiv:2407.01425,
-
[46]
FlashAttention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[47]
Rethinking the spatial inconsistency in classifier- free diffusion guidance
Dazhong Shen, Guanglu Song, Zeyue Xue, Fu-Yun Wang, and Yu Liu. Rethinking the spatial inconsistency in classifier- free diffusion guidance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9370–9379, 2024. 1, 3, 7
2024
-
[48]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021. 1, 3
2021
-
[49]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InInternational Conference on Machine Learning (ICML), 2023. 1, 3
2023
-
[50]
What the DAAM: Interpreting stable dif- fusion using cross attention
Raphael Tang, Linqing Liu, Akshat Pandey, Zhiying Jiang, Gefei Yang, Karun Kumar, Pontus Stenetorp, Jimmy Lin, and Ferhan Ture. What the DAAM: Interpreting stable dif- fusion using cross attention. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 5644–5659, 2023. 1, 3, 5
2023
-
[51]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. 1, 3
2017
-
[52]
FlashMask: Efficient and rich mask ex- tension of FlashAttention
Guoxia Wang, Jinle Zeng, Xiyuan Xiao, Siming Wu, Jiabin Yang, Lujing Zheng, Zeyu Chen, Jiang Bian, Dianhai Yu, and Haifeng Wang. FlashMask: Efficient and rich mask ex- tension of FlashAttention. InInternational Conference on Learning Representations (ICLR), 2025. 2, 3
2025
-
[53]
Cache me if you can: Accelerating diffusion models through block caching
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, Christian Rupprecht, Daniel Cre- mers, Peter Vajda, and Jialiang Wang. Cache me if you can: Accelerating diffusion models through block caching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Rec...
-
[54]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
ImageRe- ward: Learning and evaluating human preferences for text- to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. ImageRe- ward: Learning and evaluating human preferences for text- to-image generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 2, 6
2023
-
[56]
AccelAes: Accelerating Diffusion Transformers for Training-Free Aesthetic-Enhanced Image Generation
Xuanhua Yin, Chuanzhi Xu, Haoxian Zhou, Boyu Wei, and Weidong Cai. AccelAes: Accelerating diffusion transform- ers for training-free aesthetic-enhanced image generation. arXiv preprint arXiv:2603.12575, 2026. 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Scaling autoregressive models for content-rich text-to-image generation.Transactions on Machine Learn- ing Research, 2022
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gun- jan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yin- fei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation.Transactions on Machine Learn- ing Research, 2022. 3, 6
2022
-
[58]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023. 1, 3
2023
-
[59]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 586–595, 2018. 6
2018
-
[60]
Compute only 16 tokens in one timestep: Accelerating diffusion transformers with cluster-driven fea- ture caching
Zhixin Zheng, Xinyu Wang, Chang Zou, Shaobo Wang, and Linfeng Zhang. Compute only 16 tokens in one timestep: Accelerating diffusion transformers with cluster-driven fea- ture caching. InProceedings of the ACM International Con- ference on Multimedia (ACM MM), pages 10181–10189,
-
[61]
complementary
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Lin- feng Zhang. Accelerating diffusion transformers with token- wise feature caching. InInternational Conference on Learn- ing Representations (ICLR), 2025. 3 11 Appendix Overview This appendix provides the full experimental record behind the main paper: the component-level relation to the closest spatia...
2025
-
[62]
Target” and “reference
Text encoding, V AE decoding, and post-processing stay small and stable (∼0.03 / 0.13 / 0.02 s), and the sched- uler/PCSP overhead is 0.16 to 0.26 s. G. High-Resolution Frontier Table 11 gives the full numeric frontier on Lumina-Next, and Table 12 adds the strongest acceleration baselines. Temporal caches skip steps but still materialize full atten- tion ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.