Cross-Temporal Sinhala OCR: Page-Level Adaptation and Diachronic Analysis
Pith reviewed 2026-06-30 07:34 UTC · model grok-4.3
The pith
Fine-tuned LightOnOCR-2-1B reaches 1.05% CER on real Sinhala legislative pages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
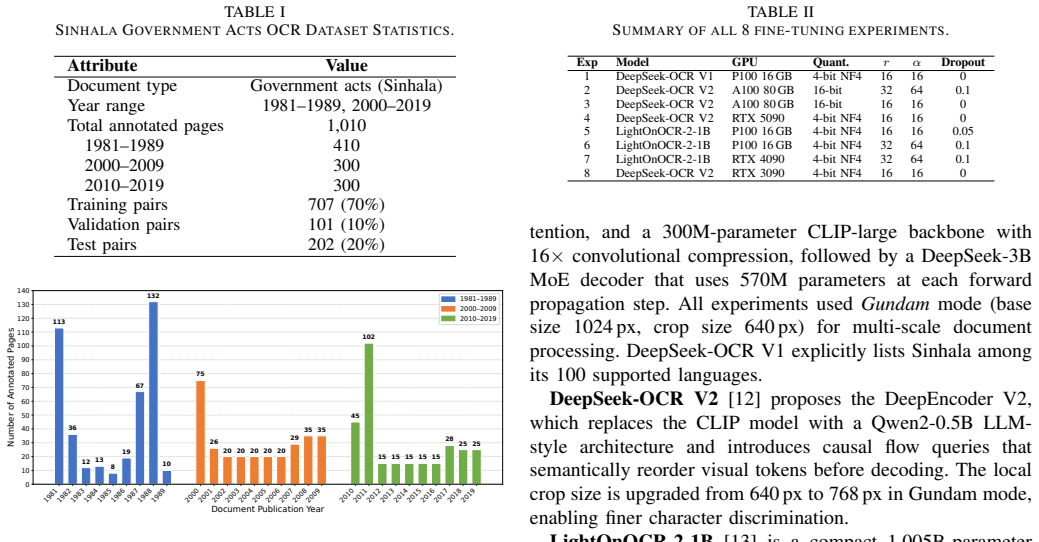
After fine-tuning on the new sinhala-ocr-lk-acts-1010 collection of 1,010 page-level images and transcriptions, LightOnOCR-2-1B attains a CER of 1.05 percent across the 202 test pages, outperforming Surya-OCR at 8.84 percent, Tesseract v5 at 10.69 percent, and Google Document AI at 2.06 percent while preserving that accuracy level on both the 1981-1989 and 2000-2019 subsets.
What carries the argument
QLoRA fine-tuning of the LightOnOCR-2-1B visual-language model on the 707 training pages of the sinhala-ocr-lk-acts-1010 dataset.
If this is right
- Page-level real data removes the need to rely on synthetic Sinhala text for model development.
- A single fine-tuned model can handle documents printed decades apart without retraining.
- Character error rates below 2 percent become achievable for this abugida script with modest compute.
- The released dataset supports direct comparison of future OCR systems on the same authentic material.
Where Pith is reading between the lines
- The same adaptation recipe could be tested on other morphologically rich scripts that currently lack page-level benchmarks.
- If the model truly ignores print-era artifacts, it may also tolerate moderate scanning noise or font variation within the same script family.
- Extending the test set to include mixed-language or partially handwritten pages would reveal remaining failure modes.
Load-bearing premise
The 1,010 pages drawn from two specific print eras of legislative acts capture the full range of real-world Sinhala OCR conditions.
What would settle it
A new test collection of Sinhala pages from newspapers or non-legislative sources on which the same fine-tuned model exceeds 5 percent CER would falsify the reported generalization.
Figures



read the original abstract
Sinhala is a morphologically rich abugida spoken by roughly 16 million people in Sri Lanka, and to date, there are no publicly available real-world datasets for page-level Sinhala OCR. All previous studies for assessing Sinhala OCR models have used artificially generated data. To bridge the gap, we introduce sinhala-ocr-lk-acts-1010, an annotated dataset of 1,010 page-level images and their transcriptions collected from Sri Lankan Legislative Acts published between 1981-1989 and 2000-2019, split into 707 training examples, 101 validation examples, and 202 testing examples. Three models based on deep learning-based visual language processing, namely DeepSeek-OCR V1, DeepSeek-OCR V2, and LightOnOCR-2-1B, are fine-tuned using QLoRA in 8 experiments conducted on consumer and cloud GPUs. LightOnOCR-2-1B is the top performer, achieving a CER of 1.05% across all test examples, outperforming state-of-the-art open-source OCR models such as Surya-OCR (8.84%) and Tesseract v5 (10.69%), as well as commercially available OCR models such as Google Document AI (2.06%). Our results suggest that LightOnOCR-2-1B outperforms other baselines on real-world OCR tasks and maintains consistent performance across all print periods, even when documents are severely degraded.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the sinhala-ocr-lk-acts-1010 dataset of 1,010 page-level images and transcriptions from Sri Lankan Legislative Acts (1981-1989 and 2000-2019), divided into 707/101/202 train/val/test splits. It fine-tunes DeepSeek-OCR V1, DeepSeek-OCR V2, and LightOnOCR-2-1B using QLoRA across 8 experiments and reports that LightOnOCR-2-1B achieves a CER of 1.05% on the test set, outperforming Surya-OCR (8.84%), Tesseract v5 (10.69%), and Google Document AI (2.06%). The work claims consistent performance across print eras and applicability to real-world, severely degraded documents.
Significance. If the performance claims hold, the introduction of the first real-world page-level Sinhala OCR dataset is a valuable contribution to low-resource language OCR research. Demonstrating that QLoRA fine-tuning of visual language models can achieve sub-2% CER on printed abugida text from legislative documents could encourage similar adaptation efforts for other under-resourced scripts and support diachronic studies of document quality.
major comments (3)
- [Abstract] The statement that the results apply to 'real-world OCR tasks' and 'severely degraded' documents is not supported by the described evaluation, as the 202 test pages are drawn from the same 1,010-page collection of legislative acts as the training data; no experiments on newspapers, books, or other degradation types are reported.
- [Abstract] The central performance numbers (e.g., CER of 1.05% for LightOnOCR-2-1B) are presented without error bars, statistics from multiple runs, or details on data cleaning and hyperparameter selection, limiting assessment of their robustness.
- [Abstract] The comparisons to Surya-OCR, Tesseract v5, and Google Document AI do not indicate that these baselines received equivalent fine-tuning or domain adaptation, raising the possibility that the reported gaps reflect the effect of QLoRA adaptation rather than intrinsic model differences.
minor comments (1)
- [Abstract] The dataset name 'sinhala-ocr-lk-acts-1010' is introduced without a citation or link to its public availability.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below, agreeing where revisions are needed to clarify scope and add details, while defending the comparison setup as central to the contribution.
read point-by-point responses
-
Referee: [Abstract] The statement that the results apply to 'real-world OCR tasks' and 'severely degraded' documents is not supported by the described evaluation, as the 202 test pages are drawn from the same 1,010-page collection of legislative acts as the training data; no experiments on newspapers, books, or other degradation types are reported.
Authors: We agree the abstract overgeneralizes. The dataset comprises real-world legislative acts from 1981-1989 and 2000-2019 with natural degradation from age and printing; we report consistent CER across these periods on held-out pages. No evaluations on newspapers, books, or other formats were performed. We will revise the abstract to limit claims to legislative acts and add a limitations paragraph on the need for broader domain testing. revision: yes
-
Referee: [Abstract] The central performance numbers (e.g., CER of 1.05% for LightOnOCR-2-1B) are presented without error bars, statistics from multiple runs, or details on data cleaning and hyperparameter selection, limiting assessment of their robustness.
Authors: Results are from single runs across the eight QLoRA experiments. The experimental section describes data cleaning (transcription verification by native speakers) and hyperparameters, but these can be expanded. We will add explicit details on cleaning and hyperparameter selection; multiple runs with error bars will be included if additional compute is feasible, otherwise the single-run nature will be stated clearly. revision: partial
-
Referee: [Abstract] The comparisons to Surya-OCR, Tesseract v5, and Google Document AI do not indicate that these baselines received equivalent fine-tuning or domain adaptation, raising the possibility that the reported gaps reflect the effect of QLoRA adaptation rather than intrinsic model differences.
Authors: The comparison demonstrates the value of QLoRA adaptation on our dataset against off-the-shelf models, which is the standard protocol for domain-adaptation work in low-resource OCR. We will revise the text to explicitly state that baselines were evaluated in default configurations without fine-tuning on sinhala-ocr-lk-acts-1010, thereby highlighting the adaptation benefit rather than claiming intrinsic superiority. revision: no
Circularity Check
No circularity; empirical results on held-out test split from new dataset
full rationale
The paper creates a new annotated dataset of 1,010 pages from Sri Lankan Legislative Acts, splits it into 707/101/202 train/val/test, fine-tunes three models via QLoRA, and reports CER on the held-out test pages. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes reduce the 1.05% CER (or baseline comparisons) to a definitional identity or input by construction. Evaluation follows standard ML practice with independent test data; claims of generalization are scope-limited but not circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zero-shot OCR accuracy of low-resourced languages: A comparative analysis on Sinhala and Tamil,
N. Jayatilleke and N. de Silva, “Zero-shot OCR accuracy of low-resourced languages: A comparative analysis on Sinhala and Tamil,” inProceedings of the 15th International Conference on Recent Advances in Natural Language Processing - Natural Language Processing in the Generative AI Era, G. Angelova, M. Kunilovskaya, M. Escribe, and R. Mitkov, Eds. Varna, B...
2025
-
[2]
Deep learning based sinhala optical character recognition (OCR),
I. Anuradha, C. Liyanage, H. Wijayawardhana, and R. Weerasinghe, “Deep learning based sinhala optical character recognition (OCR),” in 2020 20th International Conference on Advances in ICT for Emerging Regions (ICTer). IEEE, 2020, pp. 298–299. [Online]. Available: https://ieeexplore.ieee.org/document/9325428/
-
[3]
C. Vasantharajan, L. Tharmalingam, and U. Thayasivam, “Adapting the tesseract open-source OCR engine for tamil and sinhala legacy fonts and creating a parallel corpus for tamil-sinhala- english,” in2022 International Conference on Asian Language Processing (IALP). IEEE, 2022, pp. 143–149. [Online]. Available: https://ieeexplore.ieee.org/document/9961304/
-
[4]
Benchmarking OCR models for sinhala and tamil document digitization,
Purushoth Velayuthan and Thanuja D Ambegoda, “Benchmarking OCR models for sinhala and tamil document digitization,” 2025. [Online]. Available: https://rgdoi.net/10.13140/RG.2.2.20843.25129
-
[5]
TrOCR: Transformer-based optical character recognition with pre-trained models,
M. Li, T. Lv, J. Chen, L. Cui, Y . Lu, D. Florencio, C. Zhang, Z. Li, and F. Wei, “TrOCR: Transformer-based optical character recognition with pre-trained models,” vol. 37, no. 11, pp. 13 094–13 102, 2023. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/26538
2023
-
[6]
KOSMOS-2.5: A multimodal literate model,
T. Lv, Y . Huang, J. Chen, Y . Zhao, Y . Jia, L. Cui, S. Ma, Y . Chang, S. Huang, W. Wang, L. Dong, W. Luo, S. Wu, G. Wang, C. Zhang, and F. Wei, “KOSMOS-2.5: A multimodal literate model,” 2024. [Online]. Available: http://arxiv.org/abs/2309.11419
-
[7]
QLORA: Efficient finetuning of quantized LLMs
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLORA: Efficient finetuning of quantized LLMs.”
-
[8]
Nayana OCR: A scalable framework for document OCR in low-resource languages,
A. Kolavi, S. P, and V . Jain, “Nayana OCR: A scalable framework for document OCR in low-resource languages,” inProceedings of the 1st Workshop on Language Models for Underserved Communities (LM4UC 2025), S. Truong, R. A. Putri, D. Nguyen, A. Wang, D. Ho, A. Oh, and S. Koyejo, Eds. Albuquerque, New Mexico: Association for Computational Linguistics, May 20...
2025
-
[9]
Estimating the effects of text genre, image resolution and algorithmic complexity needed for sinhala optical character recognition,
I. Anuradha, C. Liyanage, and R. Weerasinghe, “Estimating the effects of text genre, image resolution and algorithmic complexity needed for sinhala optical character recognition,” vol. 14, no. 3, pp. 43–51, 2021. [Online]. Available: https://account.icter.sljol.info/index. php/sljo-j-ijaicterict/article/view/7231
2021
-
[10]
OCR with tesseract, amazon textract, and google document AI: a benchmarking experiment,
T. Hegghammer, “OCR with tesseract, amazon textract, and google document AI: a benchmarking experiment,” vol. 5, no. 1, pp. 861–882, 2021. [Online]. Available: https://link.springer.com/10.1007/ s42001-021-00149-1
2021
-
[11]
DeepSeek-OCR: Contexts Optical Compression
H. Wei, Y . Sun, and Y . Li, “DeepSeek-OCR: Contexts optical compression,” 2025. [Online]. Available: http://arxiv.org/abs/2510.18234
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
DeepSeek-OCR 2: Visual causal flow,
H. Wei, Y . Sun, and Y . Li, “DeepSeek-OCR 2: Visual causal flow,”arXiv preprint arXiv:2601.20552, 2026
-
[13]
LightOnOCR: A 1b end-to-end multilingual vision-language model for state-of-the-art OCR,
S. Taghadouini, A. Cavaill `es, and B. Aubertin, “LightOnOCR: A 1b end-to-end multilingual vision-language model for state-of-the-art OCR,” 2026. [Online]. Available: http://arxiv.org/abs/2601.14251
work page internal anchor Pith review arXiv 2026
-
[14]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,”
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
[Online]. Available: http://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
U. Springmann and A. L ¨udeling, “OCR of historical printings with an application to building diachronic corpora: A case study using the RIDGES herbal corpus,” 2017. [Online]. Available: http://arxiv.org/abs/1608.02153
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Chronicling germany: An annotated historical newspaper dataset,
C. Schultze, N. Kerkfeld, K. Kuebart, P. Weber, M. Wolter, and F. Selgert, “Chronicling germany: An annotated historical newspaper dataset,” 2025. [Online]. Available: http://arxiv.org/abs/2401.16845
-
[18]
An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,
B. Shi, X. Bai, and C. Yao, “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,”IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 11, pp. 2298–2304, 2016
2016
-
[19]
ASTER: An attentional scene text recognizer with flexible rectification,
B. Shi, M. Yang, X. Wang, P. Lyu, C. Yao, and X. Bai, “ASTER: An attentional scene text recognizer with flexible rectification,” vol. 41, no. 9, pp. 2035–2048, 2019. [Online]. Available: https: //ieeexplore.ieee.org/document/8395027/
-
[20]
Robust scene text recognition with automatic rectification,
B. Shi, X. Wang, P. Lyu, C. Yao, and X. Bai, “Robust scene text recognition with automatic rectification,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4168– 4176
2016
-
[21]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[22]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021
2021
-
[23]
East: an efficient and accurate scene text detector,
X. Zhou, C. Yao, H. Wen, Y . Wang, S. Zhou, W. He, and J. Liang, “East: an efficient and accurate scene text detector,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 5551–5560
2017
-
[24]
Character region awareness for text detection,
Y . Baek, B. Lee, D. Han, S. Yun, and H. Lee, “Character region awareness for text detection,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019, pp. 9357–9366. [Online]. Available: https://ieeexplore.ieee.org/document/ 8953846/
2019
-
[25]
PhotoOCR: Reading text in uncontrolled conditions,
A. Bissacco, M. Cummins, Y . Netzer, and H. Neven, “PhotoOCR: Reading text in uncontrolled conditions,” in2013 IEEE International Conference on Computer Vision. IEEE, 2013, pp. 785–792. [Online]. Available: http://ieeexplore.ieee.org/document/6751207/
-
[26]
A concise survey of OCR for low- resource languages,
M. Agarwal and A. Anastasopoulos, “A concise survey of OCR for low- resource languages,” inProceedings of the 4th Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP 2024). Association for Computational Linguistics, 2024, pp. 88–102. [Online]. Available: https://aclanthology.org/2024. americasnlp-1.10
2024
-
[27]
J. Baek, Y . Matsui, and K. Aizawa, “What if we only use real datasets for scene text recognition? toward scene text recognition with fewer labels,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021. [Online]. Available: https://ieeexplore.ieee.org/document/9578847/
-
[28]
Why stop at words? unveiling the bigger picture through line-level OCR,
S. Vempati, N. Anand, G. Talebailkar, A. Garai, and C. Arora, “Why stop at words? unveiling the bigger picture through line-level OCR,”
-
[29]
Available: http://arxiv.org/abs/2508.21693
[Online]. Available: http://arxiv.org/abs/2508.21693
-
[30]
Benchmarking vision-language models on chinese ancient documents: From OCR to knowledge reasoning,
H. Yu, Y . Wu, F. Shi, L. Liao, J. Lu, X. Ge, H. Wang, M. Zhuo, X. Wu, X. Fei, H. Feng, G. Tang, A.-L. Wang, H. Zhu, Y . He, Q. Liang, L. Meng, C. Feng, C. Huang, J. Tang, and B. Li, “Benchmarking vision-language models on chinese ancient documents: From OCR to knowledge reasoning,” 2025. [Online]. Available: http://arxiv.org/abs/2509.09731
-
[31]
Sri Lanka Document Datasets: A Large-Scale, Multilingual Resource for Law, News, and Policy
N. I. Senaratna, “Sri lanka document datasets: A large-scale, multilingual resource for law, news, and policy,” 2025. [Online]. Available: http://arxiv.org/abs/2510.04124
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.