Randomized neural operator for parametric PDEs with fast training and conformal uncertainty quantification
Pith reviewed 2026-06-30 08:03 UTC · model grok-4.3
The pith
PCA--RaNN recasts parametric PDE operator learning as fixed-feature linear regression to cut training time by one to three orders of magnitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
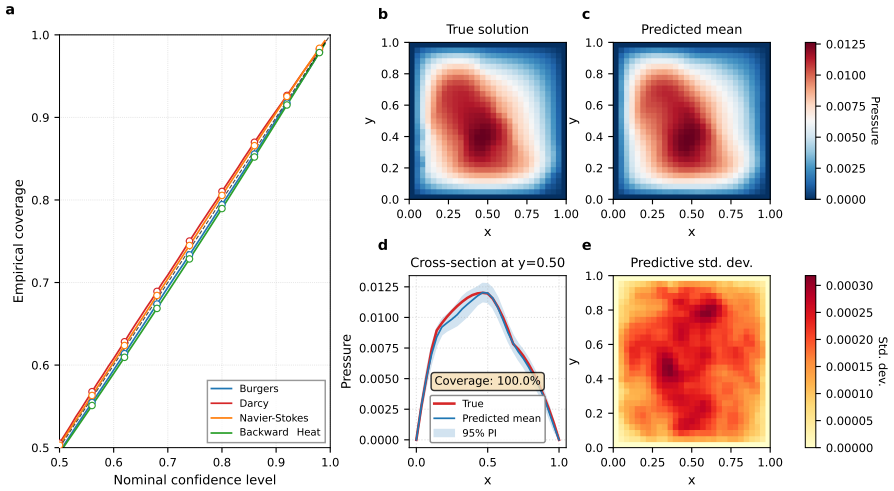
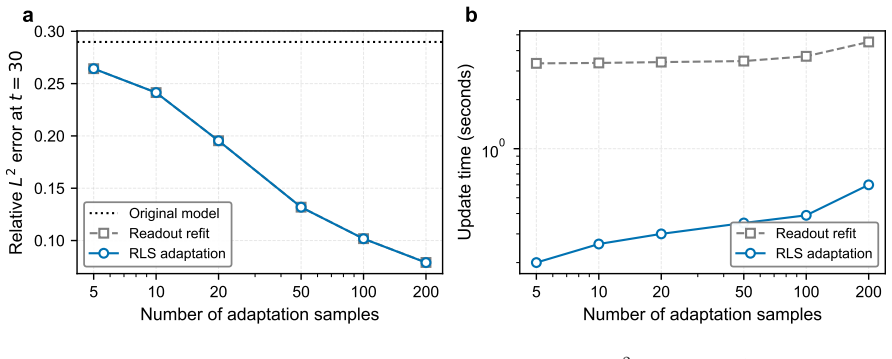
PCA--RaNN combines PCA-based dimensionality reduction with fixed random features and a closed-form least-squares readout to learn latent operators for parametric PDEs. This recasts the problem as linear regression, enabling training times reduced by one to three orders of magnitude on Burgers, Darcy, Navier-Stokes and backward heat equation problems while maintaining competitive accuracy. An energy-matched scaling rule and lightweight BFGS refinement correct feature scales, ensemble averaging reduces predictive variance, and the linear readout supports split-conformal intervals plus recursive-least-squares online adaptation without retraining hidden features.
What carries the argument
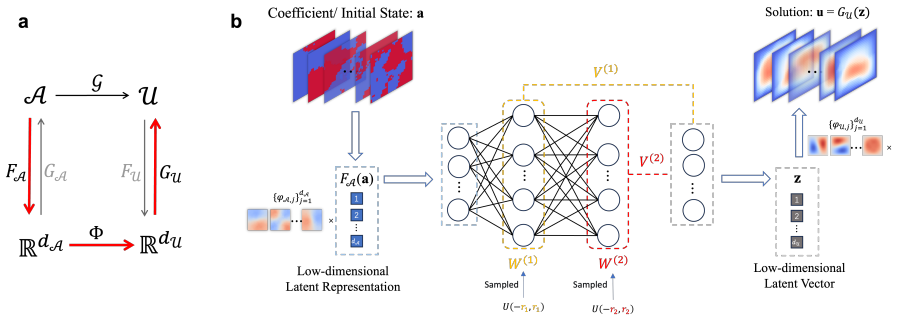
The PCA--RaNN operator, which performs PCA reduction, applies fixed random features, and solves a linear least-squares problem for the readout layer.
If this is right
- Training completes one to three orders of magnitude faster than conventional neural operators on the reported benchmarks.
- Accuracy remains competitive with fully trained neural operators on Burgers, Darcy, Navier-Stokes, and backward heat problems.
- Split-conformal prediction intervals are obtained directly from the ensemble without additional calibration.
- Recursive least squares updates the readout for new data in linear time without retraining the random features.
- Ensemble variance is lowered by simple averaging of independent random-feature realizations.
Where Pith is reading between the lines
- The linear-readout design could be paired with existing fast linear solvers to accelerate repeated forward evaluations inside outer optimization loops.
- Conformal intervals produced by the ensemble may transfer directly to inverse-problem settings that need calibrated uncertainty on inferred parameters.
- Because hidden features stay fixed, the same random-feature bank could be reused across families of related PDEs, enabling cheap transfer without retraining.
Load-bearing premise
PCA reduction plus fixed random features followed by least-squares can approximate the nonlinear mappings required by parametric PDE operators without non-convex neural-network training.
What would settle it
On the Navier-Stokes benchmark, measure whether PCA--RaNN accuracy falls more than a few percent below a trained neural-operator baseline while its wall-clock training time remains at least ten times smaller.
Figures
read the original abstract
Repeatedly solving parametric PDEs is essential for uncertainty quantification, design optimization and inverse problems, but conventional neural operators require expensive non-convex training. We introduce PCA--RaNN, a randomized latent neural operator that combines PCA-based dimensionality reduction with fixed random features and a closed-form least-squares readout. It recasts latent operator learning as fixed-feature linear regression, reducing training time by one to three orders of magnitude across benchmarks while maintaining competitive accuracy. We introduce an energy-matched scaling rule and a lightweight two-parameter BFGS refinement to correct suboptimal feature scales. Ensemble averaging reduces predictive variance. On Burgers, Darcy, Navier--Stokes and backward heat equation benchmarks, PCA--RaNN provides a favorable speed--accuracy trade-off against operator-learning baselines. The ensemble supports split-conformal prediction intervals, and the linear readout enables rapid online adaptation via recursive least squares without retraining hidden features. This provides an efficient, uncertainty-aware surrogate for many-query scientific workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PCA--RaNN, a randomized latent neural operator combining PCA-based dimensionality reduction with fixed random features and a closed-form least-squares readout. It recasts latent operator learning as fixed-feature linear regression, claiming training speedups of one to three orders of magnitude on Burgers, Darcy, Navier--Stokes and backward heat equation benchmarks while maintaining competitive accuracy. Additional contributions include an energy-matched scaling rule, two-parameter BFGS refinement, ensemble-based split-conformal prediction intervals, and rapid online adaptation via recursive least squares without retraining hidden features.
Significance. If the empirical speed-accuracy trade-off and supporting claims hold under standard benchmarks, the work provides a computationally lightweight alternative to non-convex neural operator training. The linear readout structure directly enables conformal uncertainty quantification and recursive least-squares adaptation, which are practically valuable for many-query scientific computing tasks such as UQ and optimization.
minor comments (2)
- The abstract states that the method 'maintains competitive accuracy' on named benchmarks; a brief quantitative summary (e.g., relative L2 errors versus baselines) would strengthen the claim without requiring additional experiments.
- The energy-matched scaling rule and two-parameter BFGS refinement are described as lightweight corrections; their precise definitions and implementation details should be expanded in the methods section to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly identifies the core contributions of PCA-RaNN as a randomized latent neural operator with closed-form training, energy-matched scaling, BFGS refinement, ensemble conformal intervals, and recursive least-squares adaptation. No major comments were raised that require point-by-point rebuttal.
Circularity Check
No significant circularity
full rationale
The central construction is PCA dimensionality reduction followed by fixed random features and closed-form least-squares readout for the latent operator. This is an explicit modeling choice that recasts the problem as linear regression; the resulting speed claims are empirical benchmarks rather than predictions derived from quantities defined in terms of the target result. Conformal intervals and recursive least-squares adaptation follow directly from the linear readout property without self-referential fitting. No self-citation chains, ansatz smuggling, or uniqueness theorems imported from prior author work appear as load-bearing steps. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- energy-matched scaling rule
- two-parameter BFGS refinement
axioms (2)
- domain assumption PCA provides effective dimensionality reduction for the latent representation of PDE operators
- domain assumption Fixed random features can approximate the function space needed for parametric PDE mappings
Reference graph
Works this paper leans on
-
[1]
H., Peri´ c, M
Ferziger, J. H., Peri´ c, M. & Street, R. L.Computational Methods for Fluid Dynamics3rd edn (Springer, Berlin, 2002)
2002
-
[2]
C., Taylor, R
Zienkiewicz, O. C., Taylor, R. L., Nithiarasu, P. & Zhu, J. Z.The Finite Element Method(Elsevier, 2005)
2005
-
[3]
M.The Finite Element Method in Electromagnetics(John Wiley & Sons, 2015)
Jin, J. M.The Finite Element Method in Electromagnetics(John Wiley & Sons, 2015)
2015
-
[4]
& White, H
Hornik, K., Stinchcombe, M. & White, H. Multilayer feedforward networks are universal approxima- tors.Neural Networks2, 359–366 (1989)
1989
-
[5]
& Chen, H
Chen, T. & Chen, H. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems.IEEE Trans. Neural Networks6, 911–917 (1995)
1995
-
[6]
& Chen, H
Chen, T. & Chen, H. Approximation capability to functions of several variables, nonlinear functionals, and operators by radial basis function neural networks.IEEE Trans. Neural Networks6, 904–910 (1995)
1995
-
[7]
& Karniadakis, G
Lu, L., Jin, P., Pang, G., Zhang, Z. & Karniadakis, G. E. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nat. Mach. Intell.3, 218–229 (2021)
2021
-
[8]
Fourier Neural Operator for Parametric Partial Differential Equations
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. & Anandkumar, A. Fourier neural operator for parametric partial differential equations.arXiv preprintarXiv:2010.08895 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. & Anandku- mar, A. Neural operator: graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[10]
& Anandkumar, A
Li, Z., Zheng, H., Kovachki, N., Jin, D., Chen, H., Liu, B., Azizzadenesheli, K. & Anandkumar, A. Physics-informed neural operator for learning partial differential equations.ACM/JMS J. Data Sci. 1, 1–27 (2024)
2024
-
[11]
& Perdikaris, P
Wang, S., Wang, H. & Perdikaris, P. Learning the solution operator of parametric partial differential equations with physics-informed DeepONets.Sci. Adv.7, eabi8605 (2021)
2021
-
[12]
& Anandkumar, A
Azizzadenesheli, K., Kovachki, N., Li, Z., Liu-Schiaffini, M., Kossaifi, J. & Anandkumar, A. Neural operators for accelerating scientific simulations and design.Nat. Rev. Phys.6, 320–328 (2024)
2024
-
[13]
Brunton, S. L. & Kutz, J. N. Promising directions of machine learning for partial differential equations. Nat. Comput. Sci.4, 483–494 (2024)
2024
-
[14]
DeVore, R. A. The theoretical foundation of reduced basis methods. InModel Reduction and Approximation: Theory and Algorithms(eds. Benner, P., Cohen, A., Ohlberger, M. & Willcox, K.) 137–168 (SIAM, 2017)
2017
-
[16]
Kontolati, K., Goswami, S., Karniadakis, G. E. & Shields, M. D. Learning nonlinear operators in latent spaces for real-time predictions of complex dynamics in physical systems.Nat. Commun.15, 5101 (2024)
2024
-
[17]
& Pao, Y.-H
Igelnik, B. & Pao, Y.-H. Stochastic choice of basis functions in adaptive function approximation and the functional-link net.IEEE Trans. Neural Networks6, 1320–1329 (1995)
1995
-
[18]
Igelnik, B., Pao, Y.-H., LeClair, S. R. & Shen, C. Y. The ensemble approach to neural-network learning and generalization.IEEE Trans. Neural Networks10, 19–30 (1999)
1999
-
[19]
& Sobajic, D
Pao, Y.-H., Park, G.-H. & Sobajic, D. J. Learning and generalization characteristics of the random vector functional-link net.Neurocomputing6, 163–180 (1994). 14
1994
-
[20]
& Yang, Z
Chen, J., Chi, X., E, W. & Yang, Z. Bridging traditional and machine learning-based algorithms for solving PDEs: the random feature method.J. Mach. Learn.1, 268–298 (2022)
2022
-
[21]
Dong, S. & Li, Z. Local extreme learning machines and domain decomposition for solving linear and nonlinear partial differential equations.Comput. Methods Appl. Mech. Eng.387, 114129 (2021)
2021
-
[22]
& Sun, J
Shang, Y., Wang, F. & Sun, J. Randomized neural network with Petrov–Galerkin methods for solving linear and nonlinear partial differential equations.Commun. Nonlinear Sci. Numer. Simul. 127, 107518 (2023)
2023
-
[23]
& Wang, F
Sun, J., Dong, S. & Wang, F. Local randomized neural networks with discontinuous Galerkin methods for partial differential equations.J. Comput. Appl. Math.445, 115830 (2024)
2024
-
[24]
& Wang, F
Sun, J. & Wang, F. Local randomized neural networks with discontinuous Galerkin methods for diffusive–viscous wave equation.Comput. Math. Appl.154, 128–137 (2024)
2024
-
[25]
& Wang, F
Li, Y. & Wang, F. Local randomized neural networks with finite difference methods for interface problems.J. Comput. Phys.529, 113847 (2025)
2025
-
[26]
& Wang, F
Jiang, Z., Dang, H. & Wang, F. DeepONet augmented by randomized neural networks for efficient operator learning in PDEs.Commun. Nonlinear Sci. Numer. Simul.155, 109605 (2026)
2026
-
[27]
Goswami, S., Kontolati, K., Shields, M. D. & Karniadakis, G. E. Deep transfer operator learning for partial differential equations under conditional shift.Nat. Mach. Intell.4, 1155–1164 (2022)
2022
-
[28]
Angelopoulos, A. N. & Bates, S. A gentle introduction to conformal prediction and distribution-free uncertainty quantification.arXiv preprintarXiv:2107.07511 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
& Gammerman, A
Papadopoulos, H., Proedrou, K., Vovk, V. & Gammerman, A. Inductive confidence machines for regression. InEuropean Conference on Machine Learning345–356 (Springer, 2002)
2002
-
[30]
& Shafer, G.Algorithmic Learning in a Random World(Springer, Boston, 2005)
Vovk, V., Gammerman, A. & Shafer, G.Algorithmic Learning in a Random World(Springer, Boston, 2005)
2005
-
[31]
S.Adaptive Filter Theory(Pearson Education India, 2008)
Haykin, S. S.Adaptive Filter Theory(Pearson Education India, 2008)
2008
-
[32]
H.Fundamentals of Adaptive Filtering(John Wiley & Sons, Hoboken, 2003)
Sayed, A. H.Fundamentals of Adaptive Filtering(John Wiley & Sons, Hoboken, 2003)
2003
-
[33]
& Karniadakis, G
Lu, L., Meng, X., Cai, S., Mao, Z., Goswami, S., Zhang, Z. & Karniadakis, G. E. A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data.Comput. Methods Appl. Mech. Eng.393, 114778 (2022)
2022
-
[34]
& Maggioni, M
Yin, M., Charon, N., Brody, R., Lu, L., Trayanova, N. & Maggioni, M. A scalable framework for learning the geometry-dependent solution operators of partial differential equations.Nat. Comput. Sci.4, 928–940 (2024)
2024
-
[35]
& Karniadakis, G
Zhang, E., Kahana, A., Kopaniˇ c´ akov´ a, A., Turkel, E., Ranade, R., Pathak, J. & Karniadakis, G. E. Blending neural operators and relaxation methods in PDE numerical solvers.Nat. Mach. Intell.6, 1303–1313 (2024). 15 Acknowledgements This work was supported by the National Key R&D Program of China (Grant No. 2025YFA1016400). Author contributions Z.D. co...
2024
-
[36]
Bhattacharya, K., Hosseini, B., Kovachki, N. B. & Stuart, A. M. Model reduction and neural networks for parametric PDEs.SMAI J. Comput. Math.7, 121–157 (2021)
2021
-
[37]
Barron, A. R. Universal approximation bounds for superpositions of a sigmoidal function.IEEE Trans. Inf. Theory39, 930–945 (1993). 24 Supplementary Table 1:Baseline architectures and training budgets.The reimplemented baselines in Table 2 use the architectures and maximum training epochs listed below. DeepONet and FNO baselines are trained with Adam or Ad...
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.