Harvesting AI Computation at the Edge via Generic Approximation
Pith reviewed 2026-06-30 01:51 UTC · model grok-4.3
The pith
General edge tasks can be turned into neural approximations to run on idle AI chips.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
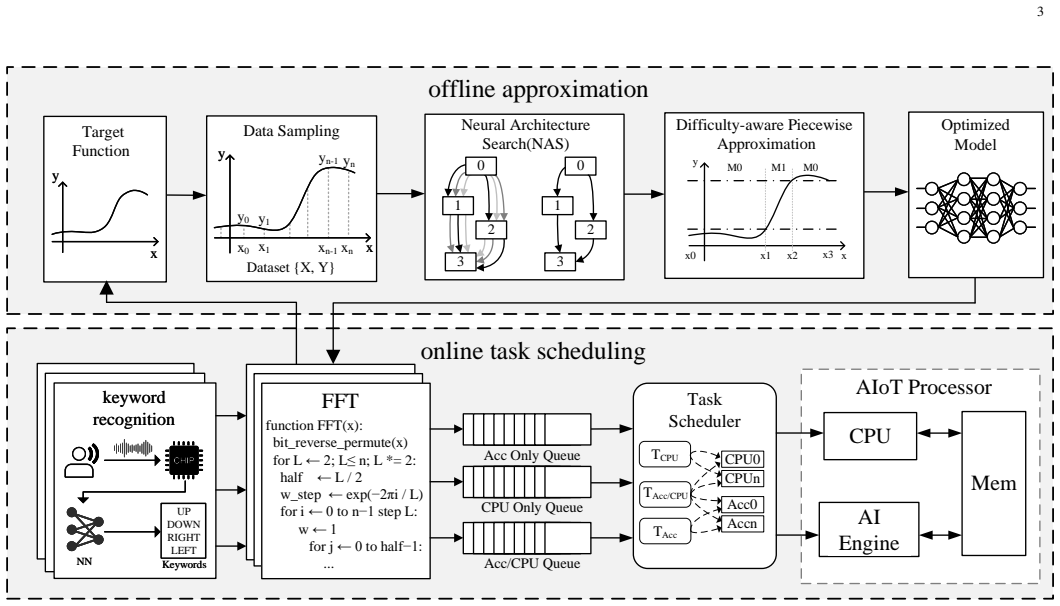
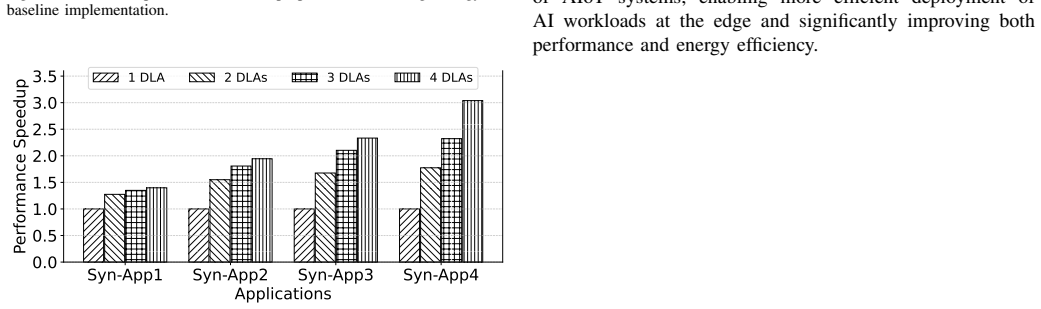
The central claim is that a framework using neural architecture search to produce approximate neural-network versions of general-purpose tasks, combined with a runtime scheduler that offloads them to AI engines only during idle periods, allows those engines to absorb extra work without degrading the performance or correctness of their primary structured neural-network workloads, thereby improving overall throughput on edge processors.
What carries the argument
Neural architecture search to generate task approximations plus a runtime scheduler that places them on AI engines only when primary workloads are idle.
If this is right
- General-purpose processors at the edge are relieved of signal-processing and numerical workloads.
- AI engines achieve higher utilization by filling temporal gaps with approximate computations.
- Edge devices can sustain a wider mix of structured and unstructured tasks without added hardware.
- The same scheduler logic can be applied to other sets of edge processing tasks beyond those tested.
Where Pith is reading between the lines
- The technique may apply to other specialized accelerators if similar approximation methods are developed for them.
- Dynamic workload mixing could become feasible in heterogeneous edge systems that combine AI engines with CPUs and DSPs.
- Accuracy of the approximations under real sensor noise or varying input distributions would need separate verification.
Load-bearing premise
The neural approximations can execute on the AI engine during idle periods without slowing down or corrupting the primary structured neural-network workloads.
What would settle it
Measure latency and accuracy of the primary neural-network workloads both with and without the approximated tasks running concurrently on the same AI engine.
Figures
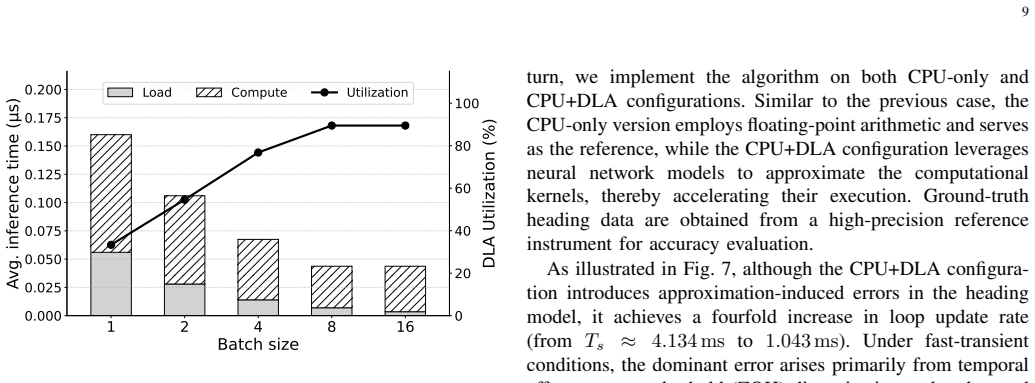
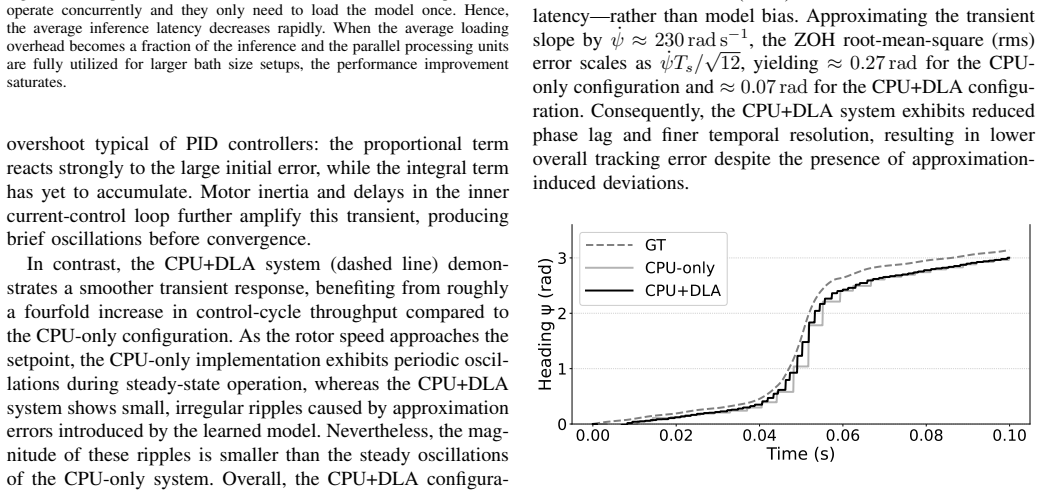
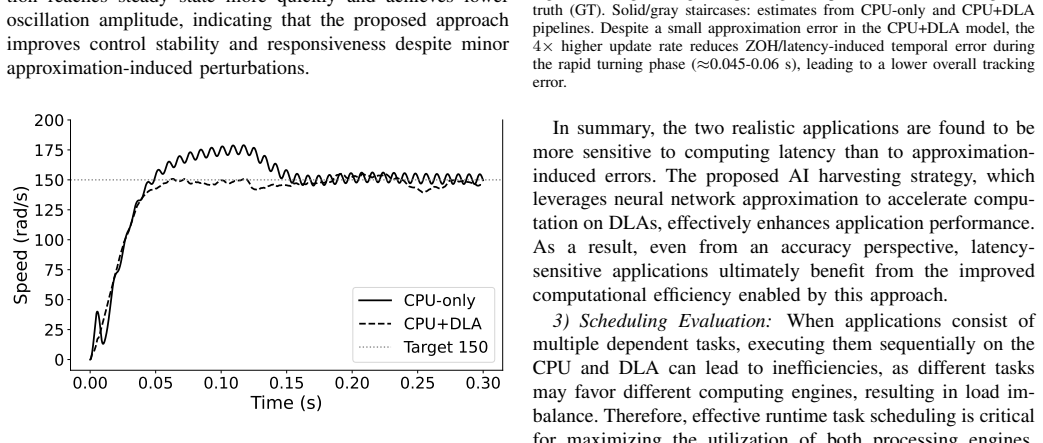
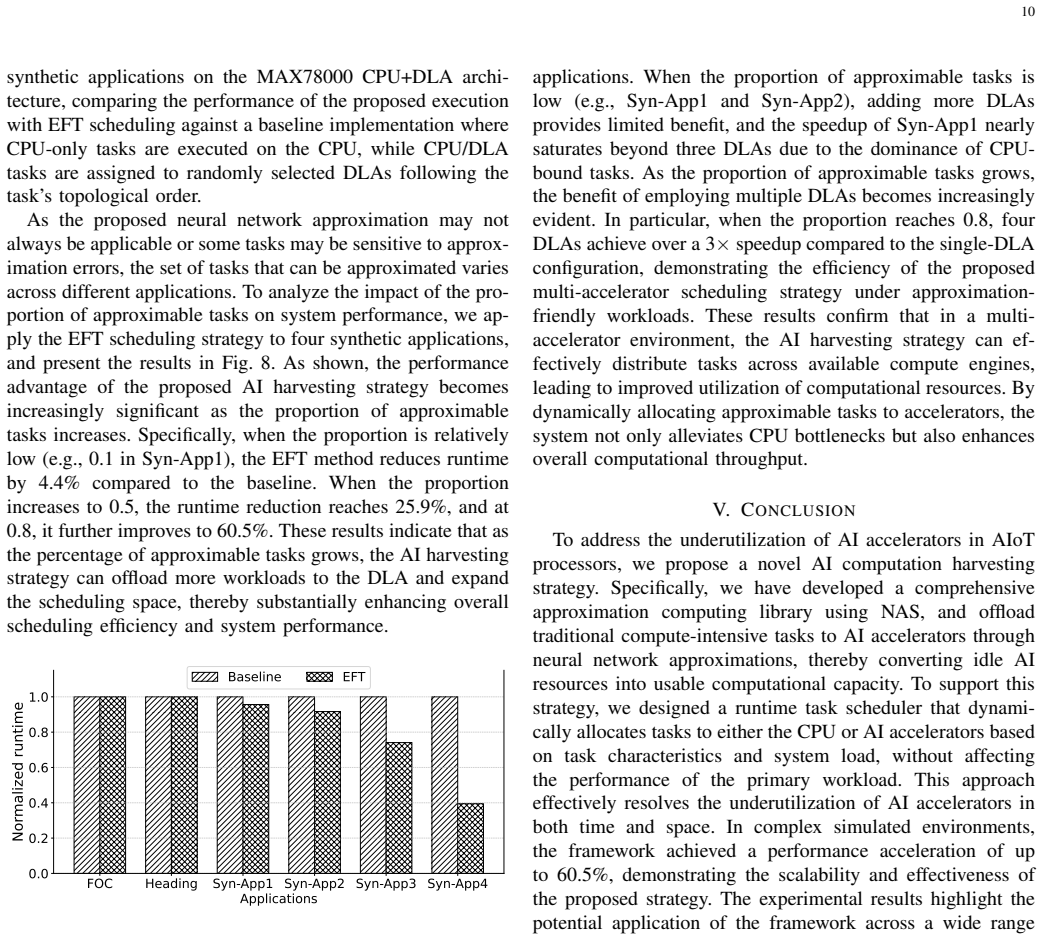
read the original abstract
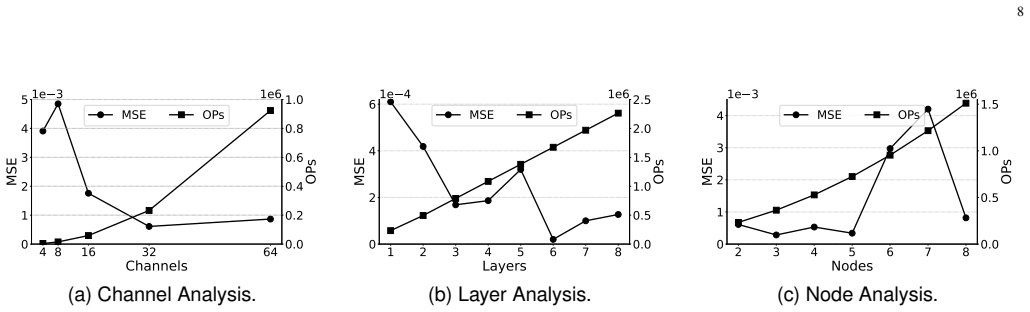
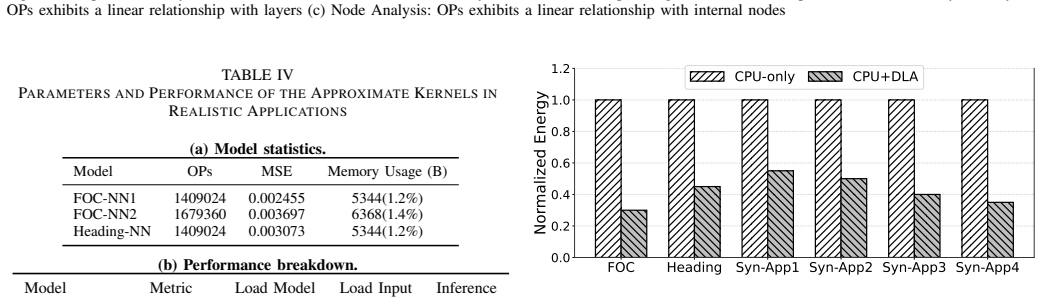
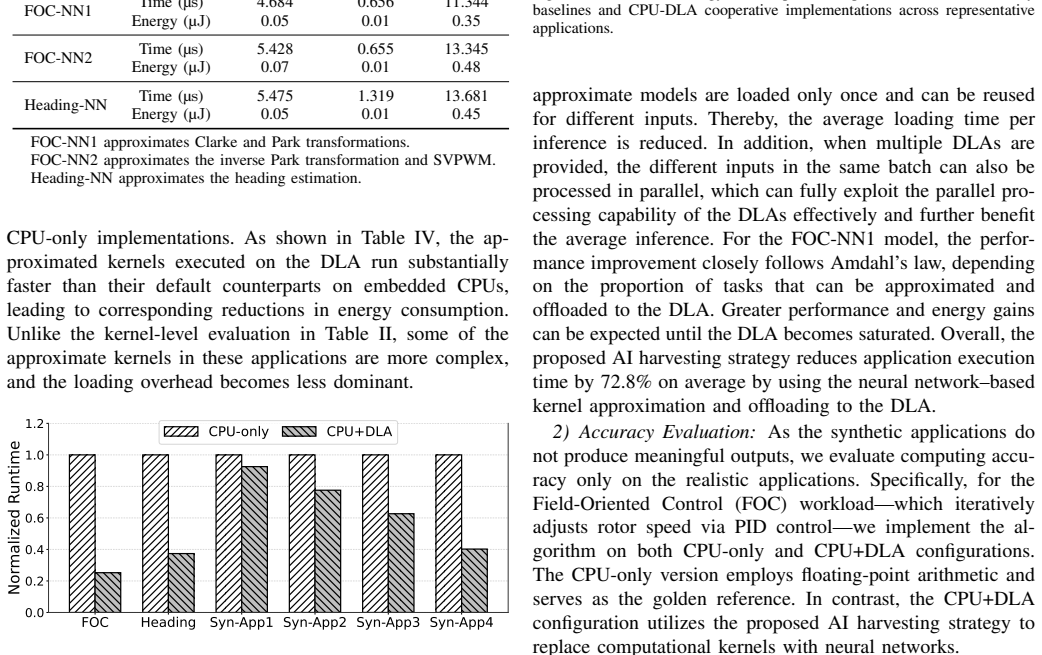
With the widespread adoption of AI in various IoT scenarios such as smart sensing and processing, AI chips have become a common component at the edge. These chips are typically specialized for structured neural network (NN) processing and are designed to meet peak workload demands. However, they are often underutilized and suffer from considerable computational waste due to temporal or spatial redundancy in processing. Conversely, general-purpose processing engines at the edge may struggle with compute-intensive tasks such as signal processing and complex numerical operations because of stringent resource constraints. To address this imbalance, we propose a framework that harvests unused AI computation resources using general-purpose approximation techniques. The core idea is to automatically convert traditional computing tasks into neural network models via a representative neural architecture search (NAS) method. These approximate versions of general-purpose tasks are then deployed on AI engines during their idle periods. Specifically, we introduce a runtime scheduler that offloads these tasks to AI chips without compromising the performance of primary AI workloads, thereby alleviating the burden on general-purpose processors. Experiments on a representative AIoT processor show that our proposed AI computation harvesting strategy delivers substantial performance improvements across a set of edge processing tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework to harvest unused AI computation resources on edge devices by converting general-purpose tasks into approximate neural networks using neural architecture search (NAS). These approximations are scheduled to run on idle periods of specialized AI engines without affecting primary workloads. Experiments on an AIoT processor are claimed to show substantial performance improvements for edge processing tasks.
Significance. If the experimental results are robust, this work could have significant impact on edge computing by improving utilization of AI accelerators and reducing load on general-purpose processors. The generic approximation via NAS is an interesting approach to bridging general and specialized computing at the edge.
major comments (1)
- Abstract: The central claim of 'substantial performance improvements' is presented without any quantitative metrics, baseline comparisons, error bars, or details on the specific tasks, NAS method, or scheduler implementation. This makes the headline experimental outcome impossible to assess or reproduce from the given text.
minor comments (1)
- Abstract: The phrase 'a representative NAS method' is used without naming the specific algorithm or search space, which hinders evaluation of the approximation quality and generality.
Simulated Author's Rebuttal
We thank the referee for their review and the comment on the abstract. We address it point by point below.
read point-by-point responses
-
Referee: [—] Abstract: The central claim of 'substantial performance improvements' is presented without any quantitative metrics, baseline comparisons, error bars, or details on the specific tasks, NAS method, or scheduler implementation. This makes the headline experimental outcome impossible to assess or reproduce from the given text.
Authors: We agree that the abstract, in its current form, lacks the quantitative details needed for immediate assessment. The body of the manuscript (Sections 4 and 5) reports the specific metrics, baselines, tasks, NAS configuration, and scheduler implementation with error bars. To improve the abstract, we will revise it to include representative quantitative results (e.g., speedup and energy figures) and brief references to the tasks and methods while preserving conciseness. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core proposal (NAS conversion of general tasks to approximate NNs for idle AI-engine execution plus a runtime scheduler) is presented as a design framework whose headline performance claims are tied directly to experiments on an AIoT processor. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the abstract or description. No load-bearing step reduces by construction to its own inputs; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The internet of things: A survey.Computer networks, 54(15):2787–2805, 2010
Luigi Atzori, Antonio Iera, and Giacomo Morabito. The internet of things: A survey.Computer networks, 54(15):2787–2805, 2010
2010
-
[2]
In-datacenter performance analysis of a tensor processing unit
Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. In-datacenter performance analysis of a tensor processing unit. InProceedings of the 44th annual international symposium on computer architecture, pages 1–12, 2017
2017
-
[3]
Leaf: A learnable frontend for audio classification.arXiv preprint arXiv:2101.08596, 2021
Neil Zeghidour, Olivier Teboul, F ´elix De Chaumont Quitry, and Marco Tagliasacchi. Leaf: A learnable frontend for audio classification.arXiv preprint arXiv:2101.08596, 2021
-
[4]
Junfeng Gong, Cheng Liu, Long Cheng, Huawei Li, and Xiaowei Li. Mcu-mixq: A hw/sw co-optimized mixed-precision neural network design framework for mcus.arXiv preprint arXiv:2407.18267, 2024
-
[5]
Empowering edge intelligence: A comprehensive survey on on-device ai models.ACM Computing Surveys, 2025
Xubin Wang, Zhiqing Tang, Jianxiong Guo, Tianhui Meng, Chenhao Wang, Tian Wang, and Weijia Jia. Empowering edge intelligence: A comprehensive survey on on-device ai models.ACM Computing Surveys, 2025
2025
-
[6]
Yolo9000: better, faster, stronger
Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7263–7271, 2017
2017
-
[7]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size.arXiv preprint arXiv:1602.07360, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard. Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning, pages 6105–6114. PMLR, 2019
2019
-
[10]
Addressing the issue of processing element under- utilization in general-purpose systolic deep learning accelerators
Bosheng Liu, Xiaoming Chen, Ying Wang, Yinhe Han, Jiajun Li, Haobo Xu, and Xiaowei Li. Addressing the issue of processing element under- utilization in general-purpose systolic deep learning accelerators. In Proceedings of the 24th Asia and South Pacific Design Automation Conference, pages 733–738, 2019
2019
-
[11]
Arnab Raha, Deepak A Mathaikutty, Soumendu K Ghosh, and Shamik Kundu. Flexnn: A dataflow-aware flexible deep learning accelerator for energy-efficient edge devices.arXiv preprint arXiv:2403.09026, 2024
-
[12]
A comprehensive survey of energy-efficient computing to enable sustain- able massive iot networks.Alexandria Engineering Journal, 91:12–29, 2024
Mohammed H Alsharif, Anabi Hilary Kelechi, Abu Jahid, Raju Kan- nadasan, Manish Kumar Singla, Jyoti Gupta, and Zong Woo Geem. A comprehensive survey of energy-efficient computing to enable sustain- able massive iot networks.Alexandria Engineering Journal, 91:12–29, 2024
2024
-
[13]
Snnap: Approximate computing on programmable socs via neural acceleration
Thierry Moreau, Mark Wyse, Jacob Nelson, Adrian Sampson, Hadi Esmaeilzadeh, Luis Ceze, and Mark Oskin. Snnap: Approximate computing on programmable socs via neural acceleration. In2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), pages 603–614. IEEE, 2015
2015
-
[14]
Neural acceleration for general-purpose approximate programs
Hadi Esmaeilzadeh, Adrian Sampson, Luis Ceze, and Doug Burger. Neural acceleration for general-purpose approximate programs. In2012 45th annual IEEE/ACM international symposium on microarchitecture, pages 449–460. IEEE, 2012
2012
-
[15]
Neural network-based accelerators for transcendental function approximation
Schuyler Eldridge, Florian Raudies, David Zou, and Ajay Joshi. Neural network-based accelerators for transcendental function approximation. InProceedings of the 24th edition of the great lakes symposium on VLSI, pages 169–174, 2014
2014
-
[16]
Hadjer Benmeziane, Kaoutar El Maghraoui, Hamza Ouarnoughi, Smail Niar, Martin Wistuba, and Naigang Wang. A comprehensive sur- vey on hardware-aware neural architecture search.arXiv preprint arXiv:2101.09336, 2021
-
[17]
Neural ar- chitecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019
Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural ar- chitecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019
2019
-
[18]
Fbnet: Hardware-aware efficient convnet design via differ- entiable neural architecture search
Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. Fbnet: Hardware-aware efficient convnet design via differ- entiable neural architecture search. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10734– 10742, 2019
2019
-
[19]
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neu- ral architecture search on target task and hardware.arXiv preprint arXiv:1812.00332, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Memory- efficient patch-based inference for tiny deep learning.Advances in Neural Information Processing Systems, 34:2346–2358, 2021
Ji Lin, Wei-Ming Chen, Han Cai, Chuang Gan, and Song Han. Memory- efficient patch-based inference for tiny deep learning.Advances in Neural Information Processing Systems, 34:2346–2358, 2021
2021
-
[21]
Pruning vs quantization: Which is better?Advances in neural information processing systems, 36:62414–62427, 2023
Andrey Kuzmin, Markus Nagel, Mart Van Baalen, Arash Behboodi, and Tijmen Blankevoort. Pruning vs quantization: Which is better?Advances in neural information processing systems, 36:62414–62427, 2023
2023
-
[22]
Minh Tri L ˆe, Pierre Wolinski, and Julyan Arbel. Efficient neural networks for tiny machine learning: A comprehensive review.arXiv preprint arXiv:2311.11883, 2023
-
[23]
Di Xu, Xiang He, Tonghua Su, and Zhongjie Wang. A survey on deep neural network partition over cloud, edge and end devices.arXiv preprint arXiv:2304.10020, 2023
-
[24]
Survey of deep learning accelerators for edge and emerging computing.Electronics, 13(15):2988, 2024
Shahanur Alam, Chris Yakopcic, Qing Wu, Mark Barnell, Simon Khan, and Tarek M Taha. Survey of deep learning accelerators for edge and emerging computing.Electronics, 13(15):2988, 2024
2024
-
[25]
Efficient processing of deep neural networks: A tutorial and survey.Proceedings of the IEEE, 105(12):2295–2329, 2017
Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S Emer. Efficient processing of deep neural networks: A tutorial and survey.Proceedings of the IEEE, 105(12):2295–2329, 2017
2017
-
[26]
{SHEPHERD}: Serving{DNNs}in the wild
Hong Zhang, Yupeng Tang, Anurag Khandelwal, and Ion Stoica. {SHEPHERD}: Serving{DNNs}in the wild. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 787–808, 2023
2023
-
[27]
Maeri: Enabling flexible dataflow mapping over dnn accelerators via recon- figurable interconnects.ACM Sigplan Notices, 53(2):461–475, 2018
Hyoukjun Kwon, Ananda Samajdar, and Tushar Krishna. Maeri: Enabling flexible dataflow mapping over dnn accelerators via recon- figurable interconnects.ACM Sigplan Notices, 53(2):461–475, 2018
2018
-
[28]
Eyeriss: A spatial archi- tecture for energy-efficient dataflow for convolutional neural networks
Yu-Hsin Chen, Joel Emer, and Vivienne Sze. Eyeriss: A spatial archi- tecture for energy-efficient dataflow for convolutional neural networks. ACM SIGARCH computer architecture news, 44(3):367–379, 2016
2016
-
[29]
A formalism of dnn accelerator flexibility
Sheng-Chun Kao, Hyoukjun Kwon, Michael Pellauer, Angshuman Parashar, and Tushar Krishna. A formalism of dnn accelerator flexibility. Proceedings of the ACM on Measurement and Analysis of Computing Systems, 6(2):1–23, 2022
2022
-
[30]
Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings
Norm Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, et al. Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings. InProceedings of the 50th annual international symposium on computer architecture, pages 1–14, 2023
2023
-
[31]
Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
George Cybenko. Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems, 2(4):303–314, 1989
1989
-
[32]
Approximation capabilities of multilayer feedforward networks.Neural networks, 4(2):251–257, 1991
Kurt Hornik. Approximation capabilities of multilayer feedforward networks.Neural networks, 4(2):251–257, 1991
1991
-
[33]
Error bounds for approximations with deep relu networks.Neural networks, 94:103–114, 2017
Dmitry Yarotsky. Error bounds for approximations with deep relu networks.Neural networks, 94:103–114, 2017
2017
-
[34]
Optimal approximation rates for deep relu neural networks on sobolev and besov spaces.Journal of Machine Learning Research, 24(357):1–52, 2023
Jonathan W Siegel. Optimal approximation rates for deep relu neural networks on sobolev and besov spaces.Journal of Machine Learning Research, 24(357):1–52, 2023
2023
-
[35]
The expressive power of neural networks: A view from the width
Zeyuan Lu, Haizhao Pu, Feicheng Wang, Zhiqiang Hu, and Liwei Wang. The expressive power of neural networks: A view from the width. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[36]
Neural networks with small weights and depth-separation barriers.Advances in neural information processing systems, 33:19433–19442, 2020
Gal Vardi and Ohad Shamir. Neural networks with small weights and depth-separation barriers.Advances in neural information processing systems, 33:19433–19442, 2020
2020
-
[37]
Optimal approximation of piecewise smooth functions using deep relu neural networks.Neural Networks, 108:296–330, 2018
Philipp Petersen and Felix V oigtlaender. Optimal approximation of piecewise smooth functions using deep relu neural networks.Neural Networks, 108:296–330, 2018
2018
-
[38]
DARTS: Differentiable Architecture Search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search.arXiv preprint arXiv:1806.09055, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Hanwen Liang, Shifeng Zhang, Jiacheng Sun, Xingqiu He, Weiran Huang, Kechen Zhuang, and Zhenguo Li. Darts+: Improved dif- ferentiable architecture search with early stopping.arXiv preprint arXiv:1909.06035, 2019
-
[40]
Arber Zela, Thomas Elsken, Tonmoy Saikia, Yassine Marrakchi, Thomas Brox, and Frank Hutter. Understanding and robustifying differentiable architecture search.arXiv preprint arXiv:1909.09656, 2019
-
[41]
Fair darts: Eliminating unfair advantages in differentiable architecture search
Xiangxiang Chu, Tianbao Zhou, Bo Zhang, and Jixiang Li. Fair darts: Eliminating unfair advantages in differentiable architecture search. In European conference on computer vision, pages 465–480. Springer, 2020
2020
-
[42]
Ultra-low power dnn accelerators for iot: Resource characterization of the max78000
Arthur Moss, Hyunjong Lee, Lei Xun, Chulhong Min, Fahim Kawsar, and Alessandro Montanari. Ultra-low power dnn accelerators for iot: Resource characterization of the max78000. InProceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, pages 934– 940, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.