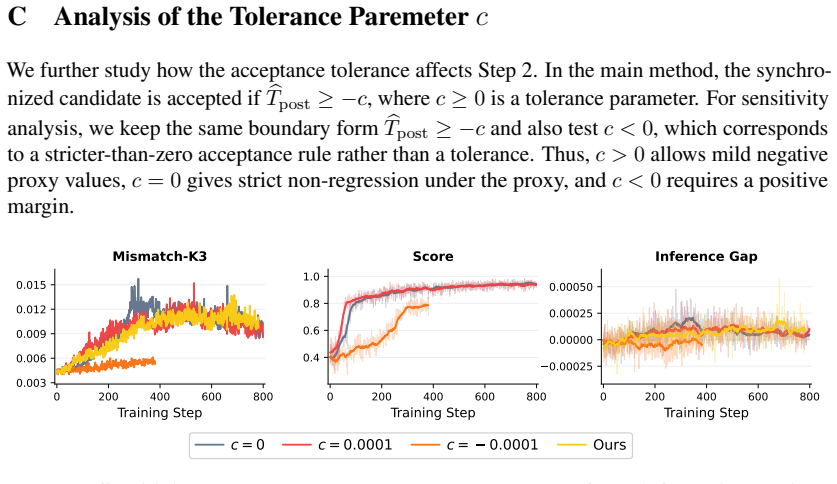
The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
Pith reviewed 2026-06-30 07:20 UTC · model grok-4.3
The pith
An effective update to the training policy does not ensure improvement of the inference policy used in deployment for LLM RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
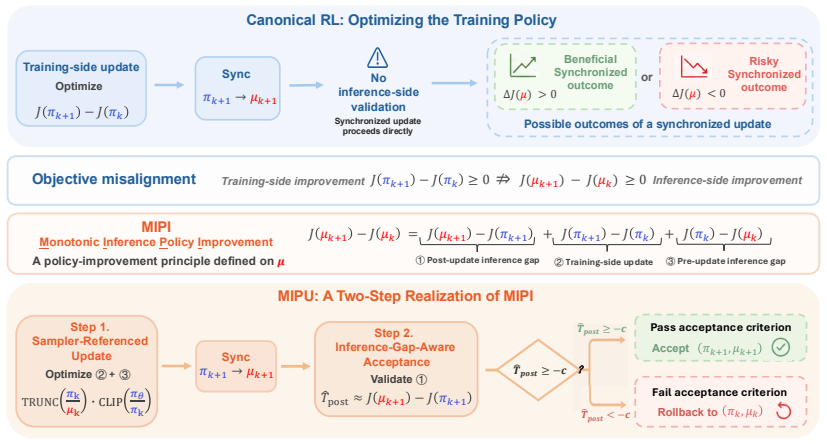
Because training and inference engines assign different probabilities to the same sequences, an update that raises the training policy objective need not raise the inference policy objective. The paper therefore defines Monotonic Inference Policy Improvement (MIPI) as the correct target and introduces Monotonic Inference Policy Update (MIPU), which constructs sampler-referenced candidate updates and selectively accepts only those whose inference-side gap proxy signals monotonic improvement on the inference policy.
What carries the argument
Monotonic Inference Policy Improvement (MIPI) objective together with the MIPU two-step framework that filters candidate updates by an inference-side gap proxy.
If this is right
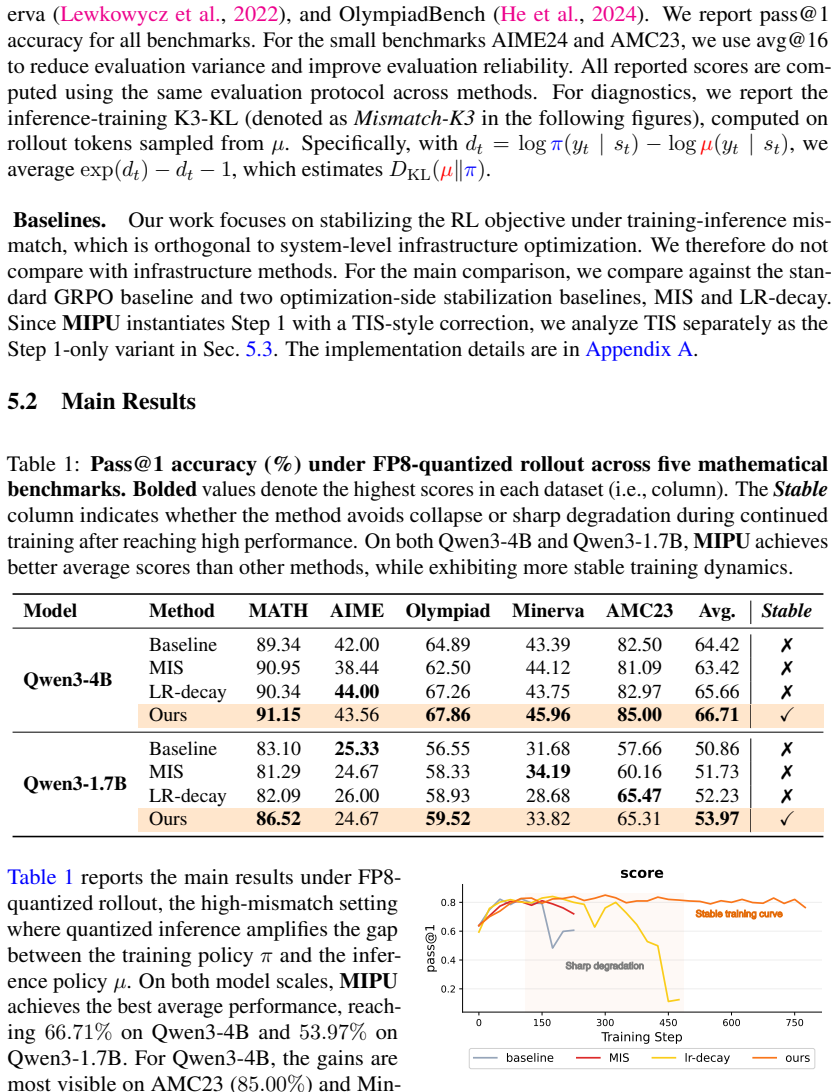
- MIPU produces higher average reasoning performance than prior mismatch-handling methods under high training-inference mismatch.
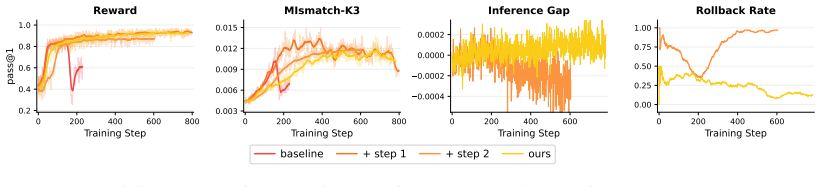
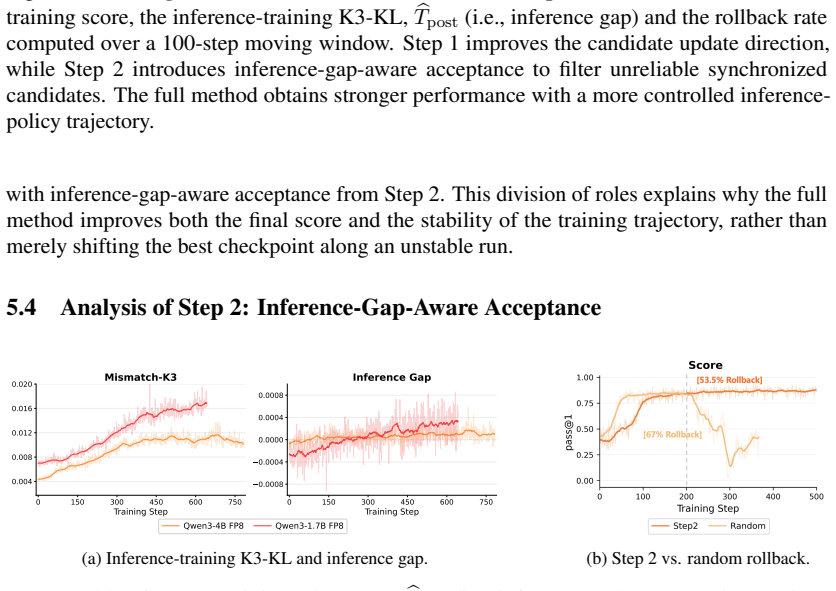
- Selective acceptance of synchronized candidates using the inference-side gap proxy increases training stability and reduces collapse risk.
- The approach works across two different model scales without requiring changes to the underlying sampler or reward model.
- MIPI replaces the training-policy objective as the quantity to be maximized at every step.
Where Pith is reading between the lines
- If the proxy proves reliable across wider mismatch regimes, training loops could drop direct inference measurements entirely.
- The same selective-acceptance pattern might apply to other settings where training and deployment engines diverge, such as quantized or distilled models.
- A tighter theoretical bound on the proxy-to-inference correlation would strengthen the guarantee that accepted updates are monotonic on the deployed policy.
Load-bearing premise
The inference-side gap proxy reliably identifies updates that produce monotonic improvement on the actual inference policy without requiring direct measurement or additional assumptions about the mismatch distribution.
What would settle it
Direct measurement on the inference engine showing that an update accepted by the MIPU proxy produces no improvement or produces degradation in inference policy performance.
Figures
read the original abstract
Reinforcement learning (RL) has gained growing attention in large language model (LLM) post-training, yet RL training remains fragile and can suffer from instability or collapse. One vital cause is training-inference mismatch: LLM adopts separate inference and training engines for generation efficiency and training precision, which in practice exhibits inconsistent probabilities for the same trajectories on training and inference sides, even with synchronized model parameters. This naturally induces a special type of off-policyness ever existing and poisoning the training. Prior works have made various efforts in addressing the off-policyness to stabilize the training policies under the mismatch. In this paper, we point out the objective misalignment neglected by existing works that an effective update to the policy in the training engine not necessarily ensures the improvement of the inference policy, i.e., the one used in deployment. To this end, we propose a new policy optimization objective for LLM RL, named Monotonic Inference Policy Improvement (MIPI). Following this principle, we introduce Monotonic Inference Policy Update (MIPU), a two-step LLM RL framework that constructs sampler-referenced candidate updates and selectively accepts synchronized candidates using an inference-side gap proxy. Experiments conducted on two model scales under high mismatch show that MIPU improves average reasoning performance and training stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a training-inference mismatch in LLM RL arising from separate engines, which creates persistent off-policyness. It argues that optimizing the training policy does not guarantee monotonic improvement in the deployed inference policy, and proposes the Monotonic Inference Policy Improvement (MIPI) objective. It introduces the Monotonic Inference Policy Update (MIPU) framework, which generates sampler-referenced candidate updates and accepts them via an inference-side gap proxy. Experiments on two model scales under high mismatch report gains in average reasoning performance and training stability.
Significance. If MIPU's proxy reliably selects only updates that improve the true inference policy, the work would address a practical source of instability in LLM post-training that prior off-policy corrections have overlooked. The experimental results on multiple scales provide initial evidence of benefit, but the absence of a bound or stated assumption linking the proxy to monotonic inference improvement limits the strength of the central claim.
major comments (2)
- [§4] §4 (MIPU framework): The inference-side gap proxy is described as the mechanism that ensures only synchronized candidates producing monotonic inference-policy improvement are accepted, yet no derivation, bound, or explicit assumption on the mismatch distribution is supplied to establish that the proxy selects such updates. Without this link, an update passing the proxy could still degrade inference performance.
- [§5] §5 (Experiments): The reported gains in reasoning performance and stability are shown under high mismatch, but the evaluation does not include a direct measurement of inference-policy value before/after accepted updates or an ablation isolating the proxy's contribution from the candidate-generation step.
minor comments (2)
- Notation for the training and inference policies should be introduced with explicit symbols (e.g., π_train vs. π_inf) at first use rather than relying on descriptive phrases.
- The abstract states that MIPU 'constructs sampler-referenced candidate updates'; the corresponding section should clarify whether the sampler is the training engine itself or an external reference distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger theoretical grounding of the proxy and more targeted experimental validation. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (MIPU framework): The inference-side gap proxy is described as the mechanism that ensures only synchronized candidates producing monotonic inference-policy improvement are accepted, yet no derivation, bound, or explicit assumption on the mismatch distribution is supplied to establish that the proxy selects such updates. Without this link, an update passing the proxy could still degrade inference performance.
Authors: We agree that the current manuscript lacks an explicit derivation or bound connecting the inference-side gap proxy to guaranteed monotonic improvement of the inference policy. The proxy is motivated directly by the MIPI objective (difference in expected value under the inference policy) and uses the observed log-probability gap between engines on sampler trajectories as a practical surrogate. We will revise §4 to state the assumption of bounded mismatch (i.e., the total variation distance between training and inference distributions is upper-bounded by a known constant) and provide a short proof sketch showing that, under this assumption, acceptance by the proxy implies non-negative change in inference policy value. This is a partial revision because a fully general bound without assumptions on the mismatch remains an open question. revision: partial
-
Referee: [§5] §5 (Experiments): The reported gains in reasoning performance and stability are shown under high mismatch, but the evaluation does not include a direct measurement of inference-policy value before/after accepted updates or an ablation isolating the proxy's contribution from the candidate-generation step.
Authors: We concur that direct before/after inference-policy value measurements and a proxy ablation would strengthen the empirical claims. In the revised version we will add (i) inference-engine rollouts to compute policy value on a held-out set before and after each accepted update and (ii) an ablation that disables the proxy (i.e., always accepts sampler-referenced candidates) while keeping the candidate-generation step fixed. Results will be reported for both model scales under the same high-mismatch regime. revision: yes
Circularity Check
No circularity; MIPI/MIPU presented as new objective without self-referential reduction or fitted predictions
full rationale
The abstract and provided text introduce the training-inference mismatch as motivation and propose MIPI as a new objective plus MIPU as a two-step framework using an inference-side gap proxy. No equations, parameter-fitting procedures, or derivation steps are shown that would allow any claim to reduce to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is described. The central claim of objective misalignment is stated directly rather than derived from prior self-work. Because the paper's derivation chain contains no inspectable steps that match the enumerated circularity patterns, the score is 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training and inference engines produce inconsistent probabilities for identical trajectories even with synchronized parameters.
Reference graph
Works this paper leans on
-
[1]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
URL https://arxiv.org/abs/2508.06471. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/abs/2504.11456. Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset.NeurIPS,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URL https://openreview.net/forum?id=NFM8F5cV0V. Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kimi K2.5: Visual Agentic Intelligence
URL https://arxiv.org/abs/ 2602.02276. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Accessed: 2026-04-30
URL https: //artofproblemsolving.com/wiki/index.php/AMC_12_Problems_and_Solutions. Accessed: 2026-04-30. MAA. American invitational mathematics examination (aime), February
2026
-
[6]
URL https: //artofproblemsolving.com/wiki/index.php/2024_AIME_I. Accessed: 2026-04-30. Qi, P., Liu, Z., Zhou, X., Pang, T., Du, C., Lee, W. S., and Lin, M. Defeating the training- inference mismatch via fp16.arXiv preprint arXiv:2510.26788,
-
[7]
URLhttps://arxiv.org/abs/2505.09388. Schulman, J., Levine, S., Abbeel, P., Jordan, M. I., and Moritz, P. Trust region policy optimiza- tion. InICML, volume 37, pp. 1889–1897,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
URL https://arxiv.org/abs/1909.08053. Sutton, R. S. and Barto, A. G.Reinforcement learning - an introduction. Adaptive computation and machine learning. MIT Press,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[11]
Deep Reinforcement Learning and the Deadly Triad
van Hasselt, H., Doron, Y ., Strub, F., Hessel, M., Sonnerat, N., and Modayil, J. Deep reinforce- ment learning and the deadly triad.arXiv preprint, arXiv:1812.02648,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Wang, W., Xiong, S., Chen, G., Gao, W., Guo, S., He, Y ., Huang, J., Liu, J., Li, Z., Li, X., et al. Reinforcement learning optimization for large-scale learning: An efficient and user-friendly scaling library.arXiv preprint arXiv:2506.06122,
-
[13]
Wu, Z., Tang, H., Ma, Y ., Liu, J., Zheng, Y ., and Hao, J
URLhttps://arxiv.org/abs/2512.24873. Wu, Z., Tang, H., Ma, Y ., Liu, J., Zheng, Y ., and Hao, J. The rank and gradient lost in non- stationarity: Sample weight decay for mitigating plasticity loss in reinforcement learning. In ICLR,
-
[14]
URL https://fengyao.notion.site/ off-policy-rl. Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Fan, T., Liu, G., Liu, L., Liu, X., Lin, H., Lin, Z., Ma, B., Sheng, G., Tong, Y ., Zhang, C., Zhang, M., Zhang, W., Zhu, H., Zhu, J., Chen, J., Chen, J., Wang, C., Yu, H., Dai, W., Song, Y ., Wei, X., Zhou, H., Liu, J., Ma, W., Zhang, Y ., Yan, L., Q...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https://arxiv.org/abs/2602.01826. Zhao, Y ., Gu, A., Varma, R., Luo, L., Huang, C.-C., Xu, M., Wright, L., Shojanazeri, H., Ott, M., Shleifer, S., Desmaison, A., Balioglu, C., Damania, P., Nguyen, B., Chauhan, G., Hao, Y ., Mathews, A., and Li, S. Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proc. VLDB Endow., 16(12):3848–3860, August
-
[16]
ISSN 2150-8097. doi: 10.14778/3611540.3611569. URLhttps://doi.org/10.14778/3611540.3611569. Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., Zhou, J., and Lin, J. Group sequence policy optimization,
-
[17]
Group Sequence Policy Optimization
URL https://arxiv. org/abs/2507.18071. Zheng, L., Yin, L., Xie, Z., Sun, C., Huang, J., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Barrett, C., and Sheng, Y . SGLang: Efficient execution of structured language model programs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
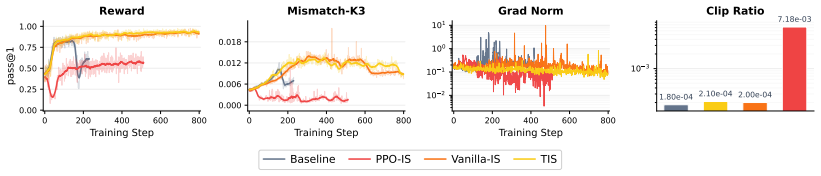
A direct implementation is PPO-IS, which clips the total trainer-to-sampler ratio: PPO-IS:ω PPO-IS = clip πθ µk ,1−ϵ,1 +ϵ
For readability, we omit token or trajectory arguments in this section, and all ratios are evaluated on sampled rollouts. A direct implementation is PPO-IS, which clips the total trainer-to-sampler ratio: PPO-IS:ω PPO-IS = clip πθ µk ,1−ϵ,1 +ϵ . 18 0 200 400 600 800 Training Step 0.00 0.25 0.50 0.75 1.00pass@1 Reward 0 200 400 600 800 Training Step 0.000 ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.