Learned Coordination Conventions in Cooperative MARL: Measuring the Translation Gap Between Theory-Informed Roles and Learned Routing
Pith reviewed 2026-06-30 07:04 UTC · model grok-4.3
The pith
Label-conditioned attention in cooperative MARL yields more concentrated role-specific routing than flat MLP baselines and shows partial alignment with designer-specified priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
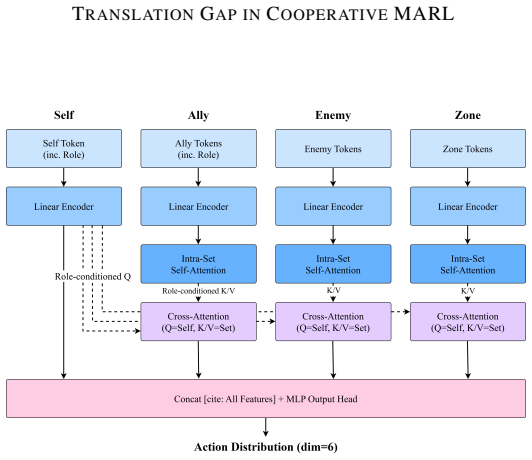
In the MiniGrid and SMACv2 settings, label-conditioned attention produces substantially more concentrated and role-specific routing matrices than flat MLP baselines. This structure remains stable when the number of agents scales from 3v3 to 9v9, transfers zero-shot to unseen team sizes, and is invariant to ally-slot padding. A five-seed re-evaluation finds partial alignment between the learned conventions and the designer-specified role priors, while also showing that small-sample noise can create apparent strategic divergence.
What carries the argument
The role-routing matrix together with formation sensitivity (Δ_max) and gradient/occlusion attribution, used to quantify how agent policies map observations to role-specific actions.
If this is right
- Label-conditioned attention produces routing that is more concentrated around designer-specified roles than flat MLP policies.
- The routing structure stays consistent when the number of agents increases from three to nine per side.
- Policies trained at one team size transfer without retraining to larger or smaller teams.
- Routing patterns do not change when ally observations are padded with dummy slots.
- Five independent seeds reveal only partial overlap between learned conventions and the priors supplied by the environment designer.
Where Pith is reading between the lines
- The same diagnostic could be applied to other attention variants or to value-decomposition methods to test whether they also reduce the translation gap.
- If the observed invariance to padding holds more generally, it would simplify the design of observation interfaces for variable-sized teams.
- The partial alignment result suggests that future work could quantify how much designer prior is needed before learned conventions reliably match it.
- Noise-induced divergence at small sample sizes implies that single-run evaluations of coordination may overstate strategic differences.
Load-bearing premise
The combination of role-routing matrix, formation sensitivity metric, and attribution methods accurately captures the coordination conventions that the agents are actually using.
What would settle it
A controlled run in which agents trained with label-conditioned attention produce routing matrices that remain diffuse and non-role-specific when evaluated on held-out team sizes or under altered observation padding.
Figures
read the original abstract
Role-semantic assignments provide priors over how heterogeneous agents may coordinate, but cooperative MARL systems instead settle on conventions through decentralized, non-stationary learning, with no guarantee that the resulting structure matches those priors. We study this translation gap between theory-informed role expectations and learned coordination structure through a diagnostic combining a role-routing matrix, formation sensitivity ($\Delta_{\max}$), and gradient/occlusion attribution across three-role MiniGrid and SMACv2 (Terran) environments. We show that label-conditioned attention produces substantially more concentrated and role-specific routing than flat MLP baselines, remains stable under 3v3--9v9 scaling, transfers zero-shot across team sizes, and is invariant to ally-slot padding. A 5-seed re-evaluation shows partial alignment between learned conventions and designer-specified priors while revealing where small-n noise can manufacture apparent strategic divergence. We present these results as an empirical framework for measuring coordination structure in cooperative MARL rather than as a new equilibrium concept or causal explanation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an empirical measurement framework for assessing the translation gap between theory-informed role priors and emergent coordination conventions in cooperative MARL. In MiniGrid and SMACv2 (Terran) environments, it compares label-conditioned attention against flat MLP baselines using a role-routing matrix, formation sensitivity metric Δ_max, and gradient/occlusion attribution. Key findings are that attention yields more concentrated, role-specific routing; the behavior is stable from 3v3 to 9v9 scaling, transfers zero-shot across team sizes, and is invariant to ally-slot padding. A 5-seed re-evaluation indicates partial alignment with designer-specified priors while noting small-n noise effects. The contribution is framed explicitly as a diagnostic toolkit rather than a new equilibrium concept.
Significance. If the comparative results hold under fuller experimental reporting, the work supplies a practical set of diagnostics for analyzing coordination structure in MARL, where decentralized learning frequently produces conventions that diverge from hand-specified roles. The scaling, transfer, and invariance findings could guide architecture selection, and the careful framing as an empirical framework (with explicit caveats on partial alignment and noise) strengthens its utility for future falsifiable comparisons.
minor comments (3)
- The experimental section should include explicit reporting of statistical tests, error bars or confidence intervals, and any data exclusion criteria for the 5-seed re-evaluation to allow verification of the stability and invariance claims.
- Clarify the precise definition and computation of the formation sensitivity metric Δ_max (including any normalization or aggregation steps) so that the metric can be reproduced independently.
- The role-routing matrix visualization would benefit from an accompanying quantitative summary table (e.g., entropy or concentration scores) to complement the qualitative description of 'more concentrated' routing.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the manuscript and the recommendation for minor revision. The referee summary correctly captures the paper as an empirical diagnostic framework rather than a new theoretical contribution, and we appreciate the recognition of its potential utility for analyzing coordination in cooperative MARL.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical measurement framework using role-routing matrices, formation sensitivity Δ_max, and attribution methods to compare attention-based vs. MLP routing in MARL environments. No equations, fitted parameters, or derivations are shown that reduce outputs to inputs by construction. Claims are explicitly comparative (attention vs. baseline, scaling, transfer) with authors noting partial alignment and noise; the text disclaims causal or equilibrium claims. No self-citations or ansatzes appear load-bearing in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ho, Thomas L
Micah Carroll, Rohin Shah, Mark K. Ho, Thomas L. Griffiths, Sanjit A. Seshia, Pieter Abbeel, and Anca Dragan. On the utility of learning about humans for human-AI coordination. InAdvances in Neural Information Processing Systems, 2019
2019
-
[2]
Minigrid & miniworld: Modular & cus- tomizable reinforcement learning environments for goal-oriented tasks.Advances in Neural Information Processing Systems, 2023
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & cus- tomizable reinforcement learning environments for goal-oriented tasks.Advances in Neural Information Processing Systems, 2023
2023
-
[3]
Albrecht
Filippos Christianos, Lukas Sch¨afer, and Stefano V . Albrecht. Shared experience actor-critic for multi- agent reinforcement learning. InAdvances in Neural Information Processing Systems, 2020
2020
-
[4]
Albrecht
Filippos Christianos, Georgios Papoudakis, Arrasy Rahman, and Stefano V . Albrecht. Scaling multi-agent reinforcement learning with selective parameter sharing. InProceedings of the International Conference on Machine Learning, 2021
2021
-
[5]
SMACv2: An improved benchmark for cooperative multi-agent reinforcement learning
Benjamin Ellis, Jonathan Cook, Skander Moalla, Mikayel Samvelyan, Mingfei Sun, Anuj Mahajan, Jakob Foerster, and Shimon Whiteson. SMACv2: An improved benchmark for cooperative multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[6]
Other-Play
Hengyuan Hu, Adam Lerer, Alex Peysakhovich, and Jakob Foerster. “Other-Play” for zero-shot coordi- nation. InProceedings of the International Conference on Machine Learning, 2020
2020
-
[7]
Off-belief learning
Hengyuan Hu, Adam Lerer, Brandon Cui, Luis Pineda, Noam Brown, and Jakob Foerster. Off-belief learning. InProceedings of the International Conference on Machine Learning, 2021
2021
-
[8]
UPDeT: Universal multi-agent reinforcement learning via policy decoupling with transformers
Siyi Hu, Fengda Zhu, Xiaojun Chang, and Xiaodan Liang. UPDeT: Universal multi-agent reinforcement learning via policy decoupling with transformers. InInternational Conference on Learning Representa- tions, 2021
2021
-
[9]
Actor-attention-critic for multi-agent reinforcement learning
Shariq Iqbal and Fei Sha. Actor-attention-critic for multi-agent reinforcement learning. InProceedings of the International Conference on Machine Learning, 2019
2019
-
[10]
Sarthak Jain and Byron C. Wallace. Attention is not explanation. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, 2019
2019
-
[11]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. InAdvances in Neural Information Processing Systems, 2017
2017
-
[12]
MA VEN: Multi-agent variational exploration
Anuj Mahajan, Tabish Rashid, Mikayel Samvelyan, and Shimon Whiteson. MA VEN: Multi-agent variational exploration. InAdvances in Neural Information Processing Systems, 2019
2019
-
[13]
Explainable reinforcement learning: A survey and comparative review.ACM Computing Surveys, 2024
Stephanie Milani, Nicholay Topin, Manuela Veloso, and Fei Fang. Explainable reinforcement learning: A survey and comparative review.ACM Computing Surveys, 2024. 7 TRANSLATIONGAP INCOOPERATIVEMARL
2024
-
[14]
Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder de Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. InProceedings of the International Conference on Machine Learning, 2018
2018
-
[15]
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob Foerster, and Shimon Whiteson. The StarCraft multi-agent challenge. InProceedings of the International Conference on Autonomous Agents and Multiagent Systems, 2019
2019
-
[16]
High-dimensional continuous control using generalized advantage estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. InInternational Conference on Learning Representations, 2016
2016
-
[17]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
2017
-
[19]
Roma: Multi-agent reinforcement learning with emergent roles
Tonghan Wang, Heng Dong, Victor Lesser, and Chongjie Zhang. Roma: Multi-agent reinforcement learning with emergent roles. InProceedings of the International Conference on Machine Learning, 2020
2020
-
[20]
RODE: Learning roles to decompose multi-agent tasks
Tonghan Wang, Tarun Gupta, Anuj Mahajan, Bei Peng, Shimon Whiteson, and Chongjie Zhang. RODE: Learning roles to decompose multi-agent tasks. InInternational Conference on Learning Representations, 2021
2021
-
[21]
Attention is not not explanation
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. InProceedings of the Conference on Empirical Methods in Natural Language Processing, 2019
2019
-
[22]
The surprising effectiveness of PPO in cooperative multi-agent games
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of PPO in cooperative multi-agent games. InAdvances in Neural Information Processing Systems, 2022
2022
-
[23]
Deep reinforcement learning with relational inductive biases
Vinicius Zambaldi, David Raposo, Adam Santoro, Victor Bapst, Yujia Li, Igor Babuschkin, Karl Tuyls, David Reichert, Timothy Lillicrap, Edward Lockhart, Murray Shanahan, Victoria Langston, Razvan Pascanu, Matthew Botvinick, Oriol Vinyals, and Peter Battaglia. Deep reinforcement learning with relational inductive biases. InInternational Conference on Learni...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.