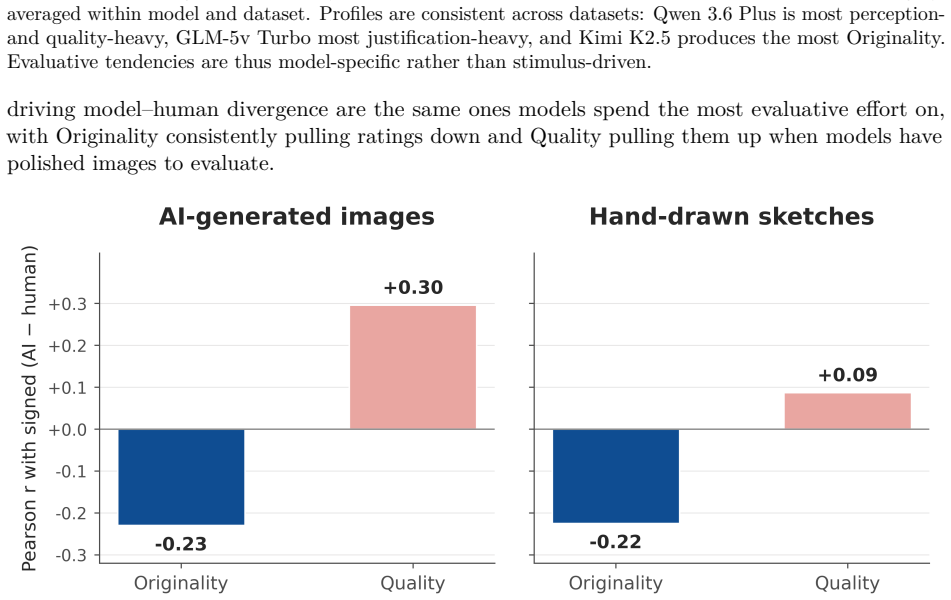
How LLMs See Creativity: Zero-Shot Scoring of Visual Creativity with Interpretable Reasoning
Pith reviewed 2026-06-30 06:47 UTC · model grok-4.3
The pith
Multimodal LLMs judge visual creativity zero-shot and align with human ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multimodal LLMs can serve as judges of visual creativity zero-shot without any fine-tuning or examples of human ratings, producing scores that align substantially with human raters on both AI-generated images and hand-drawn sketches, while their reasoning traces make the evaluation criteria interpretable.
What carries the argument
Zero-shot prompting that directs multimodal LLMs to assign creativity scores to images or drawings and to output step-by-step reasoning for each score.
If this is right
- LLMs can automate visual creativity assessment at scale without collecting new human ratings for every task.
- Model reasoning outputs reveal how evaluations balance originality against quality and what visual elements receive attention.
- The same zero-shot method applies across both AI-generated images based on prompts and hand-drawn sketches.
Where Pith is reading between the lines
- Large-scale studies of visual creativity could proceed with far fewer human raters if model scores prove stable.
- The approach invites direct comparison of model versus human criteria on the same stimuli to identify systematic differences.
- Extensions could apply the identical prompting pipeline to evaluate creativity in non-visual domains such as short stories or musical clips.
Load-bearing premise
Human ratings constitute the valid ground truth benchmark for visual creativity and model performance reflects genuine zero-shot generalization rather than overlap with training data on similar rating tasks.
What would settle it
Test the same models on a new collection of images and sketches created after the models' training data cutoff and check whether the correlations with fresh human ratings remain in the .57-.68 range.
Figures



read the original abstract
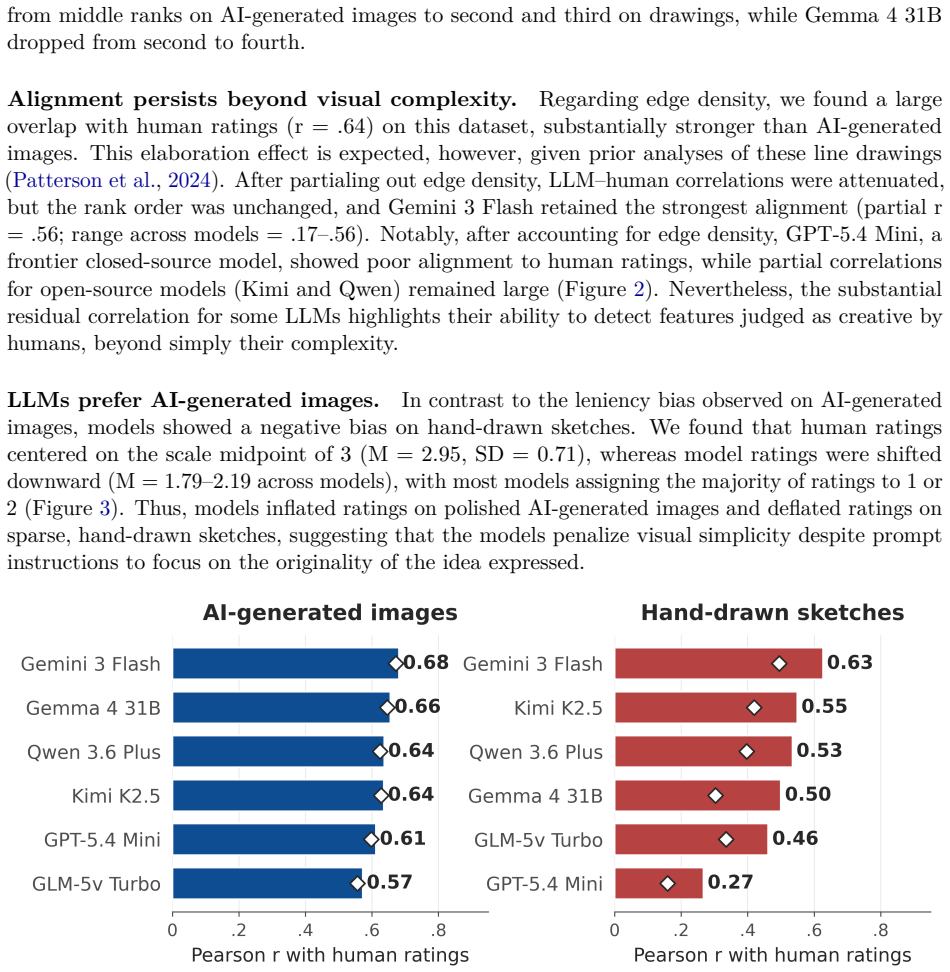
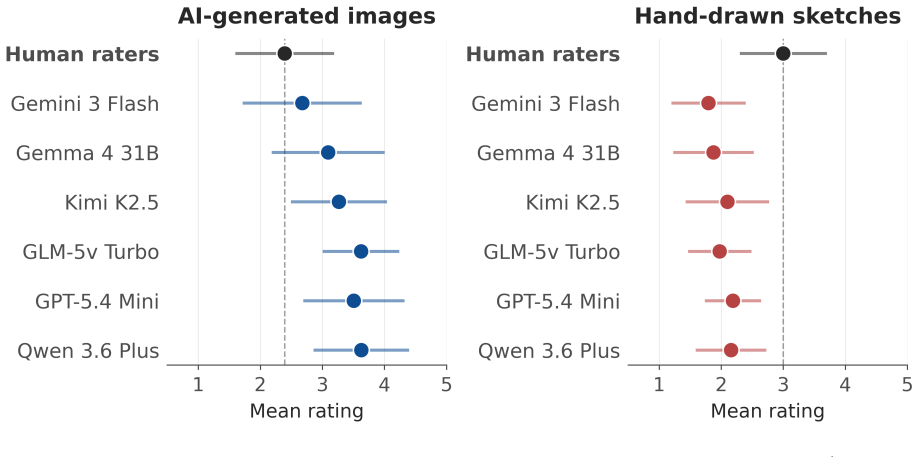
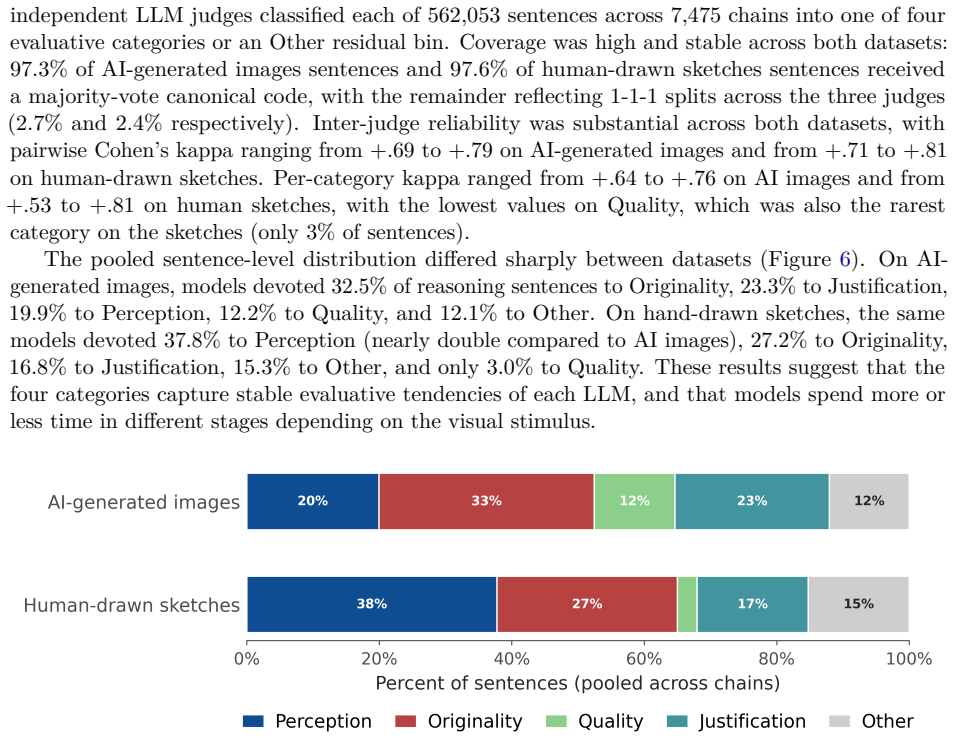
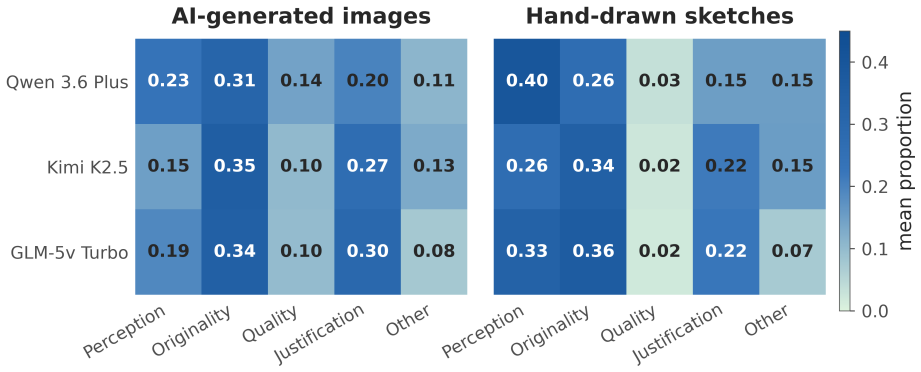
Evaluating the originality of visual images poses enduring challenges for creativity assessment. Automated scoring using AI models has proven effective in the verbal domain, yet key questions remain about evaluating visual creativity and understanding how models arrive at their ratings. The present research asks whether multimodal large language models (LLMs) can serve as judges of visual creativity zero-shot (without any fine-tuning or examples of human ratings) and whether their "reasoning" output offers an interpretable window into their evaluation process. We tested six multimodal LLMs (Gemini 3 Flash, Gemma 4 31B IT, GPT-5.4 Mini, GLM-5v Turbo, Kimi K2.5, and Qwen 3.6 Plus) on 992 AI-generated images (based on human-written prompts) and 1,500 hand-drawn sketches scored for creativity by human raters. In Study 1, all models showed substantial alignment with human creativity ratings on both datasets (r = .57-.68 on AI-generated images; r = .29-68 on sketches). In Study 2, we analyzed the step-by-step reasoning processes of three LLMs evaluating the same images and drawings. Although reasoning made model evaluations interpretable -- showing what they attend to, how they balance originality vs. quality, and how they justify their ratings -- reasoning did not improve alignment with human ratings. In sum, our findings indicate that multimodal LLMs can match human judgments of visual creativity without any additional training, and that their reasoning reveals how AI models evaluate creativity. An open scoring app implementing this pipeline is available at https://review-visual-eval-scoring.hf.space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that six multimodal LLMs (Gemini 3 Flash, Gemma 4 31B IT, GPT-5.4 Mini, GLM-5v Turbo, Kimi K2.5, Qwen 3.6 Plus) can score visual creativity zero-shot on 992 AI-generated images and 1,500 hand-drawn sketches, achieving Pearson correlations with human ratings of r=.57-.68 and r=.29-.68 respectively; Study 2 further shows that the models' step-by-step reasoning is interpretable (revealing attention to originality vs. quality) but does not improve alignment with humans. An open scoring app is provided.
Significance. If the zero-shot generalization claim is substantiated, the work would establish a scalable, training-free method for automated visual creativity assessment that extends prior LLM judging successes from verbal to visual domains, with the open app (https://review-visual-eval-scoring.hf.space) providing a concrete reproducibility asset for the community.
major comments (3)
- [Methods] Methods (zero-shot protocol description): no training-cutoff dates, decontamination checks, or out-of-distribution verification against public image-rating corpora are reported for any of the six LLMs; this directly undermines the central claim that observed correlations reflect genuine zero-shot capability rather than pretraining overlap.
- [Results (Study 1)] Results, Study 1 (correlation reporting): the ranges r=.57-.68 (AI images) and r=.29-.68 (sketches) are given without per-model breakdowns, exact sample sizes used per correlation, confidence intervals, or controls for potential confounds such as image quality or prompt similarity, making the 'substantial alignment' conclusion difficult to evaluate uniformly.
- [Study 2] Study 2 (reasoning analysis): the claim that reasoning 'did not improve alignment' requires explicit before/after correlation tables or statistical tests comparing reasoned vs. direct ratings; without these, the interpretability benefit cannot be weighed against any performance cost.
minor comments (2)
- [Abstract] Abstract: reports correlation ranges but supplies no details on statistical methods, human inter-rater reliability, or exact prompting templates, which should be summarized even at this level for reader assessment.
- Model nomenclature: names such as 'GPT-5.4 Mini' and 'Gemma 4 31B IT' should be clarified with precise version identifiers or citations to avoid ambiguity with released models.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our zero-shot evaluation protocol and results. We respond to each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods (zero-shot protocol description): no training-cutoff dates, decontamination checks, or out-of-distribution verification against public image-rating corpora are reported for any of the six LLMs; this directly undermines the central claim that observed correlations reflect genuine zero-shot capability rather than pretraining overlap.
Authors: We acknowledge the value of explicit cutoff reporting. For the open-weight models (Gemma 4, Qwen 3.6, GLM-5v), known training cutoffs will be added to the Methods section. For the proprietary models, providers do not always release exact dates, but we used the latest publicly available versions as of the study period and will note this limitation. Full decontamination is not feasible without training data access; however, the 992 AI images derive from novel human prompts and the 1,500 sketches come from a specialized creativity corpus unlikely to appear in general pretraining. We will add a brief discussion of these points and a table of model versions and known cutoffs. Out-of-distribution verification against common corpora will be noted as a limitation with supporting rationale. revision: partial
-
Referee: [Results (Study 1)] Results, Study 1 (correlation reporting): the ranges r=.57-.68 (AI images) and r=.29-.68 (sketches) are given without per-model breakdowns, exact sample sizes used per correlation, confidence intervals, or controls for potential confounds such as image quality or prompt similarity, making the 'substantial alignment' conclusion difficult to evaluate uniformly.
Authors: The full manuscript already reports per-model Pearson correlations in Tables 1 (AI images) and 2 (sketches), with N explicitly stated as 992 and 1,500 respectively. To improve clarity and address potential confounds, we will add 95% confidence intervals to all reported correlations, include a supplementary table with per-model breakdowns, and add controls: partial correlations removing variance due to aesthetic quality ratings (where available) and a note on prompt diversity metrics to address similarity concerns. These changes will allow uniform evaluation of the alignment results. revision: yes
-
Referee: [Study 2] Study 2 (reasoning analysis): the claim that reasoning 'did not improve alignment' requires explicit before/after correlation tables or statistical tests comparing reasoned vs. direct ratings; without these, the interpretability benefit cannot be weighed against any performance cost.
Authors: We will revise the Study 2 section to include an explicit comparison table listing Pearson r values for direct versus reasoned scoring for each of the three models. We will also add statistical tests (Steiger’s test for dependent correlations) to evaluate whether the differences are significant. This will make the finding that reasoning did not improve alignment fully transparent while preserving the interpretability analysis. revision: yes
Circularity Check
Empirical correlation study with no derivations or self-referential steps
full rationale
The paper reports direct empirical correlations (r values) between LLM zero-shot ratings and external human creativity ratings on two image datasets. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the abstract or described methods. The central claim is tested against independent human benchmarks rather than reducing to any internal definition or prior author result by construction. This matches the default non-circular case for an empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Journal of Creative Behavior , volume =
Acar, Selcuk and Organisciak, Peter and Dumas, Denis , title =. The Journal of Creative Behavior , volume =. 2025 , doi =
2025
-
[2]
, title =
Amabile, Teresa M. , title =. Journal of Personality and Social Psychology , volume =. 1982 , doi =
1982
-
[3]
SPARC: Separating Perception And Reasoning Circuits for Test-time Scaling of VLMs
Avogaro, Niccolo and Debnath, Nayanika and Mi, Li and Frick, Thomas and Wang, Junling and He, Zexue and Hua, Hang and Schindler, Konrad and Rigotti, Mattia , title =. 2026 , note =. doi:10.48550/arXiv.2602.06566 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.06566 2026
-
[4]
and Johnson, Dan R
Beaty, Roger E. and Johnson, Dan R. , title =. Behavior Research Methods , volume =. 2021 , doi =
2021
-
[5]
Chiang, Cheng-Han and Lee, Hung-yi , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , publisher =. doi:10.18653/v1/2023.acl-long.870 , url =
-
[6]
and Marrone, Rebecca L
Cropley, David H. and Marrone, Rebecca L. , title =. Psychology of Aesthetics, Creativity, and the Arts , volume =. 2025 , doi =
2025
-
[7]
and Theurer, Caroline and Mathijssen, Anne C
Cropley, David H. and Theurer, Caroline and Mathijssen, Anne C. S. and Marrone, Rebecca L. , title =. Creativity Research Journal , volume =. 2025 , doi =
2025
-
[8]
and Patterson, John D
DiStefano, Paul V. and Patterson, John D. and Beaty, Roger E. , title =. Creativity Research Journal , volume =. 2025 , doi =
2025
-
[9]
The Effect of Idea Elaboration on the Automatic Assessment of Idea Originality
Domanti, Umberto and Mock, Moritz and Agnoli, Sergio and De Angeli, Antonella , title =. 2026 , note =. doi:10.48550/arXiv.2604.20569 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.20569 2026
-
[10]
A Survey on In-context Learning
Dong, Qingxiu and Li, Lei and Dai, Damai and Zheng, Ce and Ma, Jingyuan and Li, Rui and Xia, Heming and Xu, Jingjing and Wu, Zhiyong and Chang, Baobao and Sun, Xu and Li, Lei and Sui, Zhifang , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , publisher =. doi:10.18653/v1/2024.emnlp-main.64 , url =
-
[11]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
2025
-
[12]
Jiang, Chaoya and Heng, Yongrui and Ye, Wei and Yang, Han and Xu, Haiyang and Yan, Ming and Zhang, Ji and Huang, Fei and Zhang, Shikun , title =. 2025 , note =. doi:10.48550/arXiv.2505.16192 , eprint =
-
[13]
and Maliakkal, Nadine T
Luchini, Simone A. and Maliakkal, Nadine T. and DiStefano, Paul V. and Laverghetta, Antonio and Patterson, John D. and Beaty, Roger E. and Reiter-Palmon, Roni , title =. Psychology of Aesthetics, Creativity, and the Arts , year =
-
[14]
Psychology of Aesthetics, Creativity, and the Arts , volume =
Myszkowski, Nils and Storme, Martin , title =. Psychology of Aesthetics, Creativity, and the Arts , volume =. 2019 , doi =
2019
-
[15]
Thinking Skills and Creativity , volume =
Organisciak, Peter and Acar, Selcuk and Dumas, Denis and Berthiaume, Kelly , title =. Thinking Skills and Creativity , volume =. 2023 , doi =
2023
-
[16]
and Barr, Nathaniel and Seli, Paul , title =
Orwig, William and Bellaiche, Lucas and Spooner, Sarah and Vo, Anh and Baig, Zia and Ragnhildstveit, Anya and Schacter, Daniel L. and Barr, Nathaniel and Seli, Paul , title =. Creativity Research Journal , volume =. 2026 , doi =
2026
-
[17]
and Greene, Joshua D
Orwig, William and Edenbaum, Emma R. and Greene, Joshua D. and Schacter, Daniel L. , title =. The Journal of Creative Behavior , volume =. 2024 , doi =
2024
-
[18]
and Feng, Shi , title =
Panickssery, Arjun and Bowman, Samuel R. and Feng, Shi , title =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[19]
and Barbot, Baptiste and Lloyd-Cox, James and Beaty, Roger E
Patterson, John D. and Barbot, Baptiste and Lloyd-Cox, James and Beaty, Roger E. , title =. Behavior Research Methods , volume =. 2024 , doi =
2024
-
[20]
and Pronchick, Jimmy and Panchanadikar, Ruchi and Fuge, Mark and van Hell, Janet G
Patterson, John D. and Pronchick, Jimmy and Panchanadikar, Ruchi and Fuge, Mark and van Hell, Janet G. and Miller, Scarlett R. and Johnson, Dan R. and Beaty, Roger E. , title =. Behavior Research Methods , volume =. 2025 , doi =
2025
-
[21]
and Kaufman, James C
Rafner, Janet and Beaty, Roger E. and Kaufman, James C. and Lubart, Todd and Sherson, Jacob , title =. Nature Human Behaviour , volume =. 2023 , doi =
2023
-
[22]
Journal of Intelligence , volume =
Saretzki, Janika and Knopf, Thomas and Forthmann, Boris and Goecke, Benjamin and Jaggy, Ann-Kathrin and Benedek, Mathias and Weiss, Selina , title =. Journal of Intelligence , volume =. 2025 , doi =
2025
-
[23]
and Winterstein, Beate P
Silvia, Paul J. and Winterstein, Beate P. and Willse, John T. and Barona, Christopher M. and Cram, Joshua T. and Hess, Karl I. and Martinez, Jenna L. and Richard, Crystal A. , title =. Psychology of Aesthetics, Creativity, and the Arts , volume =. 2008 , doi =
2008
-
[24]
Self-Preference Bias in LLM-as-a-Judge
Wataoka, Koki and Takahashi, Tsubasa and Ri, Ryokan , title =. 2024 , note =. doi:10.48550/arXiv.2410.21819 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21819 2024
-
[25]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[26]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.