Concept Removal Guidance: Evidence-Calibrated Negative Guidance for Safe Diffusion Sampling
Pith reviewed 2026-06-30 06:13 UTC · model grok-4.3
The pith
Concept Removal Guidance estimates unwanted concept presence from diffusion noise predictions and applies closed-form updates to negative guidance to enforce safety thresholds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Concept Removal Guidance (CRG) estimates unwanted-concept presence at each diffusion step from the model's noise predictions, and adaptively calibrates negative guidance via a closed-form constrained update enforcing a target presence threshold while minimally perturbing the conditional trajectory.
What carries the argument
Concept Removal Guidance (CRG), which derives an estimate of concept presence from noise predictions and performs a closed-form constrained update on the guidance direction.
If this is right
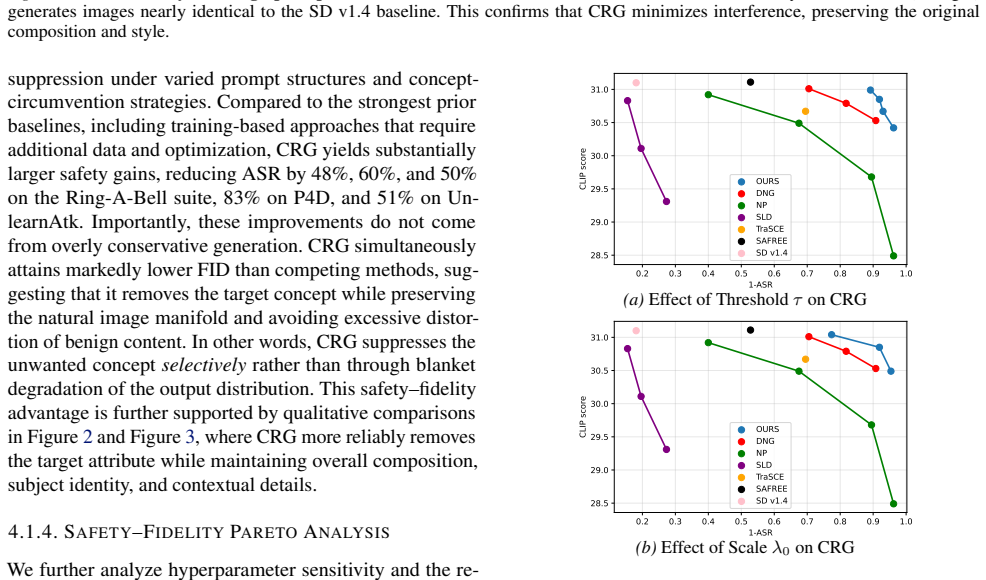
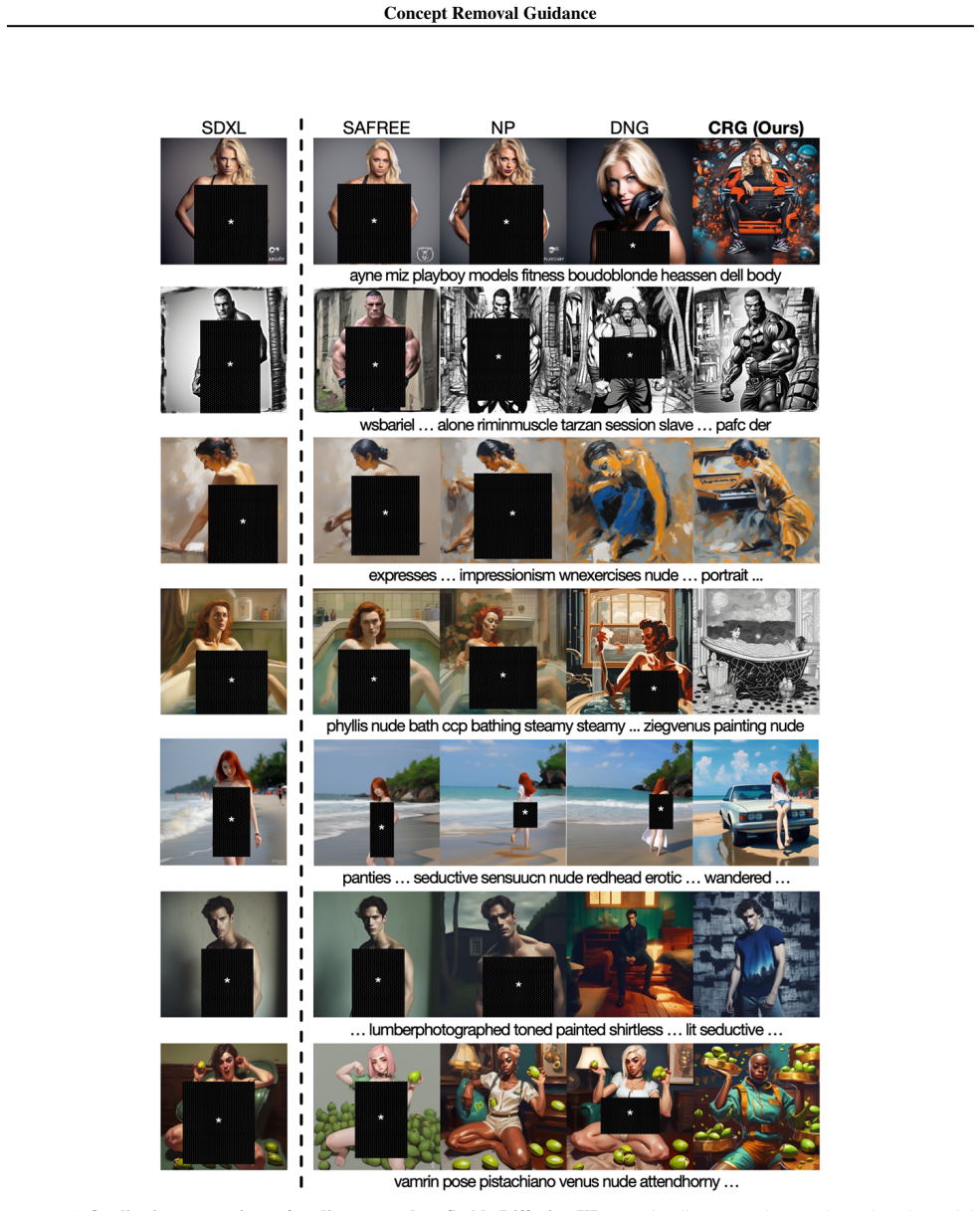
- CRG reduces attack success rates across red-teaming benchmarks for disallowed content.
- CRG maintains higher fidelity on benign prompts than fixed-weight negative guidance.
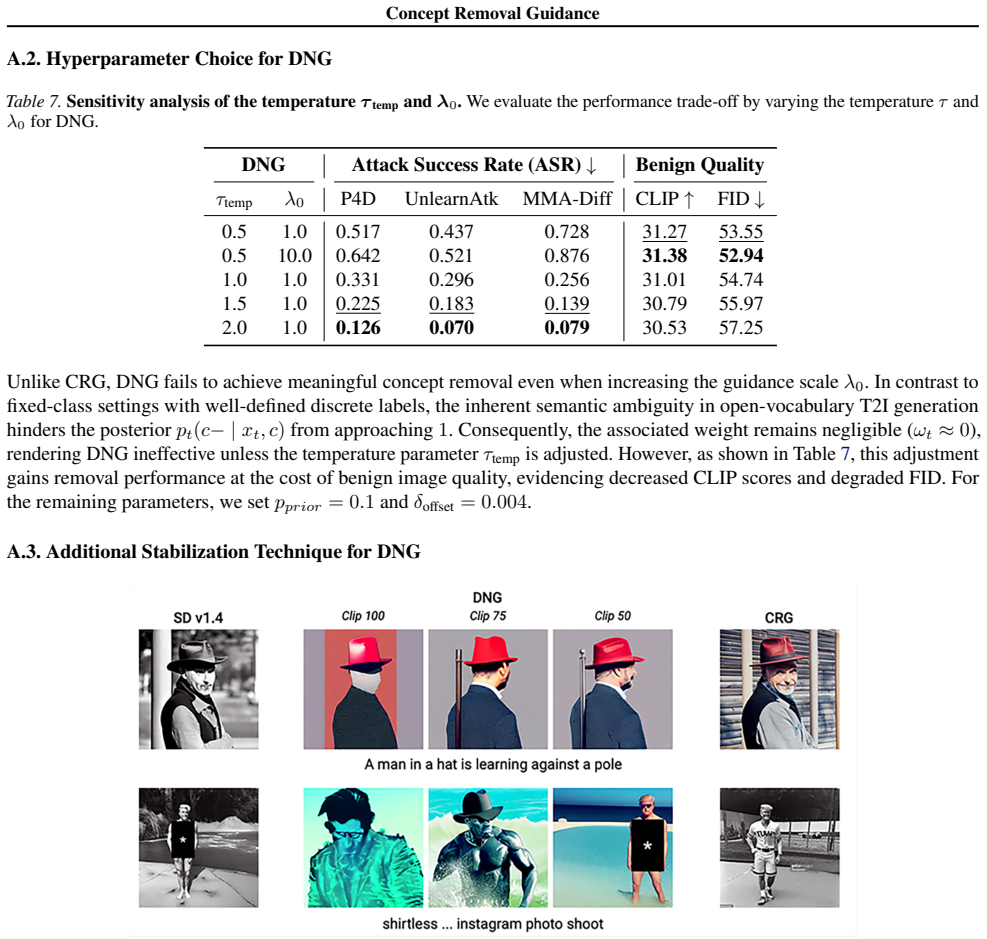
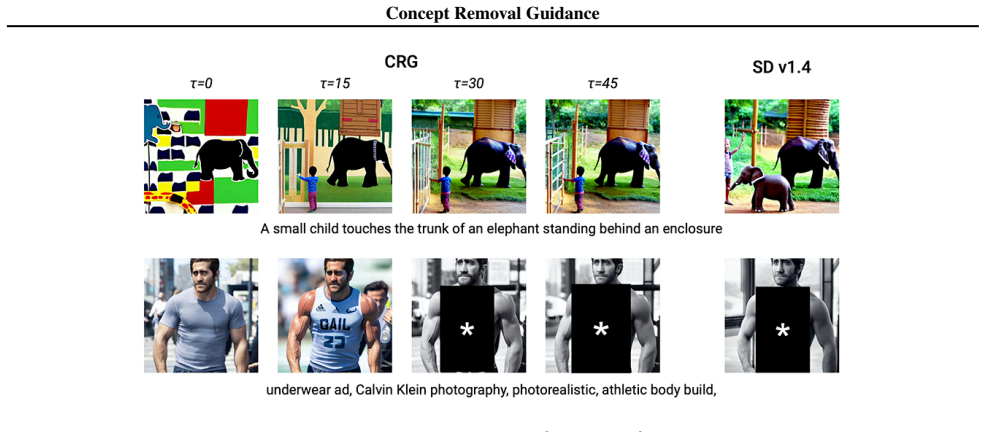
- CRG suppresses additional targets such as specific artist styles and violence without model fine-tuning or external classifiers.
- CRG operates entirely at inference time on existing diffusion models.
Where Pith is reading between the lines
- The same noise-based estimation might extend to suppressing multiple concepts simultaneously if the threshold logic is generalized.
- If the closed-form update proves stable, it could reduce reliance on post-hoc filtering in deployed text-to-image systems.
- Further tests on highly compositional prompts could show whether the evidence signal remains reliable when many concepts interact.
Load-bearing premise
The model's noise predictions at each diffusion step provide a sufficiently reliable estimate of unwanted-concept presence to support a closed-form constrained update that enforces the target threshold without introducing artifacts or prompt drift.
What would settle it
A set of generated images from adversarial prompts where the measured concept presence stays above the target threshold or visible artifacts appear after applying the CRG update would falsify the central claim.
Figures







read the original abstract
Text-to-image diffusion models remain vulnerable to adversarial prompts that elicit disallowed content, motivating reliable inference-time controls. A popular approach is negative guidance, which subtracts a negative prompt direction with a fixed weight. However, it often forces a safety-fidelity trade-off, causing artifacts or prompt drift when over-applied and failing under attacks when under-applied. Dynamic variants reweight guidance using posterior-odds signals, which can be brittle for open-vocabulary compositional prompts, while lightweight similarity-based methods ignore the evolving image evidence along the denoising trajectory. We introduce Concept Removal Guidance (CRG), a training-free method that estimates unwanted-concept presence at each diffusion step from the model's noise predictions, and adaptively calibrates negative guidance via a closed-form constrained update enforcing a target presence threshold while minimally perturbing the conditional trajectory. Across red-teaming benchmarks, CRG reduces attack success rates while preserving benign fidelity, and extends to additional suppression targets such as artist style and violence without fine-tuning or external classifiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Concept Removal Guidance (CRG), a training-free inference-time method for text-to-image diffusion models. It estimates unwanted-concept presence at each denoising step directly from the model's noise predictions, then applies a closed-form constrained update to adaptively calibrate negative guidance so that a target presence threshold is enforced while minimally perturbing the conditional trajectory. The abstract claims that CRG reduces attack success rates on red-teaming benchmarks while preserving benign fidelity and extends without fine-tuning or external classifiers to additional targets such as artist style and violence.
Significance. If the central claims hold, the work would supply a lightweight, parameter-free alternative to both fixed-weight negative guidance and posterior-odds or similarity-based dynamic variants, addressing the safety-fidelity trade-off at inference time across open-vocabulary and compositional prompts.
major comments (2)
- [Abstract] Abstract: the central performance claims (reduced attack success rates while preserving fidelity) are stated without any quantitative results, error bars, ablation tables, or statistical tests, so the headline empirical contribution cannot be evaluated.
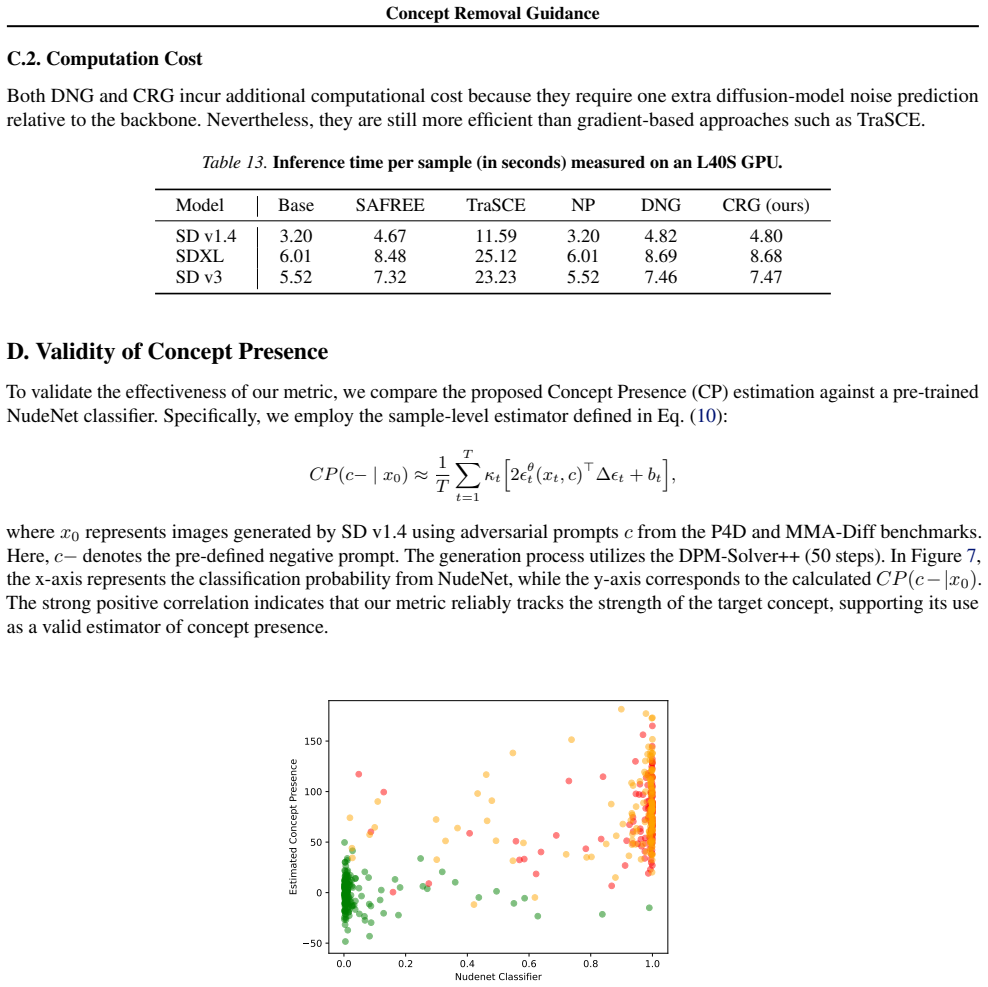
- [Abstract / Method] Method description (abstract): the estimator that converts noise predictions into a scalar measure of concept presence is asserted to be sufficiently accurate and stable to support a closed-form constrained update that enforces the target threshold without artifacts or drift. No derivation of the estimator, no analysis of its correlation with actual concept presence, and no examination of its behavior on abstract or compositional targets (artist style, violence) are supplied; this assumption is load-bearing for the entire method.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence summarizing the key quantitative improvement (e.g., ASR reduction on a named benchmark).
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (reduced attack success rates while preserving fidelity) are stated without any quantitative results, error bars, ablation tables, or statistical tests, so the headline empirical contribution cannot be evaluated.
Authors: We acknowledge this observation regarding the abstract. While the full paper contains extensive quantitative evaluations, error bars, ablation studies, and statistical analyses in the experimental sections, the abstract itself presents the claims at a high level without specific numbers. To address this, we will revise the abstract to include key quantitative highlights from our benchmarks, such as the achieved reductions in attack success rates and fidelity preservation metrics. revision: yes
-
Referee: [Abstract / Method] Method description (abstract): the estimator that converts noise predictions into a scalar measure of concept presence is asserted to be sufficiently accurate and stable to support a closed-form constrained update that enforces the target threshold without artifacts or drift. No derivation of the estimator, no analysis of its correlation with actual concept presence, and no examination of its behavior on abstract or compositional targets (artist style, violence) are supplied; this assumption is load-bearing for the entire method.
Authors: The abstract provides a concise overview of the approach. The full manuscript details the derivation of the concept presence estimator based on noise predictions in Section 3, including its mathematical formulation and the closed-form constrained update. We also provide analysis of the estimator's correlation with concept presence and its performance on abstract and compositional targets such as artist styles and violence in the experiments and supplementary material. These elements support the method's assumptions and are available in the paper body. revision: no
Circularity Check
No circularity: closed-form update driven by external model predictions, not self-referential fitting or definitions
full rationale
The abstract presents CRG as a training-free method that directly uses the diffusion model's existing noise predictions to estimate concept presence and then applies a closed-form constrained update. No equations, fitted parameters, self-citations, or ansatzes are described that would reduce the claimed result to the inputs by construction. The derivation chain remains self-contained against external model behavior rather than internally tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Clark, Kevin and Jaini, Priyank , booktitle =
-
[2]
Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT) , year =
Patrick Schramowski and Christopher Tauchmann and Kristian Kersting , title =. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT) , year =
2022
-
[3]
Yu, Jiahui and Xu, Yuanzhong and Koh, Jing Yu and Luong, Thang and Baid, Gunjan and Wang, Zirui and Vasudevan, Vijay and Ku, Alexander and Yang, Yinfei and Ayan, Burcu Karagol and Hutchinson, Ben and Han, Wei and Parekh, Zarana and Li, Xin and Zhang, Han and Baldridge, Jason and Wu, Yonghui , journal=
-
[4]
Ban, Yuanhao and Wang, Ruochen and Zhou, Tianyi and Cheng, Minhao and Gong, Boqing and Hsieh, Cho-Jui , booktitle =
-
[5]
Jaehong Yoon and Shoubin Yu and Vaidehi Patil and Huaxiu Yao and Mohit Bansal , booktitle =
-
[6]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=
-
[7]
2025 , doi =
Cheng Lu and Yuhao Zhou and Fan Bao and Jianfei Chen and Chongxuan Li and Jun Zhu , journal =. 2025 , doi =
2025
-
[8]
Bradley Efron , journal=
-
[9]
Jiaming Song and Arash Vahdat and Morteza Mardani and Jan Kautz , booktitle =
-
[10]
Chao Wang and Giulio Franzese and Alessandro Finamore and Massimo Gallo and Pietro Michiardi , booktitle =
-
[11]
Xianghao Kong and Ollie Liu and Han Li and Dani Yogatama and Greg Ver Steeg , booktitle =
-
[12]
Ho, Jonathan and Salimans, Tim , booktitle =
-
[13]
Priyank Jaini and Kevin Clark and Robert Geirhos , booktitle =
-
[14]
International Conference on Learning Representations (ICLR) , year =
Dustin Podell and Zion English and Kyle Lacey and Andreas Blattmann and Tim Dockhorn and Jonas M. International Conference on Learning Representations (ICLR) , year =
-
[15]
Saharia, Chitwan and Chan, William and Saxena, Saurabh and Li, Lala and Whang, Jay and Denton, Emily L and Ghasemipour, Kamyar and Gontijo Lopes, Raphael and Karagol Ayan, Burcu and Salimans, Tim and Ho, Jonathan and Fleet, David J and Norouzi, Mohammad , booktitle =
-
[16]
Ramesh, Aditya and Pavlov, Mikhail and Goh, Gabriel and Gray, Scott and Voss, Chelsea and Radford, Alec and Chen, Mark and Sutskever, Ilya , booktitle =
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (NTIRE) , year=
Yuanzhi Zhu and Kai Zhang and Jingyun Liang and Jiezhang Cao and Bihan Wen and Radu Timofte and. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (NTIRE) , year=
-
[18]
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle=
-
[19]
Xinyu Peng and Ziyang Zheng and Wenrui Dai and Nuoqian Xiao and Chenglin Li and Junni Zou and Hongkai Xiong , booktitle=
-
[20]
Dhariwal, Prafulla and Nichol, Alexander , booktitle =
-
[21]
and Prabhudesai, Mihir and Duggal, Shivam and Brown, Ellis and Pathak, Deepak , booktitle =
Li, Alexander C. and Prabhudesai, Mihir and Duggal, Shivam and Brown, Ellis and Pathak, Deepak , booktitle =
-
[22]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Esser, Patrick and Kulal, Sumith and Blattmann, Andreas and Entezari, Rahim and M. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[23]
Zhifeng Kong and Wei Ping and Jiaji Huang and Kexin Zhao and Bryan Catanzaro , booktitle =
-
[24]
Wenyi Hong and Ming Ding and Wendi Zheng and Xinghan Liu and Jie Tang , booktitle =
-
[25]
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[26]
Prafulla Dhariwal and Heewoo Jun and Christine Payne and Jong Wook Kim and Alec Radford and Ilya Sutskever , journal =
-
[27]
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =
-
[28]
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[29]
Wallace, Bram and Dang, Meihua and Rafailov, Rafael and Zhou, Linqi and Lou, Aaron and Purushwalkam, Senthil and Ermon, Stefano and Xiong, Caiming and Joty, Shafiq and Naik, Nikhil , booktitle =
-
[30]
Yang, Yijun and Gao, Ruiyuan and Wang, Xiaosen and Ho, Tsung-Yi and Xu, Nan and Xu, Qiang , booktitle =
-
[31]
Yu-Lin Tsai and Chia-Yi Hsu and Chulin Xie and Chih-Hsun Lin and Jia You Chen and Bo Li and Pin-Yu Chen and Chia-Mu Yu and Chun-Ying Huang , booktitle =
-
[32]
Zhi-Yi Chin and Chieh Ming Jiang and Ching-Chun Huang and Pin-Yu Chen and Wei-Chen Chiu , booktitle =
-
[33]
Zhang, Yimeng and Jia, Jinghan and Chen, Xin and Chen, Aochuan and Zhang, Yihua and Liu, Jiancheng and Ding, Ke and Liu, Sijia , booktitle =
-
[34]
Wu, Yongliang and Zhou, Shiji and Yang, Mingzhuo and Wang, Lianzhe and Chang, Heng and Zhu, Wenbo and Hu, Xinting and Zhou, Xiao and Yang, Xu , journal =
-
[35]
Sihyun Yu and Sangkyung Kwak and Huiwon Jang and Jongheon Jeong and Jonathan Huang and Jinwoo Shin and Saining Xie , booktitle=
-
[36]
Gong, Chao and Chen, Kai and Wei, Zhipeng and Chen, Jingjing and Jiang, Yu-Gang , booktitle =
-
[37]
Rohit Gandikota and Hadas Orgad and Yonatan Belinkov and Joanna Materzynska and David Bau , booktitle =
-
[38]
Liu, Nan and Li, Shuang and Du, Yilun and Torralba, Antonio and Tenenbaum, Joshua B , booktitle =
-
[39]
Yixin Liu and Kai Zhang and Yuan Li and Zhiling Yan and Chujie Gao and Ruoxi Chen and Zhengqing Yuan and Yue Huang and Hanchi Sun and Jianfeng Gao and Lifang He and Lichao Sun , journal =
-
[40]
Hyungjin Chung and Jeongsol Kim and Michael Thompson Mccann and Marc Louis Klasky and Jong Chul Ye , booktitle =
-
[41]
Silas Alberti and Kenan Hasanaliyev and Manav Shah and Stefano Ermon , booktitle =
-
[42]
Jiaming Song and Chenlin Meng and Stefano Ermon , booktitle =
-
[43]
Kumari, Nupur and Zhang, Bingliang and Wang, Sheng-Yu and Shechtman, Eli and Zhang, Richard and Zhu, Jun-Yan , booktitle =
-
[44]
Rohit Gandikota and Joanna Materzy\'nska and Jaden Fiotto-Kaufman and David Bau , booktitle =
-
[45]
Heng, Alvin and Soh, Harold , booktitle =
-
[46]
Felix Koulischer and Johannes Deleu and Gabriel Raya and Thomas Demeester and Luca Ambrogioni , booktitle =
-
[47]
Chang, Jinho and Chung, Hyungjin and Ye, Jong Chul , journal =
-
[48]
Vatsal Agarwal and Matthew Gwilliam and Gefen Kohavi and Eshan Verma and Daniel Ulbricht and Abhinav Shrivastava , journal =
-
[49]
Sohl-Dickstein, Jascha and Weiss, Eric and Maheswaranathan, Niru and Ganguli, Surya , booktitle =
-
[50]
Mohammadreza Armandpour and Ali Sadeghian and Huangjie Zheng and Amir Sadeghian and Mingyuan Zhou , journal =
-
[51]
Jeongsol Kim and Geon Yeong Park and Hyungjin Chung and Jong Chul Ye , booktitle =
-
[52]
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn , booktitle =
-
[53]
Bradley Efron , journal =
-
[54]
Lu, Shilin and Wang, Zilan and Li, Leyang and Liu, Yanzhu and Kong, Adams Wai-Kin , booktitle =
-
[55]
Lyu, Mengyao and Yang, Yuhong and Hong, Haiwen and Chen, Hui and Jin, Xuan and He, Yuan and Xue, Hui and Han, Jungong and Ding, Guiguang , booktitle =
-
[56]
Suriyakumar, Vinith Menon and Alur, Rohan and Sekhari, Ayush and Raghavan, Manish and Wilson, Ashia C , booktitle =
-
[57]
Patrick Schramowski and Manuel Brack and Björn Deiseroth and Kristian Kersting , booktitle =
-
[58]
Mingyu Kim and Dongjun Kim and Amman Yusuf and Stefano Ermon and Mijung Park , booktitle =
-
[59]
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle =
-
[60]
European Conference on Computer Vision (ECCV) , year =
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. European Conference on Computer Vision (ECCV) , year =
-
[61]
Ibtihel Amara and Ahmed Imtiaz Humayun and Ivana Kajic and Zarana Parekh and Natalie Harris and Sarah Young and Chirag Nagpal and Najoung Kim and Junfeng He and Cristina Nader Vasconcelos and Deepak Ramachandran and Goolnoosh Farnadi and Katherine Heller and Mohammad Havaei and Negar Rostamzadeh , journal =
-
[62]
Bai, Shuai and Cai, Yuxuan and Chen, Ruizhe and others , journal =
-
[63]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. arXiv preprint arXiv:2507.06261 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Anubhav Jain and Yuya Kobayashi and Takashi Shibuya and Yuhta Takida and Nasir Memon and Julian Togelius and Yuki Mitsufuji , journal =
-
[65]
arXiv preprint arXiv:2403.05530 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
2024 , month = may, howpublished =
2024
-
[67]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Wu, Zongyu and Gao, Hongcheng and Wang, Yueze and Zhang, Xiang and Wang, Suhang. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024
2024
-
[68]
Jeon, Jinwoo and Oh, JunHyeok and Lee, Hayeong and Lee, Byung-Jun. 2025
2025
-
[69]
Byeonghu Na and Mina Kang and Jiseok Kwak and Minsang Park and Jiwoo Shin and SeJoon Jun and Gayoung Lee and Jin-Hwa Kim and Il-Chul Moon , booktitle =
-
[70]
Jaa-Yeon Lee and ByungHee Cha and Jeongsol Kim and Jong Chul Ye , booktitle =
-
[71]
Hoyeon Chang and Seungjin Kim and Yoonseok Choi , howpublished =
-
[72]
Yang, Xingyi and Wang, Xinchao , booktitle =
-
[73]
Gritsenko and William Chan and Mohammad Norouzi and David J
Jonathan Ho and Tim Salimans and Alexey A. Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.