LLM Agents Are Latent Context Managers: Eliciting Self-Managed Context via a Proprioceptive Dashboard
Pith reviewed 2026-06-30 06:24 UTC · model grok-4.3
The pith
A visible internal-state dashboard lets LLM agents self-manage context without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
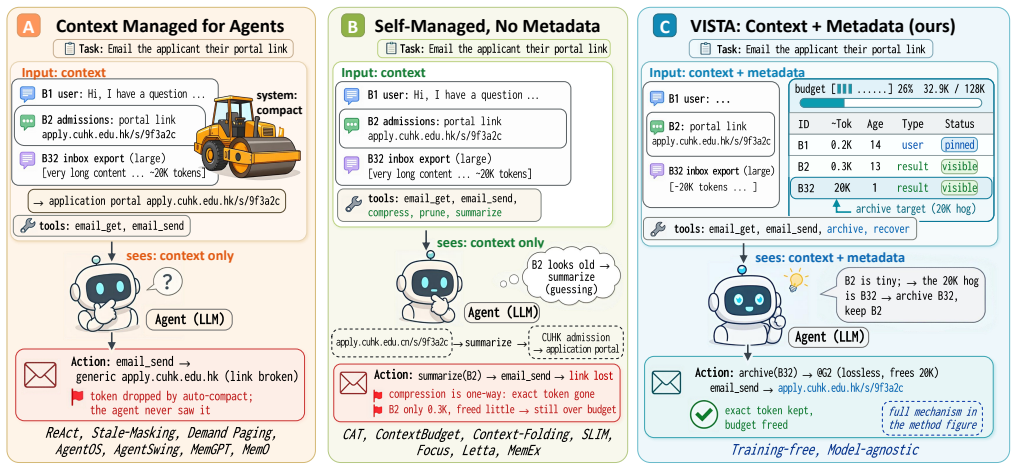
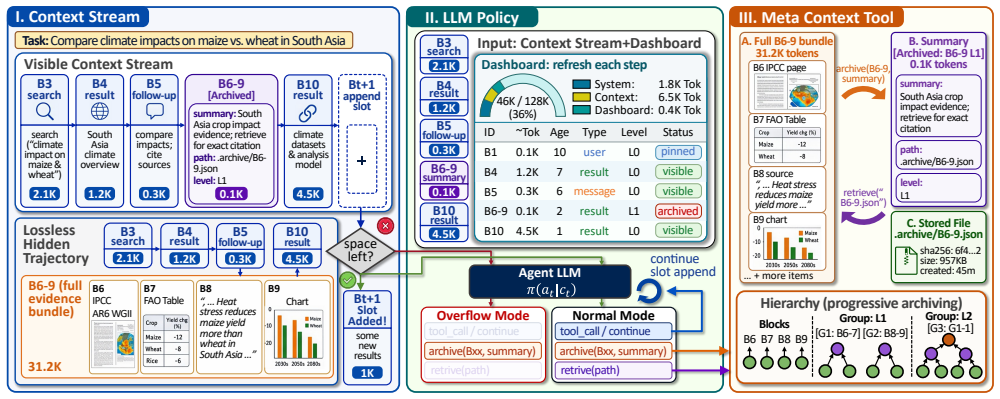
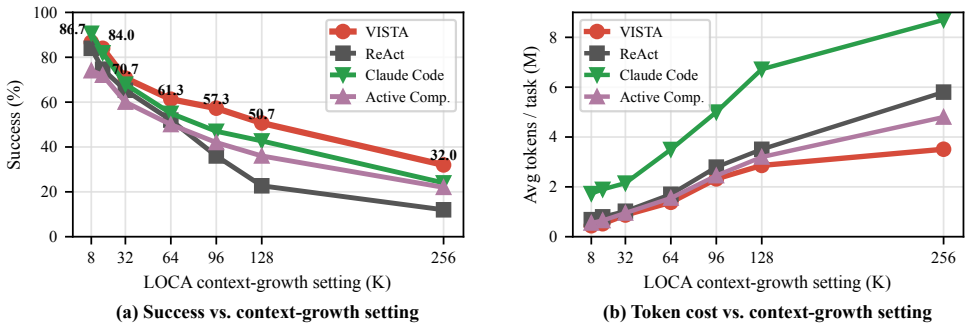
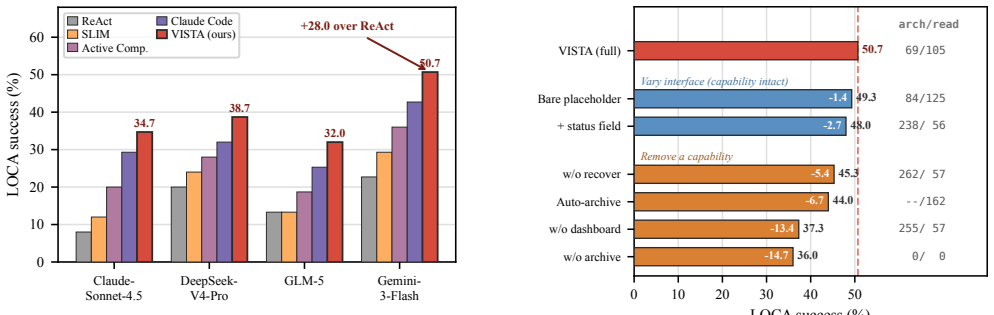
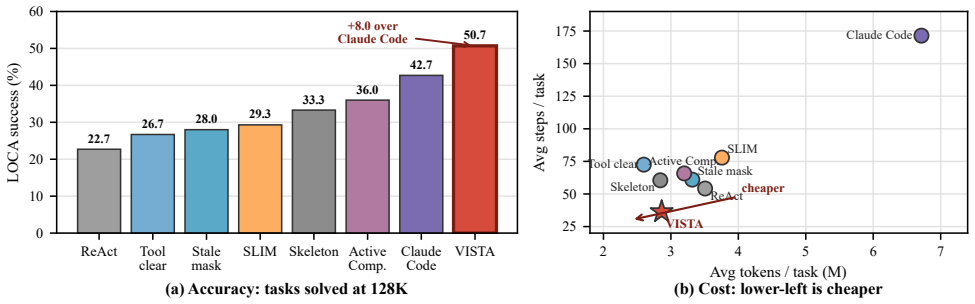
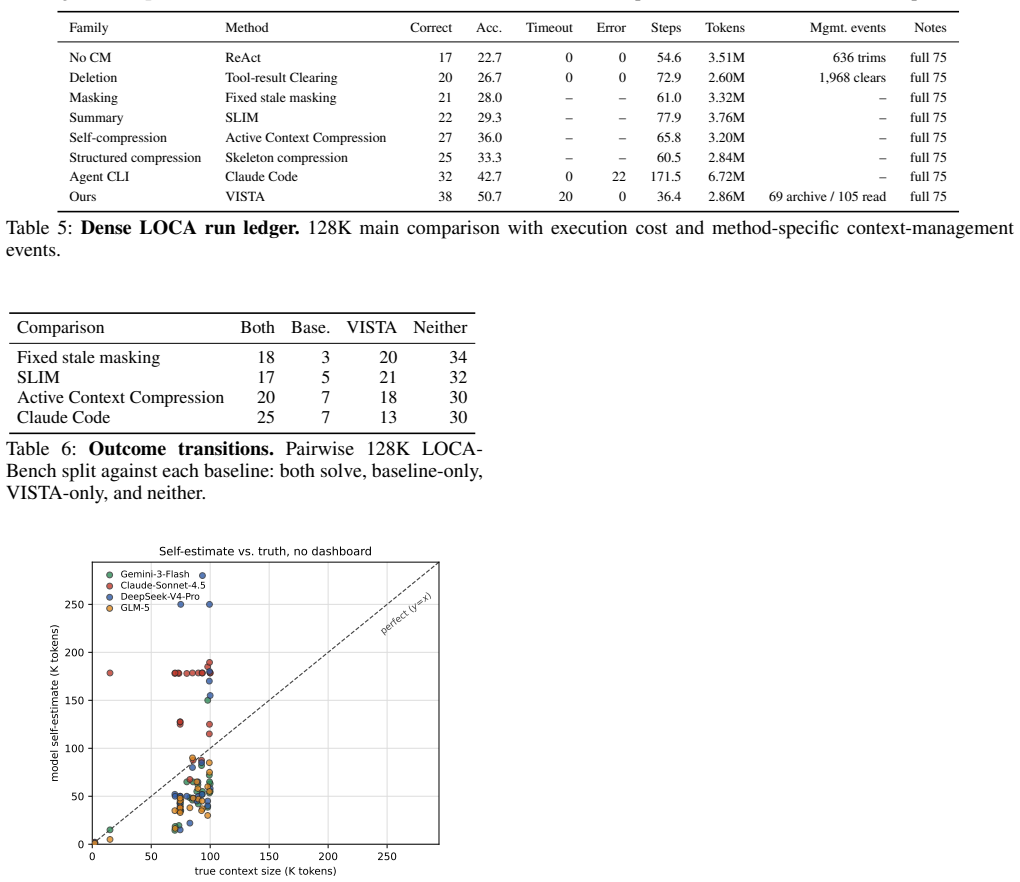
Competent context management is latent inside capable models; the missing piece is an interface that surfaces per-block token usage, recency, and access history so the model can keep or archive blocks itself. VISTA implements this interface as a training-free, model-agnostic layer that represents working memory as typed addressable blocks, provides the dashboard at runtime, and stores blocks as recoverable full-fidelity payloads. On LOCA-Bench the interface lifts four backbones and the lift grows with context pressure; the same layer transfers to BrowseComp-Plus and GAIA.
What carries the argument
VISTA (Visible Internal State for Tool Agents), the training-free layer that turns working memory into typed addressable blocks and exposes a runtime dashboard of per-block token usage, recency, and access history.
If this is right
- The same untrained interface improves four different backbones on LOCA-Bench.
- Performance lift increases as context pressure grows.
- Gains transfer across models with million-, 100 K-, and 10 K-scale trajectories.
- Ablations show the dashboard contributes beyond archive and recovery tools alone.
Where Pith is reading between the lines
- Similar visibility layers could be tested on non-agent long-context tasks such as multi-document reasoning.
- If the dashboard works, agents might sustain coherent behavior over trajectories that exceed current context windows by dynamically archiving and restoring blocks.
- The result suggests many apparent limits in agent reliability may trace to hidden rather than absent internal state.
Load-bearing premise
The paper assumes that capable models already possess competent context-management skills that only need to be made visible by an interface.
What would settle it
Providing the dashboard and archive tools to the same backbones on LOCA-Bench would produce no accuracy gain if the latent-competence claim is false.
Figures
read the original abstract
Long-horizon tool agents are bottlenecked by how their context grows toward the limits of the context window. Recent systems make context management agent- or system-controlled, but they either learn a compression policy that discards evidence or manage context in a layer the agent never sees. We argue both leave a more basic gap unaddressed. Frontier language models are proprioceptively blind to their own context. From the prompt alone they cannot see how large, how old, or how used each block is, the signals a keep-or-drop decision needs. We hypothesize that competent context management is already latent in capable models, and that what is missing is not a learned policy but an interface exposing this state. We introduce VISTA (Visible Internal State for Tool Agents), a training-free, model-agnostic layer that represents working memory as typed, addressable blocks, surfaces a runtime dashboard of per-block token usage, recency, and access history, and archives blocks as recoverable full-fidelity payloads. On LOCA-Bench, BrowseComp-Plus, and GAIA, the same untrained interface transfers across million-, 100K-, and 10K-scale trajectories. On LOCA-Bench it improves four backbones and lifts Gemini-3-Flash from 22.7 to 50.7%. The lift grows with context pressure and transfers across backbones. Ablations further confirm that the dashboard matters beyond archive and recovery tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that frontier LLMs possess latent context-management competence but are proprioceptively blind to their own context state from the prompt alone. It introduces VISTA, a training-free and model-agnostic dashboard that represents working memory as typed addressable blocks and surfaces per-block token usage, recency, and access history (plus archive/recovery tools). On LOCA-Bench, BrowseComp-Plus, and GAIA the interface improves four backbones, lifts Gemini-3-Flash from 22.7% to 50.7% on LOCA-Bench, with the lift scaling with context pressure and transferring across models; ablations isolate the dashboard's contribution beyond archive/recovery.
Significance. If the reported gains prove robust, the result would be significant because it shows that explicit state exposure can elicit competent context management without learned policies or external controllers. The training-free, model-agnostic transfer across million-, 100K-, and 10K-scale trajectories and the scaling with context pressure are notable strengths that could simplify long-horizon agent design.
major comments (1)
- [Abstract and §4] Abstract and §4 (Experimental results): the central claim rests on concrete lifts (Gemini-3-Flash 22.7% → 50.7% on LOCA-Bench; gains on three benchmarks across four backbones). The provided description supplies no information on number of runs, error bars, statistical significance, or whether the dashboard was the sole change, leaving the attribution to VISTA only weakly supported.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential significance of our work. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental results): the central claim rests on concrete lifts (Gemini-3-Flash 22.7% → 50.7% on LOCA-Bench; gains on three benchmarks across four backbones). The provided description supplies no information on number of runs, error bars, statistical significance, or whether the dashboard was the sole change, leaving the attribution to VISTA only weakly supported.
Authors: We agree that the current manuscript does not provide sufficient details on the experimental protocol to allow full assessment of the results' reliability. In the revised version, we will report that all experiments were run with 5 independent trials per condition, include error bars (standard deviation) in the result tables and figures, and add statistical significance testing (paired t-tests with p-values) between conditions. We will also clarify in §4 that the VISTA dashboard is the sole modification, with all other elements of the prompt, tools, and agent loop held constant across conditions. This will directly address the attribution concern. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper introduces a training-free interface (VISTA) and reports empirical gains on external benchmarks (LOCA-Bench, BrowseComp-Plus, GAIA) across multiple backbones. No equations, fitted parameters, predictions, or derivations are present that could reduce to self-defined inputs. The hypothesis that context-management competence is latent is tested directly via measured performance lifts and ablations; no self-citation chains, ansatzes, or renamings of known results appear in the load-bearing claims. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frontier language models are proprioceptively blind to their own context from the prompt alone.
- domain assumption Competent context management is already latent in capable models.
Reference graph
Works this paper leans on
-
[1]
2026 , eprint =
Zeng, Weihao and Huang, Yuzhen and He, Junxian , booktitle =. 2026 , eprint =
2026
-
[2]
GAIA: a benchmark for General AI Assistants
Mialon, Gr. Proceedings of the 12th International Conference on Learning Representations (ICLR) , year =. 2311.12983 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2025 , eprint=
BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent , author=. 2025 , eprint=
2025
-
[4]
2026 , eprint =
Zhao, Yujie and Yuan, Boqin and Huang, Junbo and Yuan, Haocheng and Yu, Zhongming and Xu, Haozhou and Hu, Lanxiang and Shankarampeta, Abhilash and Huang, Zimeng and Ni, Wentao and others , booktitle =. 2026 , eprint =
2026
-
[5]
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G and Stoica, Ion and Gonzalez, Joseph E , journal=
-
[6]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Resum: Unlocking long-horizon search intelligence via context summarization , author=. arXiv preprint arXiv:2509.13313 , year=
-
[8]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
Scaling Long-Horizon LLM Agent via Context-Folding , author=. arXiv preprint arXiv:2510.11967 , year=
-
[9]
LongSeeker: Elastic Context Orchestration for Long-Horizon Search Agents
LongSeeker: Elastic Context Orchestration for Long-Horizon Search Agents , author=. arXiv preprint arXiv:2605.05191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2510.18939 , year=
Lost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search , author=. arXiv preprint arXiv:2510.18939 , year=
-
[11]
Feng, Zhaopeng and Su, Liangcai and Zhang, Zhen and Wang, Xinyu and Zhang, Xiaotian and Wang, Xiaobin and Fang, Runnan and Zhang, Qi and Li, Baixuan and Cai, Shihao and others , journal=
-
[12]
Liang, Jiaqing and Han, Jinyi and Li, Weijia and Wang, Xinyi and Zhang, Zhoujia and Jiang, Zishang and Liao, Ying and Li, Tingyun and Huang, Ying and Shen, Hao and others , journal=
-
[13]
Cheng, Yize and Moakhar, Arshia Soltani and Fan, Chenrui and Hosseini, Parsa and Faghih, Kazem and Sodagar, Zahra and Wang, Wenxiao and Feizi, Soheil , journal=. Your
-
[14]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Evaluating very long-term conversational memory of llm agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
Masking Stale Observations Helps Search Agents -- Until It Doesn't: A Regime Map and Its Mechanism
Masking Stale Observations Helps Search Agents--Until It Doesn't: A Regime Map and Its Mechanism , author=. arXiv preprint arXiv:2606.00408 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2604.01664 , year=
Contextbudget: Budget-aware context management for long-horizon search agents , author=. arXiv preprint arXiv:2604.01664 , year=
-
[17]
arXiv preprint arXiv:2601.07190 , year=
Active Context Compression: Autonomous Memory Management in LLM Agents , author=. arXiv preprint arXiv:2601.07190 , year=
-
[18]
Context as a tool: Context management for long-horizon swe-agents , author=. arXiv preprint arXiv:2512.22087 , year=
-
[19]
Liu, Jiaqi and Su, Yaofeng and Xia, Peng and Han, Siwei and Zheng, Zeyu and Xie, Cihang and Ding, Mingyu and Yao, Huaxiu , journal=
-
[20]
2026 , eprint=
Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents , author=. 2026 , eprint=
2026
-
[21]
Ke Yang and Zixi Chen and Xuan He and Jize Jiang and Michel Galley and Chenglong Wang and Jianfeng Gao and Jiawei Han and ChengXiang Zhai , year=. 2603.03296 , archivePrefix=
-
[22]
2026 , eprint=
Learning Query-Aware Budget-Tier Routing for Runtime Agent Memory , author=. 2026 , eprint=
2026
-
[23]
2026 , eprint=
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents , author=. 2026 , eprint=
2026
-
[24]
2026 , eprint=
Architecting AgentOS: From Token-Level Context to Emergent System-Level Intelligence , author=. 2026 , eprint=
2026
-
[25]
2026 , eprint=
The Missing Memory Hierarchy: Demand Paging for LLM Context Windows , author=. 2026 , eprint=
2026
-
[26]
2025 , howpublished =
Memory Blocks: The Key to Agentic Context Management , author =. 2025 , howpublished =
2025
-
[27]
2026 , howpublished =
2026
-
[28]
2026 , eprint=
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering , author=. 2026 , eprint=
2026
-
[29]
2026 , eprint=
BAGEN: Are LLM Agents Budget-Aware? , author=. 2026 , eprint=
2026
-
[30]
Evidence for Limited Metacognition in
Christopher Ackerman , year=. Evidence for Limited Metacognition in. 2509.21545 , archivePrefix=
-
[31]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yang Yue and Zhiqi Chen and Rui Lu and Andrew Zhao and Zhaokai Wang and Yang Yue and Shiji Song and Gao Huang , booktitle=. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2026 , url=
2026
-
[32]
PLOS Computational Biology , year=
Emergence of belief-like representations through reinforcement learning , author=. PLOS Computational Biology , year=
-
[33]
MEMENTO: Teaching LLMs to Manage Their Own Context
Memento: Teaching llms to manage their own context , author=. arXiv preprint arXiv:2604.09852 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2602.03773 , year=
Reasoning Cache: Continual Improvement Over Long Horizons via Short-Horizon RL , author=. arXiv preprint arXiv:2602.03773 , year=
-
[35]
arXiv preprint arXiv:2510.06557 , year=
The markovian thinker: Architecture-agnostic linear scaling of reasoning , author=. arXiv preprint arXiv:2510.06557 , year=
-
[36]
Learning Agent-Compatible Context Management for Long-Horizon Tasks
Learning Agent-Compatible Context Management for Long-Horizon Tasks , author=. arXiv preprint arXiv:2605.30785 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2603.04257 , year=
Memex (rl): Scaling long-horizon llm agents via indexed experience memory , author=. arXiv preprint arXiv:2603.04257 , year=
-
[38]
Agentic memory: Learning unified long-term and short-term memory management for large language model agents , author=. arXiv preprint arXiv:2601.01885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Findings of the Association for Computational Linguistics: ACL 2026 , pages=
Memory as action: Autonomous context curation for long-horizon agentic tasks , author=. Findings of the Association for Computational Linguistics: ACL 2026 , pages=
2026
-
[40]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Acon: Optimizing context compression for long-horizon llm agents , author=. arXiv preprint arXiv:2510.00615 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[42]
Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
One surrogate to fool them all: Universal, transferable, and targeted adversarial attacks with clip , author=. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
2025
-
[43]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Breaking the stealth-potency trade-off in clean-image backdoors with generative trigger optimization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[44]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
CLIP-Guided Backdoor Defense through Entropy-Based Poisoned Dataset Separation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[45]
Contextual Agentic Memory is a Memo, Not True Memory
Contextual Agentic Memory is a Memo, Not True Memory , author=. arXiv preprint arXiv:2604.27707 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
From Internal Diagnosis to External Auditing: A VLM-Driven Paradigm for Online Test-Time Backdoor Defense , author=. arXiv preprint arXiv:2601.19448 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
From Multi-Agent to Single-Agent: When Is Skill Distillation Beneficial?
From Multi-Agent to Single-Agent: When Is Skill Distillation Beneficial? , author =. arXiv preprint arXiv:2604.01608 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2606.16465 , year=
When Agent Automation Becomes Profitable: Quantifying and Insuring Autonomous AI Risk through Trace-Economic Underwriting , author=. arXiv preprint arXiv:2606.16465 , year=
-
[49]
The Fourteenth International Conference on Learning Representations , year=
From Samples to Scenarios: A New Paradigm for Probabilistic Forecasting , author=. The Fourteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.