CogSENet: Blind Image Deblurring with Blur-Conditioned Semantic Routing and Explicit Frequency Fusion
Pith reviewed 2026-06-30 06:16 UTC · model grok-4.3
The pith
CogSENet restores blurred images by routing semantic tokens and fusing frequencies, outperforming prior deblurring methods with fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
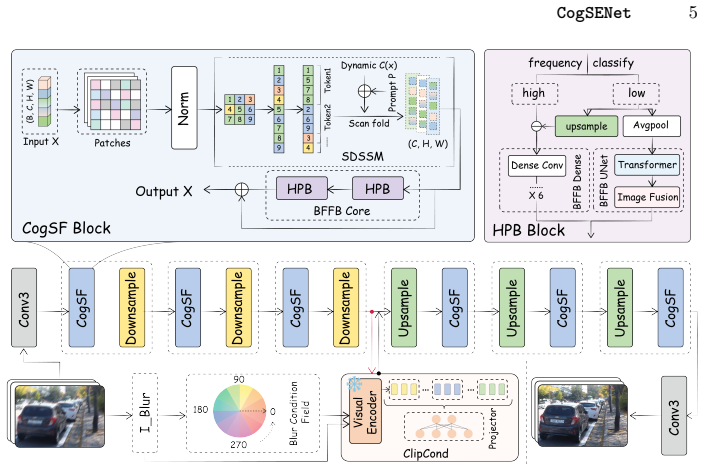
CogSENet is a dynamic semantic-aligned reconstruction framework that uses a Semantic-Driven State Space Module for prompt-conditioned long-range dependency modeling via semantic-aware token regrouping, a BiFreqFusionBlock that decomposes features into high and low frequencies with wavelet transforms for physically interpretable recovery, and estimation of a continuous Blur Field from the blur image fused with CLIP semantic priors to modulate latent features for adaptive restoration under non-uniform blur.
What carries the argument
The Semantic-Driven State Space Module (SDSSM) with differentiable semantic-aware token regrouping, combined with BiFreqFusionBlock (BFFB) using wavelet transforms and continuous Blur Field (CBF) estimation fused with CLIP priors.
If this is right
- CogSENet achieves higher visual quality and structural fidelity than state-of-the-art deblurring methods.
- It uses fewer parameters while doing so.
- It performs well on dehazing, deraining, and denoising tasks as well.
Where Pith is reading between the lines
- The approach may suggest that biologically inspired dynamic mechanisms can enhance other image restoration problems beyond deblurring.
- Explicit frequency separation could be tested for improving interpretability in related computer vision tasks.
- Combining state space models with semantic priors might reduce the need for large parameter counts in restoration networks.
Load-bearing premise
The eagle-inspired Semantic-Driven State Space Module, BiFreqFusionBlock, and continuous Blur Field estimation supply the semantic awareness and physically interpretable recovery needed to handle spatially varying real-world degradations better than existing methods.
What would settle it
A direct comparison on standard real-world deblurring benchmarks showing that CogSENet does not exceed current methods in PSNR, SSIM, or visual quality, or requires more parameters.
Figures





read the original abstract
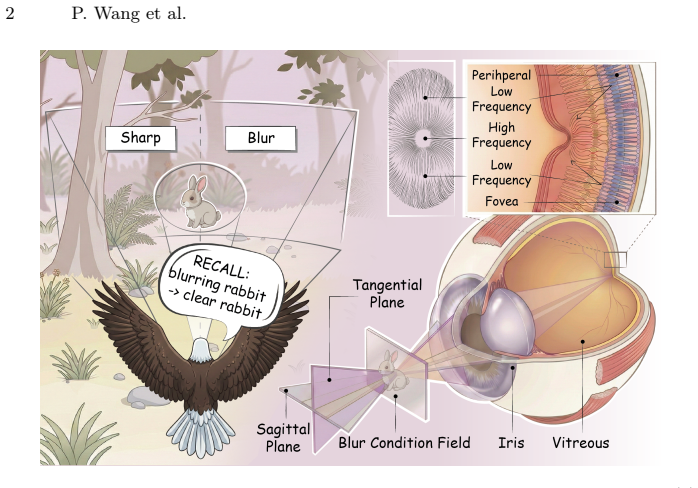
Blind image deblurring demands the recovery of high-fidelity details and coherent structures from complex, unknown degradations. Current blind image deblurring methods struggle with real-world, spatially varying degradations, and lack the semantic awareness necessary to reliably differentiate valid textures from artifacts. To bridge this gap, we propose CogSENet, a dynamic, semantic-aligned reconstruction framework inspired by the eagle's visual system. By mimicking the eagle's active saccadic scanning, we devise a Semantic-Driven State Space Module (SDSSM) with semantic-aware token regrouping via differentiable routing, enabling prompt-conditioned long-range dependency modeling. To ensure physically interpretable recovery of textures and structures, a BiFreqFusionBlock (BFFB) mirrors functional differentiation of the eagle's retina by decomposing features into high and low frequencies using wavelet transforms. Finally, we estimate a continuous Blur Field (CBF) from blur image and fuse it with CLIP semantic priors to modulate the deepest latent features, emulating focal adaptation and enabling adaptive restoration under spatially non-uniform blur. Extensive experiments demonstrate that CogSENetoutperforms state-of-the-art deblurring methods in both visual quality and structural fidelity with fewer parameters, while also performing favorably on dehazing, deraining, and denoising tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CogSENet, a bio-inspired blind image deblurring network that introduces a Semantic-Driven State Space Module (SDSSM) for differentiable semantic-aware token routing and long-range modeling, a BiFreqFusionBlock (BFFB) that uses wavelet transforms to separate and fuse high/low-frequency features, and a continuous Blur Field (CBF) estimator that conditions the deepest features with CLIP semantic priors. The central claim is that this architecture yields superior visual quality and structural fidelity on real-world spatially varying blur while using fewer parameters than prior art, and generalizes favorably to dehazing, deraining, and denoising.
Significance. If the reported gains are reproducible, the combination of semantic routing with explicit frequency decomposition and blur-field conditioning could provide a useful inductive bias for handling non-uniform degradations; the eagle-inspired framing is mainly motivational and does not itself constitute a technical contribution.
major comments (2)
- [Abstract] Abstract (and any experimental section): the claim that CogSENet 'outperforms state-of-the-art deblurring methods in both visual quality and structural fidelity with fewer parameters' is presented without any quantitative tables, PSNR/SSIM values, parameter counts, dataset names, or statistical significance tests, rendering the central empirical claim impossible to evaluate.
- [Abstract] Abstract: the descriptions of SDSSM (semantic-aware token regrouping), BFFB (wavelet-based frequency fusion), and CBF (continuous blur-field estimation fused with CLIP priors) contain no equations, pseudocode, or architectural diagrams; without these, it is impossible to verify whether the modules implement the claimed semantic routing or physically interpretable recovery, which are load-bearing for the novelty argument.
minor comments (1)
- [Abstract] Abstract: 'CogSENetoutperforms' is missing a space.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments point-by-point below, clarifying the role of the abstract versus the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (and any experimental section): the claim that CogSENet 'outperforms state-of-the-art deblurring methods in both visual quality and structural fidelity with fewer parameters' is presented without any quantitative tables, PSNR/SSIM values, parameter counts, dataset names, or statistical significance tests, rendering the central empirical claim impossible to evaluate.
Authors: The abstract serves as a concise summary and does not contain tables or full statistics, which is standard. The full manuscript includes quantitative results with PSNR/SSIM values, parameter counts, dataset names (GoPro, RealBlur, etc.), and comparisons in the Experiments section (Tables 1–4). We will revise the abstract to include a brief mention of key metrics and datasets for improved clarity. revision: yes
-
Referee: [Abstract] Abstract: the descriptions of SDSSM (semantic-aware token regrouping), BFFB (wavelet-based frequency fusion), and CBF (continuous blur-field estimation fused with CLIP priors) contain no equations, pseudocode, or architectural diagrams; without these, it is impossible to verify whether the modules implement the claimed semantic routing or physically interpretable recovery, which are load-bearing for the novelty argument.
Authors: Abstract length constraints preclude equations, pseudocode, or diagrams. Full technical details, including equations for semantic routing in SDSSM, wavelet decomposition in BFFB, and CLIP-conditioned blur field estimation in CBF, along with architectural diagrams and pseudocode, are provided in Sections 3.2–3.4 of the manuscript. These sections substantiate the claimed mechanisms and novelty. revision: no
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description contain no equations, derivations, predictions, or first-principles results. The paper introduces an architecture (SDSSM, BFFB, CBF) with bio-inspired modules and reports empirical outperformance on deblurring and related tasks. No load-bearing step reduces by construction to fitted inputs, self-citations, or renamed known results; the central claim rests on experimental validation of the proposed modules rather than any self-referential reduction. This is the expected outcome for an architecture paper without visible mathematical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ECCV
Chen, L., Chu, X., Zhang, X., Sun, J.: Simple baselines for image restoration. In: ECCV. pp. 17–33. Springer (2022)
2022
-
[2]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cho, S.J., Ji, S.W., Hong, J.P., Jung, S.W., Ko, S.J.: Rethinking coarse-to-fine ap- proach in single image deblurring. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4641–4650 (2021)
2021
-
[3]
In: European Conference on Computer Vision
Conde, M.V., Choi, U.J., Burchi, M., Timofte, R.: Swin2sr: Swinv2 transformer for compressed image super-resolution and restoration. In: European Conference on Computer Vision. pp. 669–687. Springer (2022)
2022
-
[4]
In: Proceedings of the IEEE international conference on computer vision
Dong, C., Deng, Y., Loy, C.C., Tang, X.: Compression artifacts reduction by a deep convolutional network. In: Proceedings of the IEEE international conference on computer vision. pp. 576–584 (2015)
2015
-
[5]
In: European conference on computer vision
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: European conference on computer vision. pp. 184–199. Springer (2014)
2014
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Dong, J., Pan, J., Yang, Z., Tang, J.: Multi-scale residual low-pass filter network for image deblurring. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12345–12354 (2023) 16 P. Wang et al
2023
-
[7]
In: Proceedings of the AAAI conference on artificial intelligence
Dong, Y., Liu, Y., Zhang, H., Chen, S., Qiao, Y.: Fd-gan: Generative adversarial networks with fusion-discriminator for single image dehazing. In: Proceedings of the AAAI conference on artificial intelligence. vol. 34, pp. 10729–10736 (2020)
2020
-
[8]
IEEE transactions on pattern analysis and machine intelligence43(1), 33–47 (2019)
Fan, Q., Chen, D., Yuan, L., Hua, G., Yu, N., Chen, B.: A general decoupled learn- ing framework for parameterized image operators. IEEE transactions on pattern analysis and machine intelligence43(1), 33–47 (2019)
2019
-
[9]
arXiv preprint arXiv:2212.14052 , year=
Fu, D.Y., Dao, T., Saab, K.K., Thomas, A.W., Rudra, A., Ré, C.: Hungry hun- gry hippos: Towards language modeling with state space models. arXiv preprint arXiv:2212.14052 (2022)
-
[10]
IEEE Transactions on Image Processing 26(6), 2944–2956 (2017)
Fu, X., Huang, J., Ding, X., Liao, Y., Paisley, J.: Clearing the skies: A deep network architecture for single-image rain removal. IEEE Transactions on Image Processing 26(6), 2944–2956 (2017)
2017
-
[11]
IEEE transactions on neural networks and learning systems 31(6), 1794–1807 (2019)
Fu, X., Liang, B., Huang, Y., Ding, X., Paisley, J.: Lightweight pyramid networks for image deraining. IEEE transactions on neural networks and learning systems 31(6), 1794–1807 (2019)
2019
-
[12]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Gao,H.,Ma,B.,Zhang,Y.,Yang,J.,Yang,J.,Dang,D.:Learningenrichedfeatures via selective state spaces model for efficient image deblurring. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 710–718 (2024)
2024
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gao, X., Qiu, T., Zhang, X., Bai, H., Liu, K., Huang, X., Wei, H., Zhang, G., Liu, H.: Efficient multi-scale network with learnable discrete wavelet transform for blind motion deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2733–2742 (2024)
2024
-
[14]
Efficiently Modeling Long Sequences with Structured State Spaces
Gu, A., Goel, K., Ré, C.: Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
In: European conference on computer vision
Guo, H., Li, J., Dai, T., Ouyang, Z., Ren, X., Xia, S.T.: Mambair: A simple baseline for image restoration with state-space model. In: European conference on computer vision. pp. 222–241. Springer (2024)
2024
-
[16]
In: European Conference on Computer Vision
Huang, T., Pei, X., You, S., Wang, F., Qian, C., Xu, C.: Localmamba: Visual state space model with windowed selective scan. In: European Conference on Computer Vision. pp. 12–22. Springer (2024)
2024
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Jiang, K., Wang, Z., Yi, P., Chen, C., Huang, B., Luo, Y., Ma, J., Jiang, J.: Multi- scale progressive fusion network for single image deraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8346–8355 (2020)
2020
-
[18]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Kong, L., Dong, J., Ge, J., Li, M., Pan, J.: Efficient frequency domain-based trans- formers for high-quality image deblurring. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 5886–5895 (2023)
2023
-
[19]
In: Proceedings of the computer vision and pattern recognition conference
Kong, L., Dong, J., Tang, J., Yang, M.H., Pan, J.: Efficient visual state space model for image deblurring. In: Proceedings of the computer vision and pattern recognition conference. pp. 12710–12719 (2025)
2025
-
[20]
IEEE Transactions on Image Processing28(1), 492–505 (2019).https://doi.org/10.1109/TIP.2018.2867951
Li, B., Ren, W., Fu, D., Tao, D., Feng, D., Zeng, W., Wang, Z.: Benchmarking single-image dehazing and beyond. IEEE Transactions on Image Processing28(1), 492–505 (2019).https://doi.org/10.1109/TIP.2018.2867951
-
[21]
In: CVPR
Li, B., Liu, X., Hu, P., Wu, Z., Lv, J., Peng, X.: All-in-one image restoration for unknown corruption. In: CVPR. pp. 17452–17462 (2022)
2022
-
[22]
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image restorationusingswintransformer.In:ProceedingsoftheIEEE/CVFInternational ConferenceonComputerVision(ICCV)Workshops.pp.1833–1844(October2021)
-
[23]
Advances in neural information processing systems37, 103031–103063 (2024) CogSENet17
Liu, Y., Tian, Y., Zhao, Y., Yu, H., Xie, L., Wang, Y., Ye, Q., Jiao, J., Liu, Y.: Vmamba: Visual state space model. Advances in neural information processing systems37, 103031–103063 (2024) CogSENet17
2024
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Mao, X., Li, Q., Wang, Y.: Adarevd: Adaptive patch exiting reversible decoder pushes the limit of image deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 25681–25690 (June 2024)
2024
-
[25]
In: Proceedings eighth IEEE international conference on com- puter vision
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings eighth IEEE international conference on com- puter vision. ICCV 2001. vol. 2, pp. 416–423. Ieee (2001)
2001
-
[26]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Nah, S., Hyun Kim, T., Mu Lee, K.: Deep multi-scale convolutional neural network for dynamic scene deblurring. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3883–3891 (2017)
2017
-
[27]
In: European conference on computer vision
Rim, J., Lee, H., Won, J., Cho, S.: Real-world blur dataset for learning and bench- marking deblurring algorithms. In: European conference on computer vision. pp. 184–201. Springer (2020)
2020
-
[28]
In: Proceedings of the IEEE/CVF international conference on computer vision
Shen, Z., Wang, W., Lu, X., Shen, J., Ling, H., Xu, T., Shao, L.: Human-aware motion deblurring. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5572–5581 (2019)
2019
-
[29]
Simplified State Space Layers for Sequence Modeling
Smith, J.T., Warrington, A., Linderman, S.W.: Simplified state space layers for sequence modeling. arXiv preprint arXiv:2208.04933 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Tao, X., Gao, H., Shen, X., Wang, J., Jia, J.: Scale-recurrent network for deep image deblurring. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 8174–8182 (2018)
2018
-
[31]
Neural Networks121, 461–473 (2020)
Tian, C., Xu, Y., Zuo, W.: Image denoising using deep cnn with batch renormal- ization. Neural Networks121, 461–473 (2020)
2020
-
[32]
In: European conference on computer vision
Tsai, F.J., Peng, Y.T., Lin, Y.Y., Tsai, C.C., Lin, C.W.: Stripformer: Strip trans- former for fast image deblurring. In: European conference on computer vision. pp. 146–162. Springer (2022)
2022
-
[33]
Tsai, F.J., Peng, Y.T., Tsai, C.C., Lin, Y.Y., Lin, C.W.: Banet: A blur-aware atten- tionnetworkfordynamicscenedeblurring.IEEETransactionsonImageProcessing 31, 6789–6799 (2022)
2022
-
[34]
Xiao, J., Fu, X., Liu, A., Wu, F., Zha, Z.J.: Image de-raining transformer. IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 12978–12995 (2023).https://doi.org/10.1109/TPAMI.2022.3183612
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5728–5739 (2022)
2022
-
[36]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Multi-stage progressive image restoration. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 14821–14831 (2021)
2021
-
[37]
IEEE transactions on image processing26(7), 3142–3155 (2017)
Zhang, K., Zuo, W., Chen, Y., Meng, D., Zhang, L.: Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE transactions on image processing26(7), 3142–3155 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.