Efficient Retrieval-Augmented Generation via Token Co-occurrence Graphs
Pith reviewed 2026-06-30 06:10 UTC · model grok-4.3
The pith
Token co-occurrence graphs let RAG retrieve connected evidence for multi-hop questions without LLM-based entity extraction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
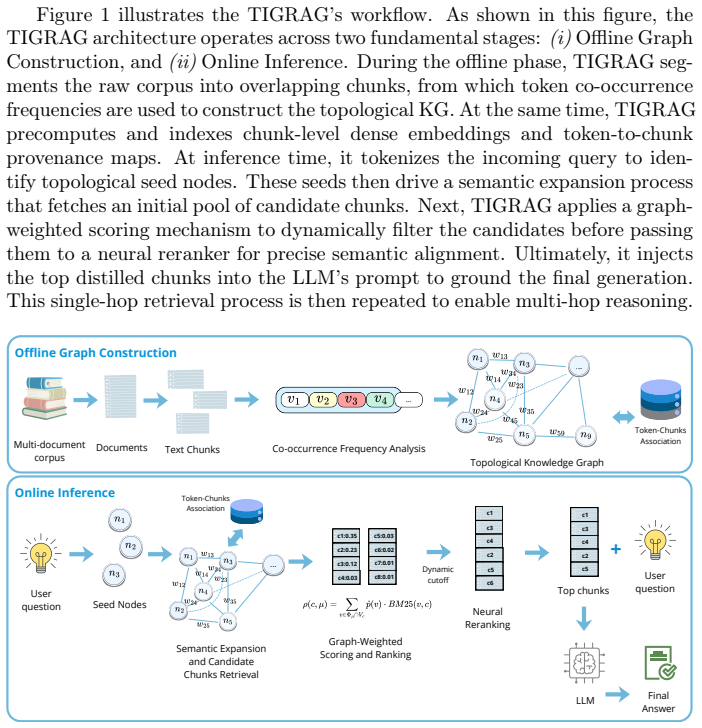
TIGRAG constructs a token-induced graph from sliding-window co-occurrence statistics to model topological relationships between tokens, then uses graph-based semantic expansion together with an iterative entity-driven retrieval loop and neural reranking to surface interconnected evidence; this pipeline outperforms both dense retrievers and LLM-dependent graph RAG systems on multi-hop QA while cutting indexing time, latency, and prompt size.
What carries the argument
The token co-occurrence Knowledge Graph, which records direct statistical links between tokens via sliding-window counts to support scalable construction and iterative bridging-entity expansion during retrieval.
If this is right
- Indexing time drops because graph construction avoids any LLM calls for entity or relation extraction.
- Inference latency and prompt footprint shrink due to smaller retrieved context sets from targeted graph expansion.
- Retrieval recall for multi-hop questions rises by iteratively adding bridging entities found in the co-occurrence graph.
- Downstream QA accuracy improves on benchmarks that require chaining evidence across documents.
Where Pith is reading between the lines
- The same co-occurrence graph could be reused across multiple queries without re-extraction, lowering amortized cost for high-volume RAG deployments.
- Domains with highly repetitive token patterns may see larger gains than domains with sparse or idiosyncratic phrasing.
- Replacing the neural reranker with a purely graph-based scorer could further reduce inference cost while preserving the core topology signal.
Load-bearing premise
Token co-occurrence statistics alone are sufficient to capture the topological relationships needed for effective multi-hop reasoning without the semantic depth provided by LLM-based entity or relation extraction.
What would settle it
A multi-hop QA test set in which correct answers depend on rare semantic connections that appear infrequently in token co-occurrence counts; if TIGRAG retrieval precision drops below that of LLM-extracted graph baselines on this set, the central efficiency claim would be falsified.
Figures

read the original abstract
Retrieval-Augmented Generation (RAG) mitigates hallucinations in Large Language Models (LLMs) by grounding the generation process on external knowledge. However, standard RAG approaches struggle with multi-hop reasoning. While recent graph-based RAG methods improve the retrieval of interconnected chunks, they often rely on computationally expensive and error-prone LLM-based extraction pipelines. To address these issues, we propose TIGRAG (Token-Induced GraphRAG), an efficient graph-augmented RAG framework based on a token co-occurrence Knowledge Graph. TIGRAG directly models topological relationships between tokens using sliding-window co-occurrence statistics, thus enabling scalable graph construction. During inference, it combines graph-based semantic expansion and neural reranking to retrieve interconnected evidence for multi-hop reasoning. Specifically, it introduces an iterative entity-driven retrieval strategy that progressively expands the query using bridging entities extracted from previously retrieved contexts. We evaluated TIGRAG on three widely adopted multi-hop Question Answering (QA) benchmarks. Experimental results demonstrated that our framework consistently outperforms dense retrieval and graph-based RAG methods in both retrieval and downstream QA tasks, while substantially reducing indexing time, inference latency, and prompt footprint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TIGRAG, an efficient graph-augmented RAG framework that constructs a token co-occurrence knowledge graph via sliding-window statistics (avoiding LLM-based entity/relation extraction) and uses iterative entity-driven query expansion with bridging entities plus neural reranking for multi-hop QA. It claims consistent outperformance over dense retrieval and prior graph-based RAG methods on three multi-hop QA benchmarks, together with reductions in indexing time, inference latency, and prompt footprint.
Significance. If the experimental claims hold, the work would demonstrate that simple frequency-based token co-occurrence graphs can substitute for more expensive LLM-driven graph construction in multi-hop retrieval, offering a scalable alternative with lower overhead. This would be a meaningful efficiency contribution in the RAG literature, provided the topological model proves sufficient for the required reasoning paths.
major comments (2)
- [Abstract] Abstract: the central claim that TIGRAG 'consistently outperforms dense retrieval and graph-based RAG methods in both retrieval and downstream QA tasks' is presented with no quantitative metrics, error bars, dataset statistics, baseline implementations, or ablation results. This absence is load-bearing for the experimental contribution and prevents verification of whether post-hoc choices affect the reported gains.
- [Method] Method description (iterative entity-driven retrieval strategy): the bridging entities used for progressive query expansion are extracted from retrieved contexts via the token co-occurrence graph, yet the manuscript provides no evidence that surface-level co-occurrence links capture the directed or semantically typed relations needed to traverse gold multi-hop chains (e.g., HotpotQA). This assumption is central to the claim that the method achieves both efficiency and reasoning capability without LLM-based extraction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract and method. We address each point below and will incorporate revisions to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TIGRAG 'consistently outperforms dense retrieval and graph-based RAG methods in both retrieval and downstream QA tasks' is presented with no quantitative metrics, error bars, dataset statistics, baseline implementations, or ablation results. This absence is load-bearing for the experimental contribution and prevents verification of whether post-hoc choices affect the reported gains.
Authors: We agree that the abstract would benefit from quantitative support. In the revised version we will include key metrics (e.g., average retrieval recall@10 and QA F1 improvements over dense and graph baselines on the three benchmarks) together with a brief note on dataset sizes and the main baseline implementations. revision: yes
-
Referee: [Method] Method description (iterative entity-driven retrieval strategy): the bridging entities used for progressive query expansion are extracted from retrieved contexts via the token co-occurrence graph, yet the manuscript provides no evidence that surface-level co-occurrence links capture the directed or semantically typed relations needed to traverse gold multi-hop chains (e.g., HotpotQA). This assumption is central to the claim that the method achieves both efficiency and reasoning capability without LLM-based extraction.
Authors: The co-occurrence graph is intentionally undirected and frequency-based rather than semantically typed. The iterative retrieval procedure relies on statistical connectivity to surface bridging entities that empirically connect multi-hop evidence; results on HotpotQA and the other benchmarks indicate that these paths suffice for the required reasoning. We will revise the method section to clarify this design choice, add a short illustrative example of bridging-entity expansion, and note the absence of explicit directionality as a deliberate efficiency trade-off. revision: partial
Circularity Check
No circularity: construction and evaluation are independent
full rationale
The paper's core construction step extracts a token co-occurrence graph via sliding-window statistics on the input corpus; this is a direct, parameter-free count that does not reference downstream QA labels or performance metrics. The iterative entity-driven expansion and neural reranking are described as deterministic operations on the resulting graph plus standard dense retrieval, with no fitted parameters, self-definitional equations, or load-bearing self-citations that reduce the claimed gains to the inputs by construction. Evaluation on external multi-hop QA benchmarks therefore remains an independent test rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
V. Agrawal, F. Wang, and R. Puri. Query-Aware Graph Neural Net- works for Enhanced Retrieval-Augmented Generation.arXiv preprint arXiv:2508.05647, 2025. 19
-
[2]
Ammann, J
P.J. Ammann, J. Golde, and A. Akbik. Question decomposition for retrieval-augmented generation. InProc. of the Annual Meeting of the As- sociation for Computational Linguistics (ACL’25), pages 497–507, Vienna, Austria, 2025
2025
-
[3]
Cheng, K
H. Cheng, K. Wang, Q. Wang, T. Liu, and K. Sheng. A Chinese financial eventknowledgegraph-basedretrieval-augmentedgenerationframeworkfor financial question answering.Engineering Applications of Artificial Intelli- gence, 175:114670, 2026. Elsevier
2026
-
[4]
Choubey, X
P.K. Choubey, X. Su, M. Luo, X. Peng, C. Xiong, T. Le, S. Rosenman, V. Lal, P.L. Mui, R. Ho, P. Howard, and C.S. Wu. Scaling Knowl- edge Graph Construction through Synthetic Data Generation and Distilla- tion. InProc. of the International Conference on Learning Representations (ICLR’26), Rio de Janeiro, Brasil, 2025
2025
-
[5]
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Tru- itt, D. Metropolitansky, R.O. Ness, and J. Larson. From local to global: A graph RAG approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
W. Fan, Y. Ding, L. Ning, S. Wang, H. Li, D. Yin, T. Chua, and Q. Li. A survey on RAG meeting LLMS: Towards retrieval-augmented large lan- guage models. InProc. of the ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining (KDD’24), pages 6491–6501, Barcelona, Catalunya, Spain, 2024
2024
- [7]
-
[8]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, and H. Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Ghanem and C
H. Ghanem and C. Cruz. Fine-tuning or prompting on llms: evaluating knowledge graph construction task.Frontiers in Big Data, 8:1505877, 2025. Frontiers Media SA
2025
-
[10]
T. Guo, C. Wang, Q. Yang, J. Tang, Y. Liu, and Y. Wen. WADSeg: Exploiting Weak Attention Associations for Enhanced Knowledge Segmen- tation in RAG.Expert Systems with Applications, page 129297, 2025. El- sevier
2025
-
[11]
Z. Guo, L. Xia, Y. Yu, T. Ao, and C. Huang. LightRAG: Simple and Fast Retrieval-Augmented Generation. InFindings of the Association for Com- putational Linguistics: EMNLP 2025, pages 10746–10761, Suzhou, China, 2025. 20
2025
-
[12]
B. J. Guti’errez, Y. Shu, W. Qi, S. Zhou, and Y. Su. From RAG to Memory: Non-Parametric Continual Learning for Large Language Models. InProc. of the International Conference on Machine Learning (ICLR’25), pages 21497–21515, Singapore, 2025
2025
-
[13]
Gutiérrez, Y
B.J. Gutiérrez, Y. Shu, Y. Gu, M. Yasunaga, and Y. Su. Hipporag: Neu- robiologically inspired long-term memory for large language models. In Proc. of the Annual Conference on Neural Information Processing Sys- tems (NeurIPS’24), volume 37, pages 59532–59569, Vancouver, British Columbia, Canada, 2024
2024
-
[14]
Haveliwala
T.H. Haveliwala. Topic-sensitive pagerank. InProc. of the International Conference on World Wide Web (WWW’02), pages 517–526, Honolulu, HI, USA, 2002
2002
-
[15]
X. Ho, A.D. Nguyen, S. Sugawara, and A. Aizawa. Constructing a multi- hop qa dataset for comprehensive evaluation of reasoning steps. InProc. of the International Conference on Computational Linguistics (ICLR’20), pages 6609–6625, Barcelona, Catalunya, Spain, 2020
2020
-
[16]
Y. Hu, Z. Lei, Z. Zhang, B. Pan, C. Ling, and L. Zhao. GRAG: Graph Retrieval-Augmented Generation. InFindings of the Association for Com- putational Linguistics: NAACL 2025, pages 4145–4157, Albuquerque, NM, USA, 2025. ACL
2025
-
[17]
Jeong, H.I
Y.B. Jeong, H.I. Seo, Y.H. Kim, and W.Y. Kim. Retrieval-augmented visual parcel invoice understanding transformer for address correction.En- gineering Applications of Artificial Intelligence, 158:111542, 2025. Elsevier
2025
-
[18]
Y. Ji, K. Wu, J. Li, W. Chen, M. Zhong, J. Xu, and M. Zhang. Retrieval and Reasoning on KGs: Integrate Knowledge Graphs into Large Language Models for Complex Question Answering. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7598–7610, Miami, FL, USA, 2024. ACL
2024
-
[19]
B. Jin, C. Xie, J. Zhang, K.K. Roy, Y. Zhang, Z. Li, R. Li, X. Tang, S. Wang, Y. Meng, and J. Han. Graph chain-of-thought: Augmenting large language models by reasoning on graphs. InFindings of the Association for Computational Linguistics: ACL 2024, pages 163–184, St. Julian’s, Malta,
2024
-
[20]
Karpukhin, B
V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W. Yih. Dense passage retrieval for open-domain question answering. InProc. of the International Conference on Empirical Methods in Natural Language Processing (EMNLP’20), pages 6769–6781, online, 2020
2020
-
[21]
Y. Kuratov, A. Bulatov, P. Anokhin, D. Sorokin, A. Sorokin, and M. Burt- sev. In search of needles in a 11m haystack: Recurrent memory finds what llms miss.arXiv preprint arXiv:2402.10790, 2024. 21
-
[22]
Linders and J.M
J. Linders and J.M. Tomczak. Knowledge graph-extended retrieval augmented generation for question answering.Applied Intelligence, 55(17):1102, 2025
2025
-
[23]
N.F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173,
-
[24]
H. Luo, G. Chen, Y. Zheng, X. Wu, Y. Guo, Q. Lin, Y. Feng, Z. Kuang, M. Song, Y. Zhu, and A.T. Luu. HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation. In Proc. of the Annual Conference on Neural Information Processing Systems (NeurIPS’25), San Diego, CA, USA, 2025
2025
-
[25]
L. Luo, Z. Zhao, G. Haffari, D. Phung, C. Gong, and S. Pan. GFM- RAG: Graph Foundation Model for Retrieval Augmented Generation. In Proc. of the Annual Conference on Neural Information Processing Systems (NeurIPS’25), San Diego, CA, USA, 2025
2025
-
[26]
C. Ma, Y. Chen, T. Wu, A. Khan, and H. Wang. Large language models meet knowledge graphs for question answering: Synthesis and opportuni- ties. InProc. of the Conference on Empirical Methods in Natural Language Processing (EMNLP’25), pages 24589–24608, Suzhou, China, 2025
2025
-
[27]
M. S. Malik, V. The Le, and Y. Y. Ou. Enhancing the classification of metal-binding residue in proteins with retrieval-augmented generation, pro- tein language models, and deep learning.Engineering Applications of Ar- tificial Intelligence, 171:114330, 2026. Elsevier
2026
- [28]
-
[29]
B. Peng, Y. Zhu, Y. Liu, X. Bo, H. Shi, C. Hong, Y. Zhang, and S. Tang. Graph retrieval-augmented generation: A survey.ACM Transactions on Information Systems, 44(2):1–52, 2025. ACM
2025
-
[30]
Perkovi’c, A
G. Perkovi’c, A. Drobnjak, and I. Botički. Hallucinations in llms: Un- derstanding and addressing challenges. InProc. of the MIPRO ICT and Electronics Convention (MIPRO’24), pages 2084–2088, Opatija, Croatia,
2084
-
[31]
Press, M
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis. Measuring and narrowing the compositionality gap in language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore, 2023. 22
2023
-
[32]
O. Ram, Y. Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton- Brown, and Y. Shoham. In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics, 11:1316– 1331, 2023. MIT Press
2023
-
[33]
Saleh, G
A.O. Saleh, G. Tur, and Y. Saygin. SG-RAG: Multi-hop question answer- ing with large language models through knowledge graphs. InProc. of the International Conference on Natural Language and Speech Processing (ICNLSP’24), pages 439–448, Trento, Italy, 2024
2024
-
[34]
Sarmah, D
B. Sarmah, D. Mehta, B. Hall, R. Rao, S. Patel, and S. Pasquali. Hy- bridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented GenerationforEfficientInformationExtraction. InProc. of the ACM Inter- national Conference on AI in Finance, (ICAIF’24), pages 608–616, Brook- lyn, NY, USA, 2024. ACM
2024
-
[35]
Sarthi, S
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, and C.D. Man- ning. RAPTOR: Recursive abstractive processing for tree-organized re- trieval. InProc. of the International Conference on Learning Representa- tions (ICLR’24), Vienna, Austria, 2024
2024
-
[36]
J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y. Gong, L. Ni, H. Shum, and J. Guo. Think-on-Graph: Deep and Responsible Reasoning of Large Lan- guageModelonKnowledgeGraph. InProc. of the International Conference on Learning Representations (ICLR’24), Vienna, Austria, 2024
2024
-
[37]
Svore and C.J
K.M. Svore and C.J. Burges. A machine learning approach for improved BM25 retrieval. InProc. of the Proceedings of the ACM Conference on Information and Knowledge Management (CIKM’09), pages 1811–1814, Hong Kong, China, 2009
2009
-
[38]
Tang and Y
Y. Tang and Y. Yang. MultiHop-RAG: Benchmarking Retrieval- Augmented Generation for Multi-Hop Queries. InProc. of the First Con- ference on Language Modeling (COLM’24), Philadelphia, PA, USA, 2024
2024
-
[39]
W. Tao, X. Xing, Y. Chen, L. Huang, and X. Xu. Treerag: Unleashing the power of hierarchical storage for enhanced knowledge retrieval in long documents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 356–371, Vienna, Austria, 2025
2025
-
[40]
Trivedi, N
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal. MuSiQue: Multihop Questions via Single-hop Question Composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022. MIT Press
2022
-
[41]
Trivedi, N
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal. Interleaving retrievalwithchain-of-thoughtreasoningforknowledge-intensivemulti-step questions. InProc. of the Annual Meeting of the Association for Com- putational Linguistics (ACL’23), pages 10014–10037, Toronto, Ontario, Canada, 2023. 23
2023
-
[42]
Y. Wang, N. Lipka, R. A. Rossi, A. Siu, R. Zhang, and T. Derr. Knowledge graph prompting for multi-document question answering. InProc. of the AAAI Conference on Artificial Intelligence (AAAI’24), volume 38, pages 19206–19214, Vancouver, British Columbia, Canada, 2024
2024
-
[43]
Y. Wang, N. Lipka, R. Zhang, A.F. Siu, Y. Zhao, B. Ni, X. Wang, R.A. Rossi, and T. Derr. Topology-aware Retrieval Augmentation for Text Gen- eration. InProc. of the ACM International Conference on Information and Knowledge Management, (CIKM’24), pages 2442–2452, Boise, ID, USA,
- [44]
- [45]
-
[46]
Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. Cohen, R. Salakhutdinov, and C.D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProc. of the conference on empirical methods in natural language processing (EMNLP’18), pages 2369–2380, Brussels, Bel- gium, 2018
2018
- [47]
- [48]
-
[49]
Zhang and J.W
S.H. Zhang and J.W. Lin. Direction-aware graph traversal for efficient multi-hop retrieval-augmented generation.Engineering Applications of Ar- tificial Intelligence, 181:115383, 2026. Elsevier
2026
-
[50]
X. Zhu, Y. Xie, Y. Liu, Y. Li, and W. Hu. Knowledge Graph-Guided Retrieval Augmented Generation. InProc. of the Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL’25) - Volume 1: Long Papers, pages 8912–8924, Albuquerque, NM, USA, 2025. ACL. 24
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.