Temporal Feature Extractors in EEG Foundation Models: A Controlled Comparison Including a Pretrained Time-Series Model
Pith reviewed 2026-06-30 05:54 UTC · model grok-4.3
The pith
A pretrained general-purpose time-series model works as an effective frozen temporal feature extractor inside EEG foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within a single unified EEG foundation model, replacing the temporal feature extractor with a frozen pretrained TSFM yields downstream performance that is competitive on motor imagery and advantageous on emotion recognition, showing that general time-series representations can be reused directly as frozen temporal modules for brain-signal modeling.
What carries the argument
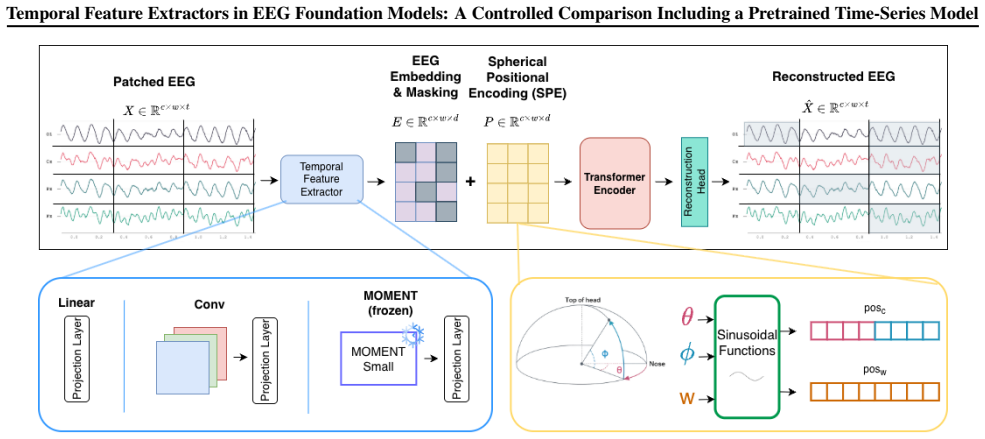
The frozen pretrained TSFM (MOMENT) inserted as the temporal feature extractor inside the otherwise fixed EEG foundation model architecture.
If this is right
- Simple linear temporal representations are sufficient for motor imagery classification under the tested conditions.
- Emotion recognition tasks gain from the richer temporal modeling supplied by the pretrained extractor.
- General-purpose time-series pretraining can be reused without EEG-specific adaptation when kept frozen.
- Task-dependent choice of temporal extractor is required rather than a single strategy for all EEG benchmarks.
Where Pith is reading between the lines
- If the transfer holds, EEG foundation model training could be accelerated by borrowing scale from existing time-series corpora instead of collecting ever-larger EEG-only datasets.
- Freezing the TSFM leaves open the question of whether light fine-tuning on EEG data would produce further gains without destroying the transferred representations.
- The same modular replacement strategy could be tested on other biosignals such as ECG or MEG to check whether the pattern generalizes beyond EEG.
Load-bearing premise
The single shared EEG foundation model backbone keeps all other design choices identical so that performance differences can be attributed only to the choice of temporal extractor.
What would settle it
Re-running the exact same unified architecture but with the TSFM weights replaced by random initialization and finding that downstream accuracy on both tasks stays within a few percent of the pretrained version would falsify the claim that the pretraining itself supplies useful transferable temporal features.
Figures
read the original abstract
Electroencephalography (EEG) foundation models aim to learn generalizable representations from large-scale brain recordings. However, the role of temporal feature extractors and whether pretrained time-series foundation models (TSFMs) can be effectively transferred to this setting remains underexplored. We conduct a controlled comparison of three temporal feature extraction strategies, including a linear baseline, a convolutional encoder, and a frozen pretrained TSFM (MOMENT), within a unified EEG foundation model. We evaluate their impact on representation quality using two downstream tasks: motor imagery and emotion recognition. Results reveal different trends across the evaluated benchmarks. On the motor imagery dataset, simple temporal representations perform competitively, whereas the emotion dataset benefits from richer temporal modeling. Although not specifically adapted to EEG, the pretrained TSFM serves as an effective temporal feature extractor, suggesting that general-purpose time-series representations can be transferred as frozen temporal feature extractors within EEG foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a controlled comparison of three temporal feature extraction strategies (linear baseline, convolutional encoder, and frozen pretrained TSFM MOMENT) integrated into a unified EEG foundation model. It evaluates their effects on representation quality for motor imagery and emotion recognition downstream tasks, reporting that simple temporal representations are competitive on motor imagery while richer modeling benefits emotion recognition, and concluding that the pretrained TSFM serves as an effective transferable temporal feature extractor despite lacking EEG-specific adaptation.
Significance. If the comparison is verifiably controlled, the work is significant for demonstrating that general-purpose time-series representations can transfer as frozen extractors to EEG foundation models. This has potential to reduce reliance on domain-specific pretraining and to highlight task-dependent needs for temporal modeling complexity. The empirical, controlled design is a positive feature.
major comments (2)
- [Abstract] Abstract: The abstract asserts that 'results reveal different trends across the evaluated benchmarks' and that the TSFM 'serves as an effective temporal feature extractor' but supplies no quantitative metrics, error bars, dataset sizes, subject counts, or statistical tests. This prevents assessment of the magnitude or reliability of the claimed performance differences and transferability result.
- [Methods] Methods (unified setup description): The central claim that the frozen MOMENT TSFM is an effective transferable extractor rests on the three strategies being compared inside an otherwise identical EEG foundation model. The manuscript must explicitly confirm that TSFM integration introduces no extra steps (input resampling to match pretraining rate, channel-wise projection to expected dimensionality, or special patch-based tokenization handling) absent from the linear and convolutional baselines; without this, any performance edge could be an artifact of those adaptations rather than intrinsic representation quality.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity and explicitness. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that 'results reveal different trends across the evaluated benchmarks' and that the TSFM 'serves as an effective temporal feature extractor' but supplies no quantitative metrics, error bars, dataset sizes, subject counts, or statistical tests. This prevents assessment of the magnitude or reliability of the claimed performance differences and transferability result.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to evaluate the results. In the revised version, we will incorporate key quantitative metrics (e.g., mean accuracies or F1 scores with standard deviations across runs or subjects), brief dataset characteristics (subject counts and sample sizes), and reference to any statistical comparisons performed. revision: yes
-
Referee: [Methods] Methods (unified setup description): The central claim that the frozen MOMENT TSFM is an effective transferable extractor rests on the three strategies being compared inside an otherwise identical EEG foundation model. The manuscript must explicitly confirm that TSFM integration introduces no extra steps (input resampling to match pretraining rate, channel-wise projection to expected dimensionality, or special patch-based tokenization handling) absent from the linear and convolutional baselines; without this, any performance edge could be an artifact of those adaptations rather than intrinsic representation quality.
Authors: The comparison was designed to be controlled, with all three extractors operating on identically preprocessed EEG inputs within the same downstream model. No differential resampling, channel projections, or tokenization steps were applied to the TSFM. To make this fully explicit, we will add a dedicated paragraph (or subsection) in the Methods section describing the shared input pipeline and confirming equivalence of integration steps across the linear, convolutional, and TSFM extractors. revision: yes
Circularity Check
No circularity: empirical comparison without derivation or self-referential fitting
full rationale
The paper conducts a controlled empirical comparison of three temporal feature extraction strategies (linear, convolutional, frozen MOMENT TSFM) inside a unified EEG foundation model setup, evaluating them on motor imagery and emotion recognition tasks. No mathematical derivations, equations, parameter fitting presented as predictions, or self-citation chains appear in the abstract or described content. The central claim—that the pretrained TSFM serves as an effective transferable extractor—rests on experimental outcomes rather than any reduction to inputs by construction. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The motor imagery and emotion recognition tasks are representative benchmarks for evaluating EEG representation quality.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1038/sdata.2017.181. Ansari, A. F., Stella, L., Turkmen, A. C., Zhang, X., Mer- cado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., Zschiegner, J., Maddix, D. C., Wang, H., Mahoney, M. W., Torkkola, K., Wilson, A. G., Bohlke-Schneider, M., and Wang, B. Chronos: Learning the language of time series.Transactions on Machine ...
-
[2]
Expert Cer- tification
ISSN 2835-8856. Expert Cer- tification. Bigdely-Shamlo, N., Mullen, T., Kothe, C., Su, K.-M., and Robbins, K. A. The prep pipeline: standardized prepro- cessing for large-scale eeg analysis.Frontiers in Neuroin- formatics, V olume 9 - 2015,
2015
-
[3]
ISSN 1662-5196. doi: 10.3389/fninf.2015.00016. Chen, J., Wang, X., Huang, C., Hu, X., Shen, X., and Zhang, D. A large finer-grained affective computing eeg dataset.Scientific Data, 10(1):740,
-
[4]
Das, A., Kong, W., Sen, R., and Zhou, Y
doi: 10.1038/s41597-023-02650-w. Das, A., Kong, W., Sen, R., and Zhou, Y . A decoder-only foundation model for time-series forecasting. InProceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learn- ing Research, pp. 10148–10167. PMLR, 21–27 Jul
-
[5]
D¨oner, B., Ingolfsson, T. M., Benini, L., and Li, Y . Luna: Efficient and topology-agnostic foundation model for eeg signal analysis.arXiv preprint arXiv:2510.22257,
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale.ArXiv, abs/2010.11929,
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale.ArXiv, abs/2010.11929,
Pith/arXiv arXiv 2010
-
[7]
Goswami, M., Szafer, K., Choudhry, A., Cai, Y ., Li, S., and Dubrawski, A
doi: 10.1161/01.CIR.101.23.e215. Goswami, M., Szafer, K., Choudhry, A., Cai, Y ., Li, S., and Dubrawski, A. MOMENT: A family of open time- series foundation models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pp. 16115–16152. PMLR, 21–27 Jul
-
[8]
A., Strohmeier, D., Brodbeck, C., Goj, R., Jas, M., Brooks, T., Parkkonen, L., and H¨am¨al¨ainen, M
Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., Goj, R., Jas, M., Brooks, T., Parkkonen, L., and H¨am¨al¨ainen, M. Meg and eeg data analysis with mne-python.Frontiers in Neuroscience, V olume 7 - 2013,
2013
-
[9]
doi: 10.3389/ fnins.2013.00267
ISSN 1662-453X. doi: 10.3389/ fnins.2013.00267. Jiang, W., Zhao, L., and liang Lu, B. Large brain model for learning generic representations with tremendous EEG data in BCI. InThe Twelfth International Conference on Learning Representations,
arXiv 2013
-
[10]
Bendr: Us- ing transformers and a contrastive self-supervised learn- ing task to learn from massive amounts of eeg data.Fron- tiers in Human Neuroscience, V olume 15 - 2021,
Kostas, D., Aroca-Ouellette, S., and Rudzicz, F. Bendr: Us- ing transformers and a contrastive self-supervised learn- ing task to learn from massive amounts of eeg data.Fron- tiers in Human Neuroscience, V olume 15 - 2021,
2021
-
[11]
doi: 10.3389/fnhum.2021.653659
ISSN 1662-5161. doi: 10.3389/fnhum.2021.653659. Kottapalli, S., Hubli, K., Chandrashekhara, S., Jain, G., Hubli, S., Botla, G., and Doddaiah, R. Foundation models for time series: A survey.ArXiv, abs/2504.04011,
-
[12]
Q., Ibrahim, H., Abdullah, M
5 Temporal Feature Extractors in EEG Foundation Models: A Controlled Comparison Including a Pretrained Time-Series Model Lai, C. Q., Ibrahim, H., Abdullah, M. Z., Abdullah, J. M., Suandi, S. A., and Azman, A. Artifacts and noise removal for electroencephalogram (eeg): A literature review. In 2018 IEEE Symposium on Computer Applications & In- dustrial Elec...
2018
-
[13]
Lai, J., Wei, J., Yao, L., and Wang, Y . A simple review of eeg foundation models: Datasets, advancements and future perspectives.arXiv preprint arXiv:2504.20069,
-
[14]
doi: 10.1038/sdata.2017.40. Ouahidi, Y . E., Lys, J., Th¨olke, P., Farrugia, N., Pasdeloup, B., Gripon, V ., Jerbi, K., and Lioi, G. Reve: A foundation model for eeg – adapting to any setup with large-scale pretraining on 25,000 subjects
-
[15]
doi: 10.1016/0013-4694(89)90180-6
ISSN 0013-4694. doi: 10.1016/0013-4694(89)90180-6. Schalk, G. EEG Motor Movement/Imagery Dataset.Phys- ioNet, September
-
[16]
doi: 10.13026/C28G6P. Version 1.0.0. Schalk, G., McFarland, D., Hinterberger, T., Birbaumer, N., and Wolpaw, J. Bci2000: a general-purpose brain- computer interface (bci) system.IEEE Transactions on Biomedical Engineering, 51(6):1034–1043,
-
[17]
doi: 10.1109/TBME.2004.827072. Shirazi, S. Y ., Franco, A., Hoffmann, M. S., Esper, N. B., Truong, D., Delorme, A., Milham, M. P., and Makeig, S. Hbn-eeg: The fair implementation of the healthy brain network (hbn) electroencephalography dataset.bioRxiv,
-
[18]
Song, Y ., Zheng, Q., Liu, B., and Gao, X
doi: 10.1101/2024.10.03.615261. Song, Y ., Zheng, Q., Liu, B., and Gao, X. Eeg conformer: Convolutional transformer for eeg decoding and visu- alization.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:710–719,
-
[19]
Tran, X.-T., V o, T.-N., Vu, S.-T., Tran, T.-T., Nguyen, M.-D., Do, T., and Lin, C.-T
doi: 10.1109/TNSRE.2022.3230250. Tran, X.-T., V o, T.-N., Vu, S.-T., Tran, T.-T., Nguyen, M.-D., Do, T., and Lin, C.-T. Inter-and intra-subject variability in eeg: A systematic survey.arXiv preprint arXiv:2602.01019,
-
[20]
6 Temporal Feature Extractors in EEG Foundation Models: A Controlled Comparison Including a Pretrained Time-Series Model A
accepted for publication. 6 Temporal Feature Extractors in EEG Foundation Models: A Controlled Comparison Including a Pretrained Time-Series Model A. Appendix The Appendix provides supplementary details on visualization, model hyperparameters, dataset descriptions, data prepro- cessing, data splits, evaluation metrics, and computational environment. A.1. ...
2024
-
[21]
The recordings were acquired using an EGI HydroCel Geodesic Sensor Net with 128 channels at a sampling rate of 500 Hz
is a large-scale collection of EEG recordings from children and adolescents aged 5 to 21 years. The recordings were acquired using an EGI HydroCel Geodesic Sensor Net with 128 channels at a sampling rate of 500 Hz. Each subject completed active and passive tasks, including resting state, surround suppression, movie watching, contrast change detection, seq...
2013
-
[22]
As the data is already band-pass filtered, no additional notch filtering (60 Hz) was applied
after applying average referencing to the remaining channels. As the data is already band-pass filtered, no additional notch filtering (60 Hz) was applied. Downstream Datasets Physio-Net MI.The PhysioNet EEG Motor Movement Dataset (Physio-Net MI) (Goldberger et al., 2000; Schalk, 2009; Schalk et al.,
2000
-
[23]
It computes the average recall across all classes
Table 3.Summary of Datasets Dataset #subjects #channels length of EEG #samples (Train-Val) or (Train-Val-Test) HBN-EEG (pretrain) 2449 128 10 seconds 482593-64991 PhysioNet-MI 109 64 4 seconds 6629-1429-1347 FACED 123 32 10 seconds 7308-1512-1512 Downstream Evaluation Metrics Balanced Accuracyis a performance metric used to evaluate models on imbalanced d...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.