B3O: Scalable Boltzmann Batch Bayesian Optimization
Pith reviewed 2026-06-30 07:48 UTC · model grok-4.3
The pith
Sampling batches directly from the acquisition function's Boltzmann distribution enables scalable large-batch Bayesian optimization with only negligible added regret.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
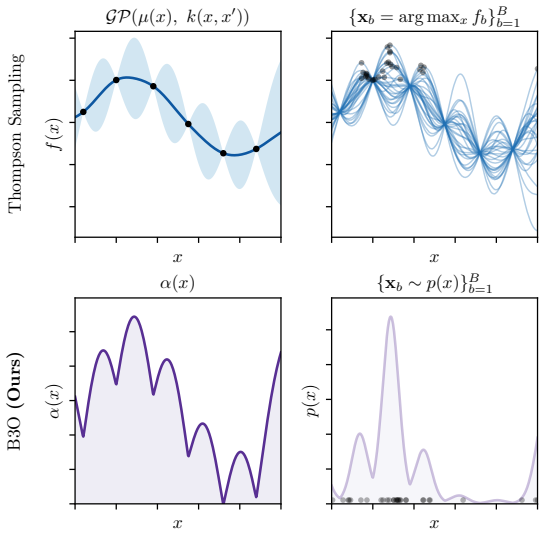
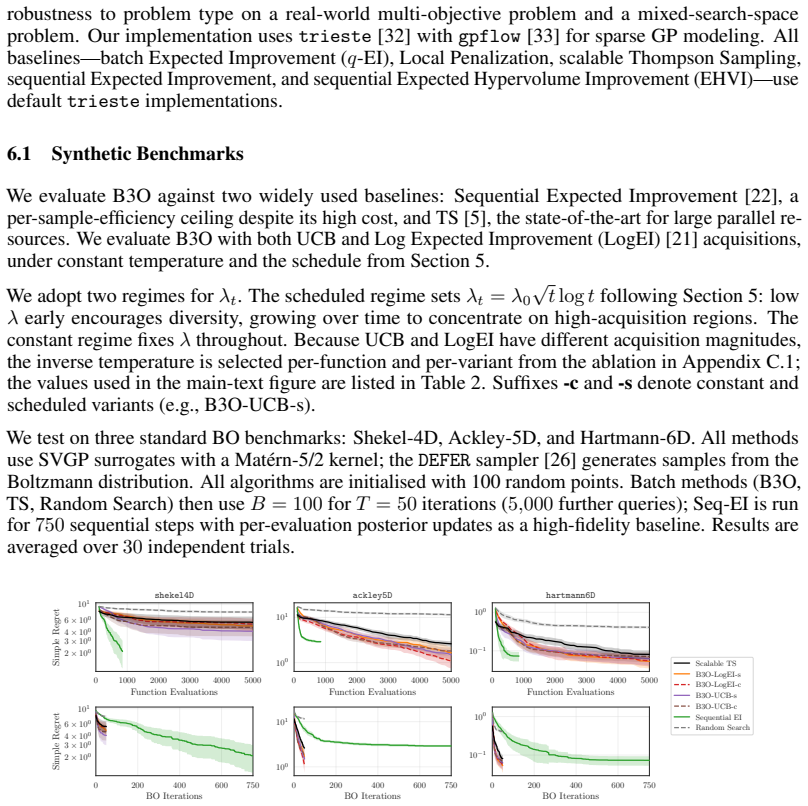
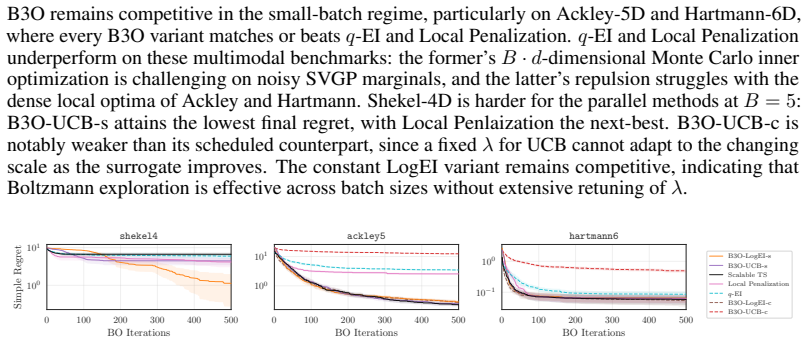
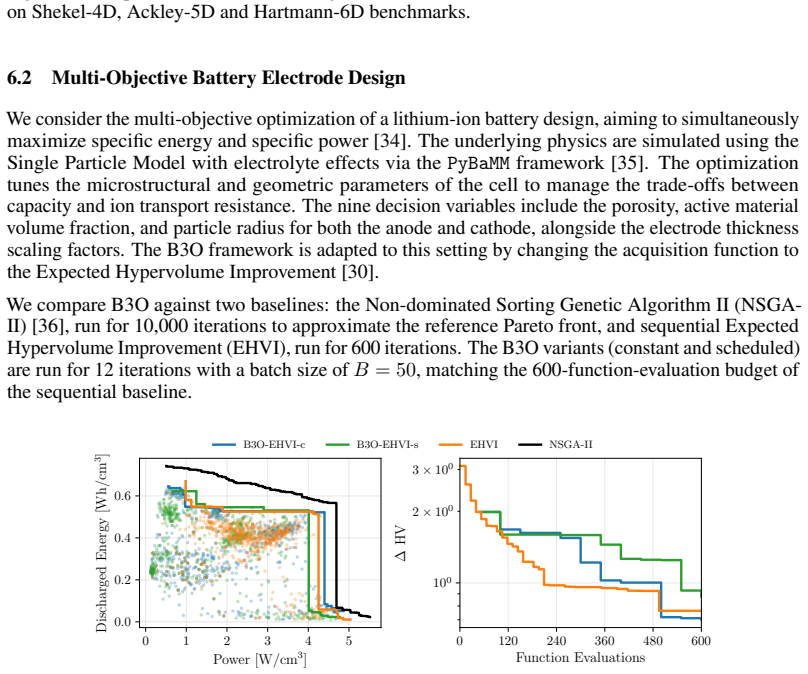
B3O reframes batch generation as a pure sampling problem by drawing samples directly from the Boltzmann distribution defined by the acquisition function. The paper proves that queries sampled from this distribution incur only negligible additional regret. It shows outperformance over existing batch BO methods on synthetic benchmarks and robust adaptation to complex tasks including multi-objective electrode design and mixed-variable race car configuration.
What carries the argument
The Boltzmann distribution induced by the acquisition function, used as the direct sampling source for batch queries.
If this is right
- Queries sampled from the distribution incur only negligible additional regret.
- B3O outperforms existing batch BO methods on standard synthetic benchmarks.
- The method adapts robustly across complex applied tasks including multi-objective electrode design.
- It successfully handles mixed-variable problems such as race car configuration.
Where Pith is reading between the lines
- The sampling formulation could let batch BO adopt fast MCMC or other statistical sampling tools without custom optimizers.
- If the regret property holds generally, explicit diversity penalties may become unnecessary in batch selection.
- The same Boltzmann-sampling idea might transfer to other parallel sequential decision settings outside Bayesian optimization.
Load-bearing premise
Efficient sampling from the Boltzmann distribution induced by typical acquisition functions is feasible at scale and preserves the necessary diversity without hidden computational or approximation costs.
What would settle it
A benchmark run in which Boltzmann-sampled batches produce regret exceeding the negligible bound by a significant margin, or where sampling time grows superlinearly with batch size.
Figures
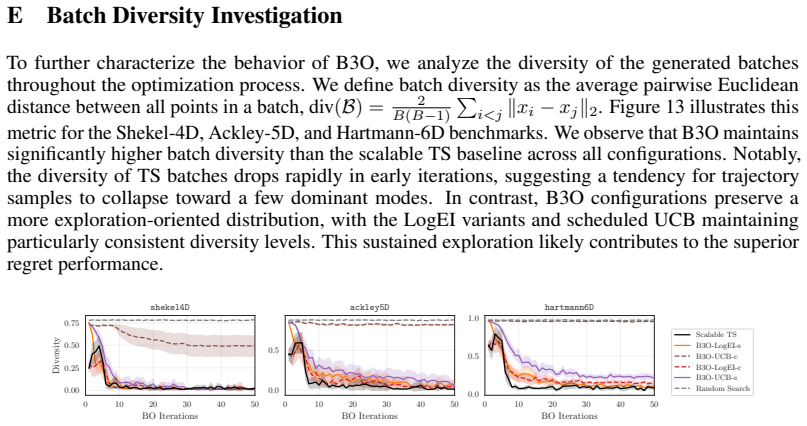
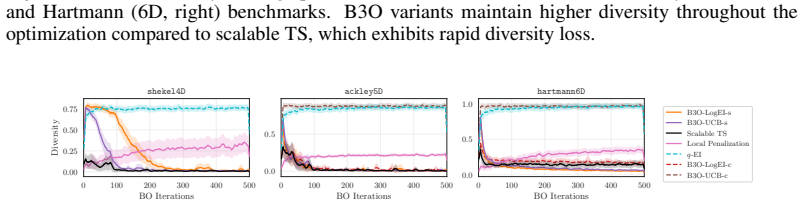
read the original abstract
Modern engineering workflows increasingly rely on massive parallel simulation, driving the need for scalable, large-batch Bayesian Optimization (BO). Existing batch BO methods, however, incur large computational cost or rely on approximations that erode batch diversity. We propose B3O (Boltzmann Batch Bayesian Optimization), a framework that reframes batch generation as a pure sampling problem: drawing samples directly from the Boltzmann distribution defined by the acquisition function avoids the bottlenecks of existing large-batch methods. Theoretically, we prove that queries sampled from this distribution incur only negligible additional regret. Empirically, B3O outperforms existing batch BO methods on standard synthetic benchmarks and adapts robustly across complex applied tasks, including multi-objective electrode design and mixed-variable race car configuration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces B3O, a batch Bayesian optimization framework that generates batches by directly sampling from the Boltzmann distribution p(x) ∝ exp(α(x)/T) induced by an acquisition function α. It claims a theoretical result that such samples incur only negligible additional regret relative to standard BO, and reports empirical outperformance over existing batch methods on synthetic benchmarks plus applied tasks such as multi-objective electrode design and mixed-variable optimization.
Significance. If the regret analysis holds for the implemented procedure and sampling remains tractable at scale while preserving diversity, B3O would offer a conceptually clean route to large-batch BO that avoids the computational bottlenecks or diversity loss of current methods. The empirical results on applied tasks would then constitute a practical contribution.
major comments (2)
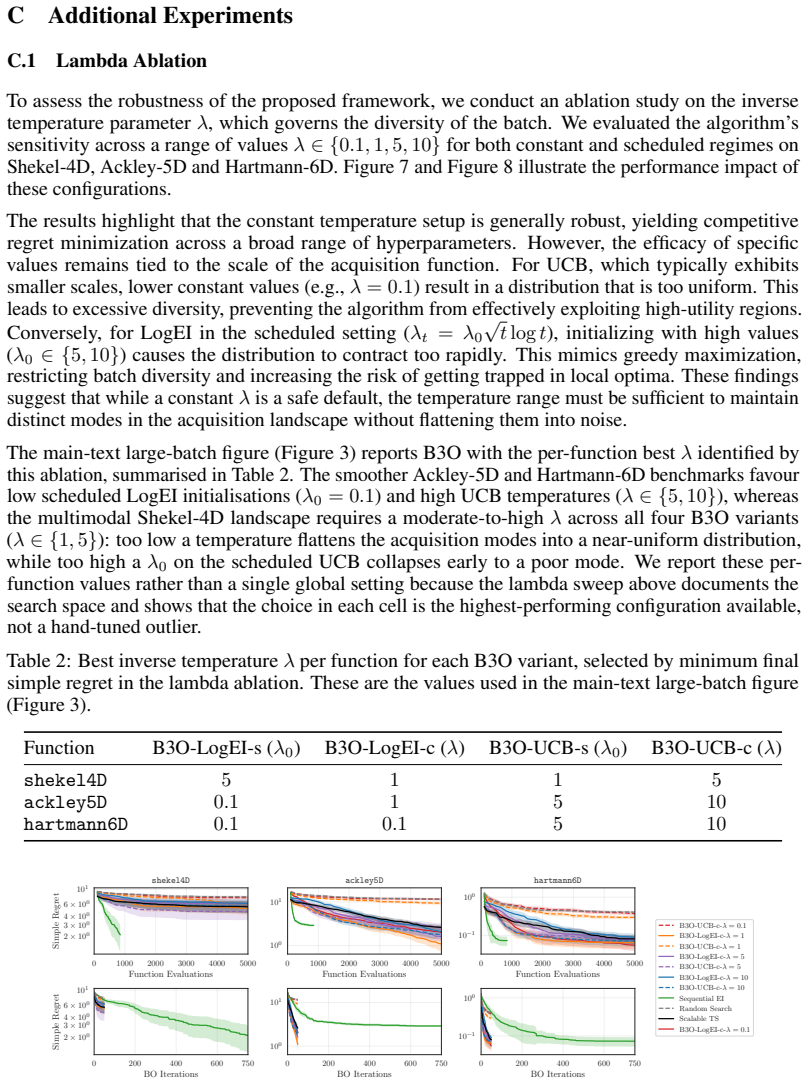
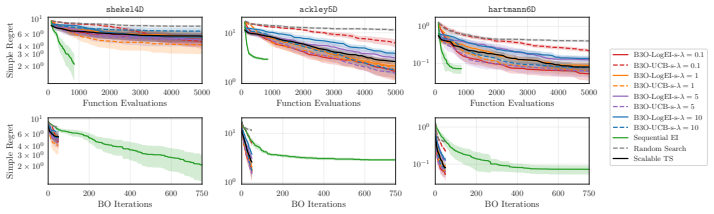
- [§3] §3 (Regret Analysis): The central theorem states that exact samples from the Boltzmann distribution incur negligible additional regret, but the manuscript does not derive or bound the propagation of sampling error (from MCMC, rejection sampling, or other approximations) into the batch regret. Because the implemented algorithm necessarily uses approximate sampling for typical acquisition functions, this gap is load-bearing for transferring the guarantee to the reported method.
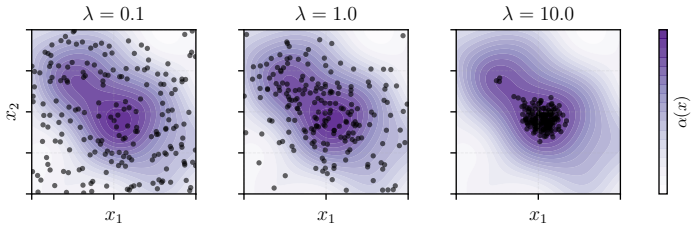
- [§4.2] §4.2 (Scalability Experiments): The reported wall-clock times and batch sizes assume efficient sampling; however, no ablation quantifies how the effective temperature T or the choice of sampler affects both regret and runtime, leaving open whether the claimed scalability holds when sampling cost is included.
minor comments (2)
- [§2] Notation for the Boltzmann distribution and temperature parameter T is introduced without an explicit reference to the acquisition function normalization used in the proof.
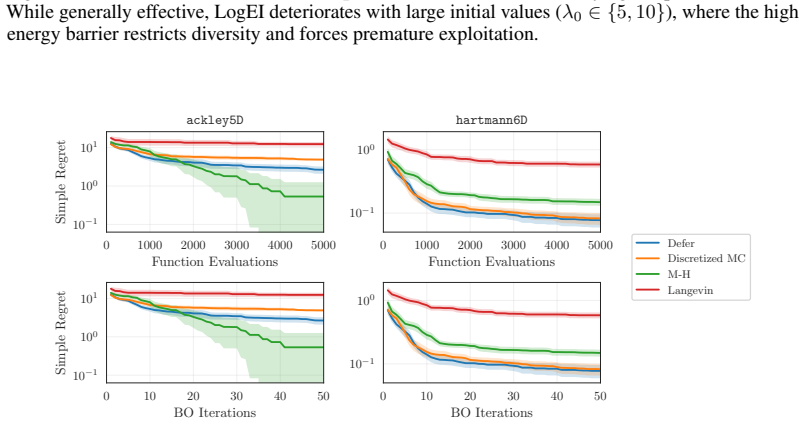
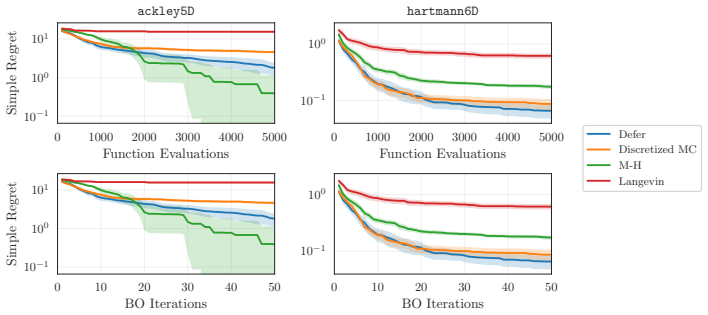
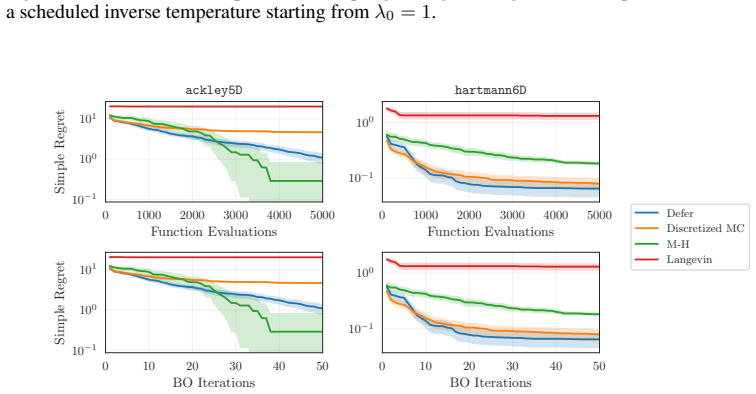
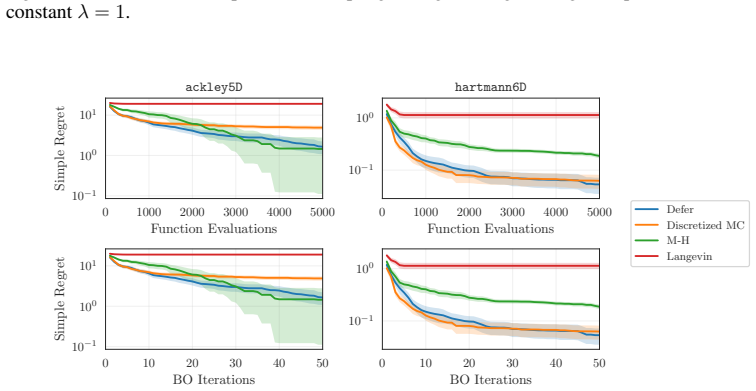
- [Figure 3] Figure 3 caption does not state the number of independent runs or the precise definition of the shaded region (standard error vs. min/max).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the regret analysis and scalability experiments. We address each point below and will revise the manuscript accordingly to strengthen the presentation of the theoretical guarantees and empirical validation.
read point-by-point responses
-
Referee: [§3] §3 (Regret Analysis): The central theorem states that exact samples from the Boltzmann distribution incur negligible additional regret, but the manuscript does not derive or bound the propagation of sampling error (from MCMC, rejection sampling, or other approximations) into the batch regret. Because the implemented algorithm necessarily uses approximate sampling for typical acquisition functions, this gap is load-bearing for transferring the guarantee to the reported method.
Authors: We agree that the stated theorem applies to exact samples from the Boltzmann distribution, while the implemented B3O relies on approximate sampling (e.g., MCMC). The current analysis does not explicitly bound the effect of sampling error on batch regret. In the revision we will add a dedicated subsection discussing this approximation gap, including a high-level argument that the total variation distance between the approximate and exact distributions can be controlled to preserve the negligible-regret property, supported by additional numerical checks on the samplers used in the experiments. revision: yes
-
Referee: [§4.2] §4.2 (Scalability Experiments): The reported wall-clock times and batch sizes assume efficient sampling; however, no ablation quantifies how the effective temperature T or the choice of sampler affects both regret and runtime, leaving open whether the claimed scalability holds when sampling cost is included.
Authors: We acknowledge that the scalability section does not include ablations on the temperature T or the specific sampler. We will expand §4.2 with new experiments that vary T across a range of values and compare multiple samplers (MCMC, rejection sampling, etc.), reporting both cumulative regret and wall-clock time. These results will be added to the revised manuscript to demonstrate that the claimed scalability remains robust when sampling cost is explicitly accounted for. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claim is a theoretical proof that exact samples from the Boltzmann distribution incur negligible additional regret, presented as independent of the empirical results. The abstract describes this as a proof without reference to fitted parameters, self-citations, or reductions by construction. No equations or sections in the provided text exhibit self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kriging is well-suited to paral- lelize optimization
David Ginsbourger, Rodolphe Le Riche, and Laurent Carraro. Kriging is well-suited to paral- lelize optimization. InComputational intelligence in expensive optimization problems, pages 131–162. Springer, 2010
2010
-
[2]
The reparameterization trick for acquisition functions
James T Wilson, Riccardo Moriconi, Frank Hutter, and Marc Peter Deisenroth. The reparame- terization trick for acquisition functions.arXiv preprint arXiv:1712.00424, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Batch bayesian optimization via local penalization
Javier González, Zhenwen Dai, Philipp Hennig, and Neil Lawrence. Batch bayesian optimization via local penalization. InArtificial intelligence and statistics, pages 648–657. PMLR, 2016
2016
-
[4]
On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika, 25(3/4):285–294, 1933
William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika, 25(3/4):285–294, 1933
1933
-
[5]
Scalable thompson sampling using sparse gaussian process models.Advances in neural information processing systems, 34:5631–5643, 2021
Sattar Vakili, Henry Moss, Artem Artemev, Vincent Dutordoir, and Victor Picheny. Scalable thompson sampling using sparse gaussian process models.Advances in neural information processing systems, 34:5631–5643, 2021
2021
-
[6]
Efficiently sampling functions from Gaussian process posteriors
James T Wilson, Viacheslav Borovitskiy, Alexander Terenin, Peter Mostowsky, and Marc Peter Deisenroth. Efficiently sampling functions from Gaussian process posteriors. InInternational Conference on Machine Learning, pages 10292–10302. PMLR, 2020
2020
-
[7]
Inducing point allocation for sparse gaussian processes in high-throughput bayesian optimisation
Henry B Moss, Sebastian W Ober, and Victor Picheny. Inducing point allocation for sparse gaussian processes in high-throughput bayesian optimisation. InInternational Conference on Artificial Intelligence and Statistics, pages 5213–5230. PMLR, 2023
2023
-
[8]
Predictive entropy search for efficient global optimization of black-box functions
José Miguel Hernández-Lobato, Matthew W Hoffman, and Zoubin Ghahramani. Predictive entropy search for efficient global optimization of black-box functions. InAdvances in Neural Information Processing Systems, 2014
2014
-
[9]
Efficient high dimensional bayesian optimization with additivity and quadrature fourier features.Advances in Neural Information Processing Systems 31, pages 9005–9016, 2019
Mojmír Mutn`y and Andreas Krause. Efficient high dimensional bayesian optimization with additivity and quadrature fourier features.Advances in Neural Information Processing Systems 31, pages 9005–9016, 2019
2019
-
[10]
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2–3):123–286, December 2012. ISSN 1935-8245. doi: 10.1561/2200000044. URLhttp://dx.doi.org/10.1561/2200000044
-
[11]
Batched gaussian process bandit optimization via determinantal point processes.Advances in neural information processing systems, 29, 2016
Tarun Kathuria, Amit Deshpande, and Pushmeet Kohli. Batched gaussian process bandit optimization via determinantal point processes.Advances in neural information processing systems, 29, 2016
2016
-
[12]
Diversified sampling for batched bayesian optimization with determinantal point processes, 2022
Elvis Nava, Mojmír Mutný, and Andreas Krause. Diversified sampling for batched bayesian optimization with determinantal point processes, 2022. URLhttps://arxiv.org/abs/2110. 11665
2022
-
[13]
Boltzmann exploration done right.Advances in neural information processing systems, 30, 2017
Nicolò Cesa-Bianchi, Claudio Gentile, Gábor Lugosi, and Gergely Neu. Boltzmann exploration done right.Advances in neural information processing systems, 30, 2017
2017
-
[14]
Fully distributed bayesian optimization with stochastic policies
J Garcia-Barcos and R Martinez-Cantin. Fully distributed bayesian optimization with stochastic policies. InIJCAI International Joint Conference on Artificial Intelligence, number ART-2019- 122825, 2019
2019
-
[15]
Advanced monte carlo for acquisition sampling in bayesian optimization.Entropy, 27(1):58, 2025
Javier Garcia-Barcos and Ruben Martinez-Cantin. Advanced monte carlo for acquisition sampling in bayesian optimization.Entropy, 27(1):58, 2025. doi: 10.3390/e27010058. 10
-
[16]
Stein boltzmann sampling: A varia- tional approach for global optimization
Gaëtan Serré, Argyris Kalogeratos, and Nicolas Vayatis. Stein boltzmann sampling: A varia- tional approach for global optimization. InInternational Conference on Artificial Intelligence and Statistics, pages 757–765. PMLR, 2025
2025
-
[17]
Gaussian processes for machine learning (gpml) toolbox.The Journal of Machine Learning Research, 11:3011–3015, 2010
Carl Edward Rasmussen and Hannes Nickisch. Gaussian processes for machine learning (gpml) toolbox.The Journal of Machine Learning Research, 11:3011–3015, 2010
2010
-
[18]
Yucen Lily Li, Tim GJ Rudner, and Andrew Gordon Wilson. A study of bayesian neural network surrogates for bayesian optimization.arXiv preprint arXiv:2305.20028, 2023
-
[19]
Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
2017
-
[20]
Variational learning of inducing variables in sparse gaussian processes
Michalis Titsias. Variational learning of inducing variables in sparse gaussian processes. In Artificial intelligence and statistics, pages 567–574. PMLR, 2009
2009
-
[21]
Unexpected improvements to expected improvement for bayesian optimization.Advances in neural information processing systems, 36:20577–20612, 2023
Sebastian Ament, Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Unexpected improvements to expected improvement for bayesian optimization.Advances in neural information processing systems, 36:20577–20612, 2023
2023
-
[22]
Efficient global optimization of expensive black-box functions.Journal of Global optimization, 13(4):455–492, 1998
Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions.Journal of Global optimization, 13(4):455–492, 1998
1998
-
[23]
Srinivas, A
N. Srinivas, A. Krause, S. Kakade, and M. Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. InProceedings of the 27th International Conference on Machine Learning, pages 1015–1022, 2010
2010
-
[24]
Thomas Desautels, Andreas Krause, and Joel W. Burdick. Parallelizing exploration-exploitation tradeoffs in gaussian process bandit optimization.Journal of Machine Learning Research, 15 (119):4053–4103, 2014. URLhttp://jmlr.org/papers/v15/desautels14a.html
2014
-
[25]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Introduction to reinforcement learning, volume 135. MIT press Cambridge, 1998
1998
-
[26]
Black-box density function estimation using recursive partitioning
Erik Bodin, Zhenwen Dai, Neill Campbell, and Carl Henrik Ek. Black-box density function estimation using recursive partitioning. InInternational Conference on Machine Learning, pages 1015–1025. PMLR, 2021
2021
-
[27]
Monte carlo sampling methods using markov chains and their applications
W Keith Hastings. Monte carlo sampling methods using markov chains and their applications. Biometrika, 57(1):97–109, 1970
1970
-
[28]
Understanding the metropolis-hastings algorithm.The american statistician, 49(4):327–335, 1995
Siddhartha Chib and Edward Greenberg. Understanding the metropolis-hastings algorithm.The american statistician, 49(4):327–335, 1995
1995
-
[29]
Exponential convergence of langevin distributions and their discrete approximations.Bernoulli, 2(4):341–363, 1996
Gareth O Roberts and Richard L Tweedie. Exponential convergence of langevin distributions and their discrete approximations.Bernoulli, 2(4):341–363, 1996
1996
-
[30]
Fast calculation of multiobjective probability of improvement and expected improvement criteria for pareto optimization.Journal of Global Optimization, 60(3):575–594, 2014
Ivo Couckuyt, Dirk Deschrijver, and Tom Dhaene. Fast calculation of multiobjective probability of improvement and expected improvement criteria for pareto optimization.Journal of Global Optimization, 60(3):575–594, 2014
2014
-
[31]
Bayesian optimization with inequality constraints
Jacob R Gardner, Matt J Kusner, Zhixiang Eddie Xu, Kilian Q Weinberger, and John P Cunning- ham. Bayesian optimization with inequality constraints. InProceedings of the 31st International Conference on Machine Learning - Volume 32, pages II–937–II–945. JMLR.org, 2014
2014
-
[32]
Trieste: Efficiently exploring the depths of black-box functions with TensorFlow, 2023
Joel Berkeley, Henry B Moss, Artem Artemev, Sergio Pascual-Diaz, Uri Granta, Hrvoje Stojic, Ivo Couckuyt, Jixiang Qing, Loka Satrio, and Victor Picheny. Trieste: Efficiently exploring the depths of black-box functions with TensorFlow, 2023. URL https://arxiv.org/abs/2302. 08436
2023
-
[33]
Gpflow: A gaussian process library using tensorflow.Journal of Machine Learning Research, 18(40):1–6, 2017
Alexander G de G Matthews, Mark Van Der Wilk, Tom Nickson, Keisuke Fujii, Alexis Bouk- ouvalas, Pablo León-Villagrá, Zoubin Ghahramani, and James Hensman. Gpflow: A gaussian process library using tensorflow.Journal of Machine Learning Research, 18(40):1–6, 2017. 11
2017
-
[34]
Multi-objective constrained optimization for energy applications via tree ensembles.Applied Energy, 306:118061, 2022
Alexander Thebelt, Calvin Tsay, Robert M Lee, Nathan Sudermann-Merx, David Walz, Tom Tranter, and Ruth Misener. Multi-objective constrained optimization for energy applications via tree ensembles.Applied Energy, 306:118061, 2022
2022
-
[35]
Python battery mathematical modelling (pybamm).Journal of Open Research Software, 9(1), 2021
Valentin Sulzer, Scott G Marquis, Robert Timms, Martin Robinson, and S Jon Chapman. Python battery mathematical modelling (pybamm).Journal of Open Research Software, 9(1), 2021
2021
-
[36]
A fast and elitist multiobjective genetic algorithm: Nsga-ii.IEEE transactions on evolutionary computation, 6 (2):182–197, 2002
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii.IEEE transactions on evolutionary computation, 6 (2):182–197, 2002
2002
-
[37]
A quasi-steady-state lap time simulation for electrified race cars
Alexander Heilmeier, Maximilian Geisslinger, and Johannes Betz. A quasi-steady-state lap time simulation for electrified race cars. In2019 Fourteenth International Conference on Ecological Vehicles and Renewable Energies (EVER). IEEE, May 2019. doi: 10.1109/ever.2019.8813646. URLhttps://doi.org/10.1109/ever.2019.8813646
-
[38]
Scalable global optimization via local bayesian optimization.Advances in neural information processing systems, 32, 2019
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local bayesian optimization.Advances in neural information processing systems, 32, 2019
2019
-
[39]
TREGO: a trust-region framework for efficient global optimization.Journal of Global Opti- mization, 86(1):1–23, 2023
Youssef Diouane, Victor Picheny, Rodolphe Le Riche, and Alexandre Scotto Di Perrotolo. TREGO: a trust-region framework for efficient global optimization.Journal of Global Opti- mization, 86(1):1–23, 2023
2023
-
[40]
On the limited memory bfgs method for large scale optimization
Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45(1):503–528, 1989. 12 A Detailed Proofs for Boltzmann Exploration In this section, we provide the proofs for the theoretical guarantees of the Boltzmann exploration strategy. These proofs rely on the assumptions of convexity of the inp...
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.