Comparing Human and Automatic Recognition of Dutch Dysarthric Continuous Speech: A Case Study
Pith reviewed 2026-06-30 06:30 UTC · model grok-4.3
The pith
Personalised dysarthric speech recognition models outperform human listeners on Dutch continuous speech from a single speaker
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuning state-of-the-art ASR systems on the dysarthric speech of one speaker with severe dysarthria produces models that achieve lower word error rates than human listeners on both read and spontaneous Dutch continuous speech, bringing performance closer to levels that could support day-to-day communication.
What carries the argument
Word error rate comparison between human listeners and off-the-shelf ASR systems before and after fine-tuning on the single speaker's data.
If this is right
- Fine-tuning significantly reduces word error rates on dysarthric speech.
- Personalised models achieve better recognition than human listeners.
- Performance approaches levels useful for supporting everyday communication.
- Spontaneous speech and longer utterances remain particularly difficult.
- Targeted work on specific phonemes could yield further gains.
Where Pith is reading between the lines
- Testing on additional speakers would clarify whether the outperformance generalizes.
- Integration with text prediction or language models could improve real-world usability.
- The personalization approach may extend to other speech disorders or languages.
- Real-time deployment in assistive devices could follow if error rates continue to drop.
Load-bearing premise
Results from one speaker with severe dysarthria indicate potential usefulness for day-to-day communication aids for dysarthric speakers more generally.
What would settle it
A study with multiple dysarthric speakers where personalised models do not outperform humans or fail to reach usable error rates would disprove the central claim.
Figures
read the original abstract
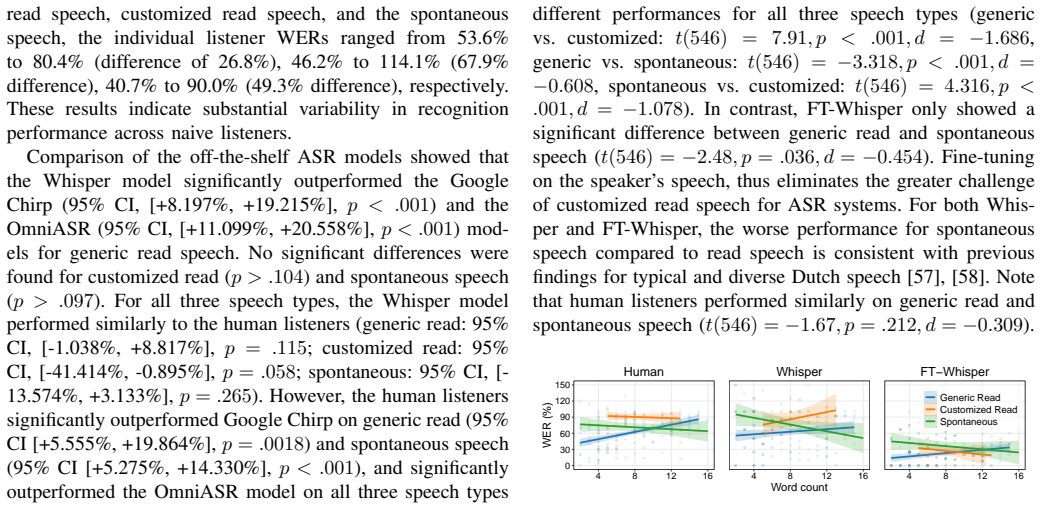
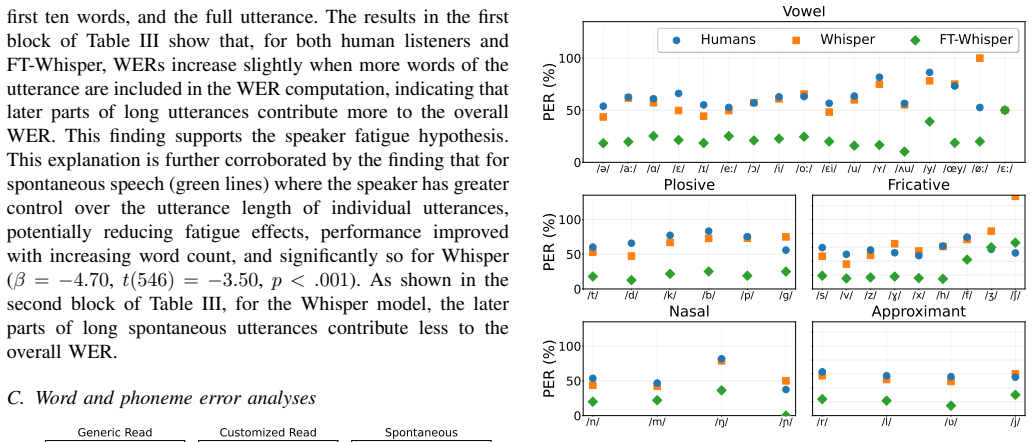
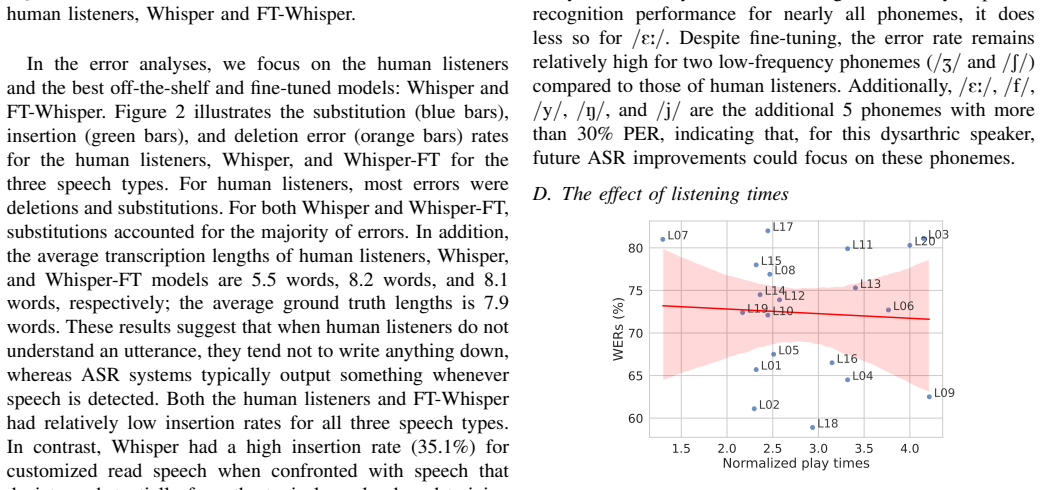
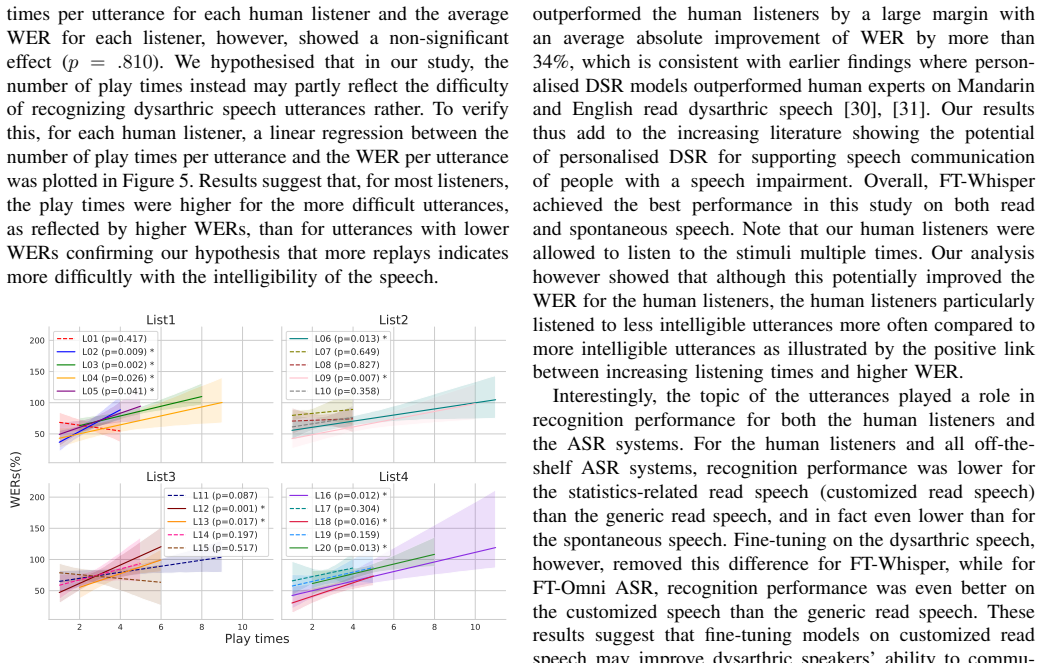
In our goal to develop personalised dysarthric speech recognition (DSR) models, this study compared the recognition performances of human listeners and those of three state-of-the-art, off-the-shelf ASR systems (Whisper-large-V3, Google Chirp 3, and Omnilingual) on the recognition of Dutch continuous read and spontaneous speech from a single speaker with severe dysarthria. Results showed that both humans listeners and the three off-the-shelf ASR systems exhibit word error rates (WER) exceeding 70% on average, indicating that DSR is highly challenging for both humans and ASR systems. Fine-tuning on the dysarthric speech significantly reduced WER. Although overall WERs are still quite high (>23%), the personalised DSR models outperformed the human listeners, and performance is getting closer to being useful for supporting day-to-day communication of dysarthric speakers. Future research should focus on improving personalized DSR on spontaneous speech and longer utterances in the case of read speech, with a specific focus on particular phonemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a single-speaker case study comparing human listeners and three off-the-shelf ASR systems (Whisper-large-V3, Google Chirp 3, Omnilingual) on Dutch read and spontaneous dysarthric speech. It reports average WERs >70% for both humans and baseline ASR, but shows that fine-tuning yields personalized models with WER >23% that outperform the human listeners, concluding that performance is approaching utility for day-to-day communication support.
Significance. If the empirical comparison holds, the work supplies a concrete data point that personalization via fine-tuning can exceed human listener performance on severe dysarthric Dutch speech, offering a proof-of-concept for tailored DSR systems in assistive applications.
major comments (2)
- [Abstract] Abstract: the inference that 'performance is getting closer to being useful for supporting day-to-day communication of dysarthric speakers' does not follow from the reported WER reduction; the manuscript provides no communicative success metrics, multi-speaker data, or severity-stratified results to support generalization beyond this single severe-dysarthria case.
- [Abstract] Abstract/Results: the outperformance claim (personalized WER >23% vs. human listeners) is presented without error bars, statistical tests, dataset size, or exclusion criteria, leaving the reliability of the human-ASR comparison only partially supported.
minor comments (1)
- [Abstract] Abstract: the three ASR systems are named but their selection criteria or exact versions could be stated more explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our single-speaker case study. We respond to each major comment below and indicate the revisions that will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the inference that 'performance is getting closer to being useful for supporting day-to-day communication of dysarthric speakers' does not follow from the reported WER reduction; the manuscript provides no communicative success metrics, multi-speaker data, or severity-stratified results to support generalization beyond this single severe-dysarthria case.
Authors: We agree that the abstract statement regarding utility for day-to-day communication is an extrapolation that does not follow directly from the WER results in this single-speaker case study. The manuscript contains no communicative success metrics, multi-speaker data, or severity stratification. We will revise the abstract to remove this claim and instead present the WER reduction and outperformance finding strictly as an observation from the reported case, with a call for future work on communicative utility. revision: yes
-
Referee: [Abstract] Abstract/Results: the outperformance claim (personalized WER >23% vs. human listeners) is presented without error bars, statistical tests, dataset size, or exclusion criteria, leaving the reliability of the human-ASR comparison only partially supported.
Authors: The full manuscript describes the utterance set from the single speaker and the human listening protocol, but these details are not restated in the abstract. We will revise both the abstract and results sections to report the dataset size (number of read and spontaneous utterances), number of human listeners, and any exclusion criteria. Error bars and statistical tests are not feasible in a single-speaker case study without additional data collection; we will add an explicit discussion of this limitation to qualify the comparison. revision: partial
Circularity Check
No circularity: purely empirical case study with measured WERs
full rationale
The paper reports an empirical comparison of human listeners and ASR systems (including fine-tuned models) on read and spontaneous Dutch dysarthric speech from one speaker. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All performance claims rest on direct measurement of word error rates rather than any self-referential logic or imported uniqueness theorems. The single-speaker limitation is a generalizability concern, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The interspeech 2008 consonant chal- lenge,
M. Cooke and O. Scharenborg, “The interspeech 2008 consonant chal- lenge,” inInterspeech, 2008, pp. 1765–1768
2008
-
[2]
Speech recognition by machines and humans,
R. P. Lippmann, “Speech recognition by machines and humans,”Speech communication, vol. 22, no. 1, pp. 1–15, 1997
1997
-
[3]
Comparing human and automatic speech recognition in simple and complex acoustic scenes,
C. Spille, B. Kollmeier, and B. T. Meyer, “Comparing human and automatic speech recognition in simple and complex acoustic scenes,” Computer Speech & Language, vol. 52, pp. 123–140, 2018
2018
-
[4]
Achieving Human Parity in Conversational Speech Recognition
W. Xiong, J. Droppo, X. Huang, F. Seide, M. Seltzer, A. Stolcke, D. Yu, and G. Zweig, “Achieving human parity in conversational speech recognition,”arXiv preprint arXiv:1610.05256, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Speech recognition in adverse conditions by humans and machines
C. Patman and E. Chodroff, “Speech recognition in adverse conditions by humans and machines.”Journal of the Acoustical Society of America - Express Letters, vol. 4 11, 2024
2024
-
[6]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[7]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020
2020
-
[8]
Google USM: Scaling Au- tomatic Speech Recognition Beyond 100 Languages,
Y . Zhang, W. Han, J. Qin, Y . Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V . Axelrod, G. Wang, Z. Meng, K. Hu, A. Rosenberg, R. Prabhavalkar, D. S. Park, P. Haghani, J. Riesa, G. Perng, H. Soltau, T. Strohman, B. Ramabhadran, T. Sainath, P. Moreno, C.-C. Chiu, J. Schalkwyk, F. Beaufays, and Y . Wu, “Google usm: Scaling automatic speech recognition beyond 1...
-
[9]
Applications of machine learning in speech recognition,
A. Davitaia, “Applications of machine learning in speech recognition,” Available at SSRN 5329566, 2025
2025
-
[10]
Wienrich, C
C. Wienrich, C. Reitelbach, and A. Carolus, “The trustworthiness of voice assistants in the context of healthcare investigating the effect of perceived expertise on the trustworthiness of voice assistants, providers, data receivers, and automatic speech recognition,”Frontiers in Computer Science, vol. 3, p. 685250, 2021
2021
-
[11]
Life after speech recognition: Fuzzing semantic misinterpretation for voice assistant applications,
Y . Zhang, L. Xu, A. Mendoza, G. Yang, P. Chinprutthiwong, and G. Gu, “Life after speech recognition: Fuzzing semantic misinterpretation for voice assistant applications,” inProceedings of the of the Network and Distributed System Security Symposium (NDSS’19), 2019
2019
-
[12]
Assessing the effectiveness of automatic speech recognition technology in emergency medicine settings: a comparative study of four ai-powered engines,
X. Luo, L. Zhou, K. Adelgais, and Z. Zhang, “Assessing the effectiveness of automatic speech recognition technology in emergency medicine settings: a comparative study of four ai-powered engines,”Journal of Healthcare Informatics Research, pp. 1–19, 2025
2025
-
[13]
Improved healthcare diagnosis accuracy through the application of deep learning techniques in medical transcription for disease identification,
A. Elhadad, I. Alrashdi, A. M. Albarrak, S. R. I. Elrefaey, H. A. E. Elsayed, F. M. Embarak, Z. Ulmas, and Y . A. B. El-Ebiary, “Improved healthcare diagnosis accuracy through the application of deep learning techniques in medical transcription for disease identification,”Alexan- dria Engineering Journal, vol. 123, pp. 112–123, 2025
2025
-
[14]
A comprehensive analysis of speech recognition systems in healthcare: current research challenges and future prospects,
Y . Kumar, “A comprehensive analysis of speech recognition systems in healthcare: current research challenges and future prospects,”SN Computer Science, vol. 5, no. 1, p. 137, 2024
2024
-
[15]
Explor- ing data augmentation in bias mitigation against non-native-accented speech,
Y . Zhang, A. Herygers, T. Patel, Z. Yue, and O. Scharenborg, “Explor- ing data augmentation in bias mitigation against non-native-accented speech,” in2023 IEEE Automatic Speech Recognition and Understand- ing Workshop (ASRU), 2023, pp. 1–8
2023
-
[16]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[17]
Speech recognition in adverse conditions by humans and machines,
C. Patman and E. Chodroff, “Speech recognition in adverse conditions by humans and machines,”JASA Express Letters, vol. 4, no. 11, 2024
2024
-
[18]
On the Limit of English Conversational Speech Recognition,
Z. T ¨uske, G. Saon, and B. Kingsbury, “On the Limit of English Conversational Speech Recognition,” inInterspeech 2021, 2021, pp. 2062–2066
2021
-
[19]
Toward Zero Oracle Word Error Rate on the Switchboard Benchmark,
A. Faria, A. Janin, S. Adkoli, and K. Riedhammer, “Toward Zero Oracle Word Error Rate on the Switchboard Benchmark,” inInterspeech 2022, 2022, pp. 3973–3977
2022
-
[20]
Bigssl: Exploring the frontier of large-scale semi-supervised learning for automatic speech recognition,
Y . Zhang, D. S. Park, W. Han, J. Qin, A. Gulati, J. Shor, A. Jansen, Y . Xu, Y . Huang, S. Wanget al., “Bigssl: Exploring the frontier of large-scale semi-supervised learning for automatic speech recognition,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1519–1532, 2022
2022
-
[21]
Toward human parity in conversational speech recognition,
W. Xiong, J. Droppo, X. Huang, F. Seide, M. L. Seltzer, A. Stolcke, D. Yu, and G. Zweig, “Toward human parity in conversational speech recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 12, pp. 2410–2423, 2017
2017
-
[22]
English conversational telephone speech recognition by humans and machines,
G. Saon, T. Sercu, K. Audhkhasi, S. Thomas, D. Dimitriadis, X. Cui, B. Ramabhadran, M. Picheny, G. Kurata, L. Limet al., “English conversational telephone speech recognition by humans and machines,” inProceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, 2017, pp. 132–136
2017
-
[23]
On the impact of dysarthric speech on contemporary asr cloud platforms,
L. De Russis and F. Corno, “On the impact of dysarthric speech on contemporary asr cloud platforms,”Journal of Reliable Intelligent Environments, vol. 5, no. 3, pp. 163–172, 2019
2019
-
[24]
The torgo database of acoustic and articulatory speech from speakers with dysarthria,
F. Rudzicz, A. K. Namasivayam, and T. Wolff, “The torgo database of acoustic and articulatory speech from speakers with dysarthria,” Language resources and evaluation, vol. 46, no. 4, pp. 523–541, 2012
2012
-
[25]
A. Alsayegh and T. Masood, “Zero-shot recognition of dysarthric speech using commercial automatic speech recognition and multimodal large language models,”arXiv preprint arXiv:2512.17474, 2025
-
[26]
Individual differences in the perception of regional, nonnative, and disordered speech varieties,
T. Bent, M. Baese-Berk, S. A. Borrie, and M. McKee, “Individual differences in the perception of regional, nonnative, and disordered speech varieties,”The Journal of the Acoustical Society of America, vol. 140, no. 5, pp. 3775–3786, 2016
2016
-
[27]
The role of listener familiarity in the perception of dysarthric speech,
K. K. Tjaden and J. M. Liss, “The role of listener familiarity in the perception of dysarthric speech,”Clinical linguistics & phonetics, vol. 9, no. 2, pp. 139–154, 1995
1995
-
[28]
Comparing humans and automatic speech recognition systems in recognizing dysarthric speech,
K. T. Mengistu and F. Rudzicz, “Comparing humans and automatic speech recognition systems in recognizing dysarthric speech,” inCana- dian Conference on Artificial Intelligence. Springer, 2011, pp. 291–300
2011
-
[29]
Familiarization effects on consonant intelligibility in dysarthric speech,
H. Kim, “Familiarization effects on consonant intelligibility in dysarthric speech,”Folia Phoniatrica et Logopaedica, vol. 67, no. 5, pp. 245–252, 2016
2016
-
[30]
Cdsd: Chinese dysarthria speech database,
M. Sun, M. Gao, X. Kang, S. Wang, J. Du, D. Yao, and S.-J. Wang, “Cdsd: Chinese dysarthria speech database,”arXiv preprint arXiv:2310.15930, 2023
-
[31]
Automatic Speech Recognition of Disordered Speech: Personalized Models Outperforming Human Listeners on Short Phrases,
J. R. Green, R. L. MacDonald, P.-P. Jiang, J. Cattiau, R. Heywood, R. Cave, K. Seaver, M. A. Ladewig, J. Tobin, M. P. Brenner, P. C. Nelson, and K. Tomanek, “Automatic Speech Recognition of Disordered Speech: Personalized Models Outperforming Human Listeners on Short Phrases,” inInterspeech 2021, 2021, pp. 4778–4782
2021
-
[32]
Developing an acoustic-phonetic characterization of dysarthric speech in french,
C. Fougeron, L. Crevier-Buchman, C. Fredouille, A. Ghio, C. Meu- nier, C. Chevrie-Muller, N. Audibert, J.-F. Bonastre, A. Colazo-Simon, C. Deloozeet al., “Developing an acoustic-phonetic characterization of dysarthric speech in french,” in7th International Conference on Language Resources, Technologies and Evaluation (LREC), vol. 1, no. 1. Nicoletta Calzo...
2010
-
[33]
A comparative study of adaptive, automatic recognition of disordered speech,
H. Christensen, S. Cunningham, C. Fox, P. Green, and T. Hain, “A comparative study of adaptive, automatic recognition of disordered speech,” inInterspeech 2012, 2012, pp. 1776–1779
2012
-
[34]
Enhancing dysarthric speech recognition through sepformer and hierarchical attention network models with multistage transfer learning,
R. Vinotha, D. Hepsiba, L. Vijay Anand, J. Andrew, and R. Jennifer Eu- nice, “Enhancing dysarthric speech recognition through sepformer and hierarchical attention network models with multistage transfer learning,” Scientific Reports, vol. 14, no. 1, p. 29455, 2024
2024
-
[35]
Automatic recognition of Dutch dysarthric speech: A pilot study,
E. Sanders, M. Ruiter, L. Beijer, and H. Strik, “Automatic recognition of Dutch dysarthric speech: A pilot study,” inInterspeech. ISCA, Sep. 2002, pp. 661–664
2002
-
[36]
Personalizing asr for dysarthric and accented speech with limited data,
J. Shor, D. Emanuel, O. Lang, O. Tuval, M. Brenner, J. Cattiau, F. Vieira, M. McNally, T. Charbonneau, M. Nollstadt, A. Hassidim, and Y . Matias, “Personalizing asr for dysarthric and accented speech with limited data,” inInterspeech 2019, vol. 2019-September, 2019, pp. 784–788
2019
-
[37]
Personalized automatic speech recognition trained on small disordered speech datasets,
J. Tobin and K. Tomanek, “Personalized automatic speech recognition trained on small disordered speech datasets,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2022, pp. 6637–6641
2022
-
[38]
A speech-controlled environmental control system for people with severe dysarthria,
M. S. Hawley, P. Enderby, P. Green, S. Cunningham, S. Brownsell, J. Carmichael, M. Parker, A. Hatzis, P. O’Neill, and R. Palmer, “A speech-controlled environmental control system for people with severe dysarthria,”Medical Engineering & Physics, vol. 29, no. 5, pp. 586–593, 2007
2007
-
[39]
Inclusive speech technology: Developing automatic speech recognition for everyone,
O. Scharenborg, “Inclusive speech technology: Developing automatic speech recognition for everyone,” Webinar delivered to the TU Delft Safety and Security Institute and Campus, The Hague, the Netherlands, 2021
2021
-
[40]
Whisper-large-v3,
OpenAI, “Whisper-large-v3,” 2023. [Online]. Available: https: //huggingface.co/openai/whisper-large-v3
2023
-
[41]
Speech-to-text: Transcription models,
Google Cloud, “Speech-to-text: Transcription models,” https://cloud. google.com/speech-to-text/docs/transcription-model, 2026, accessed: 2026-02-18
2026
-
[42]
Omnilingual asr: Open-source multilingual speech recognition for 1600+ languages
A. Omnilingual, G. Keren, A. Kozhevnikov, Y . Meng, C. Ropers, M. Set- zler, S. Wang, I. Adebara, M. Auli, C. Baliogluet al., “Omnilingual asr: Open-source multilingual speech recognition for 1600+ languages,” arXiv preprint arXiv:2511.09690, 2025
-
[43]
Dysone: dysarthric audio-video dataset in dutch and english
T. be filled in upon acceptance of this manuscript, “Dysone: dysarthric audio-video dataset in dutch and english.”
-
[44]
The Spoken Dutch Corpus. Overview and first evaluation,
N. Oostdijk, “The Spoken Dutch Corpus. Overview and first evaluation,” inProc. of the 2nd International Conference on Language Resources and Evaluation. Athens, Greece: European Language Resources Association, May 2000
2000
-
[45]
Streamlit,
“Streamlit,” 2026. [Online]. Available: https://streamlit.io
2026
-
[46]
Lexical information drives perceptual learning of distorted speech: evidence from the comprehension of noise-vocoded sentences
M. H. Davis, I. S. Johnsrude, A. Hervais-Adelman, K. Taylor, and C. McGettigan, “Lexical information drives perceptual learning of distorted speech: evidence from the comprehension of noise-vocoded sentences.”Journal of Experimental Psychology: General, vol. 134, no. 2, p. 222, 2005
2005
-
[47]
Language and voice support for the speech service,
Microsoft, “Language and voice support for the speech service,” https://learn.microsoft.com/en-us/azure/ai-services/speech-service/ language-support?tabs=stt, 2025, accessed: 2026-06-21
2025
-
[48]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandiet al., “Scaling speech technology to 1,000+ languages,”Journal of Machine Learning Re- search, vol. 25, no. 97, pp. 1–52, 2024
2024
-
[49]
Speech recognition per- formance disparities between dutch diverse speaker groups,
Y . Zhang, T. De Valck, and O. Scharenborg, “Speech recognition per- formance disparities between dutch diverse speaker groups,”Phonetica, no. 0, 2026
2026
-
[50]
Granary: Speech recognition and translation dataset in 25 european languages,
N. R. Koluguri, M. Sekoyan, G. Zelenfroynd, S. Meister, S. Ding, S. Kostandian, H. Huang, N. Karpov, J. Balam, V . Lavrukhinet al., “Granary: Speech recognition and translation dataset in 25 european languages,”arXiv preprint arXiv:2505.13404, 2025
-
[51]
omniasr-llm-300m-v2,
The Omnilingual ASR Team, “omniasr-llm-300m-v2,” 2025. [Online]. Available: https://huggingface.co/bezzam/omniasr-llm-300m-v2
2025
-
[52]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[53]
Bootstrap estimates for confidence intervals in asr performance evaluation,
M. Bisani and H. Ney, “Bootstrap estimates for confidence intervals in asr performance evaluation,” inIEEE ICASSP, vol. 1, 2004, pp. I–409
2004
-
[54]
Good practices for eval- uation of machine learning systems,
L. Ferrer, O. Scharenborg, and T. B ¨ackstr¨om, “Good practices for eval- uation of machine learning systems,”arXiv preprint arXiv:2412.03700, 2024
-
[55]
D. D. Boos and L. A. Stefanski,Essential Statistical Inference: Theory and Methods. Springer, 2013, section 11.6: Bootstrap Resampling for Hypothesis Tests
2013
-
[56]
Emmeans: Estimated marginal means, aka least-squares means
R. Lenth, “Emmeans: Estimated marginal means, aka least-squares means .”R package version 2.0. 1, 2023
2023
-
[57]
Towards inclusive automatic speech recognition,
S. Feng, B. M. Halpern, O. Kudina, and O. Scharenborg, “Towards inclusive automatic speech recognition,”Computer Speech & Language, vol. 84, p. 101567, 2024
2024
-
[58]
Uncovering bias in asr systems: Evaluating wav2vec2 and whisper for dutch speakers,
M. Fuckner, S. Horsman, P. Wiggers, and I. Janssen, “Uncovering bias in asr systems: Evaluating wav2vec2 and whisper for dutch speakers,” in2023 International Conference on Speech Technology and Human- Computer Dialogue (SpeD). IEEE, 2023, pp. 146–151
2023
-
[59]
Low-resource automatic speech recognition and error analyses of oral cancer speech,
B. M. Halpern, S. Feng, R. van Son, M. van den Brekel, and O. Scharen- borg, “Low-resource automatic speech recognition and error analyses of oral cancer speech,”Speech Communication, vol. 141, pp. 14–27, 2022
2022
-
[60]
Relative phoneme analysis,
B. M. Halpern, “Relative phoneme analysis,” 2020. [Online]. Available: https://github.com/karkirowle/relative phoneme analysis
2020
-
[61]
Effects of replay on the iin- telligibility of noisy speech,
G. Hilkhuysen, J. Lloyd, and M. Huckvale, “Effects of replay on the iin- telligibility of noisy speech,” inAudio Engineering Society Conference: 46th International Conference: Audio Forensics. Audio Engineering Society, 2012
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.