Multi-Agentic System Leveraging Open-Source LLMs to Mitigate Disinformation Threats
Pith reviewed 2026-06-30 06:24 UTC · model grok-4.3
The pith
A multi-agent system of open-source LLMs outperforms single models like GPT-4 at disinformation detection by using consensus, diverse knowledge, and hierarchy to mimic human annotators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their multi-agent system, which uses a consensus mechanism, diversity in cognition and knowledge, and hierarchical structure inspired by human annotators, achieves superior results in disinformation detection compared to individual LLMs including GPT-4 and GPT-3.5. The system is built with open-source models like LLaMA and others for transparency and is evaluated on datasets in four languages with varying resource levels on three different tasks related to disinformation.
What carries the argument
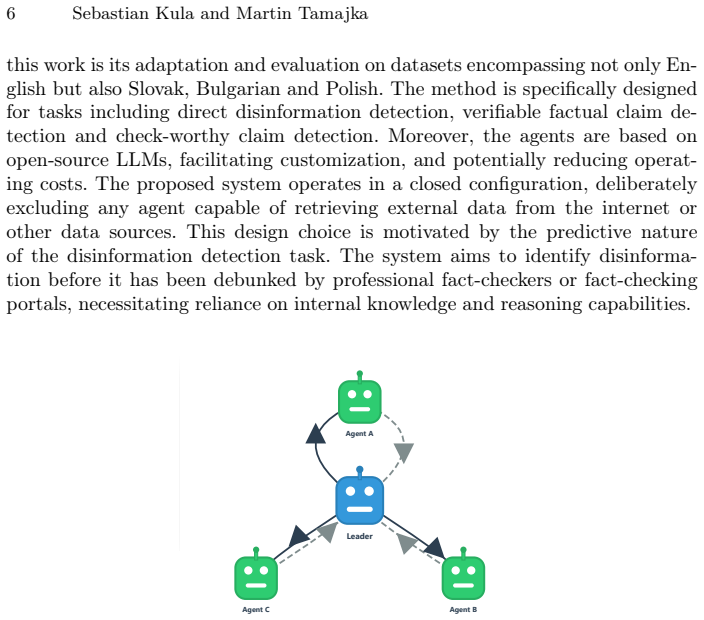
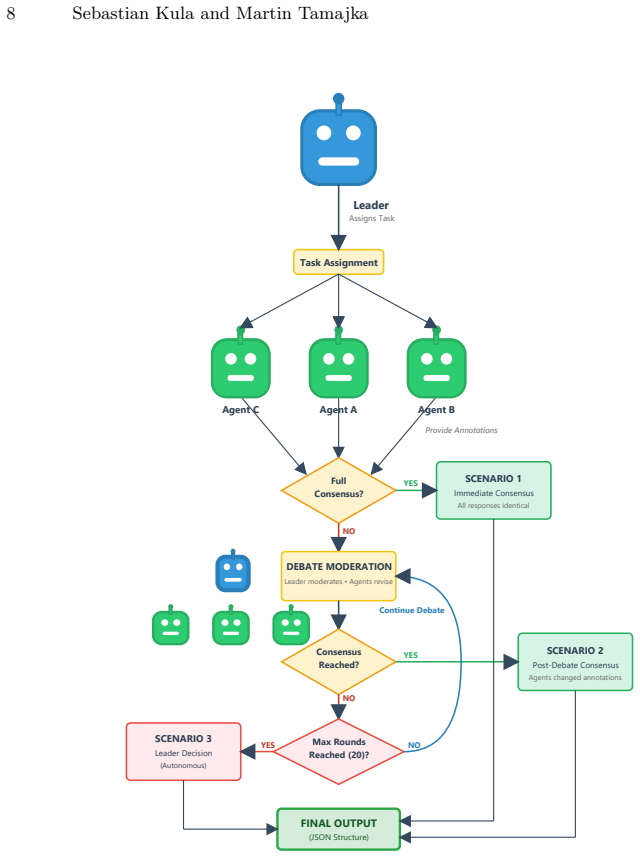
Multi-agent system emulating human annotators via consensus mechanism, diversity in cognition and knowledge, and hierarchical structure.
If this is right
- The system improves performance on low-resource languages such as Slovak and Bulgarian.
- It enables transparent, open-source alternatives to proprietary models for fact-checking tasks.
- The method applies across direct detection, identifying texts worthy of verification, and detecting verifiable claims.
- It provides a scalable automated approach to handle high volumes of disinformation where manual review falls short.
Where Pith is reading between the lines
- The approach could extend to other content moderation problems that benefit from ensemble decision-making.
- Diversity across open models may help reduce certain biases that appear in single proprietary LLMs.
- Real-time deployment on social media streams would test whether the consensus overhead remains practical at scale.
Load-bearing premise
Emulating human annotator behavior with consensus, diversity in cognition and knowledge, and hierarchy in a multi-agent LLM setup will reliably produce better disinformation detection than single models.
What would settle it
A demonstration that GPT-4 or another single LLM matches or exceeds the multi-agent system's accuracy on the same multilingual datasets and tasks would falsify the superiority claim.
Figures
read the original abstract
In contemporary societies, the threat of disinformation has reached alarming levels, exacerbated by the proliferation of electronic communication, social media, and advancements in artificial intelligence. As a result, there is an urgent need to develop effective countermeasures to mitigate this menace. However, the sheer scale of the problem renders manual fact-checking and human-based verification inadequate, underscoring the necessity for automated methods to detect and debunk disinformation. This article proposes a novel approach based on a multi-agent system that emulates the decision-making processes of human annotators engaged in disinformation detection tasks. By incorporating a consensus mechanism, diversity in cognition and diversity in knowledge, and also hierarchical structure, inspired by human annotators' behavior, the proposed method achieves superior results compared to individual Large Language Models (LLMs), including GPT 4 and GPT 3.5. The system leverages open models (e.g., LLaMA, Kimi, Qwen, Deepseek and LLaMA-Nemotron) to ensure greater transparency. The evaluation of the proposed method encompasses datasets in languages with varying resource availability, including English (high-resource), Polish (medium-resource), Slovak (low-resource) and Bulgarian (low-resource). Experiments were conducted on tasks such as direct disinformation detection, identification of texts worthy of verification, and detection of texts containing verifiable factual claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a multi-agent system using open-source LLMs (LLaMA, Kimi, Qwen, Deepseek, LLaMA-Nemotron) to detect disinformation by emulating human annotators via consensus mechanisms, cognitive and knowledge diversity, and hierarchical structure. It evaluates the approach on three tasks—direct disinformation detection, identification of texts worthy of verification, and detection of verifiable factual claims—across English (high-resource), Polish (medium-resource), Slovak and Bulgarian (low-resource) datasets, claiming superior performance to individual models including GPT-4 and GPT-3.5 while emphasizing transparency.
Significance. If substantiated with quantitative evidence and controls, the work could advance transparent, open-source tools for disinformation mitigation in multilingual settings, including low-resource languages. The multi-agent emulation of human processes offers a potentially interesting direction for robustness, though its advantages require verification against simpler baselines.
major comments (2)
- [Abstract] Abstract: The assertion that the method 'achieves superior results compared to individual Large Language Models (LLMs), including GPT 4 and GPT 3.5' is made without any reported metrics, baselines, statistical tests, dataset statistics, or effect sizes. This directly prevents assessment of the central empirical claim.
- [Evaluation] Evaluation: No ablation studies are described that isolate the effects of the consensus mechanism, cognitive/knowledge diversity, or hierarchical structure (e.g., by removing one while holding model set and prompting fixed). Without them, gains cannot be attributed to the claimed human-emulation design rather than generic ensembling or prompt variations, weakening the causal link in the main contribution.
minor comments (2)
- The distinction between 'diversity in cognition' and 'diversity in knowledge' is mentioned but not operationalized with concrete implementation details or examples; this should be clarified in the methods for reproducibility.
- Specify exact model versions, sizes, and prompting templates used for the open-source LLMs to support replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the empirical presentation and causal attribution in our work. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the method 'achieves superior results compared to individual Large Language Models (LLMs), including GPT 4 and GPT 3.5' is made without any reported metrics, baselines, statistical tests, dataset statistics, or effect sizes. This directly prevents assessment of the central empirical claim.
Authors: We agree that the abstract should be self-contained and include quantitative support for the central claim. The body of the manuscript reports full metrics, baselines (including GPT-4 and GPT-3.5), statistical tests, dataset sizes, and effect sizes across the four languages and three tasks. In revision we will condense the key results (e.g., accuracy/F1 gains, p-values, and dataset statistics) into the abstract so readers can immediately evaluate the claim. revision: yes
-
Referee: [Evaluation] Evaluation: No ablation studies are described that isolate the effects of the consensus mechanism, cognitive/knowledge diversity, or hierarchical structure (e.g., by removing one while holding model set and prompting fixed). Without them, gains cannot be attributed to the claimed human-emulation design rather than generic ensembling or prompt variations, weakening the causal link in the main contribution.
Authors: The referee correctly notes the absence of component-wise ablations. The current experiments compare the full multi-agent system against single models and simpler ensembles, but do not systematically disable consensus, diversity, or hierarchy while holding the model set and prompting constant. We will add these ablation experiments in the revised manuscript to quantify the incremental contribution of each design element and thereby strengthen the causal link to the human-emulation approach. revision: yes
Circularity Check
No circularity: empirical system description without derivations or self-referential fits
full rationale
The paper describes an empirical multi-agent LLM architecture for disinformation detection tasks across languages, claiming performance gains from consensus, cognitive/knowledge diversity, and hierarchy. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. Claims rest on experimental comparisons to single models rather than any self-definitional loop, fitted-input renaming, or load-bearing self-citation chain. The central mechanisms are presented as design choices inspired by human annotators, not as outputs forced by the evaluation results themselves. This is a standard empirical systems paper with independent experimental content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Consensus, diversity in cognition/knowledge, and hierarchical structure in multi-agent LLMs emulate human annotator decision-making for disinformation detection
Reference graph
Works this paper leans on
-
[1]
In: Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum
Alam, F., Barrón-Cedeño, A., Cheema, G.S., Hakimov, S., et al.: Overview of the CLEF-2023 CheckThat! lab task 1 on check-worthiness in multimodal and multigenre content. In: Working Notes of CLEF 2023—Conference and Labs of the Evaluation Forum. CLEF ’2023, Thessaloniki, Greece (2023)
2023
-
[2]
Alam, F., Shaar, S., Dalvi, F., Sajjad, H., et al.: Fighting the COVID-19 infodemic: Modeling the perspective of journalists, fact-checkers, social media platforms, pol- icy makers, and the society. In: Moens, M.F., Huang, X., Specia, L., Yih, S.W.t. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2021. pp. 611–649. Association for...
- [3]
- [4]
- [5]
-
[6]
In: Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners
Bisong, E.: Google colaboratory. In: Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners. pp. 59–
-
[7]
https://doi.org/10.1007/978-1-4842-4470-8_7
Apress, Berkeley, CA (2019). https://doi.org/10.1007/978-1-4842-4470-8_7
-
[8]
Cui, Z., Huang, T., Chiang, C.E., Du, C.: Toward veriable misinformation detec- tion: A multi-tool LLM agent framework. In: Proceedings of the 2025 International Conference on Generative Articial Intelligence for Business. pp. 179–185. ACM, New York, NY, USA (2025). https://doi.org/10.1145/3766918.3766948
-
[9]
Procedia Computer Science258, 2278– 2289 (2025)
Das, S., Kumari, R., Singh, R.K.: Detection of fake news by convolutional neural networks and recurrent neural networks. Procedia Computer Science258, 2278– 2289 (2025). https://doi.org/10.1016/j.procs.2025.04.481
-
[10]
DeepSeek-AI, Liu, A., Feng, B., Xue, B., et al.: Deepseek-v3 technical report (2025), https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Demagog.sk: Demagog.sk, https://demagog.sk, Accessed= March 07, 2026
2026
-
[12]
Fakty, A.: AFP Fakty, https://fakty.afp.com, Accessed= March 07, 2026
2026
-
[13]
Fenza, G., Furno, D., Loia, V., Trotta, P.: Multi-LLM agents architecture for claim verication (2024)
2024
-
[14]
Grattaori, A., Dubey, A., Jauhri, A., Pandey, A., et al.: The llama 3 herd of models (2024), https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
-
[16]
Imbwaga, J.L., Chittaragi, N., Koolagudi, S.G.: Fake news detection us- ing machine learning algorithms. In: Proceedings of the 2022 Four- teenth International Conference on Contemporary Computing (aug 2022). https://doi.org/10.1145/3549206.3549256
- [17]
-
[18]
In: Computational Science – ICCS 2021
Kula, S., Kozik, R., Choraś, M., Woźniak, M.: Transformer based models in fake news detection. In: Computational Science – ICCS 2021. Lecture Notes in Com- puter Science, vol. 12747, pp. 28–38. Springer International Publishing, Cham (2021). https://doi.org/10.1007/978-3-030-77970-2_3
- [19]
- [20]
- [21]
-
[22]
META: The Llama 4 herd: The beginning of a new era of natively multimodal AI in- novation, https://ai.meta.com/blog/llama-4-multimodal-intelligence/, Accessed= March 07, 2026
2026
-
[23]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.N
Modzelewski, A., Da San Martino, G., Savov, P., Wilczyńska, M.A., Wierzbicki, A.: MIPD: Exploring manipulation and intention in a novel corpus of Pol- ish disinformation. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Proceed- ings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing. pp. 19769–19785. Association for Computation...
-
[24]
In: Faggioli, G., Ferro, N., Hanbury, A., Potthast, M
Nakov, P., Barrón-Cedeño, A., Martino, G.D.S., Alam, F., et al.: Overview of the CLEF-2022 checkthat! lab task 1 on identifying relevant claims in tweets. In: Faggioli, G., Ferro, N., Hanbury, A., Potthast, M. (eds.) Proceedings of the Working Notes of CLEF 2022 - Conference and Labs of the Evaluation Forum, Bologna, Italy, September 5th - to - 8th, 2022....
2022
-
[25]
NVIDIA Corporation: NIM Platform (2023), https://developer.nvidia.com/nim
2023
-
[26]
OpenAI, Achiam, J., Adler, S., Agarwal, S., et al.: Gpt-4 technical report (2024), https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
State-of-the-Art Large Language Models: Performance in Detecting Nuanced Fake News
Repede, S.E., Brad, R.: LLaMA 3 vs. State-of-the-Art Large Language Models: Performance in Detecting Nuanced Fake News. Computers13(11), 292 (2024). https://doi.org/10.3390/computers13110292
-
[28]
bert - a comparative study of transformers language models for the detection of check-worthy claims
Sawiński, M., Węcel, K., Księżniak, E., Stróżyna, M., et al.: Openfact at checkthat! 2023: Head-to-head gpt vs. bert - a comparative study of transformers language models for the detection of check-worthy claims. CLEF 2023: Conference and Labs of the Evaluation Forum (2023),
2023
-
[29]
In: Lec- ture Notes in Networks and Systems
Srivastava, A.K., Reddy, L.A.: Detection of fake news using logistic regres- sion, decision tree, random forest, and gradient boosting algorithms. In: Lec- ture Notes in Networks and Systems. pp. 317–325. Springer (jan 2025). https://doi.org/10.1007/978-981-96-5238-9_28
-
[30]
Measurement: Sensors32, 101028 (2024)
Sudhakar, M., Kaliyamurthie, K.P.: Detection of fake news from social media using support vector machine learning algorithms. Measurement: Sensors32, 101028 (2024). https://doi.org/10.1016/j.measen.2024.101028
-
[31]
Team, K., Bai, Y., Bao, Y., Chen, G., et al.: Kimi k2: Open agentic intelligence (2025), https://arxiv.org/abs/2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Wu, Q., Bansal, G., Zhang, J., Wu, Y., et al.: Autogen: Enabling next-gen llm ap- plications via multi-agent conversation (2023), https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Yang, A., Li, A., Yang, B., Zhang, B., et al.: Qwen3 technical report (2025), https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.