EcoVideo: Entropy-Orchestrated Video Generation Paradigm in Cloud-Edge Dynamics
Pith reviewed 2026-06-30 06:13 UTC · model grok-4.3
The pith
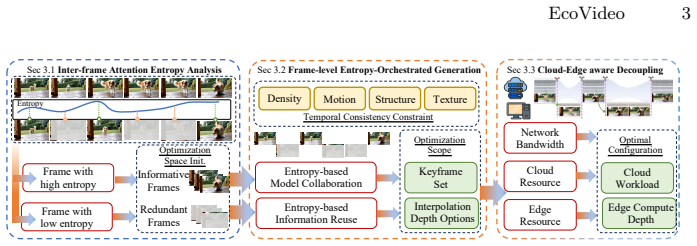
Early self-attention entropy selects which video frames receive full cloud denoising and which receive edge interpolation in DiT generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
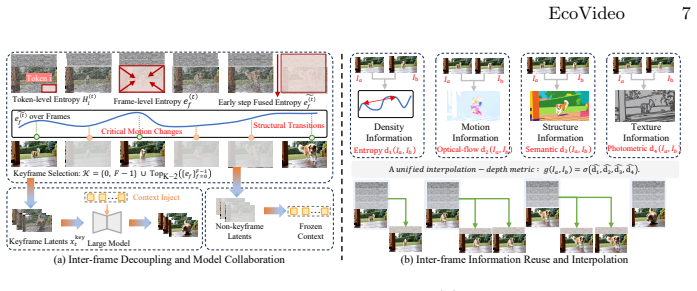
EcoVideo establishes that early-stage self-attention entropy supplies a training-free estimate of frame-wise information density, allowing sparse high-entropy keyframes to be denoised by a cloud large model while an edge lightweight model reconstructs remaining frames via motion-aware interpolation with refinement; the keyframe budget and edge refinement depth adapt in real time to bandwidth and compute availability, optimizing end-to-end latency under constraints.
What carries the argument
early-stage self-attention entropy as training-free estimate of frame-wise information density for dynamic keyframe selection
If this is right
- Only sparse high-entropy keyframes require full cloud denoising.
- Edge reconstruction uses motion-aware interpolation plus refinement for temporal stability.
- Keyframe count and refinement depth adjust automatically to measured bandwidth and compute.
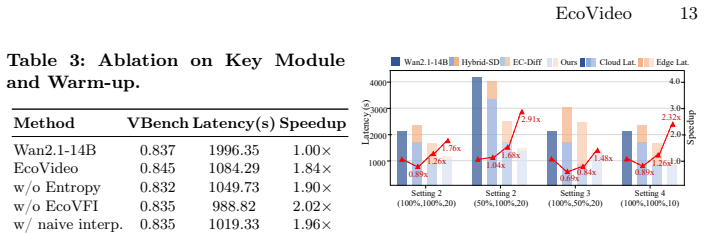
- End-to-end latency improves by up to 2.9 times in low-bandwidth, compute-limited settings.
Where Pith is reading between the lines
- The same entropy signal could guide allocation in other diffusion-based generation tasks beyond video.
- Real-world deployment would need to test how often the adaptation logic changes the split under fluctuating networks.
- Extending the edge model to handle occasional mid-entropy frames might further cut cloud load.
Load-bearing premise
Early self-attention entropy accurately identifies which frames require full denoising versus simple interpolation.
What would settle it
Measurement showing that entropy-ranked frames produce visible quality loss when the low-entropy ones are interpolated on the edge instead of denoised in the cloud.
Figures



read the original abstract
DiT video generation is latency-intensive due to iterative full-frame denoising, while prior cloud-edge methods largely rely on static inter-step decoupling and cannot leverage inter-frame similarity or adapt to system dynamics. We propose EcoVideo, an entropy-orchestrated framework for dynamic inter-frame decoupling: early-stage self-attention entropy provides a training-free estimate of frame-wise information density for frame selection; a cloud large model denoises sparse high-entropy keyframes; and an edge lightweight model reconstructs the remaining frames via motion-aware interpolation with refinement for temporal stability. EcoVideo further adapts the keyframe budget and edge refinement depth to real-time bandwidth and compute availability, optimizing end-to-end latency under constraints. Experiments on representative DiT video generators show improved quality--efficiency trade-offs and up to 2.9x end-to-end speedup in low-bandwidth, compute-limited edge settings. Code is available at https://github.com/IF-LAB-PKU/EcoVideo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EcoVideo, a framework for cloud-edge DiT video generation that uses early-stage self-attention entropy as a training-free proxy to select sparse high-entropy keyframes for full cloud denoising, while an edge lightweight model performs motion-aware interpolation and refinement on the remaining frames. The method dynamically adapts the keyframe budget and refinement depth to real-time bandwidth and compute constraints to optimize end-to-end latency. Experiments on representative DiT generators are reported to yield improved quality-efficiency trade-offs and up to 2.9x speedup in low-bandwidth edge settings, with code released.
Significance. If the entropy-based selection mechanism is shown to reliably identify frames whose full denoising provides marginal quality gains over interpolation, the approach could meaningfully advance practical deployment of iterative video diffusion models by exploiting inter-frame redundancy and system dynamics in distributed settings. The public code release supports reproducibility and extension.
major comments (2)
- [Method and Experiments] The central claim that early self-attention entropy provides a reliable training-free estimate of frame-wise information density (and thus correctly ranks frames for cloud vs. edge processing) is load-bearing for all reported gains, yet the manuscript provides no oracle comparison (e.g., selection by post-interpolation reconstruction error) or ablation against motion-magnitude or uniform baselines under identical keyframe budgets. This leaves open whether observed quality-efficiency improvements are attributable to the proposed proxy.
- [Experiments] The experimental evaluation reports up to 2.9x end-to-end speedup and improved trade-offs but does not include controls that isolate the contribution of the entropy-orchestrated selection from the overall cloud-edge architecture or from simpler dynamic allocation heuristics. Without these, the attribution of gains to the entropy mechanism cannot be verified.
minor comments (1)
- [Method] Notation for entropy computation and the precise early timestep used for attention-map extraction should be formalized with an equation to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of validating the entropy-based selection mechanism. We address each major comment below and will revise the manuscript to incorporate additional controls and ablations as outlined.
read point-by-point responses
-
Referee: [Method and Experiments] The central claim that early self-attention entropy provides a reliable training-free estimate of frame-wise information density (and thus correctly ranks frames for cloud vs. edge processing) is load-bearing for all reported gains, yet the manuscript provides no oracle comparison (e.g., selection by post-interpolation reconstruction error) or ablation against motion-magnitude or uniform baselines under identical keyframe budgets. This leaves open whether observed quality-efficiency improvements are attributable to the proposed proxy.
Authors: We agree that an oracle comparison using post-interpolation reconstruction error and ablations against motion-magnitude and uniform baselines under matched keyframe budgets would strengthen attribution of gains to the entropy proxy. The current manuscript demonstrates end-to-end improvements of the full EcoVideo framework on representative DiT models, but does not include these specific isolations. We will add the requested oracle analysis and ablations in the revision, reporting quality metrics for entropy selection versus the suggested baselines at fixed budgets. revision: yes
-
Referee: [Experiments] The experimental evaluation reports up to 2.9x end-to-end speedup and improved trade-offs but does not include controls that isolate the contribution of the entropy-orchestrated selection from the overall cloud-edge architecture or from simpler dynamic allocation heuristics. Without these, the attribution of gains to the entropy mechanism cannot be verified.
Authors: We concur that additional controls are needed to isolate the entropy-orchestrated selection from the cloud-edge architecture and from simpler dynamic heuristics. The reported results focus on overall latency and quality trade-offs under bandwidth constraints. In revision we will include targeted ablations that hold the architecture fixed while varying only the frame selection strategy, plus comparisons against non-entropy dynamic allocation methods, to verify the specific contribution of the entropy mechanism. revision: yes
Circularity Check
No circularity; procedural method with experimental results
full rationale
The paper describes a procedural framework: compute early self-attention entropy to select keyframes, denoise selected frames in cloud, interpolate others on edge, and adapt budgets dynamically. No equations, derivations, or fitted parameters are presented that reduce the reported quality or 2.9x speedup to inputs by construction. No self-citations of prior uniqueness theorems or ansatzes appear in the provided text. The central claim rests on empirical validation rather than self-referential definitions or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI Blog1(8), 1 (2024)
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., et al.: Video generation models as world simulators. OpenAI Blog1(8), 1 (2024)
2024
-
[2]
In: CVPR
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: CVPR. pp. 9650– 9660 (2021)
2021
-
[3]
In: ICLR (2026)
Chen, J., Lin, R., Le, J., Zheng, Z., Li, M., Luo, G., Chen, X.: Toprovar: Efficient visual autoregressive modeling via tri-dimensional entropy-aware semantic analysis and sparsity optimization. In: ICLR (2026)
2026
-
[4]
arXiv preprint arXiv:2505.19151 (2025)
Cheng, S., Wei, Y., Diao, L., Liu, Y., Chen, B., Huang, L., Liu, Y., Yu, W., Du, J., Lin, W., You, Y.: SRDiffusion: Accelerate video diffusion inference via sketching- rendering cooperation. arXiv preprint arXiv:2505.19151 (2025)
-
[5]
IEEE signal processing mag- azine35(1), 53–65 (2018)
Creswell, A., White, T., Dumoulin, V., Arulkumaran, K., Sengupta, B., Bharath, A.A.: Generative adversarial networks: An overview. IEEE signal processing mag- azine35(1), 53–65 (2018)
2018
-
[6]
In: AAAI
Danier, D., Zhang, F., Bull, D.: Ldmvfi: Video frame interpolation with latent diffusion models. In: AAAI. vol. 38, pp. 1472–1480 (2024)
2024
-
[7]
PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transformers Inference
Fang, J., Pan, J., Li, A., Sun, X., Wang, J.: Pipefusion: Patch-level pipeline paral- lelism for diffusion transformers inference. arXiv preprint arXiv:2405.14430 (2024) 16 Jiayu Chen et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
LTX-Video: Realtime Video Latent Diffusion
HaCohen, Y., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., et al.: Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
NeurIPS33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS33, 6840–6851 (2020)
2020
-
[10]
Jin, Y., Sun, Z., Li, N., Xu, K., Jiang, H., Zhuang, N., Huang, Q., Song, Y., Mu, Y., Lin, Z.: Pyramidal flow matching for efficient video generative modeling. arXiv preprint arXiv:2410.05954 (2024)
-
[11]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[12]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
In: CVPR
Li, M., Cai, T., Cao, J., Zhang, Q., Cai, H., Bai, J., Jia, Y., Li, K., Han, S.: Distrifusion: Distributed parallel inference for high-resolution diffusion models. In: CVPR. pp. 7183–7193 (2024)
2024
-
[14]
In: CVPR
Liu, F., Zhang, S., Wang, X., Wei, Y., Qiu, H., Zhao, Y., Zhang, Y., Ye, Q., Wan, F.: Timestep embedding tells: It’s time to cache for video diffusion model. In: CVPR. pp. 7353–7363 (2025)
2025
-
[15]
In: ICML (2026)
Luo, J., Chen, J., Wang, J., Wang, C., Zhu, H., Sun, Q., Gao, C., Chen, Z., Li, J.: Attention sparsity is input-stable: Training-free sparse attention for video genera- tion via offline sparsity profiling and online qk co-clustering. In: ICML (2026)
2026
-
[16]
arXiv preprint arXiv:2510.09012 (2025)
Ma, X., Zhao, F., Ling, P., Qiu, H., Wei, Z., Yu, H., Huang, J., Zeng, Z., Ma, L.: Towards better & faster autoregressive image generation: From the perspective of entropy. arXiv preprint arXiv:2510.09012 (2025)
-
[17]
arXiv preprint arXiv:2511.12578 (2025)
Ma, Y., Liu, C., Wang, J., Liu, J., Huang, H., Wu, Z., Zhang, C., Li, X.: Tempomas- ter: Efficient long video generation via next-frame-rate prediction. arXiv preprint arXiv:2511.12578 (2025)
-
[18]
In: ICLR
Pan, Z., Zhuang, B., Huang, D.A., Nie, W., Yu, Z., Xiao, C., Cai, J., Anandkumar, A.: T-stitch: Accelerating sampling in pre-trained diffusion models with trajectory stitching. In: ICLR. pp. 4238–4272 (2025)
2025
-
[19]
In: ICCV
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV. pp. 4195–4205 (2023)
2023
-
[20]
In: CVPR
Skorokhodov, I., Menapace, W., Siarohin, A., Tulyakov, S.: Hierarchical patch diffusion models for high-resolution video generation. In: CVPR. pp. 7569–7579 (2024)
2024
-
[21]
In: ECCV
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: ECCV. pp. 402–419 (2020)
2020
-
[22]
NeurIPS30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS30(2017)
2017
-
[23]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
In: CVPR
Wang, G., Liu, J., Li, C., Zhang, Y., Ma, J., Wei, X., Zhang, K., Chong, M., Zhang, R., Liu, Y., et al.: Cloud-device collaborative learning for multimodal large language models. In: CVPR. pp. 12646–12655 (2024)
2024
-
[25]
arXiv preprint arXiv:2504.09656 (2025) EcoVideo 17
Wang, X., Liu, J., Wang, Z., Yu, X., Wu, J., Sun, X., Su, Y., Yuille, A., Liu, Z., Barsoum, E.: Keyvid: Keyframe-aware video diffusion for audio-synchronized visual animation. arXiv preprint arXiv:2504.09656 (2025) EcoVideo 17
-
[26]
arXiv preprint arXiv:2508.12691 (2025)
Wei, Y., Diao, L., Chen, B., Cheng, S., Qian, Z., Yu, W., Xiao, N., Lin, W., Du, J.: Mixcache: Mixture-of-cache for video diffusion transformer acceleration. arXiv preprint arXiv:2508.12691 (2025)
-
[27]
Xi, H., Yang, S., Zhao, Y., Xu, C., Li, M., Li, X., Lin, Y., Cai, H., Zhang, J., Li, D., et al.: Sparse videogen: Accelerating video diffusion transformers with spatial- temporal sparsity. arXiv preprint arXiv:2502.01776 (2025)
-
[28]
Xiang, X., Chen, Y., Zhang, G., Wang, Z., Gao, Z., Xiang, Q., Shang, G., Liu, J., Huang, H., Gao, Y., et al.: Macro-from-micro planning for high-quality and parallelized autoregressive long video generation. arXiv preprint arXiv:2508.03334 (2025)
-
[29]
arXiv preprint arXiv:2507.11980 (2025)
Xie, J., Zhang, S., Zhao, Z., Wu, F., Wu, F.: Ec-diff: Fast and high-quality edge- cloud collaborative inference for diffusion models. arXiv preprint arXiv:2507.11980 (2025)
-
[30]
arXiv preprint arXiv:2408.06646 (2024)
Yan, C., Liu, S., Liu, H., Peng, X., Wang, X., Chen, F., Fu, L., Mei, X.: Hybrid sd: Edge-cloud collaborative inference for stable diffusion models. arXiv preprint arXiv:2408.06646 (2024)
-
[31]
In: 2024 IEEE 37th International System-on-Chip Conference (SOCC)
Yang, F., Wang, Z., Zhang, H., Zhu, Z., Yang, X., Dai, G., Wang, Y.: Efficient deployment of large language model across cloud-device systems. In: 2024 IEEE 37th International System-on-Chip Conference (SOCC). pp. 1–6. IEEE (2024)
2024
-
[32]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Yin, S., Wu, C., Yang, H., Wang, J., Wang, X., Ni, M., Yang, Z., Li, L., Liu, S., Yang, F., et al.: Nuwa-xl: Diffusion over diffusion for extremely long video generation. In: ACL. pp. 1309–1320 (2023)
2023
-
[34]
Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507, 2025
Zhang, P., Chen, Y., Su, R., Ding, H., Stoica, I., Liu, Z., Zhang, H.: Fast video generation with sliding tile attention. arXiv preprint arXiv:2502.04507 (2025)
-
[35]
arXiv preprint arXiv:2502.05179 (2025)
Zhang, S., Li, W., Chen, S., Ge, C., Sun, P., Zhang, Y., Jiang, Y., Yuan, Z., Peng, B., Luo, P.: Flashvideo: Flowing fidelity to detail for efficient high-resolution video generation. arXiv preprint arXiv:2502.05179 (2025)
-
[36]
In: CVPR
Zhang, Z., Chen, H., Zhao, H., Lu, G., Fu, Y., Xu, H., Wu, Z.: Eden: Enhanced diffusion for high-quality large-motion video frame interpolation. In: CVPR. pp. 2105–2115 (2025)
2025
-
[37]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y., Zhang, F., Gu, L., Zhang, Y., He, J., Zheng, W.S., et al.: Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
arXiv preprint arXiv:2410.05317 (2024) OTCache 19
Zou, C., Liu, X., Liu, T., Huang, S., Zhang, L.: Accelerating diffusion transformers with token-wise feature caching. arXiv preprint arXiv:2410.05317 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.