Why can genetic algorithms work in high-dimensional search spaces?
Pith reviewed 2026-06-30 03:06 UTC · model grok-4.3
The pith
The elitist genetic algorithm performs clipped gradient descent on the loss with anisotropic noise set by the Hessian's effective rank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
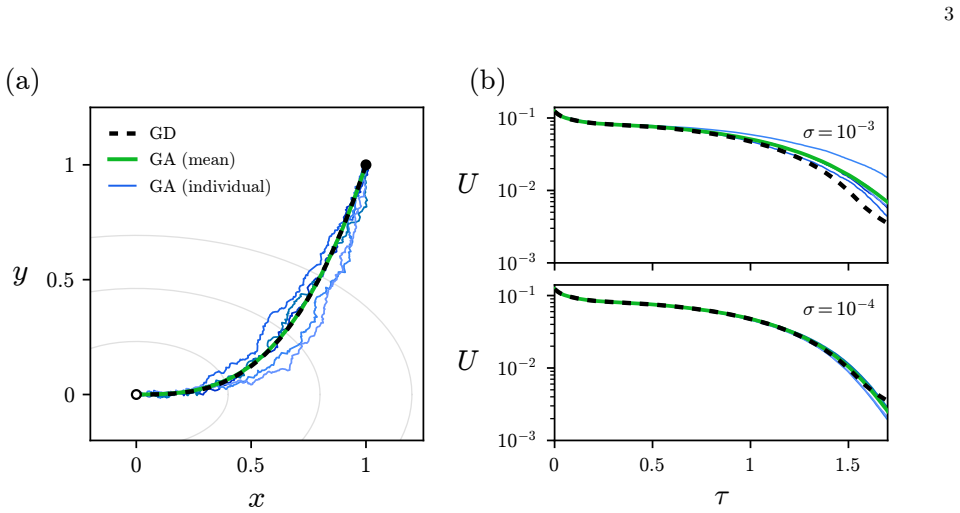
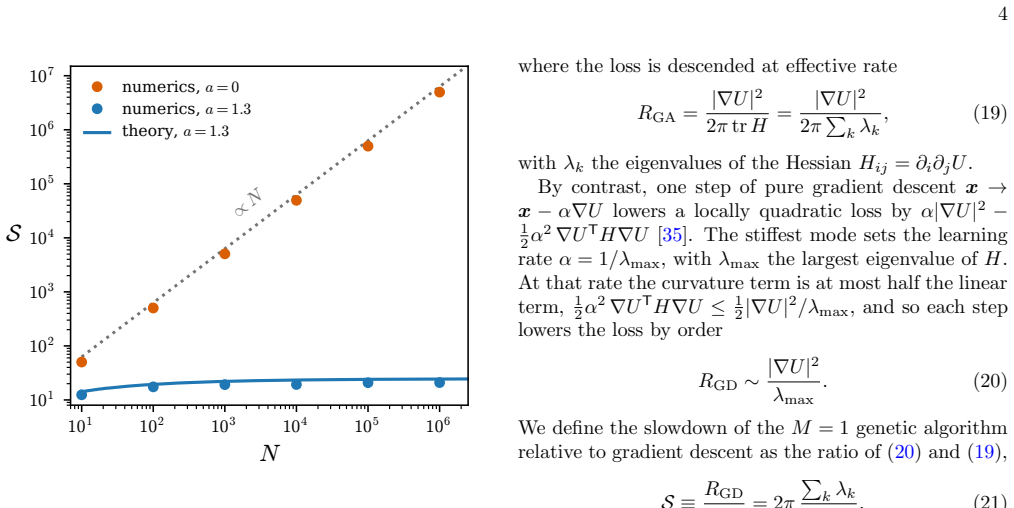
The effective dynamics of the elitist (1+M) genetic algorithm is, in the limit of small mutations, clipped gradient descent on the loss in the presence of anisotropic Gaussian white noise. In expectation the algorithm therefore follows the gradient of the loss without explicit gradient calculation. The transverse noise that slows it is controlled by the effective rank of the Hessian rather than the full parameter count, which can be far smaller than the dimension for concentrated Hessian spectra typical of neural-network loss functions.
What carries the argument
Mapping of mutation-selection steps to clipped gradient descent driven by anisotropic Gaussian white noise whose variance in each eigendirection is set by the corresponding Hessian eigenvalue.
If this is right
- The algorithm follows the loss gradient in expectation without gradient computation or averaging.
- Transverse noise strength is set by the Hessian eigenvalues rather than the ambient dimension.
- Slowdown relative to gradient descent scales with the effective rank of the Hessian.
- Concentrated Hessian spectra therefore permit scaling to high-dimensional search spaces.
Where Pith is reading between the lines
- The same noise-controlled mechanism may apply to other selection-based optimizers when mutations remain small.
- One could measure the effective rank of Hessians in non-neural loss landscapes to predict whether genetic algorithms will scale there.
- Finite-mutation corrections could be derived by expanding beyond the Gaussian-white-noise limit.
Load-bearing premise
The analysis requires mutations to be small enough that the resulting fluctuations can be treated as anisotropic Gaussian white noise whose transverse strength is fully determined by the Hessian spectrum.
What would settle it
Numerical trajectories of the (1+M) algorithm on a quadratic loss with known Hessian should match the statistics of clipped gradient descent with the predicted anisotropic noise; mismatch in the transverse diffusion rates would falsify the claimed equivalence.
Figures
read the original abstract
We show that the effective dynamics of the elitist $(1+M)$ genetic algorithm is, in the limit of small mutations, clipped gradient descent on the loss in the presence of anisotropic Gaussian white noise. In expectation, therefore, a simple mutation-selection genetic algorithm follows the gradient of the loss, without explicit calculation of gradients and without averaging over loss evaluations. The genetic algorithm is slower than gradient descent because of the noise that acts in directions transverse to the gradient. However, this slowdown is controlled not by the number of parameters of the search space but by the effective rank of the Hessian of the loss function. For the concentrated Hessian spectra observed in neural-network loss functions the effective rank can be far smaller than the number of parameters, which may explain why genetic algorithms can scale to large search spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the effective dynamics of the elitist (1+M) genetic algorithm, in the small-mutation limit, is equivalent to clipped gradient descent on the loss in the presence of anisotropic Gaussian white noise. In expectation the algorithm therefore follows the gradient without explicit gradient computation or averaging over loss evaluations. The transverse noise slows convergence relative to gradient descent, but the slowdown is governed by the effective rank of the Hessian rather than the nominal parameter count; because neural-network Hessians often have concentrated spectra, the effective rank can be far smaller than the dimension, which is offered as an explanation for why genetic algorithms scale to large search spaces.
Significance. If the claimed equivalence is rigorously established, the result supplies a concrete stochastic-dynamics bridge between evolutionary algorithms and first-order methods, and it supplies a falsifiable mechanism (effective-rank control of transverse diffusion) for the observed scaling of GAs on high-dimensional, low-effective-rank landscapes. The absence of fitted parameters and the derivation from the mutation-selection rule are strengths that would make the explanation more compelling than purely phenomenological accounts.
major comments (2)
- [Derivation of the continuous limit (presumably §3–4)] The load-bearing step is the derivation that the small-mutation mutation-selection process yields, at leading order, anisotropic Gaussian white noise whose transverse covariance is set by the Hessian spectrum. The manuscript must exhibit the explicit expansion of the update rule (mutation kernel plus elitist selection) and the resulting Fokker-Planck or Itô equation; without this calculation the asserted equivalence to clipped gradient descent plus the stated noise covariance cannot be verified.
- [Abstract] The abstract states the central equivalence but supplies neither the intermediate equations nor a proof outline. Even if the full text contains the derivation, the absence of key steps makes it impossible to assess whether the continuous approximation and the precise form of the noise covariance follow directly from the GA update rule.
minor comments (2)
- [Notation and definitions] Define 'clipped' gradient descent explicitly and show how the clipping emerges from the elitist (1+M) selection operator.
- [Introduction or related-work section] Add a short paragraph contrasting the present noise model with earlier continuous approximations of evolutionary algorithms (e.g., those based on the diffusion approximation or on the Price equation).
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the potential significance of the claimed equivalence. We address each major comment below and will revise the manuscript to improve the explicitness of the derivation and the abstract.
read point-by-point responses
-
Referee: [Derivation of the continuous limit (presumably §3–4)] The load-bearing step is the derivation that the small-mutation mutation-selection process yields, at leading order, anisotropic Gaussian white noise whose transverse covariance is set by the Hessian spectrum. The manuscript must exhibit the explicit expansion of the update rule (mutation kernel plus elitist selection) and the resulting Fokker-Planck or Itô equation; without this calculation the asserted equivalence to clipped gradient descent plus the stated noise covariance cannot be verified.
Authors: We agree that the explicit expansion is essential for verification. Sections 3–4 derive the continuous limit from the mutation kernel and elitist selection, but the presentation will be expanded in revision to display the full perturbative expansion of the update rule, the resulting Fokker-Planck equation, and the conversion to the Itô SDE, with the transverse covariance explicitly tied to the Hessian spectrum at leading order. revision: yes
-
Referee: [Abstract] The abstract states the central equivalence but supplies neither the intermediate equations nor a proof outline. Even if the full text contains the derivation, the absence of key steps makes it impossible to assess whether the continuous approximation and the precise form of the noise covariance follow directly from the GA update rule.
Authors: We accept that the abstract should supply a concise proof outline. The revised abstract will indicate the key intermediate steps: the small-mutation expansion of the (1+M) elitist update, the emergence of the Fokker-Planck/Itô description, and the identification of the anisotropic noise covariance from the Hessian. revision: yes
Circularity Check
No significant circularity; derivation presented as direct limit analysis from GA update rule
full rationale
The paper presents its central result as a derivation of effective dynamics from the elitist (1+M) GA update rule taken in the small-mutation limit, with fluctuations modeled as anisotropic Gaussian white noise controlled by the Hessian. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described chain. The result is framed as following from the update rule itself rather than reducing to a prior fit or self-citation by construction, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Metropolis, A
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, and E. Teller, The Journal of Chemical Physics21, 1087 (1953)
1953
-
[2]
W. K. Hastings, Biometrika57, 97 (1970)
1970
-
[3]
J. H. Holland, Scientific american267, 66 (1992)
1992
-
[4]
D. B. Fogel and L. C. Stayton, BioSystems32, 171 (1994)
1994
-
[5]
D. J. Montana and L. Davis, inIJCAI, Vol. 89 (1989) pp. 762–767
1989
-
[6]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever, arXiv preprint arXiv:1703.03864 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
F. P. Such, V. Madhavan, E. Conti, J. Lehman, K. O. Stanley, and J. Clune, arXiv preprint arXiv:1712.06567 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
D. E. Goldberg,Genetic Algorithms in Search, Optimiza- tion, and Machine Learning(Addison-Wesley, Reading, MA, 1989)
1989
-
[9]
Mitchell,An Introduction to Genetic Algorithms (MIT Press, Cambridge, MA, 1996)
M. Mitchell,An Introduction to Genetic Algorithms (MIT Press, Cambridge, MA, 1996)
1996
-
[10]
Frenkel and B
D. Frenkel and B. Smit,Understanding molecular simu- lation: from algorithms to applications, Vol. 1 (Academic Press, 2001)
2001
-
[11]
Rechenberg,Evolutionsstrategie: Optimierung technis- cher Systeme nach Prinzipien der biologischen Evolution (Frommann–Holzboog, Stuttgart, 1973)
I. Rechenberg,Evolutionsstrategie: Optimierung technis- cher Systeme nach Prinzipien der biologischen Evolution (Frommann–Holzboog, Stuttgart, 1973)
1973
-
[12]
Beyer,The Theory of Evolution Strategies (Springer, Berlin, 2001)
H.-G. Beyer,The Theory of Evolution Strategies (Springer, Berlin, 2001)
2001
-
[13]
Nesterov and V
Y. Nesterov and V. Spokoiny, Found. Comput. Math.17, 527 (2017)
2017
-
[14]
Whitelam, V
S. Whitelam, V. Selin, I. Benlolo, C. Casert, and I. Tam- blyn, Mach. Learn.: Sci. Technol.3, 045026 (2022)
2022
-
[15]
Evolution strategies at the hyperscale.arXiv preprint arXiv:2511.16652,
B. Sarkar, M. Fellows, J. A. Duque, J. N. Foerster,et al., arXiv:2511.16652 (2025)
- [16]
-
[17]
[11, 12]
This is the (1 +M)evolution strategyof Refs. [11, 12]
-
[18]
Wierstra, T
D. Wierstra, T. Schaul, T. Glasmachers, Y. Sun, J. Pe- ters, and J. Schmidhuber, J. Mach. Learn. Res.15, 949 (2014)
2014
-
[19]
Kikuchi, M
K. Kikuchi, M. Yoshida, T. Maekawa, and H. Watanabe, Chemical Physics Letters185, 335 (1991)
1991
-
[20]
Kikuchi, M
K. Kikuchi, M. Yoshida, T. Maekawa, and H. Watanabe, Chemical Physics Letters196, 57 (1992)
1992
-
[21]
Mitchell, J
M. Mitchell, J. H. Holland, and S. Forrest, inAdvances in Neural Information Processing Systems 6(Morgan Kauf- mann, San Francisco, 1993) pp. 51–58
1993
-
[22]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
L. Sagun, U. Evci, V. U. G¨ uney, Y. Dauphin, and L. Bot- tou, arXiv:1706.04454 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
The Full Spectrum of Deepnet Hessians at Scale: Dynamics with SGD Training and Sample Size
V. Papyan, arXiv:1811.07062 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Ghorbani, S
B. Ghorbani, S. Krishnan, and Y. Xiao, inProceedings of the 36th International Conference on Machine Learning (ICML)(2019) pp. 2232–2241
2019
- [25]
-
[26]
Q.-Y. Tang, Y. Gu, Y. Cai, M. Sun, P. Li, Z. Xun, and Z. Xie, inProceedings of the 42nd International Confer- ence on Machine Learning, Vol. 267 (PMLR, 2025) pp. 58805–58831
2025
-
[27]
Schmidhuber, Neural networks61, 85 (2015)
J. Schmidhuber, Neural networks61, 85 (2015)
2015
-
[28]
LeCun, Y
Y. LeCun, Y. Bengio, and G. Hinton, Nature521, 436 (2015)
2015
-
[29]
Bahri, J
Y. Bahri, J. Kadmon, J. Pennington, S. S. Schoenholz, J. Sohl-Dickstein, and S. Ganguli, Annual Review of Condensed Matter Physics (2020)
2020
-
[30]
Sabattini, A
L. Sabattini, A. Coriolano, C. Casert, S. Forti, E. S. Barnard, F. Beltram, M. Pontil, S. Whitelam, C. Coletti, and A. Rossi, Communications Physics8, 180 (2025)
2025
-
[31]
Risken,The Fokker–Planck Equation: Methods of So- lution and Applications, 2nd ed
H. Risken,The Fokker–Planck Equation: Methods of So- lution and Applications, 2nd ed. (Springer, Berlin, 1989)
1989
-
[32]
Pascanu, T
R. Pascanu, T. Mikolov, and Y. Bengio, inInternational conference on machine learning(PMLR, 2013) pp. 1310– 1318
2013
-
[33]
Whitelam, V
S. Whitelam, V. Selin, S.-W. Park, and I. Tamblyn, Nature Communications12, 6317 (2021)
2021
-
[34]
Gardiner,Stochastic methods: A handbook for the nat- ural and social sciences(Springer, Heidelberg, Germany, 2009)
C. Gardiner,Stochastic methods: A handbook for the nat- ural and social sciences(Springer, Heidelberg, Germany, 2009)
2009
-
[35]
Boyd and L
S. Boyd and L. Vandenberghe,Convex Optimization (Cambridge University Press, Cambridge, 2004)
2004
-
[36]
Beyer and A
H.-G. Beyer and A. Melkozerov, IEEE Transactions on Evolutionary Computation18, 764 (2014)
2014
- [37]
-
[38]
Glasmachers, T
T. Glasmachers, T. Schaul, Y. Sun, D. Wierstra, and J. Schmidhuber, inProceedings of the 12th Annual Conference on Genetic and Evolutionary Computation (GECCO)(2010) pp. 393–400
2010
-
[39]
Ollivier, L
Y. Ollivier, L. Arnold, A. Auger, and N. Hansen, J. Mach. Learn. Res.18, 1 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.