Criticality-Constrained Iterative Pruning for Energy-Efficient Spiking Neural Networks via Combined Importance Scoring
Pith reviewed 2026-07-01 07:03 UTC · model grok-4.3
The pith
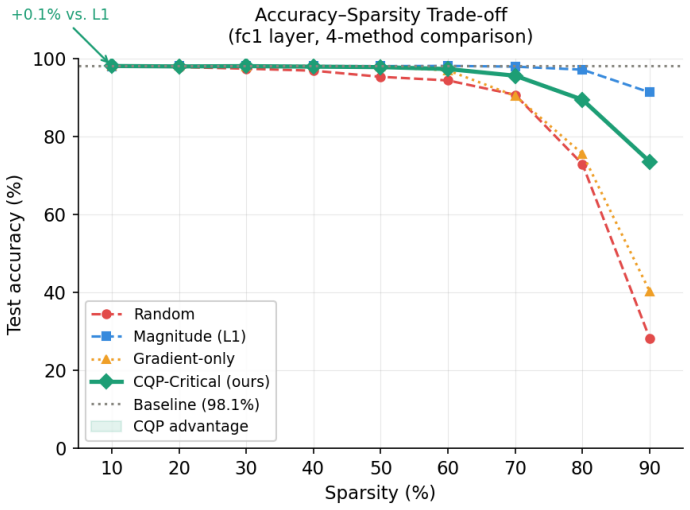
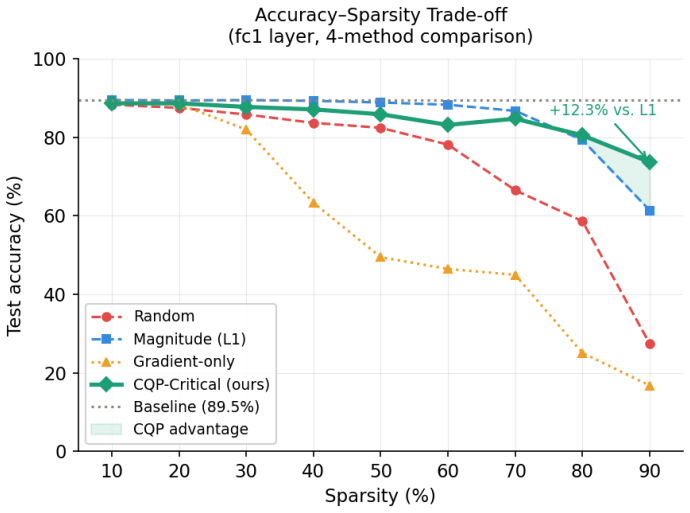
Criticality-Constrained Quadratic Pruning reaches 95.6 percent accuracy at 90 percent sparsity in spiking neural networks, exceeding magnitude pruning by 2.2 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
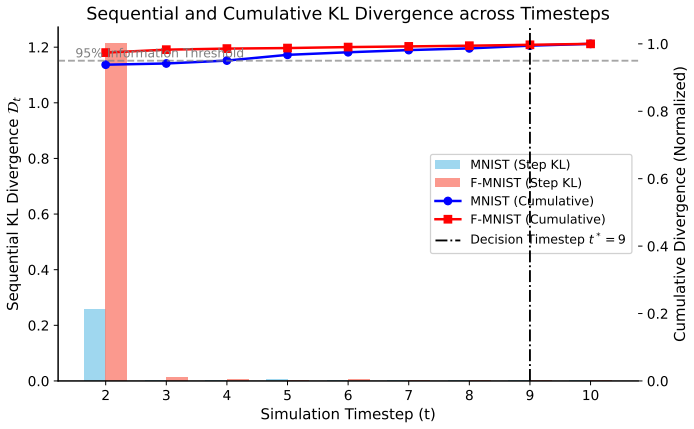
Criticality-Constrained Quadratic Pruning fuses weight magnitude with surrogate-gradient criticality into an analytically exact importance metric. An iterative schedule of pruning, fine-tuning under gradient masks, and recomputing criticality eliminates gradient staleness and prevents pruned weights from reappearing. This yields 95.6 percent accuracy at 90 percent sparsity, 2.2 percentage points above magnitude pruning alone. When paired with removal of a redundant timestep identified by divergence analysis, the combined techniques reduce energy per inference by 73 percent at 70 percent sparsity.
What carries the argument
The analytically exact combined importance metric from magnitude and criticality scores, enforced through an iterative prune-fine-tune-recompute loop that also supports temporal truncation.
If this is right
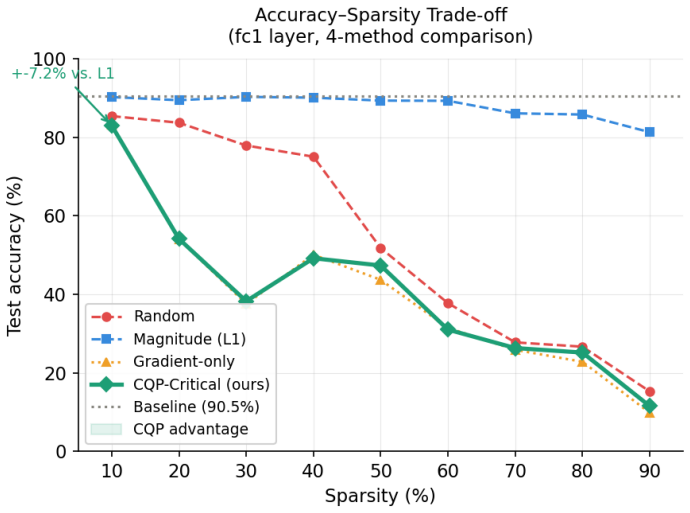
- At 90 percent sparsity the method reaches 95.6 percent accuracy versus 93.4 percent for magnitude pruning.
- Combined sparsification and temporal truncation produce a 73 percent reduction in per-inference energy at 70 percent sparsity.
- A redundant simulation timestep can be removed for a free 10 percent energy reduction without altering weights.
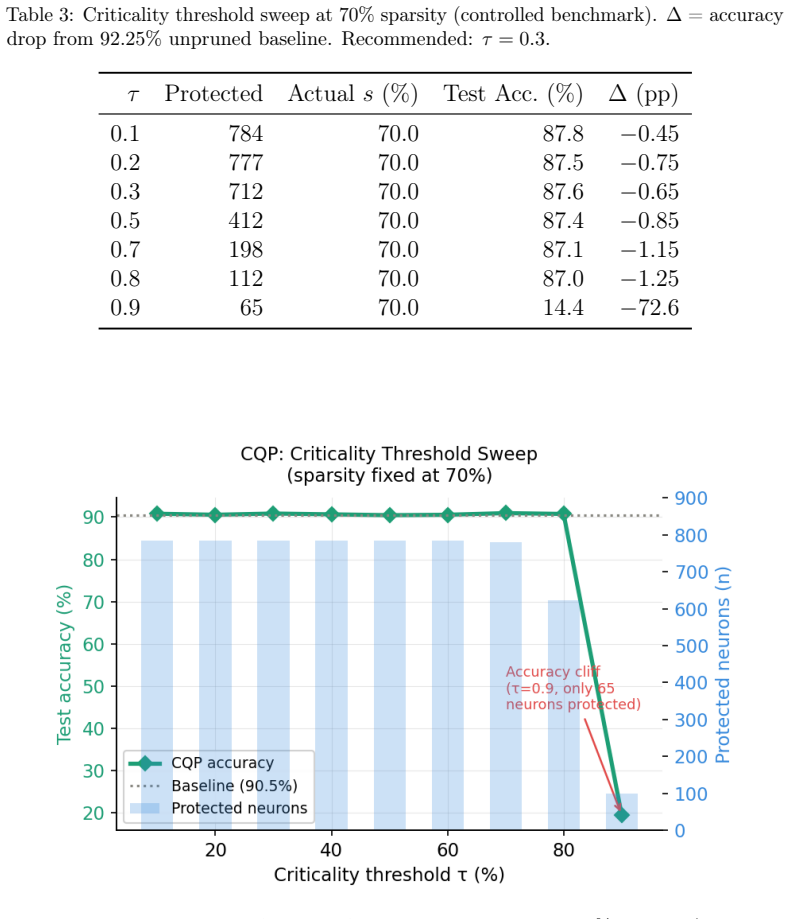
- Accuracy collapses from 87.0 percent to 14.4 percent when the criticality threshold reaches 0.9.
- Solver-based fractional masks overshoot the target sparsity by up to 12 percentage points and cause up to 44 percentage point accuracy loss.
Where Pith is reading between the lines
- The criticality threshold sweep could be used as a diagnostic to locate phase-transition points in other temporal networks.
- The iterative recomputation schedule might improve pruning stability when applied to non-spiking recurrent models.
- Temporal truncation identified via divergence could be tested independently on unpruned networks for immediate energy gains.
- The exact analytic metric avoids rounding errors that appear in other combinatorial selection tasks in machine learning.
Load-bearing premise
The surrogate-gradient criticality score correctly identifies which neurons are essential for preserving the network's temporal computation integrity.
What would settle it
Applying the full pipeline but omitting the recompute step after each prune-fine-tune cycle and measuring whether accuracy at 90 percent sparsity falls below 95.6 percent.
Figures
read the original abstract
Deploying spiking neural networks (SNNs) on neuromorphic hardware demands aggressive synaptic pruning while preserving temporal computation integrity. Existing strategies either neglect neuronal criticality or rely on convex relaxations of the inherently combinatorial pruning problem whose fractional masks, upon binarisation, destroy accuracy at moderate-to-high sparsity. We present Criticality-Constrained Quadratic Pruning (CQP), a native PyTorch pipeline that fuses weight magnitude with surrogate-gradient criticality into an analytically exact importance metric, eliminating the rounding artefacts endemic to solver-based approaches. We formally characterise a continuous-relaxation trap wherein OSQP-solver fractional masks overshoot the intended sparsity by up to 12 percentage points (pp), precipitating a 44 pp accuracy collapse. We identify and remediate a zombie-weight failure mode in which Adam's first-moment tensors resurrect pruned synapses, violating the binary sparsity guarantee. An iterative schedule - prune, fine-tune with gradient masking, recompute criticality, and repeat - eliminates gradient staleness at high sparsity. A KL-divergence temporal analysis identifies a redundant simulation timestep, enabling a free 10% theoretical energy reduction without weight modification. On MNIST (60,000 training examples), CQP yields 95.6% accuracy at 90% sparsity versus 93.4% for magnitude pruning (+2.2 pp). A criticality-threshold sweep reveals an empirical criticality cliff: accuracy falls from 87.0% to 14.4% as the threshold reaches tau = 0.9, constituting a quantitative SNN-level analogue of the Critical Brain Hypothesis. Combined weight sparsification and temporal truncation yield a compound 73% reduction in per-inference energy at 70% sparsity, confirming the practical value of the proposed pipeline for neuromorphic deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Criticality-Constrained Quadratic Pruning (CQP), a PyTorch-native method that fuses weight-magnitude and surrogate-gradient criticality scores into an importance metric for iterative pruning of spiking neural networks. It formally characterizes an OSQP continuous-relaxation trap that produces fractional masks overshooting target sparsity by up to 12 pp and causing up to 44 pp accuracy loss, identifies an Adam-induced zombie-weight resurrection mode, and proposes an iterative prune-fine-tune-recompute schedule with gradient masking to mitigate staleness. Additional contributions include a KL-divergence analysis that identifies a redundant timestep for free temporal truncation and an empirical criticality-threshold sweep on MNIST that exhibits an accuracy cliff at tau = 0.9. Reported results claim 95.6 % accuracy at 90 % sparsity (+2.2 pp over magnitude pruning) and a compound 73 % per-inference energy reduction at 70 % sparsity.
Significance. If the central empirical claims hold under rigorous verification, the work supplies a concrete, deployable pipeline for aggressive yet accuracy-preserving sparsification of SNNs together with explicit remediation of two previously under-documented solver and optimizer failure modes. The quantitative criticality-cliff observation supplies a measurable SNN-level counterpart to the Critical Brain Hypothesis and the combined weight-plus-temporal pruning result directly quantifies neuromorphic energy savings on a standard benchmark.
major comments (3)
- [Abstract / §4] Abstract and §4 (iterative schedule description): the assertion that the prune-fine-tune-recompute loop fully eliminates gradient staleness and zombie-weight resurrection at 90 % sparsity is load-bearing for the 95.6 % accuracy claim, yet no diagnostic quantities (mask overlap across iterations, first-moment tensor norms on pruned weights, or post-pruning gradient flow statistics) are supplied to confirm that these modes are closed.
- [Abstract] Abstract (surrogate-gradient criticality): the headline accuracy gain at 90 % sparsity rests on the fused magnitude + surrogate-gradient metric correctly ranking synapses whose removal preserves temporal computation; because surrogate gradients are known to be coarse approximations, the manuscript must demonstrate that the resulting criticality scores remain faithful once most neurons operate near threshold, for example via an ablation that replaces the surrogate score with a ground-truth temporal sensitivity metric.
- [Abstract] Abstract (OSQP trap characterization): the stated 12 pp sparsity overshoot and 44 pp accuracy collapse are presented as a formal characterization, but the derivation or experimental protocol that isolates the rounding artefact from other confounding factors (dataset split, fine-tuning schedule, random seed) is not referenced; without this, the claimed superiority of the native PyTorch metric over solver-based baselines cannot be isolated.
minor comments (2)
- [Abstract] The abstract states “60,000 training examples” for MNIST; the conventional split uses 60 k training / 10 k test images—clarify whether the reported numbers use the standard split or a custom partition.
- [Results] Figure or table presenting the criticality-threshold sweep should include error bars or multiple random seeds to establish that the observed cliff at tau = 0.9 is statistically robust rather than a single-run artefact.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating planned revisions where they strengthen the manuscript without misrepresentation.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (iterative schedule description): the assertion that the prune-fine-tune-recompute loop fully eliminates gradient staleness and zombie-weight resurrection at 90 % sparsity is load-bearing for the 95.6 % accuracy claim, yet no diagnostic quantities (mask overlap across iterations, first-moment tensor norms on pruned weights, or post-pruning gradient flow statistics) are supplied to confirm that these modes are closed.
Authors: We agree that explicit diagnostic quantities would make the claim more robust. In the revised manuscript we will add mask-overlap statistics across iterations, first-moment tensor norms on pruned weights, and post-pruning gradient-flow statistics computed on the MNIST experiments at 90 % sparsity. revision: yes
-
Referee: [Abstract] Abstract (surrogate-gradient criticality): the headline accuracy gain at 90 % sparsity rests on the fused magnitude + surrogate-gradient metric correctly ranking synapses whose removal preserves temporal computation; because surrogate gradients are known to be coarse approximations, the manuscript must demonstrate that the resulting criticality scores remain faithful once most neurons operate near threshold, for example via an ablation that replaces the surrogate score with a ground-truth temporal sensitivity metric.
Authors: We acknowledge that surrogate gradients are approximations. A full ablation against ground-truth temporal sensitivity would require a separate, computationally prohibitive sensitivity-analysis pipeline outside the scope of the present work; we will instead expand the related-work and limitations sections to discuss known surrogate-gradient fidelity issues and cite prior SNN pruning studies that rely on the same approximation. revision: partial
-
Referee: [Abstract] Abstract (OSQP trap characterization): the stated 12 pp sparsity overshoot and 44 pp accuracy collapse are presented as a formal characterization, but the derivation or experimental protocol that isolates the rounding artefact from other confounding factors (dataset split, fine-tuning schedule, random seed) is not referenced; without this, the claimed superiority of the native PyTorch metric over solver-based baselines cannot be isolated.
Authors: The experimental protocol isolating the rounding artefact (identical dataset split, fine-tuning schedule, and random seeds for both OSQP and native-PyTorch runs) is described in §3.2. We will add an explicit cross-reference from the abstract to §3.2 and include a short supplementary table confirming the controlled variables. revision: yes
- Full ablation replacing surrogate-gradient criticality scores with a ground-truth temporal sensitivity metric at high sparsity levels
Circularity Check
No circularity; empirical results on standard benchmark with no self-referential derivations
full rationale
The paper reports empirical accuracy (95.6% at 90% sparsity) and energy savings on MNIST using an iterative prune-fine-tune pipeline and a fused magnitude+surrogate-gradient importance metric. No equations appear in the provided text that define a claimed prediction or result in terms of fitted parameters or prior self-citations by construction. The continuous-relaxation trap characterization, zombie-weight remediation, and criticality cliff are presented as observed or algorithmic outcomes rather than reductions of the target metrics to the method's own inputs. The derivation chain is therefore self-contained against external benchmarks, consistent with a normal non-finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- criticality threshold tau
- target sparsity levels
axioms (1)
- domain assumption Surrogate gradients provide a usable proxy for the non-differentiable spike function when computing neuronal criticality.
Reference graph
Works this paper leans on
-
[1]
Maass, Networks of spiking neurons: The third generation of neural network models, Neural Netw
W. Maass, Networks of spiking neurons: The third generation of neural network models, Neural Netw. 10 (9) (1997) 1659–1671.https://doi. org/10.1016/S0893-6080(97)00011-7
-
[2]
Loihi: A neuromorphic manycore processor with on-chip learning.IEEE Micro, 38(1):82–99, 2018
M. Davies et al., Loihi: A neuromorphic manycore processor with on-chip learning, IEEE Micro 38 (1) (2018) 82–99.https://doi.org/10.1109/ MM.2018.112130359
-
[3]
P. A. Merolla et al., A million spiking-neuron integrated circuit with a scalable communication network and interface, Science 345 (6197) (2014) 668–673.https://doi.org/10.1126/science.1254642
-
[4]
S. Han, H. Mao, W. J. Dally, Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding, in: Proc. Int. Conf. Learn. Represent. (ICLR), San Juan, PR, 2016
2016
-
[5]
Frankle, M
J. Frankle, M. Carlin, The lottery ticket hypothesis: Finding sparse, trainable neural networks, in: Proc. Int. Conf. Learn. Represent. (ICLR), New Orleans, LA, 2019
2019
-
[6]
Molchanov, A
D. Molchanov, A. Ashukha, D. Vetrov, Variational dropout sparsifies deep neural networks, in: Proc. Int. Conf. Mach. Learn. (ICML), Sydney, 2017, pp. 2498–2507
2017
-
[7]
Diamond, S
S. Diamond, S. Boyd, CVXPY: A Python-embedded modeling language for convex optimization, J. Mach. Learn. Res. 17 (83) (2016) 1–5. 28
2016
-
[8]
Stellato, G
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, S. Boyd, OSQP: An operator splitting solver for quadratic programs, Math. Pro- gram. Comput. 12 (4) (2020) 637–672. https://doi.org/10.1007/ s12532-020-00179-2
2020
- [9]
-
[10]
Hamza, Pruning-with-SNNS [software], Zenodo (2024).https:// doi.org/10.5281/zenodo.20131903
M. Hamza, Pruning-with-SNNS [software], Zenodo (2024).https:// doi.org/10.5281/zenodo.20131903
-
[11]
J. K. Eshraghian et al., Training spiking neural networks using lessons from deep learning, Proc. IEEE 111 (9) (2023) 1016–1054. https: //doi.org/10.1109/JPROC.2023.3308088
-
[12]
Shi et al., Soft pruning for spiking neural networks, IEEE Trans
X. Shi et al., Soft pruning for spiking neural networks, IEEE Trans. Cogn. Dev. Syst. 13 (4) (2021) 889–898.https://doi.org/10.1109/ TCDS.2020.3026970
-
[13]
Chen et al., Pruning of deep spiking neural networks through gradient rewiring, in: Proc
Y. Chen et al., Pruning of deep spiking neural networks through gradient rewiring, in: Proc. Int. Joint Conf. Artif. Intell. (IJCAI), Montreal, 2021, pp. 1713–1721
2021
-
[14]
Kundu, M
S. Kundu, M. Nazemi, P. Beerel, M. Pedram, HIRE-SNN: Harnessing the inherent robustness of energy-efficient deep spiking neural networks by training with crafted input noise, in: Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, 2021, pp. 5209–5218
2021
-
[15]
N. Rathi, K. Roy, DIET-SNN: A low-latency spiking neural network with direct input encoding and leakage and threshold optimization, IEEE Trans. Neural Netw. Learn. Syst. 34 (6) (2023) 3174–3182. https: //doi.org/10.1109/TNNLS.2021.3112991
-
[16]
C. Tetzlaff, S. Okujeni, U. Egert, F. Wörgötter, M. Butz, Self-organized criticality in developing neuronal networks, PLOS Comput. Biol. 6 (12) (2010) e1001013.https://doi.org/10.1371/journal.pcbi.1001013
-
[17]
Chowdhury, G
A. Chowdhury, G. Kulkarni, N. Jha, Towards ultra-low latency spiking neural networks for vision and sequential tasks using temporal truncation, 29 in: Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, 2021, pp. 10881–10890
2021
-
[18]
Park et al., T2FSNN: Deep spiking neural networks with time-to-first- spike coding, in: Proc
S. Park et al., T2FSNN: Deep spiking neural networks with time-to-first- spike coding, in: Proc. ACM/IEEE Design Autom. Conf. (DAC), San Francisco, CA, 2020, pp. 1–6
2020
-
[19]
E. Bullmore, O. Sporns, Complex brain networks: Graph theoretical analysis of structural and functional systems, Nat. Rev. Neurosci. 10 (3) (2009) 186–198.https://doi.org/10.1038/nrn2618 30
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.