Mind the Residual Gap: Probabilistic Downscaling under Real-World Bias
Pith reviewed 2026-07-01 06:30 UTC · model grok-4.3
The pith
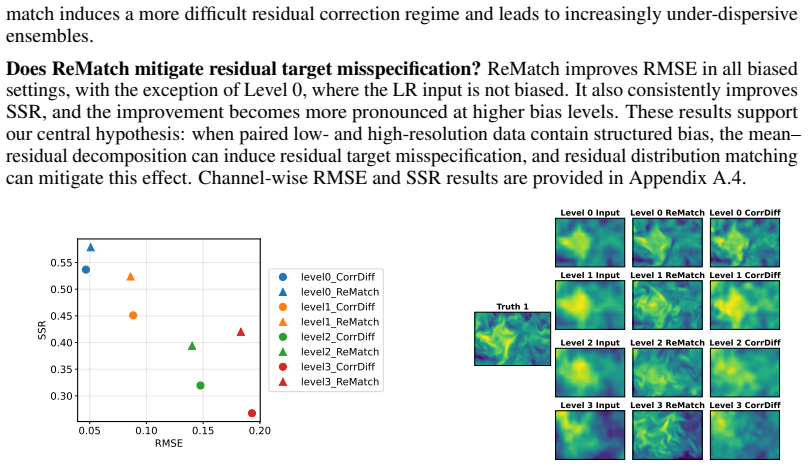
Residual target misspecification arises because training residuals differ systematically from those needed at test time due to downscaling bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Residual target misspecification occurs because the residual distribution induced during training differs systematically from the one required at test time due to downscaling bias. ReMatch aligns the training residual distribution toward the test-time regime via optimal transport in a low-dimensional PCA space. This preserves the statistical benefits of the mean-residual framework while reducing the train-test mismatch in the residual targets seen by the stochastic generator.
What carries the argument
ReMatch, which aligns the training residual distribution to the test-time regime by optimal transport performed inside a low-dimensional PCA space.
If this is right
- Reduces under-dispersion in the generated ensembles on both synthetic and real data.
- Improves calibration metrics SSR and CRPS relative to the unaligned mean-residual baseline.
- Outperforms standard mean-residual variants and state-of-the-art super-resolution models on the HRRR-ERA5 wind task.
- Maintains the two-stage decomposition while only modifying the residual generator's training distribution.
Where Pith is reading between the lines
- The same residual-gap mechanism may appear in other multiscale physical systems whenever a coarse-to-fine bias is present.
- If the chosen PCA subspace omits physically important modes, the transport step could still leave residual error on variables with strong small-scale structure.
- Combining ReMatch with non-stationary bias models could extend the approach to long climate-projection horizons.
Load-bearing premise
That optimal transport alignment performed in a low-dimensional PCA space will close the train-test residual gap without discarding critical high-frequency variability or introducing new biases that degrade ensemble quality.
What would settle it
Apply ReMatch to the synthetic benchmark at increasing bias levels and measure whether the transported residuals match the test-time distribution while SSR and CRPS improve; if calibration metrics stay unchanged or worsen, the claim is false.
Figures


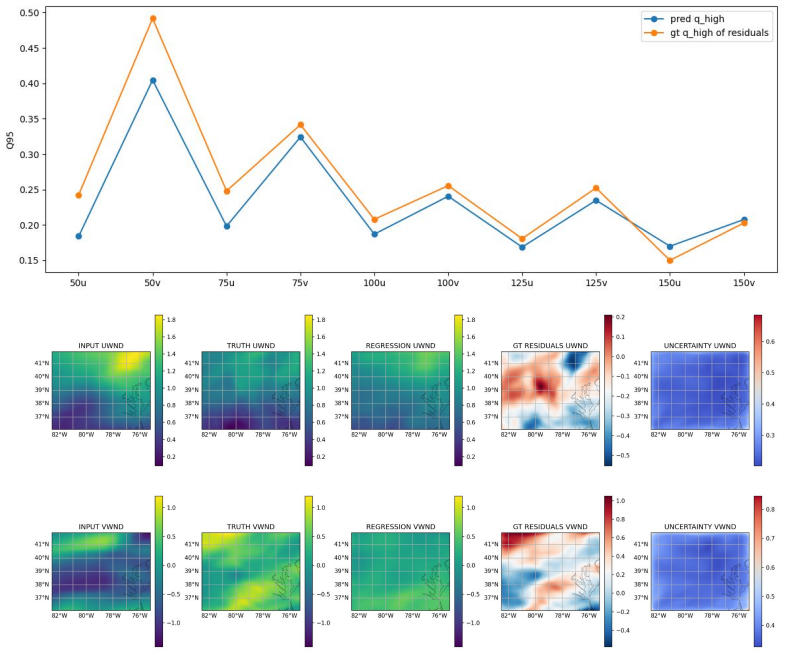
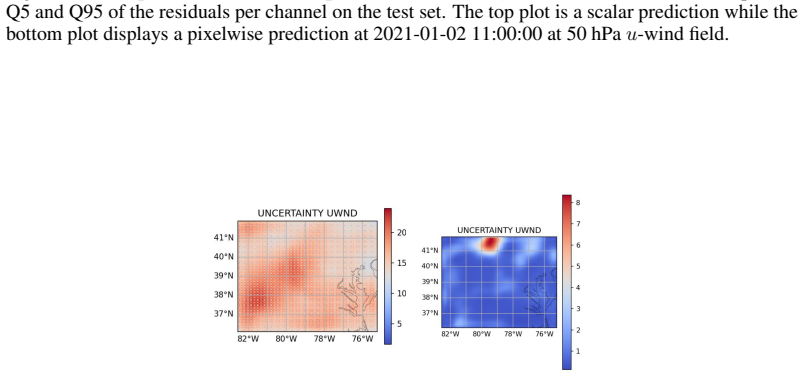
read the original abstract
Probabilistic downscaling is the task of modeling the conditional distribution of high-resolution fields given coarse inputs, and is a central challenge to atmospheric science, climate modeling, and other multiscale physical systems. A widely used paradigm decomposes the problem into a deterministic mean predictor followed by a stochastic residual generator. While effective in idealized settings, this mean--residual approach frequently produces biased and under-dispersive ensembles in real-world applications. Is this merely generic predictive uncertainty miscalibration? We show that the root cause is more fundamental: residual target misspecification, the residual distribution induced during training differs systematically from the one required at test time due to downscaling bias. To close this gap, we introduce ReMatch (Residual Distribution Matching). ReMatch aligns the training residual distribution toward the test-time regime via optimal transport in a low-dimensional PCA space. This preserves the statistical benefits of the mean--residual framework while reducing the train--test mismatch in the residual targets seen by the stochastic generator. On a controlled synthetic benchmark with varying bias levels and a real-world HRRR--ERA5 wind field downscaling task, ReMatch substantially reduces under-dispersion, improves calibration (SSR and CRPS), and outperforms strong baselines, including the standard mean--residual model and its variants, as well as state-of-the-art super-resolution models. Our code is available at https://github.com/sdean-group/ReMatch.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the mean-residual decomposition in probabilistic downscaling suffers from residual target misspecification caused by downscaling bias, which leads to biased and under-dispersive ensembles at test time. It introduces ReMatch to align the training residual distribution to the test-time regime via optimal transport in a low-dimensional PCA space, and reports substantial improvements in SSR, CRPS, and under-dispersion metrics on both a controlled synthetic benchmark with explicit bias levels and a real HRRR-ERA5 wind downscaling task, outperforming the standard mean-residual model and other baselines.
Significance. If the central mechanism holds, the work identifies and mitigates a previously under-appreciated source of miscalibration in a widely used paradigm for probabilistic downscaling, with direct relevance to atmospheric science and climate applications. The public release of code at the cited GitHub repository is a clear strength that supports reproducibility and further testing.
major comments (3)
- [Experiments] The central claim that residual target misspecification is the root cause (rather than generic miscalibration) rests on the synthetic benchmark and HRRR-ERA5 results, but the manuscript does not report direct diagnostics (e.g., Wasserstein distances or moment comparisons between training and test residuals before/after ReMatch) that would isolate this mechanism from other possible sources of improvement.
- [Method] §3 (ReMatch description): the assumption that low-dimensional PCA followed by OT preserves the high-frequency residual statistics required for ensemble dispersion is load-bearing for the claim of gap closure without side effects; no power-spectrum or scale-dependent ablation is shown to confirm that small-scale turbulent structures in the HRRR-ERA5 wind fields are not attenuated.
- [Experiments] Table 2 / Figure 4 (real-world results): the reported gains in SSR and CRPS are presented without statistical significance tests across multiple random seeds or cross-validation folds, making it difficult to assess whether the improvements are robust or could be explained by other modeling choices.
minor comments (2)
- [Abstract / Method] The abstract states that ReMatch 'preserves the statistical benefits of the mean-residual framework,' but the precise definition of this preservation (e.g., which moments or properties) is not restated in the method section.
- [Method] Notation for the PCA dimensionality hyperparameter and the OT cost function should be introduced once and used consistently; currently the text alternates between descriptive phrases and symbols without a central table of symbols.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below and outline targeted revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Experiments] The central claim that residual target misspecification is the root cause (rather than generic miscalibration) rests on the synthetic benchmark and HRRR-ERA5 results, but the manuscript does not report direct diagnostics (e.g., Wasserstein distances or moment comparisons between training and test residuals before/after ReMatch) that would isolate this mechanism from other possible sources of improvement.
Authors: We agree that explicit diagnostics of the residual distribution mismatch would more rigorously isolate the proposed mechanism. In the revised manuscript we will add Wasserstein-2 distances together with first- and second-moment comparisons between the training residuals, the test residuals, and the ReMatch-transformed residuals; these quantities will be reported for both the synthetic benchmark and the HRRR-ERA5 experiments. revision: yes
-
Referee: [Method] §3 (ReMatch description): the assumption that low-dimensional PCA followed by OT preserves the high-frequency residual statistics required for ensemble dispersion is load-bearing for the claim of gap closure without side effects; no power-spectrum or scale-dependent ablation is shown to confirm that small-scale turbulent structures in the HRRR-ERA5 wind fields are not attenuated.
Authors: This is a substantive methodological concern. We will augment the revised manuscript with a power-spectral-density comparison (and a supplementary scale-dependent energy plot) that contrasts the original HRRR residuals, the PCA-reconstructed residuals, and the OT-matched residuals, thereby quantifying any attenuation of small-scale variance. revision: yes
-
Referee: [Experiments] Table 2 / Figure 4 (real-world results): the reported gains in SSR and CRPS are presented without statistical significance tests across multiple random seeds or cross-validation folds, making it difficult to assess whether the improvements are robust or could be explained by other modeling choices.
Authors: We acknowledge the need for statistical rigor. The revision will include results aggregated over five independent random seeds, with mean and standard-deviation values reported for all metrics; paired statistical tests (t-tests or Wilcoxon signed-rank tests, as appropriate) will be added to Table 2 and Figure 4 to establish significance of the observed improvements. revision: yes
Circularity Check
No significant circularity; derivation and evaluation are independent
full rationale
The paper identifies residual target misspecification as the root cause of biased ensembles and proposes ReMatch (OT alignment in PCA space) to close the train-test gap. This is supported by explicit evaluations on a controlled synthetic benchmark with varying bias levels and on external HRRR-ERA5 observations. No equations reduce the claimed improvements to a fitted parameter defined by the result itself, no self-citations are load-bearing for the central premise, and the method does not rename known results or smuggle ansatzes via prior self-work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- PCA dimensionality
axioms (1)
- domain assumption Optimal transport alignment in PCA space preserves the statistical benefits of the mean-residual framework while correcting the train-test mismatch
Reference graph
Works this paper leans on
-
[1]
Optimal transport maps for distribution preserving operations on latent spaces of Generative Models
Eirikur Agustsson, Alexander Sage, Radu Timofte, and Luc Van Gool. Optimal transport maps for distribution preserving operations on latent spaces of generative models.arXiv preprint arXiv:1711.01970, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Image-to-image regression with distribution-free uncertainty quantification and applications in imaging
Anastasios N Angelopoulos, Amit Pal Kohli, Stephen Bates, Michael Jordan, Jitendra Malik, Thayer Alshaabi, Srigokul Upadhyayula, and Yaniv Romano. Image-to-image regression with distribution-free uncertainty quantification and applications in imaging. InInternational Conference on Machine Learning, pages 717–730. PMLR, 2022
2022
-
[3]
Robust optimal transport with applications in generative modeling and domain adaptation.Advances in Neural Information Processing Systems, 33:12934–12944, 2020
Yogesh Balaji, Rama Chellappa, and Soheil Feizi. Robust optimal transport with applications in generative modeling and domain adaptation.Advances in Neural Information Processing Systems, 33:12934–12944, 2020
2020
-
[4]
A theory of learning from different domains.Machine learning, 79(1):151–175, 2010
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. A theory of learning from different domains.Machine learning, 79(1):151–175, 2010
2010
-
[5]
Sliced and radon wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision, 51(1):22–45, 2015
Nicolas Bonneel, Julien Rabin, Gabriel Peyré, and Hanspeter Pfister. Sliced and radon wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision, 51(1):22–45, 2015
2015
-
[6]
Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, et al. Resgrad: Residual denoising diffusion probabilistic models for text to speech.arXiv preprint arXiv:2212.14518, 2022
-
[7]
Generative modeling through the semi-dual formu- lation of unbalanced optimal transport.Advances in Neural Information Processing Systems, 36:42433– 42455, 2023
Jaemoo Choi, Jaewoong Choi, and Myungjoo Kang. Generative modeling through the semi-dual formu- lation of unbalanced optimal transport.Advances in Neural Information Processing Systems, 36:42433– 42455, 2023
2023
-
[8]
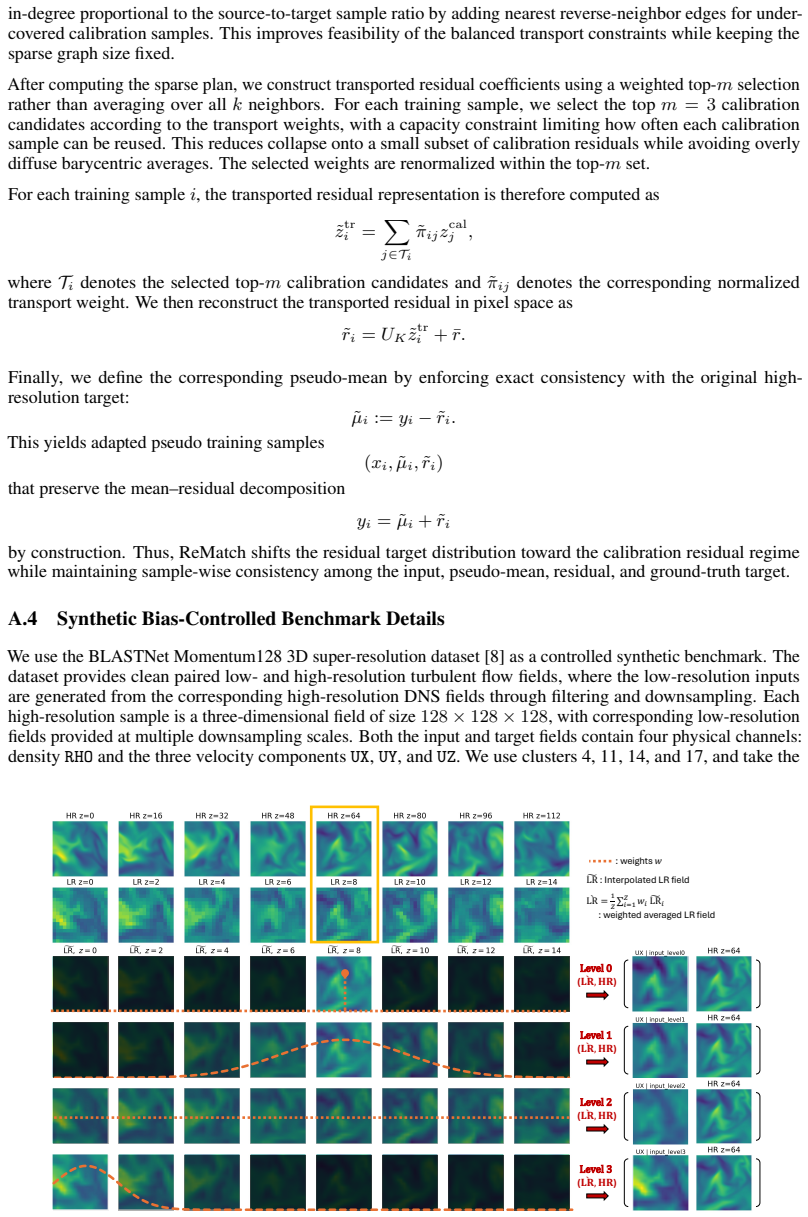
Turbulence in focus: Benchmarking scaling behavior of 3d volumetric super-resolution with blastnet 2.0 data.Advances in Neural Information Processing Systems, 36:77430–77484, 2023
Wai Tong Chung, Bassem Akoush, Pushan Sharma, Alex Tamkin, Ki Sung Jung, Jacqueline Chen, Jack Guo, Davy Brouzet, Mohsen Talei, Bruno Savard, et al. Turbulence in focus: Benchmarking scaling behavior of 3d volumetric super-resolution with blastnet 2.0 data.Advances in Neural Information Processing Systems, 36:77430–77484, 2023
2023
-
[9]
Joint distribution optimal transportation for domain adaptation
Nicolas Courty, Rémi Flamary, Amaury Habrard, and Alain Rakotomamonjy. Joint distribution optimal transportation for domain adaptation. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[10]
Optimal transport for domain adaptation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(9):1853–1865, 2017
Nicolas Courty, Rémi Flamary, Devis Tuia, and Alain Rakotomamonjy. Optimal transport for domain adaptation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(9):1853–1865, 2017
2017
-
[11]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
2013
-
[12]
Max-sliced wasserstein distance and its use for gans
Ishan Deshpande, Yuan-Ting Hu, Ruoyu Sun, Ayis Pyrros, Nasir Siddiqui, Sanmi Koyejo, Zhizhen Zhao, David Forsyth, and Alexander G Schwing. Max-sliced wasserstein distance and its use for gans. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10648–10656, 2019
2019
-
[13]
The high-resolution rapid refresh (hrrr): An hourly updating convection-allowing forecast model
David C Dowell, Curtis R Alexander, Eric P James, Stephen S Weygandt, Stanley G Benjamin, Geoffrey S Manikin, Benjamin T Blake, John M Brown, Joseph B Olson, Ming Hu, et al. The high-resolution rapid refresh (hrrr): An hourly updating convection-allowing forecast model. part i: Motivation and system description.Weather and Forecasting, 37(8):1371–1395, 2022
2022
-
[14]
Adaptive flow matching for resolving small-scale physics
Stathi Fotiadis, Noah D Brenowitz, Tomas Geffner, Yair Cohen, Michael Pritchard, Arash Vahdat, and Morteza Mardani. Adaptive flow matching for resolving small-scale physics. InForty-second International Conference on Machine Learning, 2025
2025
-
[15]
On the rate of convergence in wasserstein distance of the empirical measure.Probability Theory and Related Fields, 162(3–4):707–738, 2015
Nicolas Fournier and Arnaud Guillin. On the rate of convergence in wasserstein distance of the empirical measure.Probability Theory and Related Fields, 162(3–4):707–738, 2015. 10
2015
-
[16]
Stochastic optimization for large-scale optimal transport.Advances in neural information processing systems, 29, 2016
Aude Genevay, Marco Cuturi, Gabriel Peyré, and Francis Bach. Stochastic optimization for large-scale optimal transport.Advances in neural information processing systems, 29, 2016
2016
-
[17]
Cascast: Skillful high-resolution precipitation now- casting via cascaded modelling,
Junchao Gong, Lei Bai, Peng Ye, Wanghan Xu, Na Liu, Jianhua Dai, Xiaokang Yang, and Wanli Ouyang. Cascast: Skillful high-resolution precipitation nowcasting via cascaded modelling.arXiv preprint arXiv:2402.04290, 2024
-
[18]
The era5 global reanalysis.Quarterly journal of the royal meteorological society, 146(730):1999–2049, 2020
Hans Hersbach, Bill Bell, Paul Berrisford, Shoji Hirahara, András Horányi, Joaquín Muñoz-Sabater, Julien Nicolas, Carole Peubey, Raluca Radu, Dinand Schepers, et al. The era5 global reanalysis.Quarterly journal of the royal meteorological society, 146(730):1999–2049, 2020
1999
-
[19]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Predicting tropical cyclone rainfall through perceptual-based identification of similar atmospheric fields.Weather and Climate Extremes, page 100896, 2026
Jose Angelo Hokson, Shinjiro Kanae, and Yusuke Hiraga. Predicting tropical cyclone rainfall through perceptual-based identification of similar atmospheric fields.Weather and Climate Extremes, page 100896, 2026
2026
-
[21]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[22]
What uncertainties do we need in bayesian deep learning for computer vision? Advances in neural information processing systems, 30, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? Advances in neural information processing systems, 30, 2017
2017
-
[23]
Pope, Charles E
Soheil Kolouri, Phillip E. Pope, Charles E. Martin, and Gustavo K. Rohde. Sliced-wasserstein autoencoder: An embarrassingly simple generative model. InInternational Conference on Learning Representations, 2019
2019
-
[24]
Neural optimal transport.arXiv preprint arXiv:2201.12220, 2022
Alexander Korotin, Daniil Selikhanovych, and Evgeny Burnaev. Neural optimal transport.arXiv preprint arXiv:2201.12220, 2022
-
[25]
Chih-Yu Lai, Yu-Chien Ning, and Duane S Boning. Rdit: Residual-based diffusion implicit models for probabilistic time series forecasting.arXiv preprint arXiv:2509.02341, 2025
-
[26]
Rescast: Enhancing global medium-range precipitation forecasting with residual diffusion model
Guowen Li, Yang Liu, Shilei Cao, Mengxuan Chen, Xintong Liu, Xuehe Wang, Juepeng Zheng, Yuxiang Li, Zhiyu Ye, Haoyuan Liang, et al. Rescast: Enhancing global medium-range precipitation forecasting with residual diffusion model
-
[27]
Diffusion-based decoupled deterministic and uncertain framework for probabilistic multivariate time series forecasting
Qi Li, Zhenyu Zhang, Lei Yao, Zhaoxia Li, Tianyi Zhong, and Yong Zhang. Diffusion-based decoupled deterministic and uncertain framework for probabilistic multivariate time series forecasting. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 1833–1844, 2021
2021
-
[29]
Tianyi Lin, Chenyou Fan, Nhat Ho, Marco Cuturi, and Michael I. Jordan. Projection robust wasserstein distance and riemannian optimization. InAdvances in Neural Information Processing Systems, volume 33, pages 9383–9397, 2020
2020
-
[30]
Latent Space Optimal Transport for Generative Models
Huidong Liu, Yang Guo, Na Lei, Zhixin Shu, Shing-Tung Yau, Dimitris Samaras, and Xianfeng Gu. Latent space optimal transport for generative models.arXiv preprint arXiv:1809.05964, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Cambridge University Press, 2018
Douglas Maraun and Martin Widmann.Statistical downscaling and bias correction for climate research. Cambridge University Press, 2018
2018
-
[32]
Residual corrective diffusion modeling for km-scale atmospheric downscaling.Communications Earth & Environment, 6(1):124, 2025
Morteza Mardani, Noah Brenowitz, Yair Cohen, Jaideep Pathak, Chieh-Yu Chen, Cheng-Chin Liu, Arash Vahdat, Mohammad Amin Nabian, Tao Ge, Akshay Subramaniam, et al. Residual corrective diffusion modeling for km-scale atmospheric downscaling.Communications Earth & Environment, 6(1):124, 2025
2025
-
[33]
Boosting weather forecast via generative superensemble.npj Climate and Atmospheric Science, 8(1):377, 2025
Congyi Nai, Xi Chen, Shangshang Yang, Ziniu Xiao, and Baoxiang Pan. Boosting weather forecast via generative superensemble.npj Climate and Atmospheric Science, 8(1):377, 2025
2025
-
[34]
Thao Nguyen, Jiaqi Ma, Fahad Shahbaz Khan, Souhaib Ben Taieb, and Salman Khan. Raindiff: End-to-end precipitation nowcasting via token-wise attention diffusion.arXiv preprint arXiv:2510.14962, 2025
-
[35]
A survey on transfer learning.IEEE Transactions on Knowledge and Data Engineering, 22(10):1345–1359, 2010
Sinno Jialin Pan and Qiang Yang. A survey on transfer learning.IEEE Transactions on Knowledge and Data Engineering, 22(10):1345–1359, 2010. 11
2010
-
[36]
Subspace robust wasserstein distances
François-Pierre Paty and Marco Cuturi. Subspace robust wasserstein distances. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 5072–5081. PMLR, 2019
2019
-
[37]
Now Foundations and Trends, 2019
Gabriel Peyré and Marco Cuturi.Computational optimal transport: With applications to data science. Now Foundations and Trends, 2019
2019
-
[38]
Enhancing regional climate downscaling through advances in machine learning.Artificial Intelligence for the Earth Systems, 3(2):230066, 2024
Neelesh Rampal, Sanaa Hobeichi, Peter B Gibson, Jorge Baño-Medina, Gab Abramowitz, Tom Beucler, Jose González-Abad, William Chapman, Paula Harder, and José Manuel Gutiérrez. Enhancing regional climate downscaling through advances in machine learning.Artificial Intelligence for the Earth Systems, 3(2):230066, 2024
2024
-
[39]
Optimal transport for multi-source domain adaptation under target shift
Ievgen Redko, Nicolas Courty, Rémi Flamary, and Devis Tuia. Optimal transport for multi-source domain adaptation under target shift. InProceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 849–858. PMLR, 2019
2019
-
[40]
Improving predictive inference under covariate shift by weighting the log-likelihood function.Journal of Statistical Planning and Inference, 90(2):227–244, 2000
Hidetoshi Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function.Journal of Statistical Planning and Inference, 90(2):227–244, 2000
2000
-
[41]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[42]
Maximilian Springenberg, Noelia Otero, Yuxin Xue, and Jackie Ma. Diffscale: Continuous downscaling and bias correction of subseasonal wind speed forecasts using diffusion models.Journal of Advances in Modeling Earth Systems, 18(3):e2025MS005282, 2026
2026
-
[43]
MIT Press, 2012
Masashi Sugiyama and Motoaki Kawanabe.Machine Learning in Non-Stationary Environments: Introduc- tion to Covariate Shift Adaptation. MIT Press, 2012
2012
-
[44]
Wasserstein auto-encoders
Ilya Tolstikhin, Olivier Bousquet, Sylvain Gelly, and Bernhard Schölkopf. Wasserstein auto-encoders. In International Conference on Learning Representations, 2018
2018
-
[45]
Springer, 2009
Cédric Villani et al.Optimal transport: old and new, volume 338. Springer, 2009
2009
-
[46]
Zhong Yi Wan, Ricardo Baptista, Anudhyan Boral, Yi-Fan Chen, John Anderson, Fei Sha, and Leonardo Zepeda-Núñez. Debias coarsely, sample conditionally: Statistical downscaling through optimal transport and probabilistic diffusion models.Advances in Neural Information Processing Systems, 36:47749–47763, 2023
2023
-
[47]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[48]
Sharp asymptotic and finite-sample rates of convergence of empirical measures in wasserstein distance
Jonathan Weed and Francis Bach. Sharp asymptotic and finite-sample rates of convergence of empirical measures in wasserstein distance. InBernoulli, volume 25, pages 2620–2648, 2019
2019
-
[49]
U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow.Advances in Water Resources, 163:104180, 2022
Gege Wen, Zongyi Li, Kamyar Azizzadenesheli, Anima Anandkumar, and Sally M Benson. U-fno—an enhanced fourier neural operator-based deep-learning model for multiphase flow.Advances in Water Resources, 163:104180, 2022
2022
-
[50]
Diffcast: A unified framework via residual diffusion for precipitation nowcasting
Demin Yu, Xutao Li, Yunming Ye, Baoquan Zhang, Chuyao Luo, Kuai Dai, Rui Wang, and Xunlai Chen. Diffcast: A unified framework via residual diffusion for precipitation nowcasting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27758–27767, 2024
2024
-
[51]
Yubai Yuan, Babak Shahbaba, Norbert Fortin, Keiland Cooper, Qing Nie, and Annie Qu. Optimal transport for latent integration with an application to heterogeneous neuronal activity data.arXiv preprint arXiv:2407.00099, 2024
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[53]
∑𝑤# LR$#
Zhenkai Zhang, Markus Hiller, Krista A Ehinger, and Tom Drummond. Pixel-level residual diffusion transformer: Scalable 3d ct volume generation. InThe Fourteenth International Conference on Learning Representations. 12 A Appendix A.1 Related Work Statistical and deep learning downscaling.Statistical downscaling models high-resolution fields from coarse inp...
2087
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.