Beyond Clean Text: Evaluating Encoder and Decoder Robustness for Bangla Event Detection in Noisy Text
Pith reviewed 2026-07-01 01:43 UTC · model grok-4.3
The pith
Encoder models for Bangla event detection lose more performance under noise than decoder-only LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
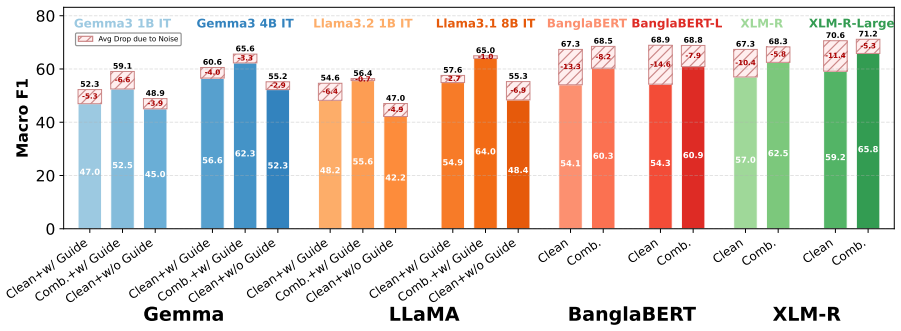
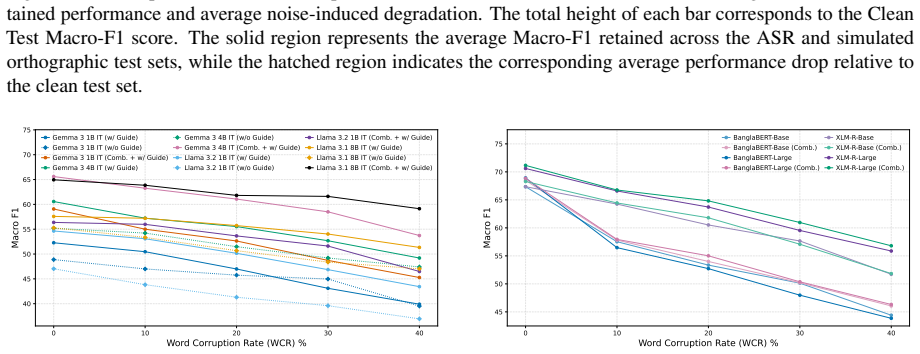
Encoder models achieve higher performance on clean text but degrade substantially under noise, whereas decoder-only LLMs are markedly more robust, particularly when event triggers are corrupted.
What carries the argument
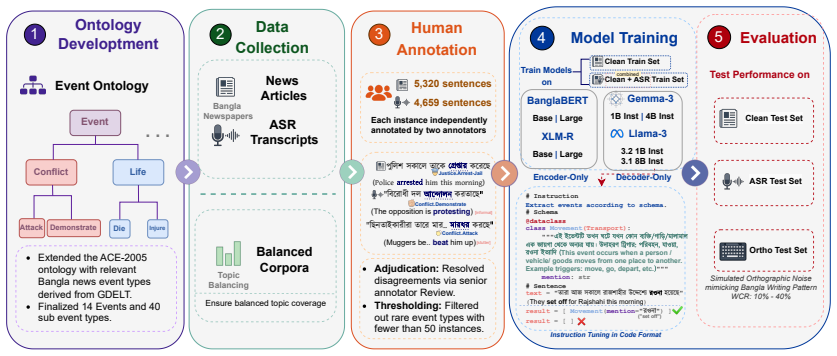
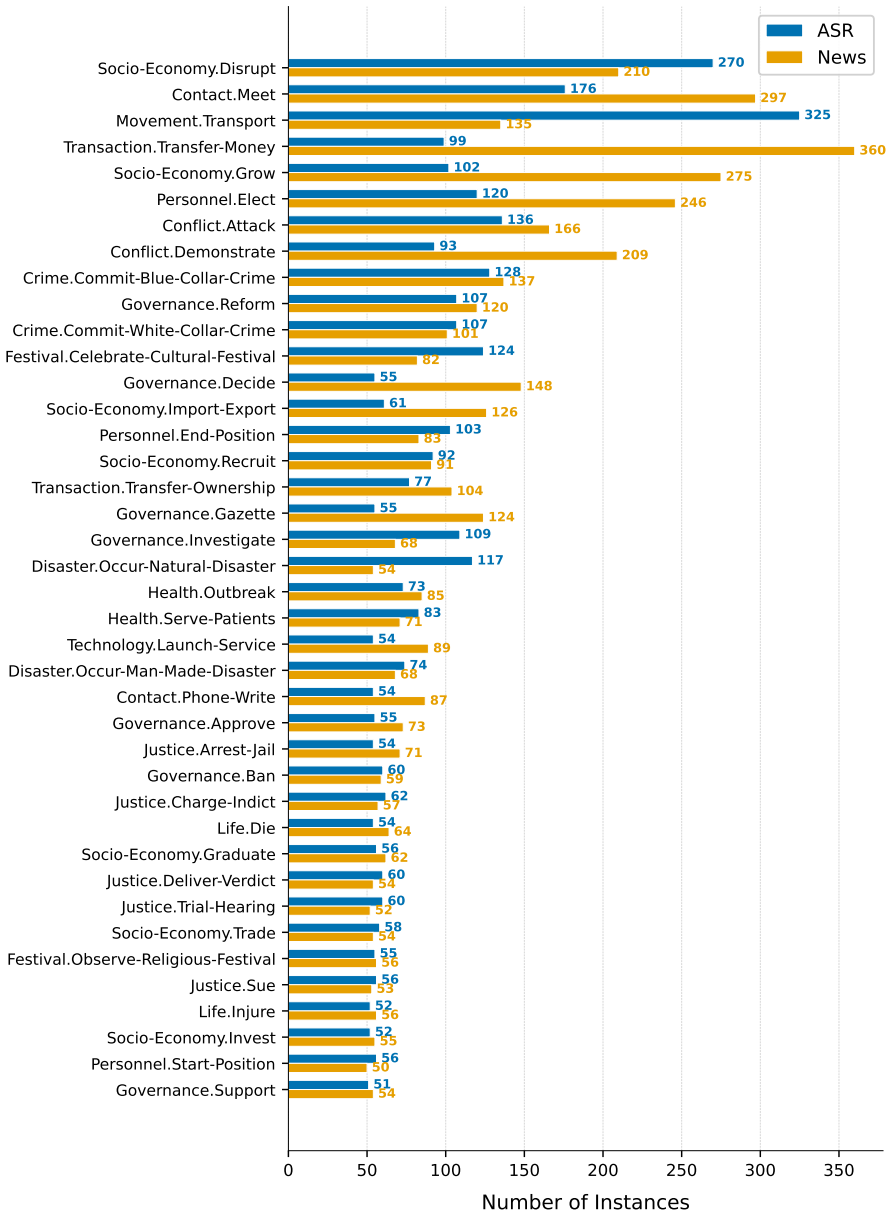
The generalized Bangla news event ontology and 9,979-sentence benchmark with clean, ASR, and orthographically corrupted conditions, used to evaluate fine-tuned encoders against instruction-tuned decoders.
If this is right
- Combined training on clean and noisy data serves as an effective regularization strategy that narrows the robustness gap for encoder architectures.
- Model scaling consistently improves the robustness of decoder-only LLMs.
- Embedding annotation guidelines during instruction tuning establishes a higher performance baseline on noisy text.
Where Pith is reading between the lines
- The robustness pattern may apply to other low-resource languages facing similar text noise issues.
- Systems for real-time event detection from speech might prefer decoder models due to their noise tolerance.
Load-bearing premise
The 9,979-sentence benchmark with its three noise conditions sufficiently represents real-world Bangla text noise and event distributions for the robustness conclusions to generalize.
What would settle it
Running the same models on a separate Bangla event detection dataset collected from different sources with new noise patterns and finding that encoder models no longer degrade more than decoders.
Figures




read the original abstract
Event detection (ED) systems are typically evaluated on clean, curated text, leaving their robustness to real-world noise largely unexplored, particularly for low-resource languages such as Bangla. We introduce a generalized Bangla news event ontology and a benchmark comprising 9,979 annotated sentences across 40 event subtypes, spanning clean news text, real-world Automatic Speech Recognition (ASR) transcripts, and orthographically corrupted text. We systematically evaluate fine-tuned encoder-only models (BanglaBERT and XLM-R) alongside instruction-tuned decoder-only large language models (Llama 3 and Gemma 3). Our results reveal a clear architectural trade-off: encoder models achieve higher performance on clean text but degrade substantially under noise, whereas decoder-only LLMs are markedly more robust, particularly when event triggers are corrupted. We further show that embedding annotation guidelines during instruction tuning establishes a higher performance baseline on noisy text but yields inconsistent reductions in performance degradation across noisy conditions. Finally, model scaling consistently improves the robustness of decoder-only LLMs, while combined training on clean and noisy data serves as an effective regularization strategy that disproportionately benefits encoder architectures, significantly narrowing the robustness gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Bangla event detection ontology and a 9,979-sentence benchmark spanning 40 subtypes across clean news text, real-world ASR transcripts, and orthographically corrupted text. It evaluates fine-tuned encoder-only models (BanglaBERT, XLM-R) against instruction-tuned decoder-only LLMs (Llama 3, Gemma 3), reporting that encoders achieve higher clean-text performance but degrade substantially under noise while decoders are more robust (especially to trigger corruption). Additional results show that embedding annotation guidelines during tuning raises noisy-text baselines, model scaling improves decoder robustness, and combined clean+noisy training narrows the robustness gap, particularly for encoders.
Significance. If the observed architectural trade-off and mitigation strategies hold beyond the specific benchmark, the work would provide actionable guidance for deploying event detection in noisy, low-resource settings such as ASR-derived or social-media Bangla text, while highlighting the value of decoder-only models for robustness.
major comments (1)
- [Benchmark construction section] Benchmark construction section: the claim that the three noise conditions (clean news, ASR transcripts, orthographic corruption) sufficiently proxy real-world Bangla noise distributions for generalizing the encoder/decoder robustness trade-off is not supported by any quantitative validation against external corpora (e.g., social-media text or outputs from additional ASR engines); without such checks the degradation patterns and the effectiveness of combined training could be artifacts of the chosen noise realizations.
minor comments (2)
- [Abstract and results sections] Abstract and results sections: the abstract states performance differences but the main text should explicitly report the precise metrics (F1, precision, recall), statistical tests, and per-condition breakdowns for each model to allow verification of the claimed trade-offs.
- [Noise conditions subsection] The paper should clarify whether the orthographic corruption mechanism is deterministic or stochastic and provide the exact corruption rate or distribution used, as this directly affects reproducibility of the trigger-corruption results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark construction section] Benchmark construction section: the claim that the three noise conditions (clean news, ASR transcripts, orthographic corruption) sufficiently proxy real-world Bangla noise distributions for generalizing the encoder/decoder robustness trade-off is not supported by any quantitative validation against external corpora (e.g., social-media text or outputs from additional ASR engines); without such checks the degradation patterns and the effectiveness of combined training could be artifacts of the chosen noise realizations.
Authors: We acknowledge the absence of quantitative validation against external corpora such as social-media text or outputs from additional ASR engines. The ASR transcripts are drawn from real-world Bangla ASR systems, and the orthographic corruption is modeled on attested error patterns in Bangla; however, we performed no distributional comparisons or statistical tests against broader external sources. In the revised version we will (1) qualify the benchmark-construction claims to describe the three conditions as representative proxies rather than validated proxies of all real-world Bangla noise, and (2) add an explicit limitations paragraph noting that observed degradation patterns and the benefits of combined training could be influenced by the specific noise realizations chosen. These changes will prevent over-generalization while retaining the benchmark’s utility for the evaluated settings. revision: yes
Circularity Check
No circularity: purely empirical benchmark and model comparison
full rationale
The paper introduces a new Bangla event detection benchmark (9,979 sentences across clean, ASR, and orthographic conditions) and reports direct experimental results comparing encoder-only and decoder-only models. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All claims (e.g., encoder degradation vs. decoder robustness) rest on observed performance metrics rather than any reduction to inputs by construction. This is standard empirical evaluation work with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Stages of Event Extraction , booktitle =
Ahn, David , editor =. The Stages of Event Extraction , booktitle =
-
[13]
Cunha, Lu. Event. doi:10.1007/9 , urldate =. arXiv , keywords =:2408.16932 , primaryclass =
-
[21]
International Studies Association Annual Conference , year=
GDELT: Global Data on Events, Language, and Tone, 1979-2012 , author=. International Studies Association Annual Conference , year=
1979
-
[23]
Machine Learning and Knowledge Discovery in Databases , pages=
On the stratification of multi-label data , author=. Machine Learning and Knowledge Discovery in Databases , pages=. 2011 , publisher=
2011
-
[24]
Proceedings of the First International Workshop on Learning with Imbalanced Domains: Theory and Applications , pages =
A Network Perspective on Stratification of Multi-Label Data , author =. Proceedings of the First International Workshop on Learning with Imbalanced Domains: Theory and Applications , pages =. 2017 , editor =
2017
-
[29]
Patwardhan, Siddharth and Riloff, Ellen , editor =. A. Proceedings of the 2009
2009
-
[30]
Hong, Yu and Zhang, Jianfeng and Ma, Bin and Yao, Jianmin and Zhou, Guodong and Zhu, Qiaoming , editor =. Using. Proceedings of the 49th
-
[31]
Li, Qi and Ji, Heng and Huang, Liang , editor =. Joint. Proceedings of the 51st
-
[34]
Overview of
Kim, Jin-Dong and Ohta, Tomoko and Pyysalo, Sampo and Kano, Yoshinobu and Tsujii, Jun'ichi , editor =. Overview of. Proceedings of the
-
[37]
Proceedings of the 2024
Touileb, Samia and Murstad, Jeanett and M. Proceedings of the 2024
2024
-
[38]
Li, Peng and Sun, Tianxiang and Tang, Qiong and Yan, Hang and Wu, Yuanbin and Huang, Xuanjing and Qiu, Xipeng , editor =. Proceedings of the 61st. doi:10.18653/v1/2023.acl-long.855 , urldate =
-
[39]
Guo, Yucan and Li, Zixuan and Jin, Xiaolong and Liu, Yantao and Zeng, Yutao and Liu, Wenxuan and Li, Xiang and Yang, Pan and Bai, Long and Guo, Jiafeng and Cheng, Xueqi , year = 2023, month = nov, number =. Retrieval-. doi:10.48550/arXiv.2311.02962 , urldate =. arXiv , keywords =:2311.02962 , primaryclass =
-
[43]
David Ahn. 2006. The stages of event extraction. In Proceedings of the Workshop on Annotating and Reasoning about Time and Events , pages 1--8, Sydney, Australia. Association for Computational Linguistics
2006
-
[44]
Abdullah Al Monsur, Nitesh Vamshi Bommisetty, and Gene Louis Kim. 2026. https://doi.org/10.18653/v1/2026.findings-eacl.314 Event Detection with a Context-Aware Encoder and LoRA for Improved Performance on Long-Tailed Classes . In Findings of the Association for Computational Linguistics : EACL 2026 , pages 5985--6003, Rabat, Morocco. Association for Compu...
-
[45]
Saddam Hossain Mukta, and Swakkhar Shatabda
Iftakhar Ali Khandokar, Abdullah All Tanvir, Md . Saddam Hossain Mukta, and Swakkhar Shatabda. 2025. https://doi.org/10.1007/s44230-025-00092-8 Temporal, Demographic , and Geographical Analysis of Violent Events in Bangla News Media Using NLP Techniques . Human-Centric Intelligent Systems, 5(1):90--102
-
[46]
Sohel Rahman, and Rifat Shahriyar
Abhik Bhattacharjee, Tahmid Hasan, Wasi Ahmad, Kazi Samin Mubasshir, Md Saiful Islam, Anindya Iqbal, M. Sohel Rahman, and Rifat Shahriyar. 2022. https://doi.org/10.18653/v1/2022.findings-naacl.98 BanglaBERT : Language Model Pretraining and Benchmarks for Low-Resource Language Understanding Evaluation in Bangla . In Findings of the Association for Computat...
-
[47]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. https://doi.org/10.18653/v1/2020.acl-main.747 Unsupervised Cross-lingual Representation Learning at Scale . In Proceedings of the 58th Annual Meeting of the Association for Comp...
-
[48]
Bhargav Dave, Surupendu Gangopadhyay, Prasenjit Majumder, Pushpak Bhattacharya, Sudeshna Sarkar, and Sobha Lalitha Devi. 2021. https://doi.org/10.1145/3441501.3441516 FIRE 2020 EDNIL Track : Event Detection from News in Indian Languages . In Proceedings of the 12th Annual Meeting of the Forum for Information Retrieval Evaluation , FIRE '20, pages 25--28, ...
-
[49]
Sazzadur Rahman, Motahara Sabah Mredula, A
Noyon Dey, Md. Sazzadur Rahman, Motahara Sabah Mredula, A. S. M. Sanwar Hosen, and In-Ho Ra. 2021. https://doi.org/10.3390/electronics10192367 Using Machine Learning to Detect Events on the Basis of Bengali and Banglish Facebook Posts . Electronics, 10(19):2367
-
[50]
Abhimanyu Dubey, Abhinav Jauhri, and et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Seth Ebner, Patrick Xia, Ryan Culkin, Kyle Rawlins, and Benjamin Van Durme. 2020. https://doi.org/10.18653/v1/2020.acl-main.718 Multi- Sentence Argument Linking . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 8057--8077, Online. Association for Computational Linguistics
-
[52]
Kazi Toufique Elahi, Tasnuva Binte Rahman, Shakil Shahriar, Samir Sarker, Md Tanvir Rouf Shawon, and G. M. Shahariar. 2024. https://doi.org/10.48550/arXiv.2401.14360 A Comparative Analysis of Noise Reduction Methods in Sentiment Analysis on Noisy Bangla Texts . Preprint, arXiv:2401.14360
-
[53]
Gemma Team , Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram \'e , Morgane Rivi \`e re, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean-bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 193 others. 2025. https://doi.org/10.4855...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
-
[54]
Yu Hong, Jianfeng Zhang, Bin Ma, Jianmin Yao, Guodong Zhou, and Qiaoming Zhu. 2011. Using Cross-Entity Inference to Improve Event Extraction . In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics : Human Language Technologies , pages 1127--1136, Portland, Oregon, USA. Association for Computational Linguistics
2011
-
[55]
Md. Mithun Hossain, Sanjara , Md. Shakil Hossain, Sudipto Chaki, Md. Saifur Rahman, and A B M Shawkat Ali. 2025. https://doi.org/10.1109/NCIM65934.2025.11160104 MaskNet : Enhancing Crime Event Detection with Feature Masking and Dynamic Attention . In 2025 2nd International Conference on Next-Generation Computing , IoT and Machine Learning ( NCIM ) , pages 1--6
-
[56]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu , Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. https://doi.org/10.48550/arXiv.2106.09685 LoRA : Low-Rank Adaptation of Large Language Models . Preprint, arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2021
-
[57]
Kuan-Hao Huang, I-Hung Hsu, Tanmay Parekh, Zhiyu Xie, Zixuan Zhang, Prem Natarajan, Kai-Wei Chang, Nanyun Peng, and Heng Ji. 2024. https://doi.org/10.18653/v1/2024.findings-acl.760 TextEE : Benchmark , Reevaluation , Reflections , and Future Challenges in Event Extraction . In Findings of the Association for Computational Linguistics : ACL 2024 , pages 12...
-
[58]
HumanSignal . 2020. Label Studio : Data labeling software. Available at https://labelstud.io
2020
-
[59]
Khondoker Ittehadul Islam, Sudipta Kar, Md Saiful Islam, and Mohammad Ruhul Amin. 2021. https://doi.org/10.18653/v1/2021.findings-emnlp.278 SentNoB : A Dataset for Analysing Sentiment on Noisy Bangla Texts . In Findings of the Association for Computational Linguistics : EMNLP 2021 , pages 3265--3271, Punta Cana, Dominican Republic. Association for Computa...
-
[60]
Iftakhar Ali Khandokar, Imtiaz Mamun, Tasmia Ishrat Alam Chadni, Zubair Ahmed Anas, and Swakkhar Shatabda. 2020. https://doi.org/10.1109/ETCCE51779.2020.9350891 Event Detection and Knowledge Mining from Unlabelled Bengali News Articles . In 2020 Emerging Technology in Computing , Communication and Electronics ( ETCCE ) , pages 1--6, Bangladesh. IEEE
-
[61]
Jin-Dong Kim, Tomoko Ohta, Sampo Pyysalo, Yoshinobu Kano, and Jun'ichi Tsujii. 2009. Overview of BioNLP '09 Shared Task on Event Extraction . In Proceedings of the BioNLP 2009 Workshop Companion Volume for Shared Task , pages 1--9, Boulder, Colorado. Association for Computational Linguistics
2009
-
[62]
Duong Le and Thien Huu Nguyen. 2021. https://doi.org/10.18653/v1/2021.eacl-main.237 Fine- Grained Event Trigger Detection . In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics : Main Volume , pages 2745--2752, Online. Association for Computational Linguistics
-
[63]
Kalev Leetaru and Philip Schrodt. 2013. Gdelt: Global data on events, language, and tone, 1979-2012. In International Studies Association Annual Conference, San Francisco, CA
2013
-
[64]
Qi Li, Heng Ji, and Liang Huang. 2013. Joint Event Extraction via Structured Prediction with Global Features . In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 73--82, Sofia, Bulgaria. Association for Computational Linguistics
2013
-
[65]
Ilya Loshchilov and Frank Hutter. 2019. https://doi.org/10.48550/arXiv.1711.05101 Decoupled Weight Decay Regularization . Preprint, arXiv:1711.05101
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2019
-
[66]
Minh Van Nguyen, Viet Dac Lai, Amir Pouran Ben Veyseh, and Thien Huu Nguyen. 2021. https://doi.org/10.18653/v1/2021.eacl-demos.10 Trankit: A Light-Weight Transformer-based Toolkit for Multilingual Natural Language Processing . In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics : System Demonstrat...
-
[67]
Chaoxu Pang, Yixuan Cao, Qiang Ding, and Ping Luo. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.950 Guideline Learning for In-Context Information Extraction . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 15372--15389, Singapore. Association for Computational Linguistics
-
[68]
Siddharth Patwardhan and Ellen Riloff. 2009. A Unified Model of Phrasal and Sentential Evidence for Information Extraction . In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing , pages 151--160, Singapore. Association for Computational Linguistics
2009
-
[69]
Amir Pouran Ben Veyseh, Minh Van Nguyen, Franck Dernoncourt, and Thien Nguyen. 2022. https://doi.org/10.18653/v1/2022.naacl-main.166 MINION : A Large-Scale and Diverse Dataset for Multilingual Event Detection . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies...
-
[70]
Shahidul Salim, and Sk Imran Hossain
Asif Mohammed Saad, Umme Niraj Mahi, Md. Shahidul Salim, and Sk Imran Hossain. 2024. https://doi.org/10.1016/j.dib.2024.110874 Bangla news article dataset . Data in Brief, 57:110874
-
[71]
Oscar Sainz, Iker Garc \'i a-Ferrero , Rodrigo Agerri, Oier Lopez de Lacalle, German Rigau, and Eneko Agirre. 2024. https://doi.org/10.48550/arXiv.2310.03668 GoLLIE : Annotation Guidelines improve Zero-Shot Information-Extraction . Preprint, arXiv:2310.03668
-
[72]
Konstantinos Sechidis, Grigorios Tsoumakas, and Ioannis Vlahavas. 2011. On the stratification of multi-label data. Machine Learning and Knowledge Discovery in Databases, pages 145--158
2011
-
[73]
Omar Sharif, Joseph Gatto, Madhusudan Basak, and Sarah Masud Preum. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.673 Explicit, Implicit , and Scattered : Revisiting Event Extraction to Capture Complex Arguments . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 12061--12081, Miami, Florida, USA. Associ...
-
[74]
Md Habibur Rahman Sifat, Chowdhury Rafeed Rahman, Mohammad Rafsan, and Md Hasibur Rahman. 2020. https://doi.org/10.48550/arXiv.2003.03484 Synthetic Error Dataset Generation Mimicking Bengali Writing Pattern . Preprint, arXiv:2003.03484
-
[75]
Matthew Sims, Jong Ho Park, and David Bamman. 2019. https://doi.org/10.18653/v1/P19-1353 Literary Event Detection . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 3623--3634, Florence, Italy. Association for Computational Linguistics
-
[76]
Saurabh Srivastava, Sweta Pati, and Ziyu Yao. 2025. https://doi.org/10.18653/v1/2025.findings-acl.677 Instruction- Tuning LLMs for Event Extraction with Annotation Guidelines . In Findings of the Association for Computational Linguistics : ACL 2025 , pages 13055--13071, Vienna, Austria. Association for Computational Linguistics
-
[77]
Piotr Szymański and Tomasz Kajdanowicz. 2017. A network perspective on stratification of multi-label data. In Proceedings of the First International Workshop on Learning with Imbalanced Domains: Theory and Applications, volume 74 of Proceedings of Machine Learning Research, pages 22--35, ECML-PKDD, Skopje, Macedonia. PMLR
2017
-
[78]
Samia Touileb, Jeanett Murstad, Petter M hlum, Lubos Steskal, Lilja Charlotte Storset, Huiling You, and Lilja vrelid. 2024. EDEN : A Dataset for Event Detection in Norwegian News . In Proceedings of the 2024 Joint International Conference on Computational Linguistics , Language Resources and Evaluation ( LREC-COLING 2024) , pages 5495--5506, Torino, Itali...
2024
-
[79]
Walker, Christopher , Strassel, Stephanie , Medero, Julie , and Maeda, Kazuaki . 2006. https://doi.org/10.35111/MWXC-VH88 ACE 2005 Multilingual Training Corpus
-
[80]
Xiaozhi Wang, Ziqi Wang, Xu Han, Wangyi Jiang, Rong Han, Zhiyuan Liu, Juanzi Li, Peng Li, Yankai Lin, and Jie Zhou. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.129 MAVEN : A Massive General Domain Event Detection Dataset . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pages 1652--1671, Online. ...
-
[81]
Xingyao Wang, Sha Li, and Heng Ji. 2023. https://doi.org/10.48550/arXiv.2210.12810 Code4Struct : Code Generation for Few-Shot Event Structure Prediction . Preprint, arXiv:2210.12810
-
[82]
Feng Yao, Chaojun Xiao, Xiaozhi Wang, Zhiyuan Liu, Lei Hou, Cunchao Tu, Juanzi Li, Yun Liu, Weixing Shen, and Maosong Sun. 2022. https://doi.org/10.18653/v1/2022.findings-acl.17 LEVEN : A Large-Scale Chinese Legal Event Detection Dataset . In Findings of the Association for Computational Linguistics : ACL 2022 , pages 183--201, Dublin, Ireland. Associatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.