Personalizing Marketplace Policies with Competing Objectives and Constrained Experiments: Evidence from a Job Marketplace
Pith reviewed 2026-07-01 06:17 UTC · model grok-4.3
The pith
A personalized policy for free-value thresholds improves target metrics in a job marketplace while respecting engagement constraints despite limited experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an integrated framework of ensemble-based hybrid ranking models, treatment effect extrapolation under validated monotonicity, and production deployment enables personalization of free-value thresholds that delivers statistically significant and economically sizable lift in the target metric while complying with engagement guardrails, succeeding where single-objective methods increase guardrail risk by over 10 percent for equivalent target gains.
What carries the argument
Ensemble-based hybrid ranking models that separately target employer metrics and job-seeker engagement guardrails, paired with a treatment effect extrapolation method that extends estimates from few discrete levels to untested policies under monotonicity.
If this is right
- Hybrid ranking models cut guardrail risk by more than 10 percent compared with single-objective ranking for the same target improvement.
- The extrapolation method accurately forecasts effects at policy levels never directly tested in the experiment.
- Post-launch monitoring confirms both the predicted lift and continued compliance with engagement constraints.
- The overall approach succeeds under cluster randomization that limits experiments to discrete treatments.
Where Pith is reading between the lines
- Similar hybrid modeling plus extrapolation could address personalization in other two-sided platforms where interference also forces cluster experiments.
- If monotonicity fails in some segments, the framework would need additional validation experiments at more levels before wider rollout.
- Extending the models to optimize more than two objectives might handle marketplaces with additional stakeholder groups.
Load-bearing premise
Treatment effects follow a monotonic pattern that allows reliable extrapolation from the few tested policy levels to other values.
What would settle it
If actual outcomes after deploying the extrapolated policy levels deviated substantially from the model's predictions while monotonicity held in the data, the extrapolation component would be falsified.
Figures



read the original abstract
Two-sided marketplaces connect distinct user groups whose interests often conflict -- improving outcomes on one side could degrade the other side's experience. To address this challenge, we deploy an integrated framework for personalizing free-value thresholds -- a policy governing the scope of complimentary services for job listings -- across a two-sided job marketplace connecting millions of employers and job seekers. Our personalized policy delivers statistically significant and economically sizable lift in the target metric while respecting engagement guardrail constraints. Direct application of standard uplift methods proves insufficient here for two reasons. First, cross-side externalities demand multi-objective optimization: maximizing employer-side metrics risks harming job seeker engagement, with effects varying substantially across job segments. Second, marketplace interference necessitates cluster-level randomization, limiting us to few discrete treatment levels -- effectively a form of positivity violation that rules out methods designed for continuous treatments. We contribute an integrated framework with three components. Our ensemble-based hybrid ranking models target and guardrail metrics separately, cutting guardrail risk by over 10% for equivalent target gains compared to single-objective approaches. A treatment effect extrapolation method extends our estimates from limited experimental variation to untested policy levels, relying on monotonicity assumptions that we validate empirically. Finally, we present production deployment, where post-launch data confirms both extrapolation accuracy and guardrail compliance. Our deployed system demonstrates that principled methodology can enable meaningful personalization even when experiments are severely constrained and different objectives compete -- common conditions that characterize many real-world marketplaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an integrated framework for personalizing free-value thresholds in a two-sided job marketplace. It uses ensemble-based hybrid ranking models to separately target employer metrics and job-seeker engagement guardrails, a treatment-effect extrapolation procedure that extends limited cluster-randomized experimental levels to untested policy values under monotonicity assumptions validated empirically, and post-deployment results claiming statistically significant lifts in the target metric while maintaining guardrail compliance despite cross-side externalities and positivity violations from cluster randomization.
Significance. If the extrapolation and validation hold, the work shows that principled multi-objective personalization remains feasible under severe experimental constraints common to marketplaces. The reported >10% reduction in guardrail risk for equivalent target gains relative to single-objective baselines, together with post-launch confirmation of extrapolation accuracy, supplies concrete evidence of practical utility.
major comments (2)
- [Abstract] Abstract (treatment effect extrapolation method): the claim that monotonicity assumptions are validated empirically does not specify whether the checks are performed within the job segments used for personalization or only globally. Segment-level heterogeneity and cross-side interference can produce non-monotonic responses even when average monotonicity holds; without segment-specific falsification, the guardrail compliance guarantee for the deployed personalized policy is not assured.
- [Abstract] Production deployment paragraph: the statement that post-launch data confirms extrapolation accuracy and guardrail compliance provides no quantitative details on the validation procedure (e.g., how monotonicity was tested per segment, sample sizes, confidence intervals, or exclusion rules), rendering the empirical grounding of the central safety claim impossible to evaluate from the given information.
minor comments (1)
- [Abstract] The abstract states that the hybrid models 'cut guardrail risk by over 10%' but does not define the exact risk metric or the baseline single-objective comparator used for the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major point below and agree that greater specificity is required to substantiate the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (treatment effect extrapolation method): the claim that monotonicity assumptions are validated empirically does not specify whether the checks are performed within the job segments used for personalization or only globally. Segment-level heterogeneity and cross-side interference can produce non-monotonic responses even when average monotonicity holds; without segment-specific falsification, the guardrail compliance guarantee for the deployed personalized policy is not assured.
Authors: We agree that the abstract is insufficiently precise on this point and that segment-level validation is necessary to rule out heterogeneity-driven violations. The full manuscript conducts the monotonicity checks separately within each personalization segment (using the same cluster-randomized data) precisely to address cross-side interference and segment-specific non-monotonicity. We will revise the abstract to state explicitly that "monotonicity assumptions are validated empirically at the segment level." This change directly strengthens the guardrail-compliance claim for the personalized policy. revision: yes
-
Referee: [Abstract] Production deployment paragraph: the statement that post-launch data confirms extrapolation accuracy and guardrail compliance provides no quantitative details on the validation procedure (e.g., how monotonicity was tested per segment, sample sizes, confidence intervals, or exclusion rules), rendering the empirical grounding of the central safety claim impossible to evaluate from the given information.
Authors: We acknowledge that the abstract supplies no quantitative validation metrics, making independent assessment impossible from the abstract alone. The full manuscript contains the per-segment tests, sample sizes, confidence intervals, and exclusion criteria, but these are not summarized in the abstract. In the revision we will either (a) insert a concise quantitative summary into the abstract or (b) add an explicit reference to a new validation table in the main text. Either approach will make the empirical grounding evaluable. revision: yes
Circularity Check
No circularity: extrapolation grounded in empirical monotonicity validation and post-launch confirmation
full rationale
The paper's derivation chain centers on an ensemble hybrid ranking model for multi-objective optimization and a treatment effect extrapolation method that extends from cluster-randomized discrete levels using monotonicity assumptions explicitly validated empirically, followed by post-launch data confirming accuracy and guardrail compliance. No step reduces by construction to fitted inputs or self-citations; the monotonicity check and deployment validation supply independent empirical grounding outside the fitted parameters. The abstract and described framework remain self-contained against external benchmarks without self-definitional loops or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Himan Abdollahpouri, Gediminas Adomavicius, Robin Burke, Ido Guy, Dietmar Jannach, Toshihiro Kamishima, Jan Krasnodebski, and Luiz Pizzato. 2020. Multi- stakeholder Recommendation: Survey and Research Directions.User Modeling and User-Adapted Interaction30, 1 (2020), 127–158. doi:10.1007/s11257-019-09256- 1
-
[2]
Sanae Amani, Mahnoosh Alizadeh, and Christos Thrampoulidis. 2019. Linear Stochastic Bandits Under Safety Constraints. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 32
2019
-
[3]
Susan Athey, Julie Tibshirani, and Stefan Wager. 2019. Generalized Random Forests.The Annals of Statistics47, 2 (2019), 1148–1178
2019
- [4]
-
[5]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. Double/Debiased Machine Learning for Treatment and Structural Parameters.The Econometrics Journal21, 1 (2018), C1–C68
2018
-
[6]
Simon De Vos, Christopher Bockel-Rickermann, Stefan Lessmann, and Wouter Verbeke. 2026. Uplift modeling with continuous treatments: A predict-then- optimize approach.European Journal of Operational Research330, 1 (2026), 230–244. doi:10.1016/j.ejor.2025.10.025
-
[7]
Floris Devriendt, Jeroen Berrevoets, and Wouter Verbeke. 2021. Why You Should Stop Predicting Customer Churn and Start Using Uplift Models.Information Sciences548 (2021), 497–515
2021
-
[8]
Floris Devriendt, Darie Moldovan, and Wouter Verbeke. 2018. A Literature Survey and Experimental Evaluation of the State-of-the-Art in Uplift Modeling: A Stepping Stone Toward the Development of Prescriptive Analytics.Big Data6, 1 (2018), 13–41. doi:10.1089/big.2017.0104
-
[9]
Benjamin Edelman and Julian Wright. 2015. Price Coherence and Excessive Intermediation.The Quarterly Journal of Economics130, 3 (2015), 1283–1328
2015
-
[10]
Google Marketing Solutions. 2023. Fractional Uplift: A Flexible Python Package for Cost-Aware Uplift Modelling. GitHub repository
2023
-
[11]
Robin Gubela, Stefan Lessmann, and Szymon Jaroszewicz. 2020. Response Trans- formation and Profit Decomposition for Revenue Uplift Modeling.European Journal of Operational Research283, 2 (2020), 647–661
2020
-
[12]
Keisuke Hirano and Guido W. Imbens. 2004. The Propensity Score with Con- tinuous Treatments. InApplied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives. Wiley, 73–84
2004
-
[13]
David Holtz, Felipe Lobel, Ruben Lobel, Inessa Liskovich, and Sinan Aral. 2024. Reducing Interference Bias in Online Marketplace Experiments Using Cluster Randomization: Evidence from a Pricing Meta-experiment on Airbnb.Manage- ment Science71, 1 (2024), 390–406. doi:10.1287/mnsc.2020.01157
-
[14]
John J. Horton. 2010. Online Labor Markets. InInternet and Network Economics. 515–522
2010
-
[15]
Weintraub
Ramesh Johari, Hannah Li, Inessa Liskovich, and Gabriel Y. Weintraub. 2022. Experimental Design in Two-Sided Platforms: An Analysis of Bias.Management Science68, 10 (2022), 7069–7089
2022
-
[16]
Kennedy, Zongming Ma, Matthew D
Edward H. Kennedy, Zongming Ma, Matthew D. McHugh, and Dylan S. Small
-
[17]
Non-parametric Methods for Doubly Robust Estimation of Continuous Treatment Effects.Journal of the Royal Statistical Society: Series B79, 4 (2017), 1229–1245
2017
-
[18]
Künzel, Jasjeet S
Sören R. Künzel, Jasjeet S. Sekhon, Peter J. Bickel, and Bin Yu. 2019. Metalearn- ers for Estimating Heterogeneous Treatment Effects Using Machine Learning. Proceedings of the National Academy of Sciences116, 10 (2019), 4156–4165
2019
-
[19]
Aurélie Lemmens and Sunil Gupta. 2020. Managing Churn to Maximize Profits. Marketing Science39, 5 (2020), 956–973
2020
-
[20]
Xiao Lin, Hongjie Chen, Changhua Pei, Fei Sun, Xuanji Xiao, Hanxiao Sun, Yongfeng Zhang, Wenwu Ou, and Peng Jiang. 2019. A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation. InPro- ceedings of the 13th ACM Conference on Recommender Systems (RecSys ’19). 20–28. doi:10.1145/3298689.3346998
- [21]
-
[22]
Daniele Micci-Barreca. 2001. A Preprocessing Scheme for High-Cardinality Categorical Attributes in Classification and Prediction Problems.ACM SIGKDD Explorations Newsletter3, 1 (2001), 27–32
2001
-
[23]
Felipe Moraes, Hugo Manuel Proença, Anastasiia Kornilova, Javier Albert, and Dmitri Goldenberg. 2023. Uplift Modeling: from Causal Inference to Personaliza- tion. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM ’23). 5212–5215. doi:10.1145/3583780.3615298
-
[24]
Xinkun Nie and Stefan Wager. 2021. Quasi-oracle Estimation of Heterogeneous Treatment Effects.Biometrika108, 2 (2021), 299–319
2021
-
[25]
Michael Schomaker, Helen McIlleron, Paolo Denti, and Iván Díaz. 2024. Causal Inference for Continuous Multiple Time Point Interventions.Statistics in Medicine 43 (2024), 5380–5400. doi:10.1002/sim.10246
-
[26]
Aleksandrs Slivkins. 2019. Introduction to Multi-Armed Bandits.Foundations and Trends in Machine Learning12, 1-2 (2019), 1–286. doi:10.1561/2200000068
-
[27]
Wouter Verbeke, Diego Olaya, Marie-Anne Guerry, and Jente Van Belle. 2023. To do or not to do? Cost-sensitive causal classification with individual treatment effect estimates.European Journal of Operational Research305 (2023), 838–852. doi:10.1016/j.ejor.2022.03.049
-
[28]
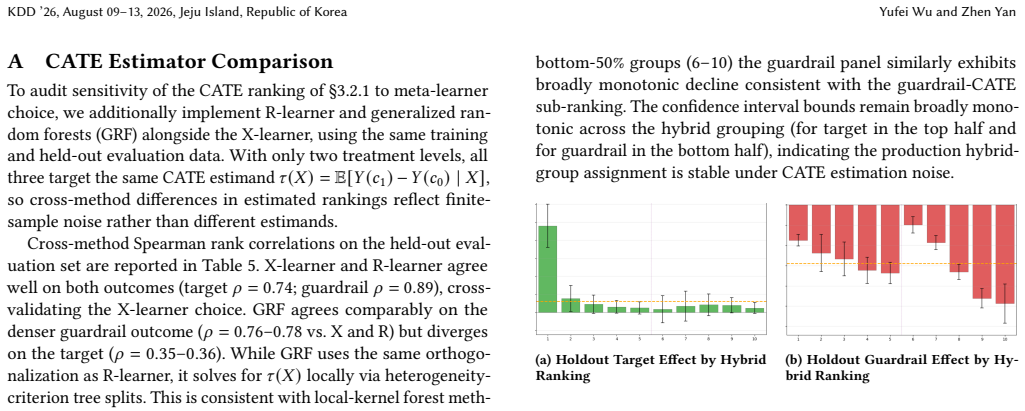
Stefan Wager and Susan Athey. 2018. Estimation and Inference of Heterogeneous Treatment Effects Using Random Forests.J. Amer. Statist. Assoc.113, 523 (2018), 1228–1242. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Yufei Wu and Zhen Yan A CATE Estimator Comparison To audit sensitivity of the CATE ranking of §3.2.1 to meta-learner choice, we ...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.