ShardNet: Training Neural Controllers with Hard, Non-Convex Constraints
Pith reviewed 2026-07-01 01:15 UTC · model grok-4.3
The pith
ShardNet embeds a differentiable projection layer into neural controllers to enforce non-convex safety constraints by construction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
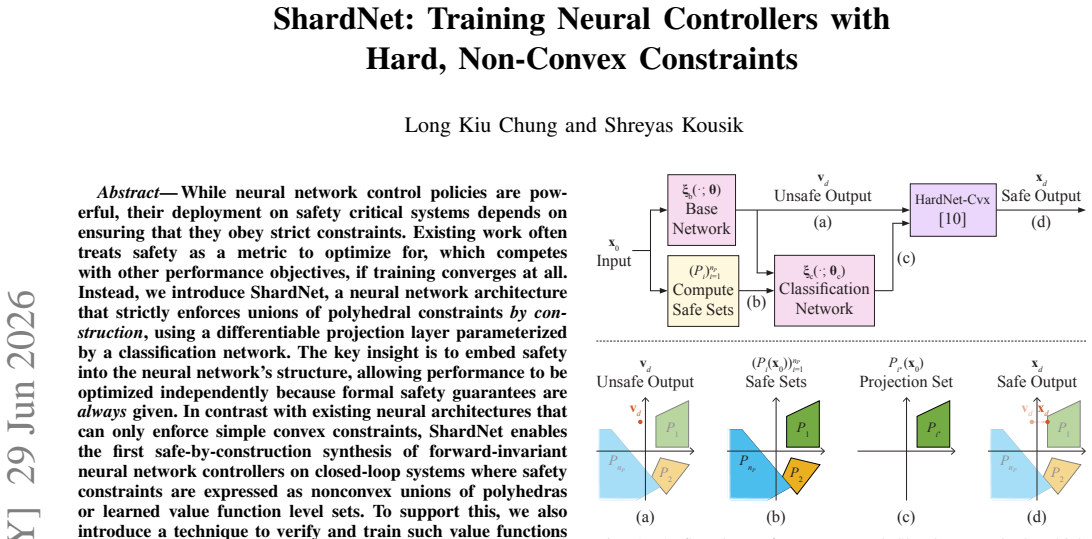
ShardNet is a neural network architecture that strictly enforces unions of polyhedral constraints by construction using a differentiable projection layer parameterized by a classification network. This enables the first safe-by-construction synthesis of forward-invariant neural network controllers on closed-loop systems where safety constraints are expressed as nonconvex unions of polyhedras or learned value function level sets. A supporting technique trains and verifies such value functions correctly as ReLU networks, which had not previously been possible. On double integrator benchmarks, the resulting policies maintain 100% safety on verified sets and achieve significantly lower objective
What carries the argument
The differentiable projection layer parameterized by a classification network, which maps proposed actions onto the safe set defined by nonconvex unions of polyhedra or value-function level sets while preserving differentiability for gradient-based training.
If this is right
- Performance objectives can be optimized independently because formal safety guarantees are supplied by the network structure rather than by the loss function.
- Forward-invariant controllers become trainable for safety sets that are nonconvex unions of polyhedra or level sets of learned value functions.
- Value functions represented as ReLU networks can be trained and verified to certify larger safe sets than earlier verification methods allow.
- On double-integrator systems drawn from the literature, the approach yields policies with 100 percent safety compliance on verified sets and lower objective loss than prior formal synthesis techniques.
Where Pith is reading between the lines
- The same projection mechanism could be tested on higher-dimensional or nonlinear dynamics to check whether the forward-invariance property scales beyond the double-integrator case.
- If the layer remains stable under discretization and sensor noise, it might reduce reliance on post-training reachability analysis in some embedded control settings.
- Combining the ReLU value-function technique with existing set-propagation tools could produce hybrid verification pipelines that certify both the network and the closed-loop trajectories.
Load-bearing premise
The projection layer can be inserted into the closed-loop dynamics without creating numerical instabilities or breaking the forward-invariance property during training and verification.
What would settle it
A closed-loop simulation or formal verification run in which a trained ShardNet policy produces a trajectory that exits the claimed forward-invariant safe set would falsify the safety guarantee.
Figures


read the original abstract
While neural network control policies are powerful, their deployment on safety critical systems depends on ensuring that they obey strict constraints. Existing work often treats safety as a metric to optimize for, which competes with other performance objectives, if training converges at all. Instead, we introduce ShardNet, a neural network architecture that strictly enforces unions of polyhedral constraints by construction, using a differentiable projection layer parameterized by a classification network. The key insight is to embed safety into the neural network's structure, allowing performance to be optimized independently because formal safety guarantees are always given. In contrast with existing neural architectures that can only enforce simple convex constraints, ShardNet enables the first safe-by-construction synthesis of forward-invariant neural network controllers on closed-loop systems where safety constraints are expressed as nonconvex unions of polyhedras or learned value function level sets. To support this, we also introduce a technique to verify and train such value functions correctly as rectified linear unit (ReLU) networks, which has not previously been possible. On double integrator benchmarks drawn from the literature, ShardNet policies maintain 100% safety on verified sets and achieves significantly lower objective loss compared to existing formal methods. Furthermore, our value function training technique also produces safe sets more than 3 times larger than existing verification approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShardNet, a neural controller architecture that embeds unions of polyhedral safety constraints via a differentiable projection layer parameterized by a learned classification network. This is claimed to enforce forward invariance by construction even for non-convex unions of polyhedra or level sets of ReLU value functions. A new technique for training and verifying such ReLU value functions is presented. On double-integrator benchmarks the method is reported to achieve 100% safety on verified sets, lower objective loss than prior formal methods, and safe sets more than 3 times larger than existing verification approaches.
Significance. If the central claims on invariance-by-construction and the new ReLU verification technique hold, the work would be significant: it would separate safety enforcement from performance optimization for constraint sets that are non-convex, which existing convex-only neural architectures cannot handle. The reported benchmark gains (100% safety, 3x larger sets) would constitute a concrete advance over prior formal synthesis methods on the same double-integrator problems.
major comments (3)
- [§3 (architecture and projection layer)] The central claim that the projection layer (parameterized by the classification network) enforces forward invariance by construction for non-convex unions is load-bearing yet lacks a complete closed-loop argument. No section demonstrates that classification errors or boundary transitions cannot map a state outside the safe set under the closed-loop map f(x, π(x)).
- [§4 (value-function training and verification)] The new ReLU value-function training/verification technique is presented as enabling >3× larger safe sets, but the manuscript provides neither a formal statement of the verification procedure nor a side-by-side comparison on the same benchmark instances with error bounds or failure cases.
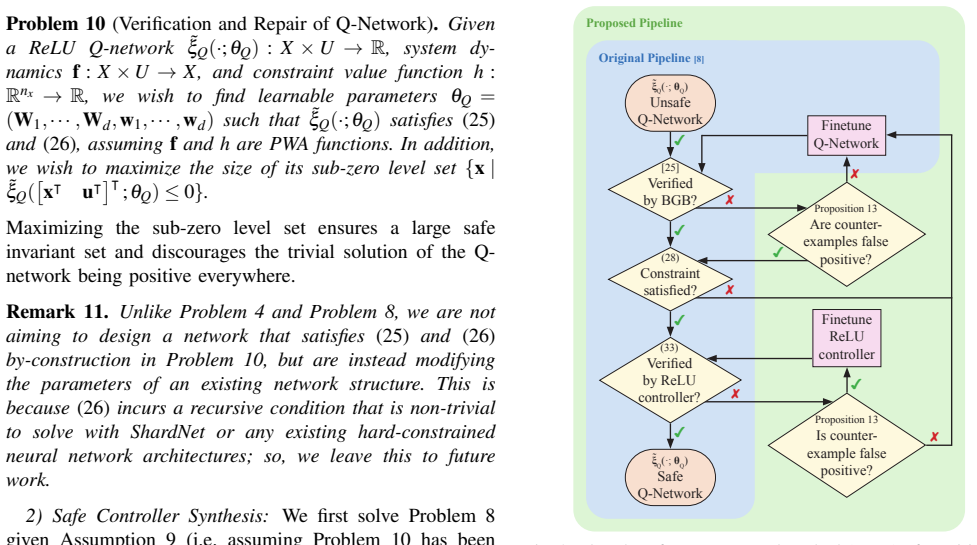
- [Table 1 and §5 (experiments)] Table 1 (double-integrator results) reports 100% safety and objective-loss improvements, yet the text does not specify how the verified safe sets were obtained or whether the projection layer was active during the verification step itself.
minor comments (2)
- [§3.2] Notation for the classification network output and the shard-selection logic is introduced without an explicit equation relating the softmax probabilities to the final projected control input.
- [abstract] The abstract states “unions of polyhedras”; the correct plural is “polyhedra.”
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which highlight important aspects of our presentation that require clarification. We address each major comment below and commit to revising the manuscript to strengthen the arguments and details.
read point-by-point responses
-
Referee: [§3 (architecture and projection layer)] The central claim that the projection layer (parameterized by the classification network) enforces forward invariance by construction for non-convex unions is load-bearing yet lacks a complete closed-loop argument. No section demonstrates that classification errors or boundary transitions cannot map a state outside the safe set under the closed-loop map f(x, π(x)).
Authors: We agree that an explicit closed-loop invariance proof would strengthen the manuscript. The projection layer ensures that the output of the controller lies within the safe set by projecting onto the union of polyhedra selected by the classification network. Since the safe set is defined as the union, any projection onto one of the constituent polyhedra keeps the state inside the safe set. However, to address concerns about classification errors at boundaries, we will add a detailed proof in the revised §3 demonstrating that the closed-loop dynamics preserve invariance regardless of classification accuracy, as the projection always maps to the safe union. This will include analysis of boundary transitions. revision: yes
-
Referee: [§4 (value-function training and verification)] The new ReLU value-function training/verification technique is presented as enabling >3× larger safe sets, but the manuscript provides neither a formal statement of the verification procedure nor a side-by-side comparison on the same benchmark instances with error bounds or failure cases.
Authors: We will add a formal statement of the verification procedure in the revised §4. Additionally, we will include a side-by-side comparison table on the same benchmark instances, reporting error bounds and discussing any failure cases observed during verification. revision: yes
-
Referee: [Table 1 and §5 (experiments)] Table 1 (double-integrator results) reports 100% safety and objective-loss improvements, yet the text does not specify how the verified safe sets were obtained or whether the projection layer was active during the verification step itself.
Authors: We will revise the text in §5 and the caption of Table 1 to explicitly state that the verified safe sets were obtained by applying the ReLU value function verification technique to the level sets, and that the projection layer was active during the verification process to ensure the reported 100% safety rates. revision: yes
Circularity Check
No circularity: derivation chain is self-contained
full rationale
The paper defines ShardNet via a new differentiable projection layer and a new ReLU value-function training/verification technique, both introduced within the manuscript. The forward-invariance claim follows directly from the architecture's construction (projection onto shards) and the stated verification procedure, without any reduction to fitted parameters from the authors' prior work or self-citation chains. Benchmark results are presented as empirical outcomes of these independent methods rather than tautological outputs. No quoted equation or step equates a claimed prediction to its own input by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The projection onto unions of polyhedra can be realized differentiably via a classification network without affecting closed-loop forward invariance.
invented entities (1)
-
ShardNet projection layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deepreach: A deep learning approach to high-dimensional reachability,
S. Bansal and C. J. Tomlin, “Deepreach: A deep learning approach to high-dimensional reachability,” in 2021 IEEE International Con- ference on Robotics and Automation (ICRA), IEEE, 2021, pp. 1817– 1824
2021
-
[2]
Bridging hamilton-jacobi safety analysis and reinforce- ment learning,
J. F. Fisac, N. F. Lugovoy, V . Rubies-Royo, S. Ghosh, and C. J. Tomlin, “Bridging hamilton-jacobi safety analysis and reinforce- ment learning,” in 2019 International Conference on Robotics and Automation (ICRA), IEEE, 2019, pp. 8550–8556
2019
-
[3]
Safe control with learned certificates: A survey of neural lyapunov, barrier, and contraction methods for robotics and control,
C. Dawson, S. Gao, and C. Fan, “Safe control with learned certificates: A survey of neural lyapunov, barrier, and contraction methods for robotics and control,” IEEE Transactions on Robotics , vol. 39, no. 3, pp. 1749–1767, 2023
2023
-
[4]
Learning safe, generalizable perception-based hybrid control with certificates,
C. Dawson, B. Lowenkamp, D. Goff, and C. Fan, “Learning safe, generalizable perception-based hybrid control with certificates,” IEEE Robotics and Automation Letters , vol. 7, no. 2, pp. 1904– 1911, 2022
1904
-
[5]
Safe nonlinear control using robust neural lyapunov-barrier functions,
C. Dawson, Z. Qin, S. Gao, and C. Fan, “Safe nonlinear control using robust neural lyapunov-barrier functions,” in Conference on Robot Learning, PMLR, 2022, pp. 1724–1735
2022
-
[6]
Provably-safe neural network train- ing using hybrid zonotope reachability analysis,
L. K. Chung and S. Kousik, “Provably-safe neural network train- ing using hybrid zonotope reachability analysis,” arXiv preprint arXiv:2501.13023, 2025
-
[7]
Certified Robust Invariant Polytope Training in Neural Controlled ODEs
A. Harapanahalli and S. Coogan, “Certified robust invariant polytope training in neural controlled odes,” arXiv preprint arXiv:2408.01273, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Verifiable safety q-filters via hamilton-jacobi reachability and multiplicative q-networks,
J. Li, H. Hu, Y . Yang, and C. Liu, “Verifiable safety q-filters via hamilton-jacobi reachability and multiplicative q-networks,” arXiv preprint arXiv:2506.15693, 2025
-
[9]
Goal-reaching trajectory design near danger with piecewise affine reach-avoid computation,
L. K. Chung, W. Jung, C. Kong, and S. Kousik, “Goal-reaching trajectory design near danger with piecewise affine reach-avoid computation,” arXiv preprint arXiv:2402.15604 , 2024
-
[10]
Y . Min and N. Azizan, “Hardnet: Hard-constrained neural net- works with universal approximation guarantees,” arXiv preprint arXiv:2410.10807, 2024
-
[11]
Infinite time reachability of state-space regions by using feedback control,
D. Bertsekas, “Infinite time reachability of state-space regions by using feedback control,” IEEE Transactions on Automatic Control , vol. 17, no. 5, pp. 604–613, 1972
1972
-
[12]
Blanchini, S
F. Blanchini, S. Miani, et al. , Set-theoretic methods in control . Springer, 2008, vol. 78
2008
-
[13]
Computing controlled invariant sets in two moves,
T. Anevlavis and P. Tabuada, “Computing controlled invariant sets in two moves,” in 2019 IEEE 58th Conference on Decision and Control (CDC), IEEE, 2019, pp. 6248–6254
2019
-
[14]
Multi- parametric toolbox 3.0,
M. Herceg, M. Kvasnica, C. N. Jones, and M. Morari, “Multi- parametric toolbox 3.0,” in 2013 European control conference (ECC), IEEE, 2013, pp. 502–510
2013
-
[15]
Reachable polyhedral marching (rpm): An exact analysis tool for deep-learned control systems,
J. A. Vincent and M. Schwager, “Reachable polyhedral marching (rpm): An exact analysis tool for deep-learned control systems,” IEEE Transactions on Neural Networks and Learning Systems , 2025
2025
-
[16]
Robust positively in- variant polyhedral sets and constrained control using fuzzy ts mod- els: A bilinear optimization design strategy,
C. E. D ´orea, E. B. Castelan, and J. G. Ernesto, “Robust positively in- variant polyhedral sets and constrained control using fuzzy ts mod- els: A bilinear optimization design strategy,” IFAC-PapersOnLine, vol. 53, no. 2, pp. 8013–8018, 2020
2020
-
[17]
Polyhedral control design: Theory and methods,
B. Houska, M. A. M ¨uller, and M. E. Villanueva, “Polyhedral control design: Theory and methods,” arXiv preprint arXiv:2412.13082 , 2024
-
[18]
Robust control barrier–value functions for safety-critical control,
J. J. Choi, D. Lee, K. Sreenath, C. J. Tomlin, and S. L. Herbert, “Robust control barrier–value functions for safety-critical control,” in 2021 60th IEEE Conference on Decision and Control (CDC) , IEEE, 2021, pp. 6814–6821
2021
-
[19]
Data-driven safety filters: Hamilton-jacobi reachability, control barrier functions, and predictive methods for uncertain systems,
K. P. Wabersich, A. J. Taylor, J. J. Choi, et al., “Data-driven safety filters: Hamilton-jacobi reachability, control barrier functions, and predictive methods for uncertain systems,” IEEE Control Systems Magazine, vol. 43, no. 5, pp. 137–177, 2023
2023
-
[20]
Hamilton-jacobi reachability: A brief overview and recent advances,
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” in 2017 IEEE 56th Annual Conference on Decision and Control (CDC) , IEEE, 2017, pp. 2242–2253
2017
-
[21]
Computa- tional techniques for the verification of hybrid systems,
C. J. Tomlin, I. Mitchell, A. M. Bayen, and M. Oishi, “Computa- tional techniques for the verification of hybrid systems,” Proceed- ings of the IEEE , vol. 91, no. 7, pp. 986–1001, 2003
2003
-
[22]
Control barrier functions: Theory and applica- tions,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applica- tions,” in2019 18th European control conference (ECC), Ieee, 2019, pp. 3420–3431
2019
-
[23]
Control barrier function based quadratic programs with application to adaptive cruise control,
A. D. Ames, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs with application to adaptive cruise control,” in 53rd IEEE conference on decision and control , IEEE, 2014, pp. 6271–6278
2014
-
[24]
Control barrier function based quadratic programs for safety critical systems,
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,”IEEE Transactions on Automatic Control , vol. 62, no. 8, pp. 3861–3876, 2016
2016
-
[25]
Scalable synthesis of formally verified neural value function for hamilton-jacobi reacha- bility analysis,
Y . Yang, H. Hu, T. Wei, S. E. Li, and C. Liu, “Scalable synthesis of formally verified neural value function for hamilton-jacobi reacha- bility analysis,” Journal of Artificial Intelligence Research , vol. 83, 2025
2025
-
[26]
Learning verifi- able control policies using relaxed verification,
P. Chaudhury, A. Estornell, and M. Everett, “Learning verifi- able control policies using relaxed verification,” arXiv preprint arXiv:2504.16879, 2025
-
[27]
Constrained feedforward neural network training via reachability analysis,
L. K. Chung, A. Dai, D. Knowles, S. Kousik, and G. X. Gao, “Constrained feedforward neural network training via reachability analysis,” arXiv preprint arXiv:2107.07696 , 2021
-
[28]
Stability and performance verification of dynamical systems controlled by neural networks: Algorithms and complexity,
M. Korda, “Stability and performance verification of dynamical systems controlled by neural networks: Algorithms and complexity,” IEEE Control Systems Letters , vol. 6, pp. 3265–3270, 2022
2022
-
[29]
Mpolice: Provable enforce- ment of multi-region affine constraints in deep neural networks,
M. Ataei, H. Cheong, and A. Butscher, “Mpolice: Provable enforce- ment of multi-region affine constraints in deep neural networks,” arXiv preprint arXiv:2502.02434 , 2025
-
[30]
Police: Provably optimal linear constraint enforcement for deep neural networks,
R. Balestriero and Y . LeCun, “Police: Provably optimal linear constraint enforcement for deep neural networks,” in ICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , IEEE, 2023, pp. 1–5
2023
-
[31]
A new computationally simple approach for implementing neural networks with output hard constraints,
A. V . Konstantinov and L. V . Utkin, “A new computationally simple approach for implementing neural networks with output hard constraints,” in Doklady Mathematics , Springer, vol. 108, 2023, S233–S241
2023
-
[32]
A Generalized Mixed-Integer Convex Program for Multilegged Footstep Planning on Uneven Terrain
B. Aceituno-Cabezas, J. Cappelletto, J. C. Grieco, and G. Fern´andez-L´opez, “A generalized mixed-integer convex program for multilegged footstep planning on uneven terrain,” arXiv preprint arXiv:1612.02109, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[33]
ENFORCE: Nonlinear Constrained Learning with Adaptive-depth Neural Projection
G. Lastrucci and A. M. Schweidtmann, “Enforce: Nonlinear con- strained learning with adaptive-depth neural projection,” arXiv preprint arXiv:2502.06774, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Physics- informed neural networks with hard nonlinear equality and inequal- ity constraints,
A. Iftakher, R. Golder, B. N. Roy, and M. F. Hasan, “Physics- informed neural networks with hard nonlinear equality and inequal- ity constraints,” Computers & Chemical Engineering , p. 109 418, 2025
2025
-
[35]
J.-B. Bouvier, K. Nagpal, and N. Mehr, “Policed rl: Learning closed-loop robot control policies with provable satisfaction of hard constraints,” arXiv preprint arXiv:2403.13297 , 2024
-
[36]
Posafenet: Safe learning with poset-structured neural nets,
K. Wong, W. Xiao, and D. Rus, “Posafenet: Safe learning with poset-structured neural nets,” arXiv preprint arXiv:2601.22356 , 2026
-
[37]
M. J. Kochenderfer, S. M. Katz, A. L. Corso, and R. J. Moss, Algorithms for validation , 2025
2025
-
[38]
Evaluating Robustness of Neural Networks with Mixed Integer Programming
V . Tjeng, K. Xiao, and R. Tedrake, “Evaluating robustness of neural networks with mixed integer programming,” arXiv preprint arXiv:1711.07356, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Effi- cient neural network robustness certification with general activation functions,
H. Zhang, T.-W. Weng, P.-Y . Chen, C.-J. Hsieh, and L. Daniel, “Effi- cient neural network robustness certification with general activation functions,” Advances in neural information processing systems , vol. 31, 2018
2018
-
[40]
Differentiable convex optimization layers,
A. Agrawal, B. Amos, S. Barratt, S. Boyd, S. Diamond, and J. Z. Kolter, “Differentiable convex optimization layers,” Advances in neural information processing systems , vol. 32, 2019
2019
-
[41]
Optnet: Differentiable optimization as a layer in neural networks,
B. Amos and J. Z. Kolter, “Optnet: Differentiable optimization as a layer in neural networks,” in International conference on machine learning, PMLR, 2017, pp. 136–145
2017
-
[42]
Guaranteed reach- avoid for black-box systems through narrow gaps via neural network reachability,
L. K. Chung, W. Jung, S. Pullabhotla, et al. , “Guaranteed reach- avoid for black-box systems through narrow gaps via neural network reachability,” in 2025 IEEE International Conference on Robotics and Automation (ICRA) , IEEE, 2025, pp. 3574–3581
2025
-
[43]
Mixed-integer formulations for opti- mal control of piecewise-affine systems,
T. Marcucci and R. Tedrake, “Mixed-integer formulations for opti- mal control of piecewise-affine systems,” inProceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, 2019, pp. 230–239
2019
-
[44]
K. He, S. Shi, T. v. d. Boom, and B. De Schutter, “State- action control barrier functions: Imposing safety on learning- based control with low online computational costs,” arXiv preprint arXiv:2312.11255, 2023
-
[45]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in International conference on machine learning , Pmlr, 2018, pp. 1861–1870
2018
-
[46]
A new general- purpose algorithm for mixed-integer bilevel linear programs,
M. Fischetti, I. Ljubi ´c, M. Monaci, and M. Sinnl, “A new general- purpose algorithm for mixed-integer bilevel linear programs,” Op- erations Research, vol. 65, no. 6, pp. 1615–1637, 2017
2017
-
[47]
Verification of deep convolutional neural networks using imagestars,
H.-D. Tran, S. Bak, W. Xiang, and T. T. Johnson, “Verification of deep convolutional neural networks using imagestars,” in Interna- tional conference on computer aided verification , Springer, 2020, pp. 18–42
2020
-
[48]
Verification of recurrent neural networks with star reachability,
H. D. Tran, S. W. Choi, X. Yang, T. Yamaguchi, B. Hoxha, and D. Prokhorov, “Verification of recurrent neural networks with star reachability,” in Proceedings of the 26th ACM International Conference on Hybrid Systems: Computation and Control , 2023, pp. 1–13
2023
-
[49]
Lyapunov- stable neural-network control,
H. Dai, B. Landry, L. Yang, M. Pavone, and R. Tedrake, “Lyapunov- stable neural-network control,” arXiv preprint arXiv:2109.14152 , 2021
-
[50]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,” arXiv preprint arXiv:1412.6980 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[51]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, et al. , “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems , vol. 32, 2019
2019
-
[52]
Safety and liveness guarantees through reach-avoid reinforcement learn- ing,
K.-C. Hsu, V . Rubies-Royo, C. J. Tomlin, and J. F. Fisac, “Safety and liveness guarantees through reach-avoid reinforcement learn- ing,” arXiv preprint arXiv:2112.12288 , 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.