No Adaptation Without Observation: Observability-Constrained Test-Time Prompt Tuning for LiDAR Semantic Segmentation
Pith reviewed 2026-07-01 01:39 UTC · model grok-4.3
The pith
A geometry-constrained prompt tuning method stabilizes test-time adaptation for LiDAR semantic segmentation by estimating per-location sensing reliability to gate updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
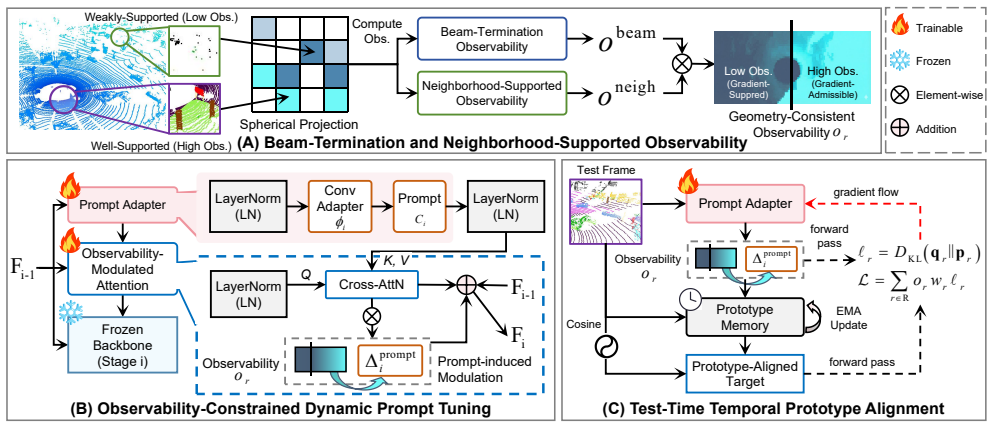
By estimating per-location sensing reliability from depth-consistent beam terminations and neighborhood support, reweighting spatial supervision, confining adaptation to prompt adapters inserted into a frozen backbone with spatial gating to shield globally shared representations, and applying temporally smoothed prototype alignment, test-time adaptation for LiDAR semantic segmentation becomes stable and effective without additional annotations.
What carries the argument
Geometry-constrained test-time prompt tuning framework that computes per-location sensing reliability to reweight supervision and apply spatial gating on prompt adapter updates.
If this is right
- Adaptation stays stable when sensing conditions evolve during online deployment.
- Segmentation accuracy rises on standard LiDAR benchmarks that include deployment shifts.
- Only lightweight prompt adapters receive updates while the backbone remains frozen.
- Unreliable spatial regions are prevented from perturbing globally shared model parameters.
Where Pith is reading between the lines
- The same reliability estimation from beam terminations and neighborhood support could be tested on camera-based or radar-based segmentation where visibility also varies spatially.
- Observability constraints of this form may generalize to other online pseudo-label settings that suffer from heteroscedastic noise, such as point cloud registration.
- If the reliability map proves accurate, it could reduce reliance on periodic full retraining for fleets of LiDAR-equipped vehicles.
Load-bearing premise
That pseudo-label reliability can be reliably estimated from depth-consistent beam terminations and neighborhood support to safely gate which regions contribute to updates.
What would settle it
An ablation on the same LiDAR benchmarks that removes or randomizes the reliability-based reweighting and spatial gating, then measures whether adaptation stability and accuracy drop under the reported deployment variations.
Figures


read the original abstract
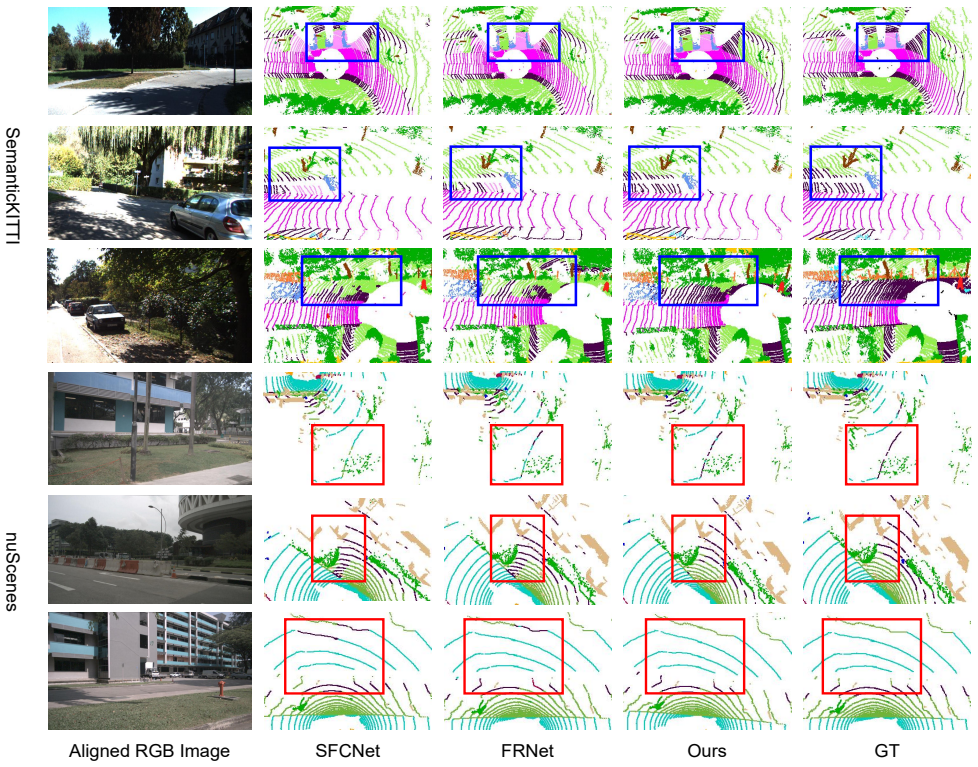
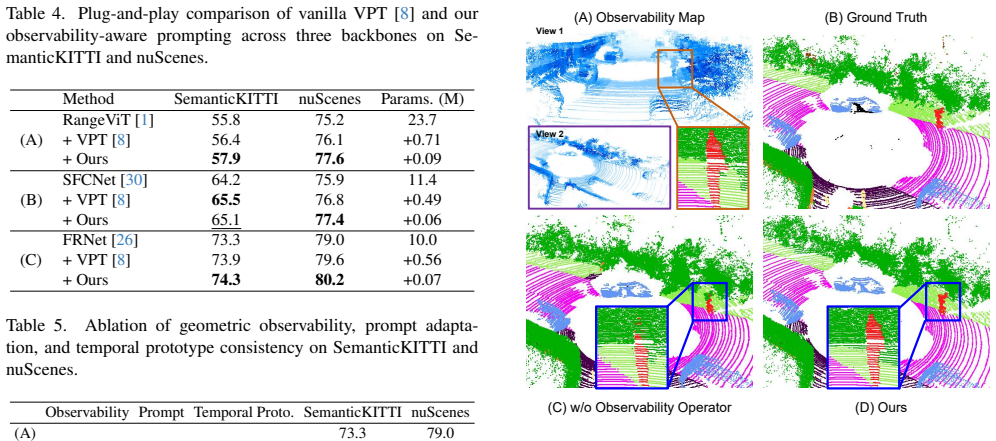
LiDAR semantic segmentation often degrades under real-world deployment due to evolving sensing conditions, while collecting new annotations for retraining is impractical. Test-time adaptation (TTA) updates model parameters online using pseudo-label supervision, but directly applying standard TTA strategies to LiDAR data is challenging. Because pseudo-label reliability is spatially heteroscedastic under range-dependent sparsity and occlusion, uniform updates on globally shared parameters can inject unstable gradients and destabilize adaptation. We propose a geometry-constrained test-time prompt tuning framework for LiDAR semantic segmentation. Our method estimates per-location sensing reliability from depth-consistent beam terminations and neighborhood support, and uses it to reweight spatial supervision. Adaptation is confined to lightweight prompt adapters inserted into a frozen backbone, with spatial gating to prevent unreliable regions from perturbing globally shared representations. A temporally smoothed prototype alignment strategy further stabilizes online updates by accumulating reliable semantic evidence over time. Experiments on standard LiDAR benchmarks demonstrate improved adaptation stability and segmentation performance under deployment variations without additional annotations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an observability-constrained test-time prompt tuning framework for LiDAR semantic segmentation. It estimates per-location sensing reliability from depth-consistent beam terminations and neighborhood support to reweight spatial supervision, confines adaptation to lightweight prompt adapters in a frozen backbone with spatial gating to avoid perturbing shared representations, and employs temporally smoothed prototype alignment for stability. Experiments on standard LiDAR benchmarks are reported to show improved adaptation stability and segmentation performance under deployment variations without additional annotations.
Significance. If the claimed improvements hold and the reliability estimator correlates with pseudo-label quality, the work would offer a practical, geometry-aware solution to a key deployment challenge in LiDAR segmentation by preventing unstable gradients from unreliable regions during online TTA. The prompt-tuning design is parameter-efficient and the spatial gating directly targets heteroscedastic reliability, which could generalize to other sparse sensing modalities.
Simulated Author's Rebuttal
We thank the referee for reviewing our manuscript and for the positive assessment of its potential significance in providing a geometry-aware solution for stable test-time adaptation in LiDAR semantic segmentation. We note that the recommendation is listed as uncertain, yet the report contains no specific major comments to address. We remain available to provide clarifications or additional experiments if requested.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an algorithmic test-time adaptation method relying on geometric observations (depth-consistent beam terminations, neighborhood support) to estimate per-location reliability for spatial reweighting and gating of prompt adapters. No equations, fitted parameters, self-citations, or uniqueness theorems are referenced in the abstract or summary that would reduce any claimed prediction or result to its own inputs by construction. The approach is presented as a sequence of independent geometric constraints and stabilization strategies whose validity is assessed via external benchmark experiments rather than internal self-definition or renaming of known patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rangevit: Towards vision transformers for 3d semantic segmentation in au- tonomous driving
Angelika Ando, Spyros Gidaris, Andrei Bursuc, Gilles Puy, Alexandre Boulch, and Renaud Marlet. Rangevit: Towards vision transformers for 3d semantic segmentation in au- tonomous driving. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5240–5250, 2023. 1, 2, 5, 6, 7, 8
2023
-
[2]
Se- mantickitti: A dataset for semantic scene understanding of lidar sequences
Jens Behley, Martin Garbade, Andres Milioto, Jan Quen- zel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. Se- mantickitti: A dataset for semantic scene understanding of lidar sequences. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 9297–9307,
-
[3]
Positioning and perception in lidar point clouds.Digital Signal Processing, 119:103193, 2021
Csaba Benedek, Andras Majdik, Balazs Nagy, Zoltan Rozsa, and Tamas Sziranyi. Positioning and perception in lidar point clouds.Digital Signal Processing, 119:103193, 2021. 4
2021
-
[4]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 1, 5
2020
-
[5]
Learning to adapt frozen clip for few-shot test-time domain adaptation
Zhixiang Chi, Li Gu, Huan Liu, Ziqiang Wang, Yanan Wu, Yang Wang, and Konstantinos Plataniotis. Learning to adapt frozen clip for few-shot test-time domain adaptation. InIn- ternational Conference on Learning Representations, pages 66359–66380, 2025. 2
2025
-
[6]
Octomap: An efficient probabilistic 3d mapping framework based on octrees.Au- tonomous robots, 34(3):189–206, 2013
Armin Hornung, Kai M Wurm, Maren Bennewitz, Cyrill Stachniss, and Wolfram Burgard. Octomap: An efficient probabilistic 3d mapping framework based on octrees.Au- tonomous robots, 34(3):189–206, 2013. 3
2013
-
[7]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023. 1
2023
-
[8]
Vi- sual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual prompt tuning. InEuropean conference on computer vision, pages 709–727. Springer, 2022. 2, 4, 7, 8
2022
-
[9]
Spherical transformer for lidar-based 3d recognition
Xin Lai, Yukang Chen, Fanbin Lu, Jianhui Liu, and Jiaya Jia. Spherical transformer for lidar-based 3d recognition. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 17545–17555, 2023. 1, 2, 5, 6
2023
-
[10]
Temporal Ensembling for Semi-Supervised Learning
Samuli Laine and Timo Aila. Temporal ensembling for semi- supervised learning.arXiv preprint arXiv:1610.02242, 2016. 5
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Tcovis: Temporally consistent online video instance seg- mentation
Junlong Li, Bingyao Yu, Yongming Rao, Jie Zhou, and Jiwen Lu. Tcovis: Temporally consistent online video instance seg- mentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1097–1107, 2023. 5
2023
-
[12]
Pre-train, prompt, and predict: A systematic survey of prompting methods in nat- ural language processing.ACM computing surveys, 55(9): 1–35, 2023
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hi- roaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in nat- ural language processing.ACM computing surveys, 55(9): 1–35, 2023. 2
2023
-
[13]
Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengx- iao Du, Zhilin Yang, and Jie Tang. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks.arXiv preprint arXiv:2110.07602, 2021. 2
-
[14]
John Wiley & Sons, 2019
Ricardo A Maronna, R Douglas Martin, Victor J Yohai, and Mat´ıas Salibi´an-Barrera.Robust statistics: theory and meth- ods (with R). John Wiley & Sons, 2019. 4
2019
-
[15]
Rangenet++: Fast and accurate lidar semantic segmentation
Andres Milioto, Ignacio Vizzo, Jens Behley, and Cyrill Stachniss. Rangenet++: Fast and accurate lidar semantic segmentation. In2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 4213–4220. IEEE, 2019. 1, 2, 3, 5, 6
2019
-
[16]
Daniel Morales-Brotons, Thijs V ogels, and Hadrien Hen- drikx. Exponential moving average of weights in deep learning: Dynamics and benefits.arXiv preprint arXiv:2411.18704, 2024. 5
-
[17]
Efficient test-time model adaptation without forgetting
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. Efficient test-time model adaptation without forgetting. InInterna- tional conference on machine learning, pages 16888–16905. PMLR, 2022. 2, 3
2022
-
[18]
Fair-vpt: Fair visual prompt tuning for image classification
Sungho Park and Hyeran Byun. Fair-vpt: Fair visual prompt tuning for image classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12268–12278, 2024. 2
2024
-
[19]
Forecasting from lidar via future object detection
Neehar Peri, Jonathon Luiten, Mengtian Li, Aljo ˇsa O ˇsep, Laura Leal-Taix ´e, and Deva Ramanan. Forecasting from lidar via future object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17202–17211, 2022. 1
2022
-
[20]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[21]
Gipso: Geometrically informed propa- gation for online adaptation in 3d lidar segmentation
Cristiano Saltori, Evgeny Krivosheev, St ´ephane Lathuili´ere, Nicu Sebe, Fabio Galasso, Giuseppe Fiameni, Elisa Ricci, and Fabio Poiesi. Gipso: Geometrically informed propa- gation for online adaptation in 3d lidar segmentation. In European Conference on Computer Vision, pages 567–585. Springer, 2022. 3, 6, 7
2022
-
[22]
Searching efficient 3d architec- tures with sparse point-voxel convolution
Haotian Tang, Zhijian Liu, Shengyu Zhao, Yujun Lin, Ji Lin, Hanrui Wang, and Song Han. Searching efficient 3d architec- tures with sparse point-voxel convolution. InEuropean con- ference on computer vision, pages 685–702. Springer, 2020. 2
2020
-
[23]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.Advances in neural information processing systems, 30, 2017
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.Advances in neural information processing systems, 30, 2017. 5
2017
-
[24]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Ol- shausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
Continual test-time domain adaptation
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. Continual test-time domain adaptation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7201–7211, 2022. 1, 3
2022
-
[26]
Frnet: Frustum-range networks for scalable lidar segmenta- tion.IEEE Transactions on Image Processing, 2025
Xiang Xu, Lingdong Kong, Hui Shuai, and Qingshan Liu. Frnet: Frustum-range networks for scalable lidar segmenta- tion.IEEE Transactions on Image Processing, 2025. 1, 2, 3, 5, 6, 7, 8
2025
-
[27]
Prompt tuning for generative multimodal pretrained models.arXiv preprint arXiv:2208.02532, 2022
Hao Yang, Junyang Lin, An Yang, Peng Wang, Chang Zhou, and Hongxia Yang. Prompt tuning for generative multimodal pretrained models.arXiv preprint arXiv:2208.02532, 2022. 2, 4
-
[28]
Lidarmultinet: Towards a unified multi-task network for lidar perception
Dongqiangzi Ye, Zixiang Zhou, Weijia Chen, Yufei Xie, Yu Wang, Panqu Wang, and Hassan Foroosh. Lidarmultinet: Towards a unified multi-task network for lidar perception. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 3231–3240, 2023. 1
2023
-
[29]
Polarnet: An improved grid representation for online lidar point clouds se- mantic segmentation
Yang Zhang, Zixiang Zhou, Philip David, Xiangyu Yue, Ze- rong Xi, Boqing Gong, and Hassan Foroosh. Polarnet: An improved grid representation for online lidar point clouds se- mantic segmentation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9601–9610, 2020. 1, 2, 5, 6
2020
-
[30]
Spherical frustum sparse con- volution network for lidar point cloud semantic segmenta- tion.Advances in Neural Information Processing Systems, 37:121827–121858, 2024
Yu Zheng, Guangming Wang, Jiuming Liu, Marc Polle- feys, and Hesheng Wang. Spherical frustum sparse con- volution network for lidar point cloud semantic segmenta- tion.Advances in Neural Information Processing Systems, 37:121827–121858, 2024. 1, 2, 5, 6, 7, 8
2024
-
[31]
Conditional prompt learning for vision-language mod- els
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language mod- els. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 16816–16825,
-
[32]
Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[33]
Dynamic adapter meets prompt tuning: Parameter-efficient transfer learning for point cloud analysis
Xin Zhou, Dingkang Liang, Wei Xu, Xingkui Zhu, Yihan Xu, Zhikang Zou, and Xiang Bai. Dynamic adapter meets prompt tuning: Parameter-efficient transfer learning for point cloud analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14707– 14717, 2024. 2
2024
-
[34]
Cylindrical and asymmetrical 3d convolution networks for lidar-based perception.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 44(10):6807–6822, 2021
Xinge Zhu, Hui Zhou, Tai Wang, Fangzhou Hong, Wei Li, Yuexin Ma, Hongsheng Li, Ruigang Yang, and Dahua Lin. Cylindrical and asymmetrical 3d convolution networks for lidar-based perception.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 44(10):6807–6822, 2021. 1, 2, 5, 6
2021
-
[35]
Hgl: Hierarchical geometry learning for test-time adaptation in 3d point cloud segmentation
Tianpei Zou, Sanqing Qu, Zhijun Li, Alois Knoll, Lianghua He, Guang Chen, and Changjun Jiang. Hgl: Hierarchical geometry learning for test-time adaptation in 3d point cloud segmentation. InEuropean Conference on Computer Vision, pages 19–36. Springer, 2024. 3, 6, 7 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.