Revealing Safety-Critical Scenarios for UTM via Transformer
Pith reviewed 2026-07-01 06:00 UTC · model grok-4.3
The pith
Transformer-based RL frames UTM vulnerability discovery as sequence modeling to generate safety-critical test scenarios
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
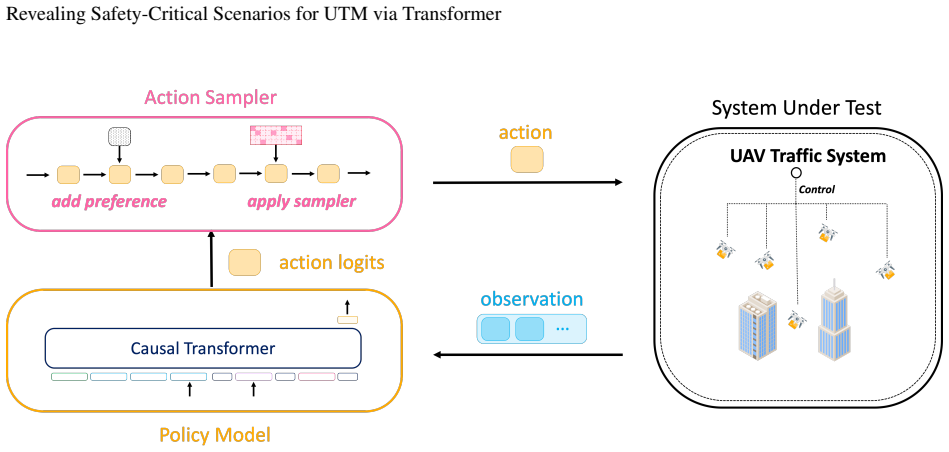
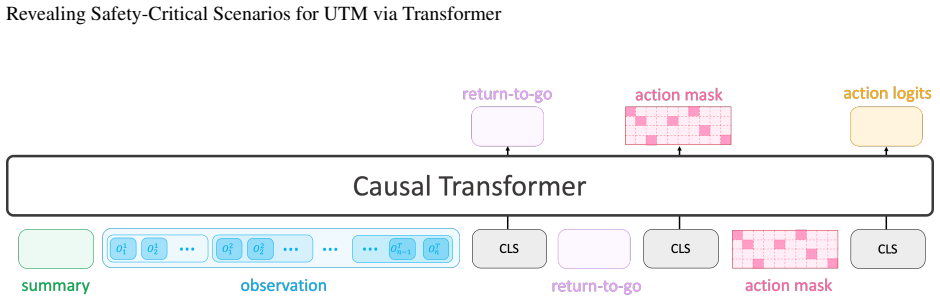
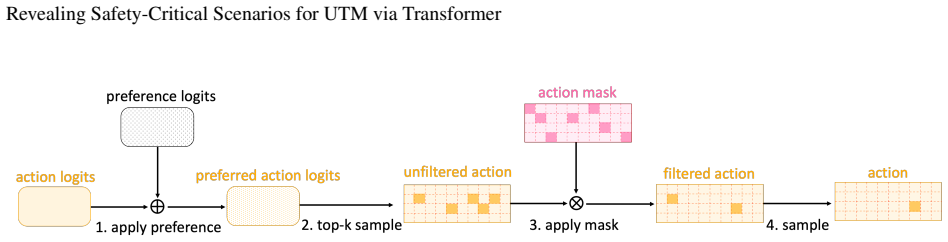
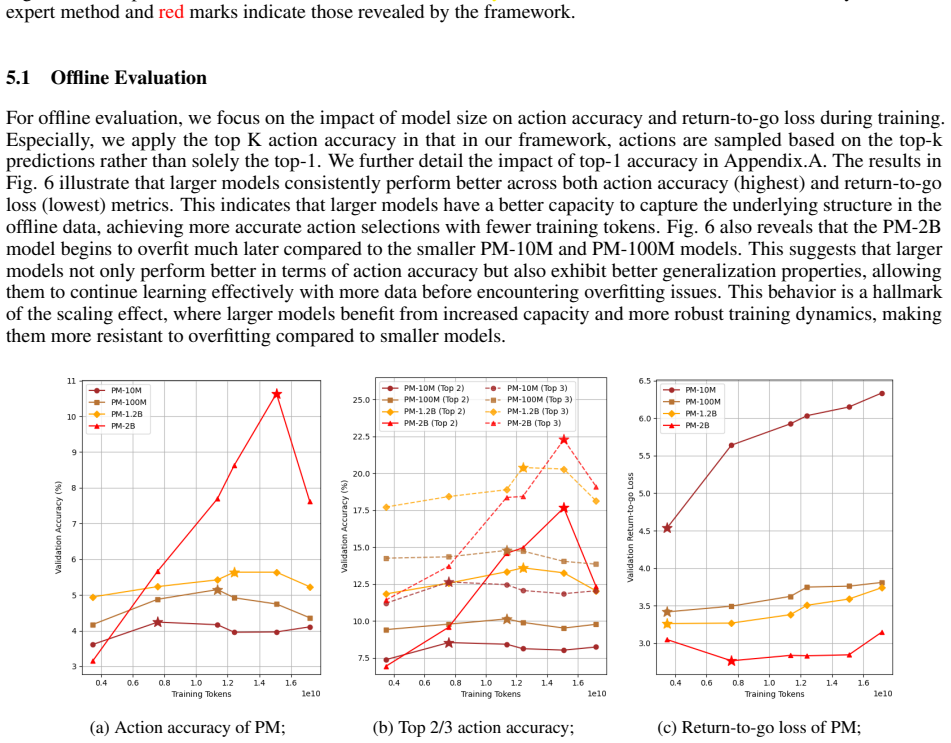
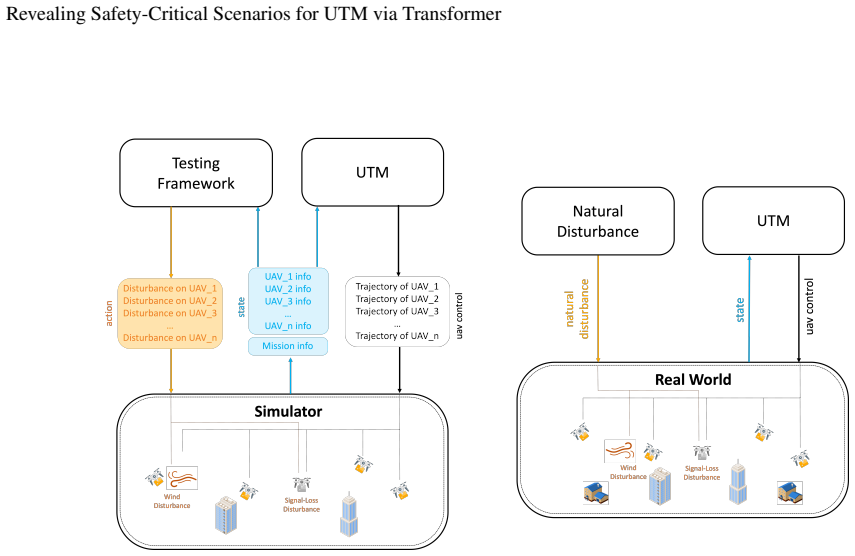
Framing UTM vulnerability discovery as a sequence modeling problem, the transformer-based RL architecture uses attention mechanisms to directly model relationships among system states and predict optimal actions, with a Policy Model generating targeted test scenarios and an Action Sampler enforcing domain constraints under a risk-based reward function, achieving an 8 imes improvement in vulnerability discovery efficiency compared to expert-guided testing in 700-hour simulations while also discovering critical edge cases that traditional methods have missed.
What carries the argument
Transformer attention mechanisms in RL that directly model relationships among system states to predict optimal actions for generating test scenarios
If this is right
- Vulnerability discovery efficiency improves by a factor of 8 compared to expert-guided testing.
- Critical edge cases missed by traditional methods are revealed through attention-based exploration.
- The long-tail effect of critical failures due to UTM self-healing is addressed by the risk-based reward guidance.
Where Pith is reading between the lines
- The sequence modeling approach could extend to testing other remote vehicle coordination platforms.
- Discovered scenarios might serve as training data to improve UTM self-healing policies.
- Integration with real-time monitoring could allow ongoing vulnerability scanning in deployed systems.
Load-bearing premise
The scenarios identified in the 700-hour simulation correspond to genuine safety-critical failures that would occur in real deployed UTM systems rather than simulation artifacts.
What would settle it
Running the discovered scenarios on a live operational UTM platform and checking whether they produce the predicted failures such as collisions or crashes.
Figures

read the original abstract
Unmanned Traffic Management (UTM) systems are cloud-based platforms designed to manage and coordinate multiple aerial vehicles remotely. UTM systems are safety-critical which cannot tolerate failures like crash or collision. To reveal latent vulnerabilities, there are neither optimal failure-exposing demonstrations nor clear reward signals. Additionally, UTM's self-healing capability introduces the ``long-tail effect'' of critical failures. We propose framing UTM vulnerability discovery as a sequence modeling problem amenable to transformer-based RL architectures. Our approach leverages attention mechanisms to directly model the relationship among system states, and predict optimal actions. Our framework introduces a Policy Model that generates targeted test scenarios and an Action Sampler that enforces domain constraints. We use a risk-based reward function to guide exploration. Through extensive evaluation on a 700-hour simulation study, we demonstrate an 8$\times$ improvement in vulnerability discovery efficiency compared to expert-guided testing. It also discovers critical edge cases that traditional methods have missed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames UTM vulnerability discovery as a sequence modeling task and proposes a transformer-based RL architecture consisting of a Policy Model that generates test scenarios and an Action Sampler that enforces domain constraints, guided by a risk-based reward function. It reports results from a 700-hour simulation study claiming an 8× improvement in vulnerability discovery efficiency over expert-guided testing and the discovery of critical edge cases missed by traditional methods.
Significance. If the simulation results are shown to generalize beyond the specific simulator and the risk-based reward is demonstrated to surface genuine operational failures rather than artifacts, the work could provide a useful automated method for exposing rare long-tail failure modes in safety-critical UTM systems. The use of attention mechanisms to model state-action relationships is a reasonable technical choice for this domain.
major comments (2)
- [Abstract] Abstract: the central empirical claim of an 8× improvement in vulnerability discovery efficiency is stated without any description of the expert-guided baseline, the precise definition or parameterization of the risk-based reward function, the metric used for efficiency (e.g., vulnerabilities per simulated hour), or any statistical tests. These omissions make the primary result impossible to assess or reproduce.
- [Abstract] Abstract: the evaluation rests entirely on a 700-hour simulation study, yet no evidence, fidelity metrics, or comparison to real UTM deployments is supplied to show that the simulator's self-healing dynamics and failure modes correspond to operational systems rather than simulator-specific artifacts. This directly undermines the claim that discovered scenarios are safety-critical in practice.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of an 8× improvement in vulnerability discovery efficiency is stated without any description of the expert-guided baseline, the precise definition or parameterization of the risk-based reward function, the metric used for efficiency (e.g., vulnerabilities per simulated hour), or any statistical tests. These omissions make the primary result impossible to assess or reproduce.
Authors: We agree that the abstract is too concise and omits key details needed for assessment. In the revised manuscript, we will expand the abstract to include: the expert-guided baseline as manual test scenario generation by UTM domain experts following standard procedures; the risk-based reward function as a weighted sum of proximity to collision thresholds, violation of separation minima, and recovery time, with specific parameterization provided in Section 3.3; the efficiency metric defined as unique vulnerabilities discovered per 100 simulated hours; and a note that the 8× improvement was statistically significant (p<0.01 via paired t-test across 10 independent runs). Full definitions and statistical analysis remain in the methods and results sections. revision: yes
-
Referee: [Abstract] Abstract: the evaluation rests entirely on a 700-hour simulation study, yet no evidence, fidelity metrics, or comparison to real UTM deployments is supplied to show that the simulator's self-healing dynamics and failure modes correspond to operational systems rather than simulator-specific artifacts. This directly undermines the claim that discovered scenarios are safety-critical in practice.
Authors: We acknowledge that the evaluation is simulation-only and no direct fidelity metrics or real-deployment comparisons are provided in the current manuscript. We have added a dedicated limitations subsection (Section 5.3) describing how the simulator was constructed to replicate UTM self-healing dynamics and failure modes based on published UTM standards, domain-expert input, and publicly available operational guidelines. Claims have been revised to specify that scenarios are safety-critical within the modeled environment. Direct validation against live operational systems is not feasible in this work due to regulatory and data-access constraints. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description frame the work as an empirical evaluation: a transformer-based RL policy with risk-based reward is run in a 700-hour simulation to measure 8× improvement over expert-guided testing. No equations, parameter-fitting steps, self-citations, or uniqueness theorems are quoted that would reduce the reported efficiency gain or discovered edge cases to inputs by construction. The central claim rests on simulation outcomes compared to an external baseline, which is self-contained and does not match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- risk-based reward parameters
axioms (1)
- domain assumption UTM systems exhibit a long-tail effect of critical failures due to self-healing capability
Reference graph
Works this paper leans on
-
[1]
Mosat: Finding safety violations of autonomous driving systems using multi-objective genetic algorithm
Haoxiang Tian, Yan Jiang, Guoquan Wu, Jiren Yan, Jun Wei, Wei Chen, Shuo Li, and Dan Ye. Mosat: Finding safety violations of autonomous driving systems using multi-objective genetic algorithm. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, pages 94–106, ...
2022
-
[2]
Association for Computing Machinery. ISBN 978-1-4503-9413-0. doi: 10.1145/3540250.3549100. Ziyuan Zhong, Yun Tang, Yuan Zhou, Vania de Oliveira Neves, Yang Liu, and Baishakhi Ray. A survey on scenario- based testing for automated driving systems in high-fidelity simulation, December
-
[3]
Gladence, V
L. Gladence, V . Anu, A. Anderson, Immanuel Stanley, Jithin Abhishek Fernando J, and S. Revathy. Swarm Intelligence in Disaster Recovery.2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS), pages 1–8,
2021
-
[4]
Wedad Alawad, Nadhir Ben Halima, and Layla Aziz
doi: 10.1109/ICICCS51141.2021.9432146. Wedad Alawad, Nadhir Ben Halima, and Layla Aziz. An Unmanned Aerial Vehicle (UA V) System for Disaster and Crisis Management in Smart Cities.Electronics,
-
[5]
Decision Transformer: Reinforcement Learning via Sequence Modeling
doi: 10.3390/electronics12041051. Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling.arXiv preprint arXiv:2106.01345,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3390/electronics12041051
-
[6]
ISBN 978-1-55860-707-1
Morgan Kaufmann Publishers Inc. ISBN 978-1-55860-707-1. Brian D Ziebart, Andrew Maas, J Andrew Bagnell, and Anind K Dey. Maximum Entropy Inverse Reinforcement Learning. InProceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008), 1433-1438,
2008
-
[7]
URLhttp://arxiv.org/abs/1803.10122. Ritchie Lee, Mykel J. Kochenderfer, Ole J. Mengshoel, Guillaume P. Brat, and Michael P. Owen. Adaptive stress testing of airborne collision avoidance systems. In2015 IEEE/AIAA 34th Digital Avionics Systems Conference (DASC), pages 6C2–1–6C2–13,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
doi: 10.1109/DASC.2015.7311450. URL https://ieeexplore.ieee. org/document/7311450. Jun Liu and Necmiye Ozay. Abstraction, discretization, and robustness in temporal logic control of dynamical systems. InProceedings of the 17th International Conference on Hybrid Systems: Computation and Control, HSCC ’14, pages 293–302. Association for Computing Machinery,
-
[9]
ISBN 978-1-4503-2732-9. doi: 10.1145/2562059.2562137. URLhttps://doi.org/10.1145/2562059.2562137. David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. A general reinforcement learning algorithm th...
-
[10]
URLhttps://www.science.org/doi/10.1126/science.aar6404
doi: 10.1126/science.aar6404. URLhttps://www.science.org/doi/10.1126/science.aar6404. Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-Attention with Relative Position Representations. In Marilyn Walker, Heng Ji, and Amanda Stent, editors,Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics...
-
[11]
Anastasiia Klimashevskaia, Dietmar Jannach, Mehdi Elahi, and Christoph Trattner
doi: 10.18653/v1/N18-2074. Anastasiia Klimashevskaia, Dietmar Jannach, Mehdi Elahi, and Christoph Trattner. A survey on popularity bias in recommender systems.User Modeling and User-Adapted Interaction, July
-
[12]
doi: 10.1007/s11257-024-09406-0
ISSN 1573-1391. doi: 10.1007/s11257-024-09406-0. URLhttp://dx.doi.org/10.1007/s11257-024-09406-0. Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. InInternational Conference on Learning Representations,
-
[13]
Konstantinos Spalas. Towards the unmanned aerial vehicle traffic management systems (utms): Security risks and challenges.arXiv preprint arXiv:2408.11125,
-
[14]
Language Models are Few-Shot Learners
Tom B Brown. Language models are few-shot learners.arXiv preprint arXiv:2005.14165,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[15]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[17]
When should we prefer decision transformers for offline reinforcement learning? InThe Twelfth International Conference on Learning Representations, October 2023b
Prajjwal Bhargava, Rohan Chitnis, Alborz Geramifard, Shagun Sodhani, and Amy Zhang. When should we prefer decision transformers for offline reinforcement learning? InThe Twelfth International Conference on Learning Representations, October 2023b. A UTM System Architecture and Testing Pipeline What is Unmanned aircraft Traffic Management (UTM) system?The U...
2014
-
[18]
Internal functionality and and robustness of on-device system of individual UA V is out of the scope of this research. Sim vs RealThe framework’s methodology emphasizes systematic exploration of edge cases and rare failure modes that might otherwise remain undiscovered in conventional testing approaches. Environmental disturbances suffer 13 Revealing Safe...
2024
-
[19]
influenced by both its historical states and the temporal evolution of other agents’ states in the shared airspace
The behavioral trajectory of each UA V is intrinsically 14 Revealing Safety-Critical Scenarios for UTM via Transformer Types Number of Influenced UA Vs Disturbance Times within 60s Case Example Real-World Ratio Complexity Safe Flight 0 0 N/A∼94% Low Disturbances 1 1 Winds with exceeding magnitude∼5% Medium ≥21 (each) Winds hit multiple UA Vs∼1% Medium 1≥2...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.