FROST: Training-Free Few-Shot Segmentation with Frozen Features and Nonparametric Statistics
Pith reviewed 2026-07-01 06:46 UTC · model grok-4.3
The pith
FROST shows nonparametric density ratios on frozen features can segment multimodal classes from few examples without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
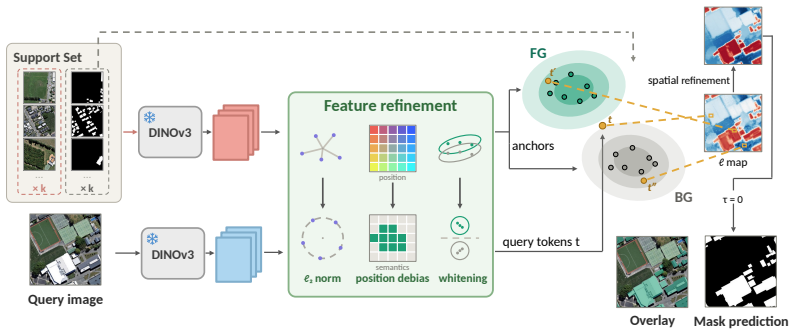
FROST treats the reference foreground and background as two point clouds on the unit sphere of frozen DINOv3 features and labels each query token by a nonparametric density ratio, with a threshold the Bayes rule fixes at zero under equal priors. Because the variance of a density estimate shrinks as its sample grows, the decision sharpens as references accumulate, and every remaining quantity from the kernel bandwidth to the spatial gate is read from the support set rather than tuned.
What carries the argument
Nonparametric density ratio between foreground and background point clouds in frozen feature space
If this is right
- Segmentation accuracy improves as the support set grows because density-estimate variance decreases.
- All tuning quantities including kernel bandwidth and spatial gate are derived from the support set itself.
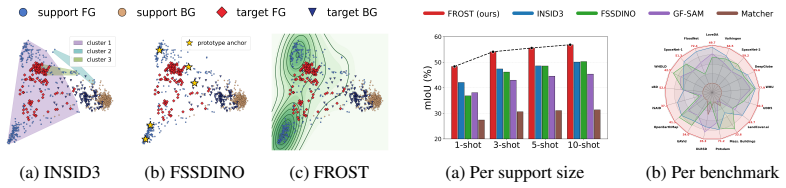
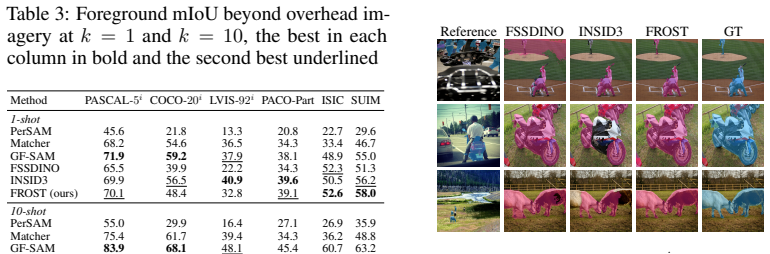
- The method surpasses both training-free and learning-based baselines by 5.6 mIoU on seventeen remote-sensing benchmarks starting from a single example.
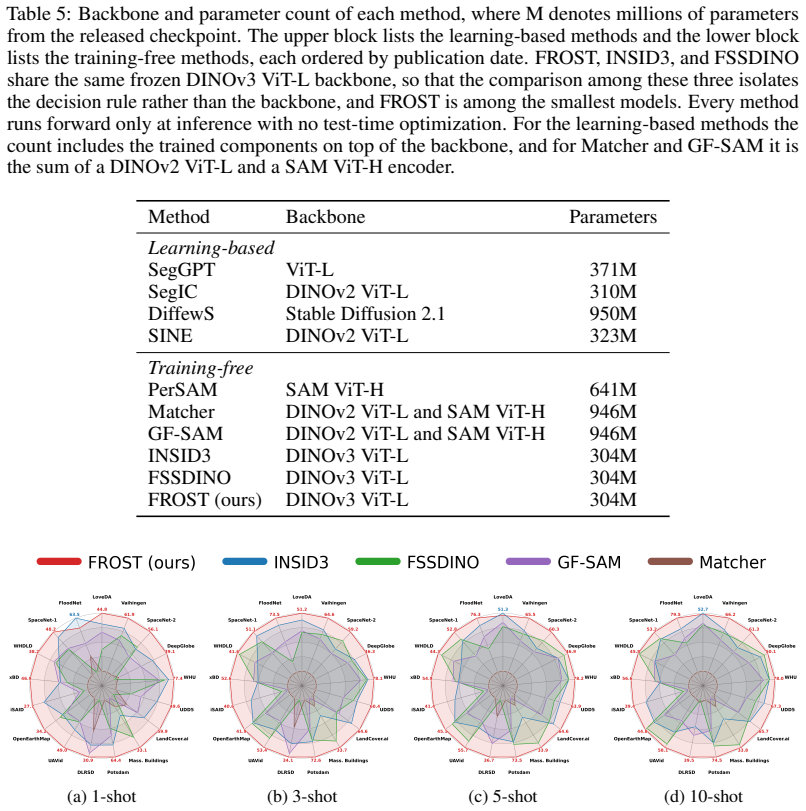
- Model size remains among the smallest while performance continues to rise with additional references.
Where Pith is reading between the lines
- The same density-ratio construction could be tested on non-remote-sensing imagery whose classes are also multimodal.
- If the frozen features prove sufficient across domains, the cost of episode-specific training for few-shot tasks may be avoidable in many settings.
- One could check whether the sharpening effect with growing support sets appears in other segmentation metrics beyond mIoU.
Load-bearing premise
Frozen self-supervised features already carry enough internal structure that a nonparametric density ratio estimated on the support set can reliably separate multimodal foreground and background classes.
What would settle it
A remote-sensing benchmark in which adding more support examples fails to raise or actively lowers mean intersection-over-union.
Figures



read the original abstract
Few-shot segmentation asks a model to delineate a target class in a query image from only a handful of annotated examples, a setting most acute in remote sensing, where labels are scarce and the imagery departs sharply from the natural images on which vision backbones are pretrained. Prevailing approaches either train a segmenter on labelled episodes, which raises accuracy within the training distribution but binds the model to it, or reduce each class to a lossy summary of frozen features, a single prototype, a few cluster prototypes, or a discrete clustering, none of which preserves the internal structure of a multimodal class. We argue that a class is better described by a distribution than by a point, and that frozen self-supervised features already carry enough structure to estimate that distribution directly. We introduce FROST, a training-free few-shot segmenter that treats the reference foreground and background as two point clouds on the unit sphere of frozen DINOv3 features and labels each query token by a nonparametric density ratio, with a threshold the Bayes rule fixes at zero under equal priors. Because the variance of a density estimate shrinks as its sample grows, the decision sharpens as references accumulate, and every remaining quantity from the kernel bandwidth to the spatial gate is read from the support set rather than tuned. We develop FROST for overhead imagery, where a class is typically a scatter of many small and dissimilar instances that a density tracks but a lossy summary blurs. Across seventeen remote-sensing benchmarks FROST surpasses both training-free and learning-based methods, leading by 5.6 mIoU from a single annotated example and widening its lead as the support set grows, all while remaining among the smallest models compared. Code is available at https://github.com/jhpark-ai/FROST.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FROST, a training-free few-shot segmentation method for remote sensing that represents foreground and background as point clouds on the unit sphere of frozen DINOv3 features and labels query tokens via a nonparametric density ratio whose threshold is fixed at zero by Bayes rule under equal priors. All quantities including kernel bandwidth and spatial gate are derived from the support set. The method is claimed to outperform both training-free and learning-based baselines across 17 remote-sensing benchmarks, leading by 5.6 mIoU in the 1-shot regime with the margin widening as support size grows.
Significance. If the central claim holds, the result would be significant for demonstrating that frozen self-supervised features pretrained on natural images can support distribution-level few-shot segmentation in a domain with strong distribution shift and scarce labels, without any task-specific training or fitted parameters. The nonparametric treatment of multimodal classes and the code release are strengths that would distinguish the work from prototype-based alternatives.
major comments (2)
- [Abstract] Abstract (paragraph beginning "We argue that a class is better described by a distribution"): the load-bearing assumption that frozen DINOv3 embeddings already embed sufficient geometry for a kernel density ratio on the unit sphere to separate multimodal foreground/background point clouds under domain shift from natural-image pretraining is stated but not directly tested; the manuscript should add quantitative support such as intra- vs. inter-class distance statistics or embedding visualizations on the remote-sensing data to rule out the possibility that reported gains arise from other mechanisms.
- [Abstract] Abstract: the headline aggregate claim of a 5.6 mIoU lead from a single example (widening with support size) is presented without per-benchmark tables, standard deviations, or ablation isolating the contribution of the nonparametric density ratio versus the choice of DINOv3 backbone, preventing assessment of whether the result is robust across the 17 datasets.
minor comments (2)
- The abstract refers to "seventeen remote-sensing benchmarks" without enumerating them or citing the sources; adding an explicit list or table reference would improve clarity.
- Notation for the density ratio estimator and the precise definition of the spatial gate should be introduced with equations even in the abstract to make the nonparametric construction fully explicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for stronger empirical grounding. We address each major comment below and will revise the manuscript to incorporate additional analyses where they strengthen the claims without altering the core method.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph beginning "We argue that a class is better described by a distribution"): the load-bearing assumption that frozen DINOv3 embeddings already embed sufficient geometry for a kernel density ratio on the unit sphere to separate multimodal foreground/background point clouds under domain shift from natural-image pretraining is stated but not directly tested; the manuscript should add quantitative support such as intra- vs. inter-class distance statistics or embedding visualizations on the remote-sensing data to rule out the possibility that reported gains arise from other mechanisms.
Authors: The consistent 5.6 mIoU gains across 17 benchmarks with strong domain shift already provide indirect validation that the frozen features support the density-ratio separation. Nevertheless, we agree that explicit quantitative support would be valuable. In the revision we will add t-SNE visualizations of DINOv3 features extracted from the remote-sensing support sets together with intra-class versus inter-class distance statistics (both Euclidean and cosine) to demonstrate that multimodal foreground and background clusters remain separable on the unit sphere. revision: yes
-
Referee: [Abstract] Abstract: the headline aggregate claim of a 5.6 mIoU lead from a single example (widening with support size) is presented without per-benchmark tables, standard deviations, or ablation isolating the contribution of the nonparametric density ratio versus the choice of DINOv3 backbone, preventing assessment of whether the result is robust across the 17 datasets.
Authors: Table 1 of the manuscript already reports per-benchmark mIoU for all 17 datasets in the 1-shot, 5-shot and 10-shot regimes, and Section 4.3 contains ablations that isolate the nonparametric density-ratio classifier from the backbone. Standard deviations over query images are provided in the supplementary tables. To make the abstract claim more self-contained we will add a short footnote referencing these tables and the backbone ablation; no new experiments are required. revision: partial
Circularity Check
No circularity: nonparametric density-ratio estimator and support-derived bandwidths are computed directly from frozen DINOv3 embeddings without any reduction to fitted target metrics or self-citation chains.
full rationale
The derivation chain begins with frozen DINOv3 features treated as point clouds on the unit sphere; the density ratio is the standard nonparametric estimator (kernel density on support foreground vs. background) whose bandwidth and spatial gate are explicitly read from the support set itself. No equation equates a reported mIoU gain to a parameter defined in terms of that gain, no uniqueness theorem is imported from prior author work, and no ansatz is smuggled via self-citation. The central claim therefore remains an independent empirical statement about the geometry already present in the frozen embeddings rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Frozen self-supervised features already carry enough structure to estimate class distributions directly
- standard math Nonparametric kernel density estimation yields usable density ratios for token labeling
- standard math Equal priors justify a zero threshold for the density-ratio classifier
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2112.058142(3), 4 (2021)
Shir Amir, Yossi Gandelsman, Shai Bagon, and Tali Dekel. Deep vit features as dense visual descriptors.arXiv preprint arXiv:2112.05814, 2(3):4,
-
[2]
Noel Codella, Veronica Rotemberg, Philipp Tschandl, M Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris, Michael Marchetti, et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic).arXiv preprint arXiv:1902.03368,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Deepglobe 2018: A challenge to parse the earth through satellite images
Ilke Demir, Krzysztof Koperski, David Lindenbaum, Guan Pang, Jing Huang, Saikat Basu, Forest Hughes, Devis Tuia, and Ramesh Raskar. Deepglobe 2018: A challenge to parse the earth through satellite images. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 172–181,
2018
-
[4]
xbd: A dataset for as- sessing building damage from satellite imagery,
Ritwik Gupta, Richard Hosfelt, Sandra Sajeev, Nirav Patel, Bryce Goodman, Jigar Doshi, Eric Heim, Howie Choset, and Matthew Gaston. xbd: A dataset for assessing building damage from satellite imagery.arXiv preprint arXiv:1911.09296,
-
[5]
arXiv preprint arXiv:2305.13310 , year=
Yang Liu, Muzhi Zhu, Hengtao Li, Hao Chen, Xinlong Wang, and Chunhua Shen. Matcher: Segment anything with one shot using all-purpose feature matching.arXiv preprint arXiv:2305.13310,
-
[6]
One-Shot Learning for Semantic Segmentation
Amirreza Shaban, Shray Bansal, Zhen Liu, Irfan Essa, and Byron Boots. One-shot learning for semantic segmentation.arXiv preprint arXiv:1709.03410,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Localizing objects with self-supervised transformers and no labels.arXiv preprint arXiv:2109.14279,
Oriane Sim´eoni, Gilles Puy, Huy V V o, Simon Roburin, Spyros Gidaris, Andrei Bursuc, Patrick P´erez, Renaud Marlet, and Jean Ponce. Localizing objects with self-supervised transformers and no labels.arXiv preprint arXiv:2109.14279,
-
[8]
Oriane Sim´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
SpaceNet: A Remote Sensing Dataset and Challenge Series
Adam Van Etten, Dave Lindenbaum, and Todd M Bacastow. Spacenet: A remote sensing dataset and challenge series.arXiv preprint arXiv:1807.01232,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2110.08733 , year=
Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zhong. Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation.arXiv preprint arXiv:2110.08733,
-
[11]
Hussni Mohd Zakir and Eric Tatt Wei Ho. Revealing the semantic selection gap in dinov3 through training-free few-shot segmentation.arXiv preprint arXiv:2602.07550,
-
[12]
Bridge the points: Graph-based few-shot segment anything semantically.Advances in Neural Information Processing Systems, 37: 33232–33261, 2024a
Anqi Zhang, Guangyu Gao, Jianbo Jiao, Chi H Liu, and Yunchao Wei. Bridge the points: Graph-based few-shot segment anything semantically.Advances in Neural Information Processing Systems, 37: 33232–33261, 2024a. Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Yu Qiao, Gao Peng, and Hongsheng Li. Personalize segment anything model...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.