AC3S: Adaptive Conditioning for 3D-Aware Synthetic Data Generation
Pith reviewed 2026-07-01 06:11 UTC · model grok-4.3
The pith
AC3S introduces a self-supervised modulator that dynamically adjusts ControlNet conditioning strength to prevent over-conditioning in diffusion-based 3D synthetic image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
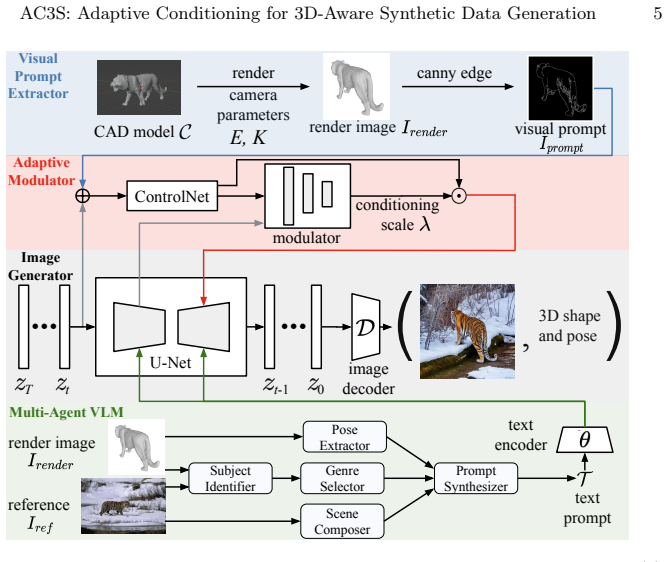
AC3S is a diffusion pipeline that enforces 3D structural alignment while preserving photorealism through adaptive conditioning. Its central component is a self-supervised visual prompt modulator that dynamically adjusts ControlNet conditioning strength, preventing over-conditioning and letting the diffusion model retain generative expressiveness. This is paired with a multi-agent vision-language model that composes detailed, 3D-aware prompts consistent with the geometric structure, enabling scalable production of high-quality synthetic datasets with reliable 2D and 3D annotations.
What carries the argument
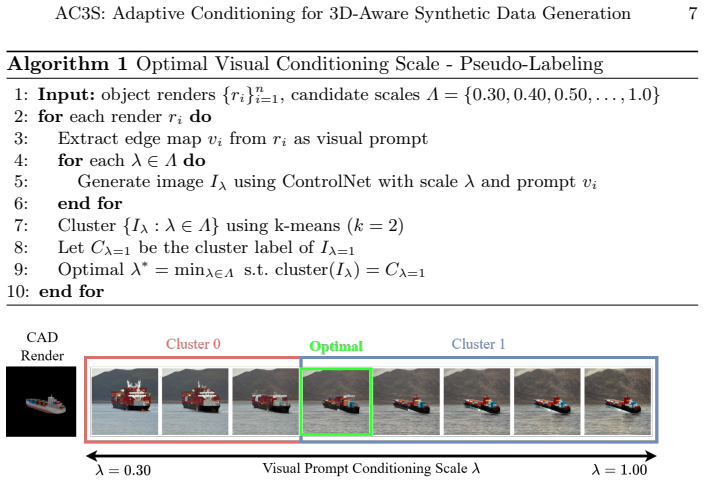
The self-supervised visual prompt modulator, which detects over-conditioning signals and scales the strength of ControlNet conditioning on the fly.
If this is right
- Synthetic datasets generated this way carry both accurate 2D and 3D annotations at scale.
- The diffusion model retains more of its generative diversity instead of being locked to the prompt.
- Downstream computer vision models trained on the output show measurable gains in performance.
- The same conditioning adjustment principle applies to other visual prompt types beyond edge maps.
Where Pith is reading between the lines
- The modulator design could transfer to other conditional generators where prompt strength needs automatic balancing.
- Combining the modulator with video or multi-view consistency losses might extend the method to 3D-consistent video synthesis.
- The multi-agent prompt composer could be tested on domains outside object-centric scenes to check generality.
Load-bearing premise
A self-supervised modulator can reliably detect and correct over-conditioning in real time without adding new artifacts or breaking the intended 3D geometric alignment.
What would settle it
An ablation that removes the modulator and measures whether image quality metrics and 3D alignment errors improve or worsen compared with the full AC3S pipeline.
Figures


read the original abstract
Synthetic data generation has emerged as a powerful tool for improving data scalability in computer vision. Recent diffusion-based pipelines have demonstrated strong photorealism. However, how to enforce precise 3D structure and pose consistency in generated images remains challenging. Existing methods leverage visual prompts such as edge maps to guide diffusion models, but often suffer from over-conditioning artifacts that degrade image realism and limit dataset quality. In this paper, we present a diffusion-based image generation framework that enforces 3D structural alignment while preserving photorealism through adaptive conditioning. Our framework, Adaptive Conditioning for 3D-Aware Synthetic Data Generation (AC3S), introduces a self-supervised visual prompt modulator that dynamically adjusts the strength of ControlNet conditioning, preventing over-conditioning and enabling the diffusion model to retain its generative expressiveness. To further enhance diversity and semantic consistency, we develop a multi-agent vision language model framework that composes detailed and 3D-aware prompts aligned with the underlying geometric structure. Together, these components enable the scalable generation of high-quality synthetic datasets with accurate 2D and 3D annotations. Extensive experiments demonstrate that our method significantly improves image quality and downstream utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AC3S, a diffusion-based framework for generating 3D-aware synthetic images. It introduces a self-supervised visual prompt modulator that dynamically scales ControlNet conditioning strength to avoid over-conditioning artifacts while retaining generative expressiveness, paired with a multi-agent VLM prompt composer for semantic and geometric consistency, enabling scalable production of annotated synthetic datasets.
Significance. If the modulator reliably detects and corrects over-conditioning without introducing artifacts or compromising 3D geometric fidelity, the approach could meaningfully improve the quality and utility of synthetic data for downstream 3D-aware computer vision tasks such as pose estimation and reconstruction.
major comments (2)
- [Abstract / §3] Abstract and §3 (method description): the central claim rests on the self-supervised modulator dynamically adjusting ControlNet strength, yet no architecture, detection signal, loss, or training procedure for this component is specified, leaving the assumption that it corrects over-conditioning without artifacts or alignment drift unverified and load-bearing.
- [§4] §4 (experiments): no ablation studies, quantitative metrics on conditioning strength, or error analysis are referenced to demonstrate that the modulator preserves photorealism and 3D alignment relative to baselines; without these, the headline improvement in image quality and downstream utility cannot be assessed.
minor comments (2)
- [§3] Notation for the modulator output (e.g., scaling factor) should be defined explicitly when first introduced.
- [§3.2] The multi-agent VLM prompt composer would benefit from a diagram showing agent roles and information flow.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestions. We address each major comment below and commit to revisions that directly strengthen the manuscript's clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method description): the central claim rests on the self-supervised modulator dynamically adjusting ControlNet strength, yet no architecture, detection signal, loss, or training procedure for this component is specified, leaving the assumption that it corrects over-conditioning without artifacts or alignment drift unverified and load-bearing.
Authors: We agree that §3 does not provide sufficient implementation detail on the self-supervised visual prompt modulator. In the revised manuscript we will add an explicit architecture diagram, the precise detection signal (e.g., feature divergence or reconstruction error), the training loss, and the full self-supervised training procedure. These additions will make the mechanism verifiable and remove the load-bearing assumption. revision: yes
-
Referee: [§4] §4 (experiments): no ablation studies, quantitative metrics on conditioning strength, or error analysis are referenced to demonstrate that the modulator preserves photorealism and 3D alignment relative to baselines; without these, the headline improvement in image quality and downstream utility cannot be assessed.
Authors: We acknowledge that the current experimental section lacks the requested ablations and metrics. The revised version will include (i) ablations isolating the modulator, (ii) quantitative plots of image quality (FID, LPIPS) and 3D alignment error versus conditioning strength, and (iii) error analysis against ControlNet baselines. These results will be added to §4 and the supplementary material. revision: yes
Circularity Check
No circularity: claims are architectural descriptions without equations or self-referential reductions
full rationale
The abstract and available text describe an AC3S framework with a self-supervised visual prompt modulator and multi-agent VLM prompt composer, but supply no equations, loss functions, derivation steps, or self-citations. No load-bearing claim reduces a prediction to a fitted input by construction, nor imports uniqueness from prior author work, nor renames a known result. The self-supervised label is stated as a design choice rather than a circular fit; without visible math or training details that close on the same data, the derivation chain (such as it is) remains self-contained and externally falsifiable via downstream experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Bordes, F., Pang, R.Y., Ajay, A., Li, A.C., Bardes, A., Petryk, S., Mañas, O., Lin, Z., Mahmoud, A., Jayaraman, B., et al.: An introduction to vision-language modeling. arXiv preprint arXiv:2405.17247 (2024)
-
[3]
Canny,J.:Acomputationalapproachtoedgedetection.TPAMIpp.679–698(2009)
2009
-
[4]
Cao, W., Zhang, H., Tang, J., Wu, Y., Li, Y., Yu, N., Wang, S., Liu, Y.: Redirect4d- bench: A scalable benchmark for camera redirection of monocular dynamic videos with pseudo-4d ground truth (2026)
2026
-
[5]
In: SIGGRAPH (2026)
Cao, W., Zhang, H., Tian, F., Wu, Y., Li, Y., Wang, S., Yu, N., Liu, Y.: Free- Orbit4D: Training-free arbitrary camera redirection for monocular videos via foreground-complete 4D reconstruction. In: SIGGRAPH (2026)
2026
-
[6]
ShapeNet: An Information-Rich 3D Model Repository
Chang, A.X., Funkhouser, T.A., Guibas, L.J., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
Blender Foun- dation, Stichting Blender Foundation, Amsterdam (2018)
Community, B.O.: Blender - a 3D modelling and rendering package. Blender Foun- dation, Stichting Blender Foundation, Amsterdam (2018)
2018
-
[8]
In: CVPR
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: CVPR. pp. 13142–13153 (2023)
2023
-
[9]
In: CVPR
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: CVPR. pp. 248–255 (2009)
2009
-
[10]
In: BMVC (2025)
Duan, R., Chen, J., Kortylewski, A., Yuille, A., Liu, Y.: Prompt-based exem- plar super-compression and regeneration for class-incremental learning. In: BMVC (2025)
2025
-
[11]
In: ECCV
Fischer, T., Liu, Y., Jesslen, A., Ahmed, N., Kaushik, P., Wang, A., Yuille, A.L., Kortylewski, A., Ilg, E.: inemo: Incremental neural mesh models for robust class- incremental learning. In: ECCV. pp. 357–374 (2024)
2024
-
[12]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Fu,S.,Tamir,N.,Sundaram,S.,Chai,L.,Zhang,R.,Dekel,T.,Isola,P.:Dreamsim: Learning new dimensions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
In: CVPR
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. pp. 770–778 (2016)
2016
- [14]
-
[15]
NeurIPS (2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. NeurIPS (2017)
2017
-
[16]
NeurIPS pp
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS pp. 6840–6851 (2020)
2020
-
[17]
(eds.) NeurIPS (2020)
Ho,J.,Jain,A.,Abbeel,P.:Denoisingdiffusionprobabilisticmodels.In:Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) NeurIPS (2020)
2020
-
[18]
In: The twelfth ICLR (2023) AC3S: Adaptive Conditioning for 3D-Aware Synthetic Data Generation 15
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Wang, J., Zhang, C., Wang, Z., Yau, S.K.S., Lin, Z., Zhou, L., Ran, C., Xiao, L., Wu, C., Schmidhuber, J.: Metagpt: Meta programming for a multi-agent collaborative framework. In: The twelfth ICLR (2023) AC3S: Adaptive Conditioning for 3D-Aware Synthetic Data Generation 15
2023
-
[19]
Advances in Neural Information Processing Systems32(2019)
Li, Y., Chen, X., Li, N.: Online optimal control with linear dynamics and predic- tions: Algorithms and regret analysis. Advances in Neural Information Processing Systems32(2019)
2019
-
[20]
In: AAAI
Li, Y., Das, S., Li, N.: Online optimal control with affine constraints. In: AAAI. pp. 8527–8537 (2021)
2021
-
[21]
IEEE Transactions on Automatic Con- trol66(10), 4761–4768 (2020)
Li, Y., Qu, G., Li, N.: Online optimization with predictions and switching costs: Fast algorithms and the fundamental limit. IEEE Transactions on Automatic Con- trol66(10), 4761–4768 (2020)
2020
-
[22]
In: ACM Multimedia
Lin, Q., Sun, X., Gao, Y., Zhong, Y., Zhao, Z., Li, D., Wang, H.: Tasr: Timestep- aware diffusion model for image super-resolution. In: ACM Multimedia. pp. 10034– 10043 (2025)
2025
-
[23]
In: AAAI
Liu, Y., Li, Y., Schiele, B., Sun, Q.: Online hyperparameter optimization for class- incremental learning. In: AAAI. pp. 8906–8913 (2023)
2023
-
[24]
In: WACV
Liu, Y., Li, Y., Schiele, B., Sun, Q.: Wakening past concepts without past data: Class-incremental learning from online placebos. In: WACV. pp. 2226–2235 (2024)
2024
-
[25]
In: CVPR
Liu, Y., Schiele, B., Sun, Q.: Adaptive aggregation networks for class-incremental learning. In: CVPR. pp. 2544–2553 (2021)
2021
-
[26]
NeurIPS34, 3478–3490 (2021)
Liu, Y., Schiele, B., Sun, Q.: Rmm: Reinforced memory management for class- incremental learning. NeurIPS34, 3478–3490 (2021)
2021
-
[27]
In: CVPR
Liu, Y., Schiele, B., Vedaldi, A., Rupprecht, C.: Continual detection transformer for incremental object detection. In: CVPR. pp. 23799–23808 (2023)
2023
-
[28]
In: CVPR
Liu, Y., Su, Y., Liu, A.A., Schiele, B., Sun, Q.: Mnemonics training: Multi-class incremental learning without forgetting. In: CVPR. pp. 12245–12254 (2020)
2020
-
[29]
TNNLS32(6), 2733–2743 (2021)
Liu, Y., Sun, Q., He, X., Liu, A., Su, Y., Chua, T.: Generating face images with attributes for free. TNNLS32(6), 2733–2743 (2021)
2021
-
[30]
In: ICCV
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: ICCV. pp. 10012–10022 (2021)
2021
-
[31]
In: CVPR
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: CVPR. pp. 11976–11986 (2022)
2022
-
[32]
In: CVPR
Luo, Z., Liu, Y., Schiele, B., Sun, Q.: Class-incremental exemplar compression for class-incremental learning. In: CVPR. pp. 11371–11380 (2023)
2023
-
[33]
In: ICLR (2023)
Ma, W., Liu, Q., Wang, J., Wang, A., Yuan, X., Zhang, Y., Xiao, Z., Zhang, G., Lu, B., Duan, R., Qi, Y., Kortylewski, A., Liu, Y., Yuille, A.: Generating images with 3d annotations using diffusion models. In: ICLR (2023)
2023
-
[34]
In: NeurIPS (2024)
Ma, W., Zhang, G., Liu, Q., Zeng, G., Kortylewski, A., Liu, Y., Yuille, A.: Im- agenet3d: Towards general-purpose object-level 3d understanding. In: NeurIPS (2024)
2024
-
[35]
NeurIPS pp
Nguyen, Q., Vu, T., Tran, A., Nguyen, K.: Dataset diffusion: Diffusion-based syn- thetic data generation for pixel-level semantic segmentation. NeurIPS pp. 76872– 76892 (2023)
2023
-
[36]
OpenAI: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
In: NeurIPS 2017 Autodiff Workshop (2017)
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., Lerer, A.: Automatic differentiation in pytorch. In: NeurIPS 2017 Autodiff Workshop (2017)
2017
-
[38]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
arXiv preprint arXiv:2501.11613 (2025) 16 E
Robino, G.: Conversation routines: A prompt engineering framework for task- oriented dialog systems. arXiv preprint arXiv:2501.11613 (2025) 16 E. Ji et al
-
[40]
In: CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR. pp. 10684–10695 (2022)
2022
-
[41]
In: MICCAI
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: MICCAI. pp. 234–241 (2015)
2015
-
[42]
NeurIPS pp
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, S.K.S., Lopes, R.G., Ayan, B.K., Salimans, T., Ho, J., Fleet, D.J., Norouzi, M.: Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS pp. 36479–36494 (2022)
2022
-
[43]
In: ICLR (2023)
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., Parikh, D., Gupta, S., Taigman, Y.: Make-a-video: Text-to- video generation without text-video data. In: ICLR (2023)
2023
-
[44]
In: ICLR (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
2021
-
[45]
Team, Q.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
arXiv preprint arXiv:2302.07944 (2023)
Trabucco, B., Doherty, K., Gurinas, M., Salakhutdinov, R.: Effective data augmen- tation with diffusion models. arXiv preprint arXiv:2302.07944 (2023)
-
[47]
In: ICLR (2023)
Villegas, R., Babaeizadeh, M., Kindermans, P., Moraldo, H., Zhang, H., Saffar, M.T., Castro, S., Kunze, J., Erhan, D.: Phenaki: Variable length video generation from open domain textual descriptions. In: ICLR (2023)
2023
-
[48]
NeurIPS pp
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models. NeurIPS pp. 24824–24837 (2022)
2022
-
[49]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., Elnashar, A., Spencer-Smith, J., Schmidt, D.C.: A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv preprint arXiv:2302.11382 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
In: CVPR
Wu, T., Zhang, J., Fu, X., Wang, Y., Ren, J., Pan, L., Wu, W., Yang, L., Wang, J., Qian, C., Lin, D., Liu, Z.: Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation. In: CVPR. pp. 803–814 (2023)
2023
-
[51]
In: WACV
Xiang, Y., Mottaghi, R., Savarese, S.: Beyond pascal: A benchmark for 3d object detection in the wild. In: WACV. pp. 75–82. IEEE (2014)
2014
-
[52]
In: SIGGRAPH Asia
Yehezkel, S., Dahary, O., Voynov, A., Cohen-Or, D.: Navigating with annealing guidance scale in diffusion space. In: SIGGRAPH Asia. pp. 1–11 (2025)
2025
-
[53]
In: ICCV
Yu, A., Grauman, K.: Just noticeable differences in visual attributes. In: ICCV. pp. 2416–2424 (2015)
2015
-
[54]
In: ECCV
Zhang, J.O., Sax, A., Zamir, A., Guibas, L., Malik, J.: Side-tuning: a baseline for network adaptation via additive side networks. In: ECCV. pp. 698–714. Springer (2020)
2020
-
[55]
TPAMI46(8), 5625–5644 (2024)
Zhang, J., Huang, J., Jin, S., Lu, S.: Vision-language models for vision tasks: A survey. TPAMI46(8), 5625–5644 (2024)
2024
-
[56]
In: ICCV
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: ICCV. pp. 3836–3847 (2023)
2023
-
[57]
In: MICCAI
Zhang, Y., Li, X., Chen, H., Yuille, A.L., Liu, Y., Zhou, Z.: Continual learning for abdominal multi-organ and tumor segmentation. In: MICCAI. pp. 35–45 (2023)
2023
-
[58]
IJCV130(9), 2337–2348 (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. IJCV130(9), 2337–2348 (2022)
2022
-
[59]
In: ICLR
Zhu, D., Shen, X., Li, X., Elhoseiny, M., et al.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. In: ICLR. vol. 2024, pp. 18378–18394 (2024)
2024
-
[60]
Zhu, Z., Gong, Y., Xiao, Y., Liu, Y., Hoiem, D.: How to teach large multimodal models new skills? In: ECCV (2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.