FeatX: Editing Software by Editing Features for Repository-Level Code Evolution
Pith reviewed 2026-07-01 04:54 UTC · model grok-4.3
The pith
FeatX lets users edit repository features instead of code, using extracted hierarchies to guide an LLM agent into patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
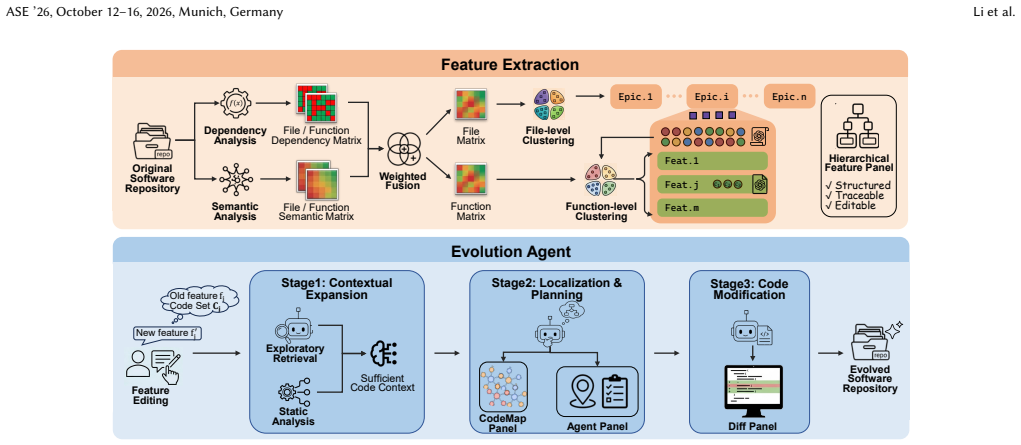
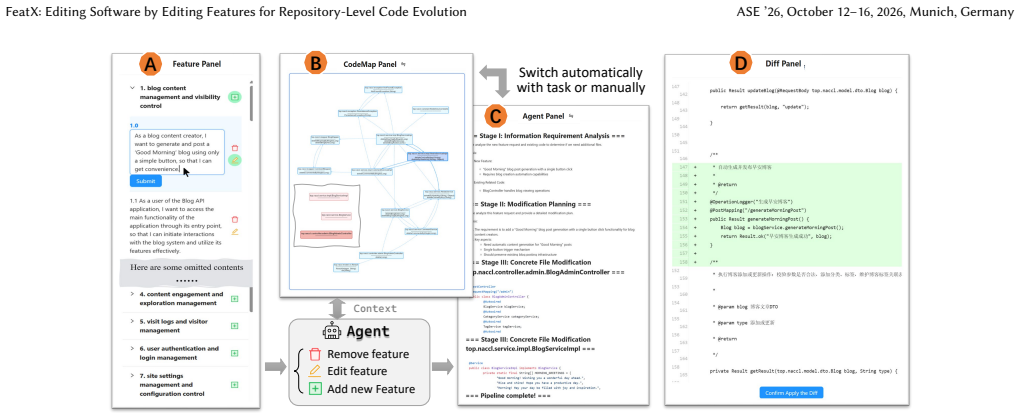
By building a hierarchical epic-feature structure with explicit feature-to-code mappings and routing edits through a three-stage Evolution Agent, FeatX converts high-level feature modifications directly into repository code patches, achieving better localization accuracy and lower user effort than direct LLM prompting.
What carries the argument
Hierarchical epic-feature structure with explicit feature-to-code mappings, which supplies the three-stage Evolution Agent with the context needed to translate feature edits into patches.
If this is right
- Developers perform repository-level changes without manually selecting or maintaining prompt context.
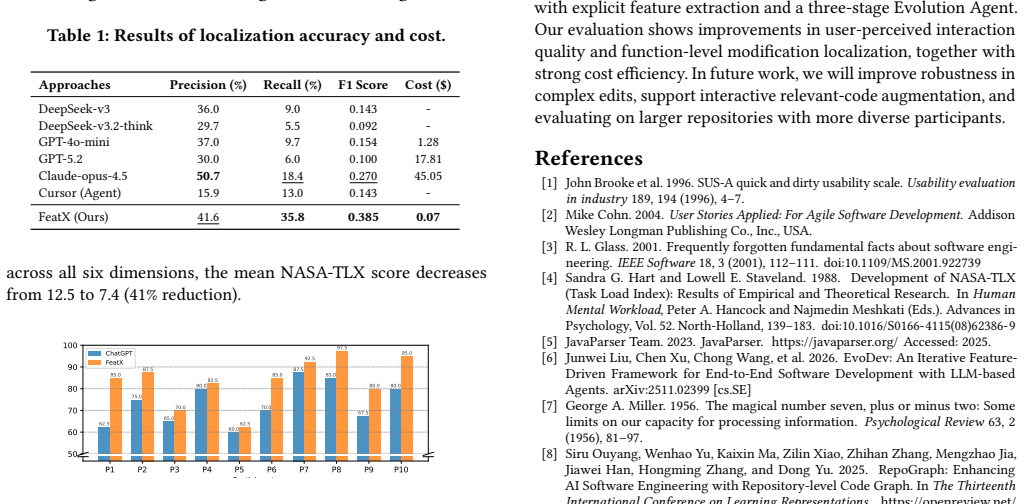
- Function-level modification localization reaches 42.6 percent higher F1 than strong LLM baselines.
- Total interaction cost stays at $0.07 even for multi-file feature changes.
- Cognitive load and usability metrics improve measurably over vanilla ChatGPT in controlled studies.
Where Pith is reading between the lines
- The same structure-extraction plus staged-agent pattern could apply to non-code artifacts such as documentation or configuration hierarchies.
- If feature mappings prove unstable across frequent refactors, the workflow would require periodic re-extraction or human verification steps.
- Combining the extracted structure with version-control history could support feature-level diffing and rollback without additional tooling.
Load-bearing premise
The hierarchical epic-feature structure extracted from the repository provides sufficiently accurate and stable feature-to-code mappings for the three-stage Evolution Agent to produce correct patches without substantial manual correction.
What would settle it
Running the same 38 real commits through FeatX after replacing the feature extraction step with a method that produces systematically inaccurate mappings, then measuring whether the F1 improvement and usability gains disappear.
Figures

read the original abstract
Large language models (LLMs) are increasingly used for software evolution, yet most interaction paradigms remain code-centric and require manual context management and prompt iteration. We present FeatX, a feature-oriented tool for editing software by editing features. Given an existing repository, FeatX extracts a hierarchical epic-feature structure with explicit feature-to-code mappings, then invokes a three-stage Evolution Agent to translate feature edits into code patches. The workflow is exposed through four coordinated panels. Across a controlled user study and replay experiments on 38 real-world feature-editing commits, FeatX significantly reduces cognitive load and improves usability compared with vanilla ChatGPT. It also achieves a 42.6\% relative improvement in function-level modification localization F1 over strong LLM baselines, at substantially lower cost (\$0.07 in total). The tool and collected dataset are available at https://github.com/a496263365/FeatX/tree/demo, with a demonstration video at https://youtu.be/OZqKZ4Ii-yM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FeatX, a system for repository-level code evolution that extracts a hierarchical epic-feature structure with explicit feature-to-code mappings from a given repository. It then employs a three-stage Evolution Agent to convert feature-level edits into code patches, presented via four coordinated UI panels. The approach is evaluated in a controlled user study and through replay experiments on 38 real-world feature-editing commits, reporting significant reductions in cognitive load and usability improvements over vanilla ChatGPT, a 42.6% relative improvement in function-level modification localization F1 score over strong LLM baselines, and a total cost of $0.07. The tool and dataset are made available.
Significance. If the empirical claims hold, FeatX represents a meaningful shift from code-centric to feature-centric interaction paradigms for LLM-assisted software maintenance, potentially reducing developer cognitive load in large repositories. The open-sourcing of the tool, dataset, and demonstration video is a clear strength supporting reproducibility.
major comments (1)
- [Replay experiments on 38 commits] The central claim that the extracted hierarchical epic-feature structure enables the three-stage Evolution Agent to produce correct patches without substantial manual correction depends on the accuracy of the feature-to-code mappings. The manuscript reports results on 38 real commits and a user study but supplies no precision, recall, or other quantitative metrics measuring how well the automatically extracted mappings align with the locations actually modified in the ground-truth commits (see abstract and replay-experiments description).
minor comments (1)
- [Abstract] The abstract asserts quantitative gains and a user study without any accompanying detail on methods, statistical tests, baseline construction, or error analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of FeatX's significance and reproducibility. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Replay experiments on 38 commits] The central claim that the extracted hierarchical epic-feature structure enables the three-stage Evolution Agent to produce correct patches without substantial manual correction depends on the accuracy of the feature-to-code mappings. The manuscript reports results on 38 real commits and a user study but supplies no precision, recall, or other quantitative metrics measuring how well the automatically extracted mappings align with the locations actually modified in the ground-truth commits (see abstract and replay-experiments description).
Authors: We agree that direct quantitative metrics on mapping accuracy would strengthen validation of the central claim. The replay experiments measure end-to-end patch correctness (via the reported F1 gains and commit reproduction), which depends on the mappings, but we did not include explicit precision/recall comparing extracted mappings to ground-truth modified locations in the 38 commits. In the revised manuscript we will add this analysis. revision: yes
Circularity Check
No circularity; empirical claims rest on external user study and commit replays
full rationale
The paper presents an empirical tool evaluation with no equations, fitted parameters, or derivation chain. Results derive from a controlled user study and replay of 38 real-world commits, with no self-definitional mappings, predictions that reduce to inputs by construction, or load-bearing self-citations. The feature-to-code extraction step is an implementation detail whose accuracy is externally testable against the ground-truth commits; it does not create a closed loop within the reported claims. This is the normal case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
John Brooke et al. 1996. SUS-A quick and dirty usability scale.Usability evaluation in industry189, 194 (1996), 4–7
1996
-
[2]
2004.User Stories Applied: For Agile Software Development
Mike Cohn. 2004.User Stories Applied: For Agile Software Development. Addison Wesley Longman Publishing Co., Inc., USA
2004
-
[3]
R. L. Glass. 2001. Frequently forgotten fundamental facts about software engi- neering.IEEE Software18, 3 (2001), 112–111. doi:10.1109/MS.2001.922739
-
[4]
Sandra G. Hart and Lowell E. Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. InHuman Mental Workload, Peter A. Hancock and Najmedin Meshkati (Eds.). Advances in Psychology, Vol. 52. North-Holland, 139–183. doi:10.1016/S0166-4115(08)62386-9
-
[5]
JavaParser Team. 2023. JavaParser. https://javaparser.org/ Accessed: 2025
2023
-
[6]
Junwei Liu, Chen Xu, Chong Wang, et al. 2026. EvoDev: An Iterative Feature- Driven Framework for End-to-End Software Development with LLM-based Agents. arXiv:2511.02399 [cs.SE]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
George A. Miller. 1956. The magical number seven, plus or minus two: Some limits on our capacity for processing information.Psychological Review63, 2 (1956), 81–97
1956
-
[8]
Siru Ouyang, Wenhao Yu, Kaixin Ma, Zilin Xiao, Zhihan Zhang, Mengzhao Jia, Jiawei Han, Hongming Zhang, and Dong Yu. 2025. RepoGraph: Enhancing AI Software Engineering with Repository-level Code Graph. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/ forum?id=dw9VUsSHGB
2025
-
[9]
Kensen Shi, Deniz Altınbüken, Saswat Anand, Mihai Christodorescu, Katja Grün- wedel, Alexa Koenings, Sai Naidu, Anurag Pathak, Marc Rasi, Fredde Ribeiro, Brandon Ruffin, Siddhant Sanyam, Maxim Tabachnyk, Sara Toth, Roy Tu, Tobias Welp, Pengcheng Yin, Manzil Zaheer, Satish Chandra, and Charles Sutton. 2025. Natural Language Outlines for Code: Literate Prog...
-
[10]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. De- mystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE (June 2025). doi:10.1145/3715754
-
[11]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2025. SWE-agent: agent-computer interfaces enable automated software engineering. InProceedings of the 38th International Conference on Neural Information Processing Systems (NIPS ’24). Curran Associates Inc., Red Hook, NY, USA
2025
-
[12]
Ryan Yen, Jian Zhao, and Daniel Vogel. 2025. Code Shaping: Iterative Code Editing with Free-form AI-Interpreted Sketching. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3706598.3713822
-
[13]
J. D. Zamfirescu-Pereira, Eunice Jun, Michael Terry, Qian Yang, and Bjoern Hartmann. 2025. Beyond Code Generation: LLM-supported Exploration of the Program Design Space. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3706598.3714154
- [14]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.