The Calibration Turn in AI-Assisted Research: A Conceptual and Methodological Framework for Evidence-Licensed Claims
Pith reviewed 2026-07-01 06:25 UTC · model grok-4.3
The pith
Calibration acts as a mechanism for managing scientific assertion rights by licensing claims based on evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
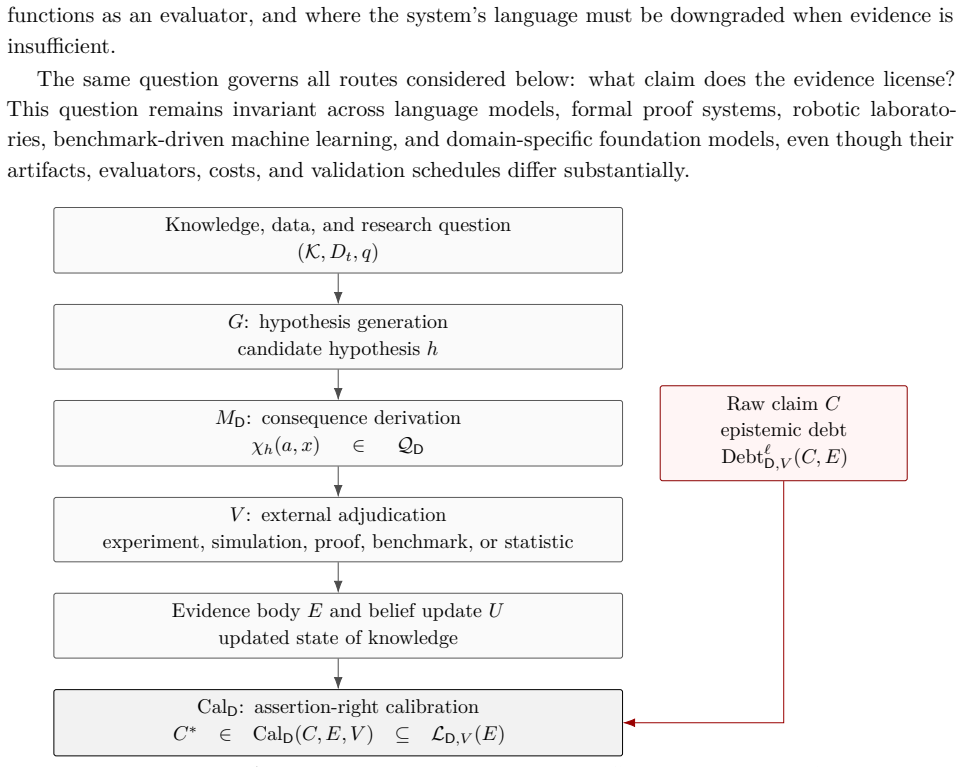
The central claim is that calibration is not merely cautious wording but a mechanism for managing scientific assertion rights: evidence licenses some forms of speech and withholds others. The paper distinguishes linguistic, consequence-based, interventional, and evidence-licensed semantics; defines the claim-evidence gap and epistemic debt; and treats minimal structural reconstruction across heterogeneous outputs as an upward form of claim calibration. The resulting principles are: no claim without license, validation does not determine claim level, and automation amplifies the need for calibration.
What carries the argument
The five operators of AI-assisted research, with claim calibration as the operator that enforces evidence-licensed outputs by managing assertion rights.
Load-bearing premise
That AI-assisted research can be adequately represented by the five operators allowing a coherent distinction between licensed and unlicensed claims.
What would settle it
A counterexample where an AI system produces consistently accurate scientific claims without using any form of claim calibration would challenge the framework's necessity.
Figures
read the original abstract
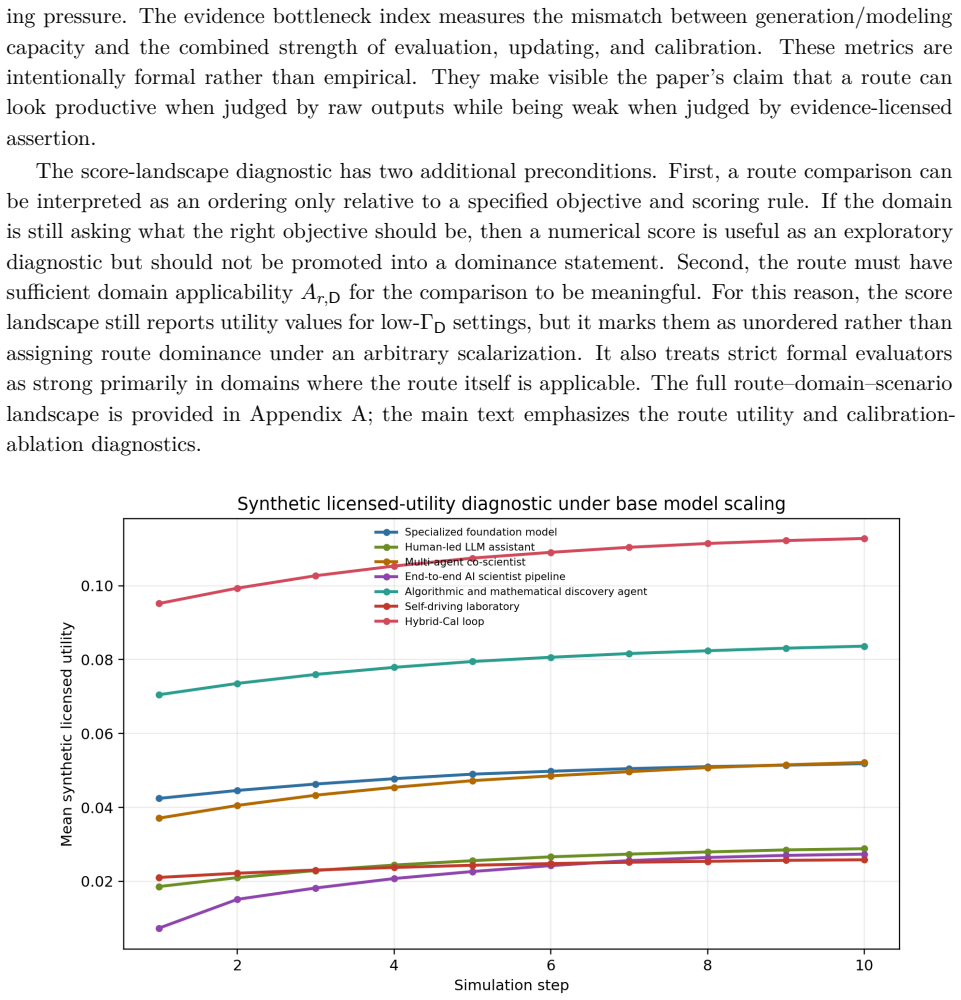
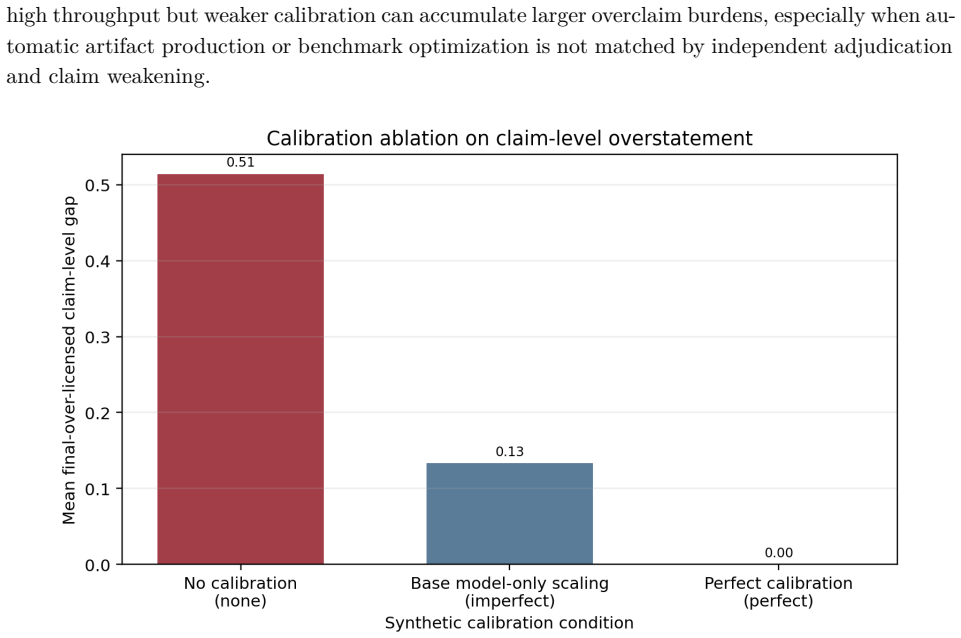
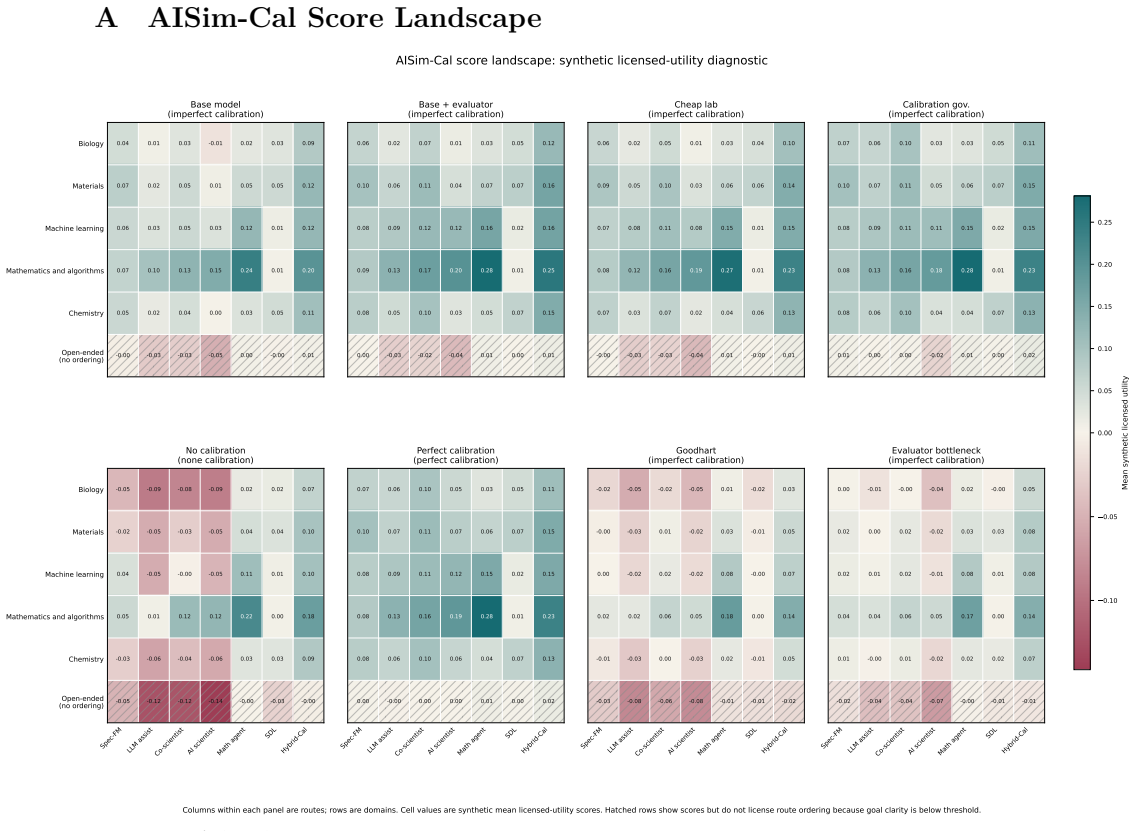
AI-assisted research has entered a stage in which the central question is not only whether systems can generate hypotheses, run experiments, or produce manuscripts, but whether their scientific claims are calibrated to the evidence that supports them. This Perspective-style paper develops a conceptual and methodological framework for evidence-licensed claims in AI-assisted research. Motivated by representative routes including specialized scientific foundation models, LLM research assistants, multi-agent co-scientists, AI Scientist pipelines, mathematical discovery agents, and self-driving laboratories, it represents AI-assisted research as five operators: hypothesis generation, model-mediated consequence derivation, external validation, belief update, and claim calibration. The central claim is that calibration is not merely cautious wording but a mechanism for managing scientific assertion rights: evidence licenses some forms of speech and withholds others. The paper distinguishes linguistic, consequence-based, interventional, and evidence-licensed semantics; defines the claim-evidence gap and epistemic debt; and treats minimal structural reconstruction across heterogeneous outputs as an upward form of claim calibration. AISim-Cal is included as an illustrative synthetic dynamics exercise, not as an empirical forecast or benchmark. The resulting principles are: no claim without license, validation does not determine claim level, and automation amplifies the need for calibration. Reliable AI-assisted research is therefore evaluated as a loop that generates hypotheses, derives testable consequences, accepts independent adjudication, updates beliefs, and outputs only evidence-licensed claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a conceptual and methodological framework for evidence-licensed claims in AI-assisted research. It models such research via five operators (hypothesis generation, model-mediated consequence derivation, external validation, belief update, and claim calibration) drawn from routes including foundation models, LLM assistants, multi-agent systems, AI Scientist pipelines, mathematical agents, and self-driving labs. The central claim is that calibration functions as a mechanism for managing scientific assertion rights, licensing some claims while withholding others, with supporting distinctions among linguistic, consequence-based, interventional, and evidence-licensed semantics, plus definitions of the claim-evidence gap and epistemic debt. An illustrative synthetic exercise (AISim-Cal) is included, and three principles are derived: no claim without license, validation does not determine claim level, and automation amplifies the need for calibration.
Significance. If the distinctions and operators hold, the framework offers a structured vocabulary for assessing when AI-generated outputs qualify as scientifically assertable, potentially informing evaluation criteria for automated research systems and emphasizing calibration as an active process rather than mere hedging. The definitional approach and illustrative exercise provide a starting point for formalizing epistemic norms in this domain.
major comments (2)
- [five operators section] The section defining the five operators: the claim that these operators represent AI-assisted research routes and enable a coherent distinction between evidence-licensed and unlicensed claims rests on an unelaborated assumption of adequacy and coverage; no explicit mapping is provided to the heterogeneous examples (e.g., self-driving laboratories or mathematical discovery agents), which is load-bearing for the central assertion-rights claim.
- [central claim and definitions] The definitional structure around calibration and licensing: calibration is introduced in terms of evidence licensing, which is then used to demarcate valid claims, creating a self-referential loop with no independent external benchmark or falsifiable test cited; this directly affects whether the framework can ground the distinction between licensed and unlicensed speech.
minor comments (2)
- [abstract and introduction] The abstract and introduction refer to 'Perspective-style paper' and 'illustrative synthetic dynamics exercise' without clarifying how these elements integrate with the methodological framework or whether AISim-Cal is intended to demonstrate any operator in action.
- [definitions] The invented terms 'claim-evidence gap' and 'epistemic debt' are introduced without comparison to existing literature on similar concepts (e.g., in philosophy of science or metrology), which would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify opportunities to strengthen the presentation of the framework. We address each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [five operators section] The section defining the five operators: the claim that these operators represent AI-assisted research routes and enable a coherent distinction between evidence-licensed and unlicensed claims rests on an unelaborated assumption of adequacy and coverage; no explicit mapping is provided to the heterogeneous examples (e.g., self-driving laboratories or mathematical discovery agents), which is load-bearing for the central assertion-rights claim.
Authors: We agree that the absence of explicit mappings weakens the load-bearing claim about coverage across routes. In the revised manuscript we will insert a new subsection (following the operator definitions) containing a mapping table. Each row will link one operator to concrete instantiations in the listed routes—for example, external validation in self-driving laboratories occurs via physical assay results, while in mathematical discovery agents it occurs via formal proof checkers. This addition will make the adequacy assumption explicit and support the assertion-rights distinction without altering the core framework. revision: yes
-
Referee: [central claim and definitions] The definitional structure around calibration and licensing: calibration is introduced in terms of evidence licensing, which is then used to demarcate valid claims, creating a self-referential loop with no independent external benchmark or falsifiable test cited; this directly affects whether the framework can ground the distinction between licensed and unlicensed speech.
Authors: The concern about circularity is well-taken for a purely definitional treatment. The manuscript already positions external validation as the independent input that feeds the claim-calibration operator; we will revise the definitions section to foreground this sequencing and to state explicitly that licensing is an output of the full operator loop rather than a premise. Because the paper is a conceptual framework rather than an empirical test, no falsifiable benchmark is supplied; we will add a short paragraph clarifying this scope limitation while preserving the internal grounding via the operators. revision: partial
Circularity Check
No significant circularity in definitional conceptual framework
full rationale
The paper is a Perspective-style conceptual framework that explicitly defines calibration as a mechanism for evidence-licensed claims and lists resulting principles. No derivation chain, equations, fitted parameters called predictions, or self-citations are present in the provided text. The five operators are introduced as a representation of AI-assisted routes, not derived from or reducing to the central claim. The framework is presented as definitional and illustrative (e.g., AISim-Cal is synthetic and not a benchmark), with no load-bearing step that reduces by construction to its inputs. This matches the default expectation for non-circular conceptual papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AI-assisted research can be represented as the five operators: hypothesis generation, model-mediated consequence derivation, external validation, belief update, and claim calibration.
- domain assumption Evidence can function as a license that permits or withholds specific forms of scientific speech.
invented entities (2)
-
claim-evidence gap
no independent evidence
-
epistemic debt
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi:10.1787/a8d820bd-en , url =
Artificial Intelligence in Science: Challenges, Opportunities and the Future of Research , year =. doi:10.1787/a8d820bd-en , url =
-
[2]
and Zenil, Hector , title =
King, Ross D. and Zenil, Hector , title =. Artificial Intelligence in Science: Challenges, Opportunities and the Future of Research , publisher =. 2023 , doi =
2023
-
[3]
and Bambrick, Joshua and Bodenstein, Sebastian W
Abramson, Josh and Adler, Jonas and Dunger, Jack and Evans, Richard and Green, Tim and Pritzel, Alexander and Ronneberger, Olaf and Willmore, Lindsay and Ballard, Andrew J. and Bambrick, Joshua and Bodenstein, Sebastian W. and Evans, David A. and Hung, Chia-Chun and O'Neill, Michael and Reiman, David and Tunyasuvunakool, Kathryn and Wu, Zachary and Zidek,...
2024
-
[4]
2026 , howpublished =
2026
-
[5]
Nucleic Acids Research , volume =
Varadi, Mihaly and Bertoni, Damian and Magana, Patricia and Paramval, Urmila and Pidruchna, Ivanna and Radhakrishnan, Mukund and Tsenkov, Maxim and Nair, Sreenath and Mirdita, Milot and Yeo, Josh and Kovalevskiy, Oleg and Tunyasuvunakool, Kathryn and Laydon, Alexander and Zidek, Augustin and Green, Tim and Jumper, John and Birney, Ewan and Steinegger, Mar...
2024
-
[6]
and Aykol, Muratahan and Cheon, Gowoon and Cubuk, Ekin Dogus and others , title =
Merchant, Amil and Batzner, Simon and Schoenholz, Samuel S. and Aykol, Muratahan and Cheon, Gowoon and Cubuk, Ekin Dogus and others , title =. Nature , volume =. 2023 , doi =
2023
-
[7]
T., Lupsasca, A., Sawhney, M., Scherrer, R., Sellke, M., Spears, B
Bubeck, Sebastien and Coester, Christian and Eldan, Ronen and Gowers, Timothy and Lee, Yin Tat and Lupsasca, Alexandru and Sawhney, Mehtaab and Scherrer, Robert and Sellke, Mark and Spears, Brian K. and Unutmaz, Derya and Weil, Kevin and Yin, Steven and Zhivotovskiy, Nikita , title =. arXiv preprint arXiv:2511.16072 , year =. doi:10.48550/arXiv.2511.16072 , url =
-
[8]
2025 , howpublished =
Early Experiments in Accelerating Science with. 2025 , howpublished =
2025
-
[9]
Gottweis, Juraj and Weng, Wei-Hung and Daryin, Andrey and others , title =. Nature , year =. doi:10.1038/s41586-026-10644-y , url =
-
[10]
Ghareeb, A. E. and Chang, B. and Mitchener, L. and others , title =. Nature , year =. doi:10.1038/s41586-026-10652-y , url =
-
[11]
Nature , volume =
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Yamada, Yutaro and Hu, Shengran and Foerster, Jakob and Ha, David and Clune, Jeff , title =. Nature , volume =. 2026 , doi =
2026
-
[12]
Novikov, Alexander and Vu, Ngan and Eisenberger, Marvin and Dupont, Emilien and Huang, Po-Sen and Wagner, Adam Zsolt and Shirobokov, Sergey and Kozlovskii, Borislav and Ruiz, Francisco J. R. and Mehrabian, Abbas and Kumar, M. Pawan and See, Abigail and Chaudhuri, Swarat and Holland, George and Davies, Alex and Nowozin, Sebastian and Kohli, Pushmeet and Ba...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.13131
-
[13]
Nature , volume =
Hubert, Thomas and Mehta, Rupesh and Sartran, Laurent and others , title =. Nature , volume =. 2026 , doi =
2026
-
[14]
and MacKnight, Robert and Kline, Ben and Gomes, Gabe , title =
Boiko, Daniil A. and MacKnight, Robert and Kline, Ben and Gomes, Gabe , title =. Nature , volume =. 2023 , doi =
2023
-
[15]
and Baird, Sterling G
Tom, Gary and Schmid, Stefan P. and Baird, Sterling G. and Cao, Yang and Darvish, Kourosh and Hao, Han and Lo, Stanley and Pablo-Garcia, Sergio and Rajaonson, Ella M. and Skreta, Marta and Yoshikawa, Naruki and Corapi, Samantha and Akkoc, Gun Deniz and Strieth-Kalthoff, Felix and Seifrid, Martin and Aspuru-Guzik, Alan , title =. Chemical Reviews , volume ...
2024
-
[16]
and Rendy, B
Szymanski, Nathan J. and Rendy, B. and Fei, Y. and others , title =. Nature , volume =. 2023 , doi =
2023
-
[17]
and Rendy, Bernardus and Fei, Yuxing and Kumar, Rishi E
Szymanski, Nathan J. and Rendy, Bernardus and Fei, Yuxing and Kumar, Rishi E. and He, Tanjin and Milsted, David and McDermott, Matthew J. and Gallant, Max and Cubuk, Ekin Dogus and Merchant, Amil and Kim, Haegyeom and Jain, Anubhav and Bartel, Christopher J. and Persson, Kristin and Zeng, Yan and Ceder, Gerbrand , title =. Nature , volume =. 2026 , doi =
2026
-
[18]
Chemical & Engineering News , year =
Chawla, Dalmeet Singh , title =. Chemical & Engineering News , year =
-
[19]
Popular Science Monthly , volume =
Peirce, Charles Sanders , title =. Popular Science Monthly , volume =
-
[20]
, title =
Popper, Karl R. , title =
-
[21]
Criticism and the Growth of Knowledge , editor =
Lakatos, Imre , title =. Criticism and the Growth of Knowledge , editor =
-
[22]
Hacking, Ian , title =
-
[23]
, title =
Mayo, Deborah G. , title =
-
[24]
Toulmin, Stephen Edelston , title =
-
[25]
Winsberg, Eric , title =
-
[26]
Pearl, Judea , title =
-
[27]
and Oxman, Andrew D
Guyatt, Gordon H. and Oxman, Andrew D. and Vist, Gunn E. and Kunz, Regina and Falck-Ytter, Yngve and Alonso-Coello, Pablo and Schunemann, Holger J. , title =. BMJ , volume =. 2008 , doi =
2008
-
[28]
Wang, Fiona Y. and Buehler, Markus J. , title =. arXiv preprint arXiv:2606.01444 , year =. doi:10.48550/arXiv.2606.01444 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.01444
-
[29]
Automatica , volume =
Rissanen, Jorma , title =. Automatica , volume =. 1978 , doi =
1978
-
[30]
Minimum Description Length Revisited , journal =
Gr. Minimum Description Length Revisited , journal =. 2019 , doi =
2019
-
[31]
The Journal of Philosophy , volume =
Friedman, Michael , title =. The Journal of Philosophy , volume =. 1974 , doi =
1974
-
[32]
Philosophy of Science , volume =
Kitcher, Philip , title =. Philosophy of Science , volume =. 1981 , doi =
1981
-
[33]
, title =
Thurston, William P. , title =. Bulletin of the American Mathematical Society , volume =. 1994 , doi =
1994
-
[34]
Synthese , volume =
Avigad, Jeremy , title =. Synthese , volume =. 2006 , doi =
2006
-
[35]
J., Bambrick, J., Bodenstein, S
Abramson, J., Adler, J., Dunger, J., Evans, R., Green, T., Pritzel, A., Ronneberger, O., Willmore, L., Ballard, A. J., Bambrick, J., Bodenstein, S. W., Evans, D. A., Hung, C.-C., O'Neill, M., Reiman, D., Tunyasuvunakool, K., Wu, Z., Zidek, A., et al. (2024). Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature , 630:493--500
2024
-
[36]
Avigad, J. (2006). Mathematical method and proof. Synthese , 153:105--159
2006
-
[37]
A., MacKnight, R., Kline, B., and Gomes, G
Boiko, D. A., MacKnight, R., Kline, B., and Gomes, G. (2023). Autonomous chemical research with large language models. Nature , 624:570--578
2023
-
[38]
T., Lupsasca, A., Sawhney, M., Scherrer, R., Sellke, M., Spears, B
Bubeck, S., Coester, C., Eldan, R., Gowers, T., Lee, Y. T., Lupsasca, A., Sawhney, M., Scherrer, R., Sellke, M., Spears, B. K., Unutmaz, D., Weil, K., Yin, S., and Zhivotovskiy, N. (2025). Early science acceleration experiments with GPT-5 . arXiv preprint arXiv:2511.16072
-
[39]
Chawla, D. S. (2026). Nature robot chemist paper corrected, but some questions remain unanswered . Chemical & Engineering News . Chemical & Engineering News report, accessed 2026-06-16
2026
-
[40]
Friedman, M. (1974). Explanation and scientific understanding. The Journal of Philosophy , 71(1):5--19
1974
-
[41]
E., Chang, B., Mitchener, L., et al
Ghareeb, A. E., Chang, B., Mitchener, L., et al. (2026). A multi-agent system for automating scientific discovery. Nature . Advance online publication, published 2026-05-19
2026
-
[42]
AlphaFold protein structure database
Google DeepMind and EMBL-EBI (2026). AlphaFold protein structure database. https://alphafold.ebi.ac.uk/. Accessed 2026-06-16
2026
-
[43]
Gottweis, J., Weng, W.-H., Daryin, A., et al. (2026). Accelerating scientific discovery with Co-Scientist . Nature . Advance online publication, published 2026-05-19
2026
-
[44]
and Roos, T
Gr \"u nwald, P. and Roos, T. (2019). Minimum description length revisited. International Journal of Mathematics for Industry , 11(1):1930001
2019
-
[45]
H., Oxman, A
Guyatt, G. H., Oxman, A. D., Vist, G. E., Kunz, R., Falck-Ytter, Y., Alonso-Coello, P., and Schunemann, H. J. (2008). GRADE : An emerging consensus on rating quality of evidence and strength of recommendations. BMJ , 336(7650):924--926
2008
-
[46]
Hacking, I. (1983). Representing and Intervening: Introductory Topics in the Philosophy of Natural Science . Cambridge University Press, Cambridge
1983
-
[47]
Hubert, T., Mehta, R., Sartran, L., et al. (2026). Olympiad-level formal mathematical reasoning with reinforcement learning. Nature , 651:607--613
2026
-
[48]
King, R. D. and Zenil, H. (2023). A framework for evaluating the AI -driven automation of science. In Artificial Intelligence in Science: Challenges, Opportunities and the Future of Research . OECD Publishing. Accessed 2026-06-16
2023
-
[49]
Kitcher, P. (1981). Explanatory unification. Philosophy of Science , 48(4):507--531
1981
-
[50]
Lakatos, I. (1970). Falsification and the methodology of scientific research programmes. In Lakatos, I. and Musgrave, A., editors, Criticism and the Growth of Knowledge , pages 91--196. Cambridge University Press, Cambridge
1970
-
[51]
T., Yamada, Y., Hu, S., Foerster, J., Ha, D., and Clune, J
Lu, C., Lu, C., Lange, R. T., Yamada, Y., Hu, S., Foerster, J., Ha, D., and Clune, J. (2026). Towards end-to-end automation of AI research. Nature , 651:914--919
2026
-
[52]
Mayo, D. G. (1996). Error and the Growth of Experimental Knowledge . University of Chicago Press, Chicago
1996
-
[53]
S., Aykol, M., Cheon, G., Cubuk, E
Merchant, A., Batzner, S., Schoenholz, S. S., Aykol, M., Cheon, G., Cubuk, E. D., et al. (2023). Scaling deep learning for materials discovery. Nature , 624:80--85
2023
-
[54]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, A., Vu, N., Eisenberger, M., Dupont, E., Huang, P.-S., Wagner, A. Z., Shirobokov, S., Kozlovskii, B., Ruiz, F. J. R., Mehrabian, A., Kumar, M. P., See, A., Chaudhuri, S., Holland, G., Davies, A., Nowozin, S., Kohli, P., and Balog, M. (2025). AlphaEvolve : A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131 . T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Artificial intelligence in science: Challenges, opportunities and the future of research
OECD (2023). Artificial intelligence in science: Challenges, opportunities and the future of research. See the chapter ``A framework for evaluating the AI-driven automation of science''
2023
-
[56]
Early experiments in accelerating science with GPT-5
OpenAI (2025). Early experiments in accelerating science with GPT-5 . https://openai.com/index/accelerating-science-gpt-5/. Official web report, accessed 2026-06-16
2025
-
[57]
Pearl, J. (2009). Causality: Models, Reasoning, and Inference . Cambridge University Press, Cambridge, 2 edition
2009
-
[58]
Peirce, C. S. (1878). How to make our ideas clear. Popular Science Monthly , 12:286--302
-
[59]
Popper, K. R. (1959). The Logic of Scientific Discovery . Hutchinson, London
1959
-
[60]
Rissanen, J. (1978). Modeling by shortest data description. Automatica , 14(5):465--471
1978
-
[61]
J., Rendy, B., Fei, Y., et al
Szymanski, N. J., Rendy, B., Fei, Y., et al. (2023). An autonomous laboratory for the accelerated synthesis of inorganic materials. Nature , 624:86--91
2023
-
[62]
J., Rendy, B., Fei, Y., Kumar, R
Szymanski, N. J., Rendy, B., Fei, Y., Kumar, R. E., He, T., Milsted, D., McDermott, M. J., Gallant, M., Cubuk, E. D., Merchant, A., Kim, H., Jain, A., Bartel, C. J., Persson, K., Zeng, Y., and Ceder, G. (2026). Author correction: An autonomous laboratory for the accelerated synthesis of inorganic materials. Nature , 650:E1--E1
2026
-
[63]
Thurston, W. P. (1994). On proof and progress in mathematics. Bulletin of the American Mathematical Society , 30(2):161--178
1994
-
[64]
P., Baird, S
Tom, G., Schmid, S. P., Baird, S. G., Cao, Y., Darvish, K., Hao, H., Lo, S., Pablo-Garcia, S., Rajaonson, E. M., Skreta, M., Yoshikawa, N., Corapi, S., Akkoc, G. D., Strieth-Kalthoff, F., Seifrid, M., and Aspuru-Guzik, A. (2024). Self-driving laboratories for chemistry and materials science. Chemical Reviews , 124:9633--9732
2024
-
[65]
Toulmin, S. E. (1958). The Uses of Argument . Cambridge University Press, Cambridge
1958
-
[66]
Varadi, M., Bertoni, D., Magana, P., Paramval, U., Pidruchna, I., Radhakrishnan, M., Tsenkov, M., Nair, S., Mirdita, M., Yeo, J., Kovalevskiy, O., Tunyasuvunakool, K., Laydon, A., Zidek, A., Green, T., Jumper, J., Birney, E., Steinegger, M., Hassabis, D., and Velankar, S. (2024). AlphaFold protein structure database in 2024: Providing structure coverage f...
2024
-
[67]
Wang, F. Y. and Buehler, M. J. (2026). Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence . arXiv preprint arXiv:2606.01444
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Winsberg, E. (2010). Science in the Age of Computer Simulation . University of Chicago Press, Chicago
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.