TabPATE: Differentially Private Tabular In-Context Learning Without Public Data
Pith reviewed 2026-07-01 06:41 UTC · model grok-4.3
The pith
TabPATE achieves differential privacy for tabular in-context learning by partitioning private data across teachers and aggregating their outputs on synthetic queries without public data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabPATE partitions the private context across teacher models, privately aggregates their labels on synthetic tabular queries generated from feature ranges or lightly privatized marginals, and releases the resulting labeled queries as context for a student model, thereby supplying differential privacy for tabular in-context learning without requiring public data.
What carries the argument
TabPATE, a PATE-style mechanism that partitions private context, creates synthetic queries from bounded features, and privately aggregates teacher predictions for student use.
If this is right
- TabPATE maintains competitive utility on standard tabular benchmarks.
- Membership inference success drops to near-random levels.
- The method removes the requirement for public data that earlier private ICL approaches needed.
- Formal privacy guarantees become available for small private tabular contexts used in foundation-model inference.
Where Pith is reading between the lines
- The query-generation step could extend to other bounded, low-dimensional structured data settings.
- Private in-context learning may become viable in regulated domains where public data is unavailable.
- The same teacher-partition and aggregation pattern might reduce leakage in non-tabular ICL tasks that also admit cheap synthetic query creation.
Load-bearing premise
Tabular features are bounded and relatively low-dimensional, so useful queries can be generated from feature ranges or lightly privatized marginals alone.
What would settle it
An experiment in which membership inference attacks on TabPATE-protected models succeed at rates well above random guessing, or in which accuracy falls substantially below non-private baselines on the paper's tabular benchmarks.
Figures
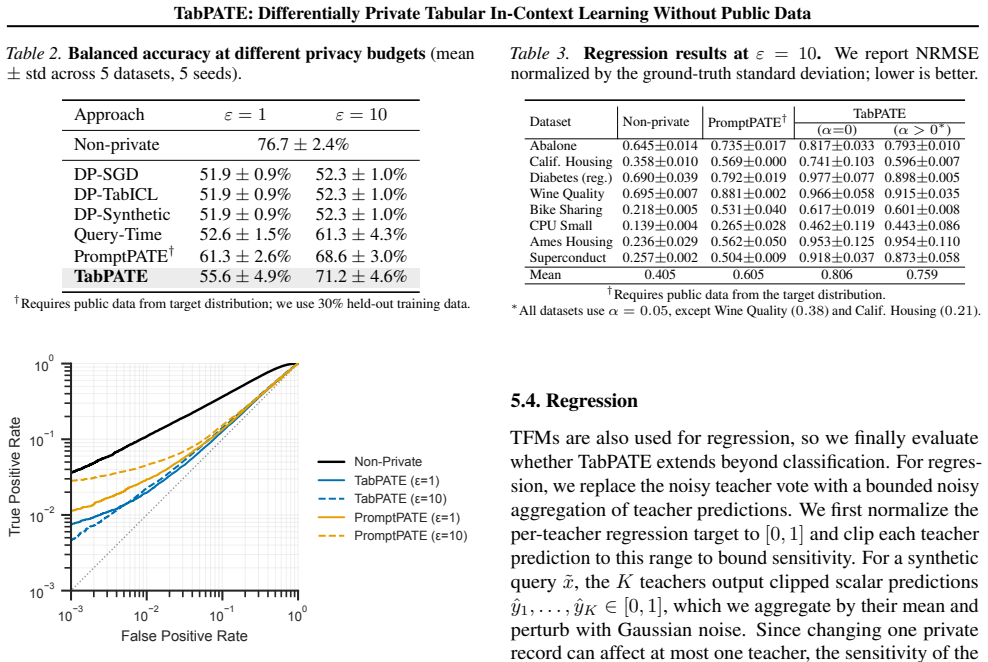
read the original abstract
Tabular foundation models enable accurate in-context learning (ICL) from small labeled datasets, but the private records placed in context can leak through model predictions. We first show that even basic membership inference attacks succeed against tabular ICL, motivating formal privacy protection. We then introduce TabPATE, a differentially private PATE-style defense for tabular ICL that does not require public in-distribution data. TabPATE partitions the private context across teacher models, privately aggregates their labels on synthetic tabular queries, and releases the resulting labeled queries as a student context. Because tabular features are bounded and relatively low-dimensional, useful queries can be generated from feature ranges alone or from lightly privatized marginals. Across tabular benchmarks, TabPATE preserves competitive utility while reducing membership inference to near-random success, providing a practical path to private tabular ICL without public data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TabPATE, a differentially private PATE-style framework for tabular in-context learning that avoids public data. Private records are partitioned across teacher models; synthetic queries are generated from feature ranges or lightly privatized marginals; teacher labels on these queries are aggregated under DP; and the resulting labeled queries form the student context. The central claim is that this construction preserves competitive utility on tabular benchmarks while driving membership-inference success to near-random levels.
Significance. If the empirical results hold under realistic feature dependence, the work supplies a concrete, public-data-free route to private tabular ICL. This is relevant because tabular foundation models are increasingly deployed on sensitive data where public in-distribution corpora are unavailable, and the bounded, low-dimensional character of tabular features is exploited to sidestep the usual public-data requirement of PATE-style methods.
major comments (2)
- [Abstract and query-generation subsection] The utility claim rests on the assertion (Abstract) that queries drawn from feature ranges or lightly privatized marginals remain sufficiently in-distribution for ICL transfer. No ablation is described that varies feature-correlation strength or compares marginal sampling against joint sampling; if higher-order dependencies are present, the synthetic queries can be OOD relative to the private distribution, directly undermining the competitive-utility guarantee.
- [Abstract and experimental evaluation] The MIA claim likewise lacks reported quantitative support in the provided description (no attack accuracies, AUC values, or error bars). Without these numbers and without a clear statement of the attack model and number of runs, it is impossible to verify that success is reduced to near-random levels rather than merely directionally lower.
minor comments (2)
- [Abstract] The abstract should state the concrete privacy budget (ε,δ) used in the reported experiments.
- [Method] Notation for the teacher aggregation step and the student context construction should be introduced with explicit equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the utility and membership-inference claims. We address each major comment below and will incorporate the requested clarifications and additional results in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and query-generation subsection] The utility claim rests on the assertion (Abstract) that queries drawn from feature ranges or lightly privatized marginals remain sufficiently in-distribution for ICL transfer. No ablation is described that varies feature-correlation strength or compares marginal sampling against joint sampling; if higher-order dependencies are present, the synthetic queries can be OOD relative to the private distribution, directly undermining the competitive-utility guarantee.
Authors: We agree that the manuscript would be strengthened by an explicit ablation on feature-correlation strength. The current justification relies on the bounded, low-dimensional character of tabular features, which permits useful queries from ranges or privatized marginals, but we will add an ablation that varies correlation strength across benchmarks and directly compares marginal versus joint sampling to demonstrate that the queries remain sufficiently in-distribution for competitive ICL utility. revision: yes
-
Referee: [Abstract and experimental evaluation] The MIA claim likewise lacks reported quantitative support in the provided description (no attack accuracies, AUC values, or error bars). Without these numbers and without a clear statement of the attack model and number of runs, it is impossible to verify that success is reduced to near-random levels rather than merely directionally lower.
Authors: The experimental section reports membership-inference results showing near-random success, but we acknowledge that the abstract and high-level description omit the specific quantitative metrics. We will revise the manuscript to include attack accuracies, AUC values with error bars, a precise description of the attack model, and the number of runs, enabling direct verification that success reaches near-random levels. revision: yes
Circularity Check
No circularity: TabPATE is a new construction using standard DP mechanisms on synthetic queries from ranges/marginals
full rationale
The paper describes TabPATE as a PATE-style defense that partitions private data across teachers, generates synthetic queries from bounded feature ranges or lightly privatized marginals, aggregates labels privately, and releases them for student ICL. No equations, fitted parameters, or derivations are presented that reduce the claimed privacy-utility tradeoff to inputs defined by the same experiment. The method relies on standard DP aggregation and the assumption that low-dimensional bounded tabular features allow useful queries without public data; this is a constructive proposal rather than a self-referential derivation or self-citation chain. The abstract and description contain no load-bearing self-citations or renamings that collapse the result to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B., Mironov, I., Talwar, K., and Zhang, L
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., and Zhang, L. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 308–318,
2016
-
[2]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A....
1901
-
[3]
Carlini, N., Chien, S., Nasr, M., Song, S., Terzis, A., and Tramer, F
doi: 10.1109/ BigData62323.2024.10826053. Carlini, N., Chien, S., Nasr, M., Song, S., Terzis, A., and Tramer, F. Membership inference attacks from first prin- ciples. In2022 IEEE Symposium on Security and Privacy (SP), pp. 1897–1914. IEEE, 2022a. Carlini, N., Jagielski, M., Zhang, C., Papernot, N., Terzis, A., and Tramer, F. The privacy onion effect: Memo...
- [4]
-
[5]
Are foundation models useful for bankruptcy prediction?arXiv:2511.16375,
Kostrzewa, M., Furman, O., Furman, R., Tomczak, S., and Zieba, M. Are foundation models useful for bankruptcy prediction?arXiv:2511.16375,
-
[6]
doi: 10.29012/jpc.778. 5 TabPATE: Differentially Private Tabular In-Context Learning Without Public Data McKenna, R., Miklau, G., and Sheldon, D. AIM: An Adap- tive and Iterative Mechanism for Differentially Private Synthetic Data. InAdvances in Neural Information Pro- cessing Systems, volume 35,
- [7]
-
[8]
Causal Foundation Models with Continuous Treatments
Stith, C., Barath, M., Balazadeh, V ., Cresswell, J. C., and Kr- ishnan, R. G. Causal Foundation Models with Continuous Treatments.arXiv:2605.15133,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
L., and Jagielski, M
Tramer, F., Shokri, R., San Joaquin, A., Le, H., Saez, M., Canonne, C. L., and Jagielski, M. Truth Serum: Poison- ing Machine Learning Models to Reveal Their Secrets. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pp. 2779–2792,
2022
-
[10]
Sampling queries from these estimates is post-processing
We then compute ˜µand ˜σfrom these noisy sufficient statistics. Sampling queries from these estimates is post-processing. Privacy guarantee.TabPATE operates in the central- DP model. We state the guarantee for the released student context eD. Theorem B.1.For any α∈[0,1] , TabPATE satisfies(ε, δ)-DP under add/remove adjacency, assuming the optional margina...
2018
-
[11]
It requires access to unlabeled public data from the same distribution as the private data, which limits applicability in sensitive domains
partitions the private data among ICL teachers and uses public in- distribution data for the private knowledge transfer via Confident-GNMax (Papernot et al., 2018). It requires access to unlabeled public data from the same distribution as the private data, which limits applicability in sensitive domains. Query-Time.Query-Time, inspired by (Nissim et al., ...
2018
-
[12]
11 TabPATE: Differentially Private Tabular In-Context Learning Without Public Data Table 13.Balanced accuracy at ε= 1 and ε= 10 for each dataset(mean ± std across seeds)
Non-private ICL remains vulnerable even at tens of thousands of samples, although leakage decreases on some larger datasets, consistent with the privacy onion effect (Carlini et al., 2022b) with potential fairness implications (Cresswell, 2025). 11 TabPATE: Differentially Private Tabular In-Context Learning Without Public Data Table 13.Balanced accuracy a...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.