CLExEval: A Human-in-the-Loop Framework for Qualitative Evaluation of LLM Clinical Reasoning
Pith reviewed 2026-07-01 05:30 UTC · model grok-4.3
The pith
Standalone automated evaluations of LLM clinical reasoning overestimate reliability without expert validation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
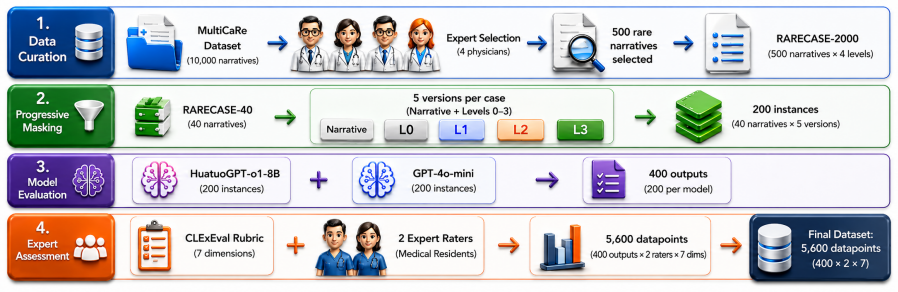
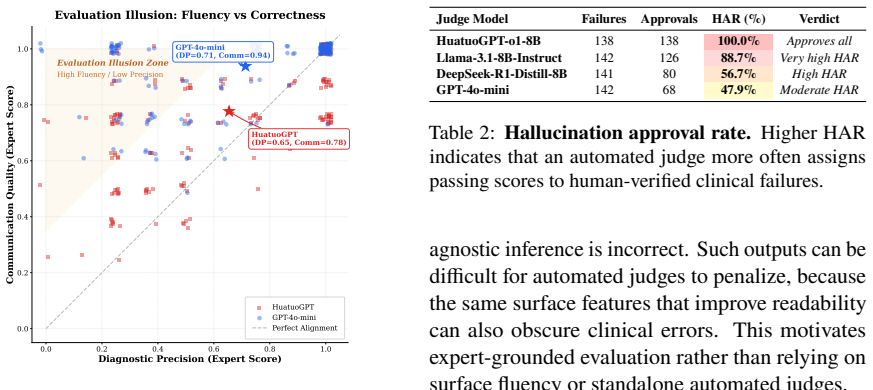
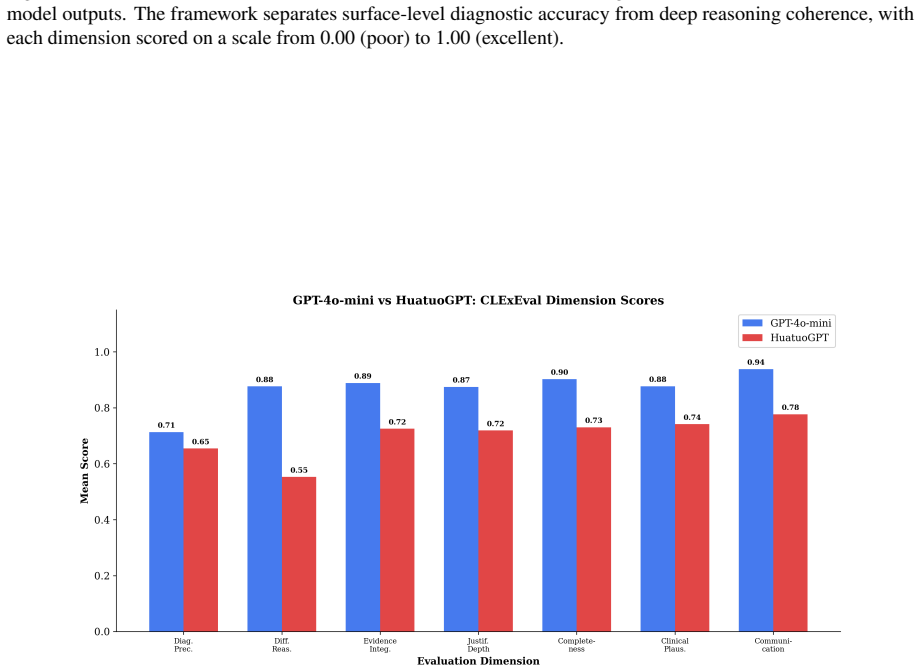
CLExEval combines expert annotations with masked clinical cases to expose that LLMs exhibit verbosity bias, hidden knowledge issues, and reasoning mismatches, while LLM judges approve 47.9 percent of incorrect outputs, indicating that automated evaluations overestimate clinical reliability.
What carries the argument
CLExEval framework using progressive information masking on rare cases combined with expert physician annotations to assess reasoning traces.
Load-bearing premise
The 40 rare diagnostic cases together with progressive information masking and the 5,600 physician annotations provide a representative and unbiased measure of LLM clinical reasoning performance.
What would settle it
A study using common cases or different masking that finds LLM judges matching human accuracy on incorrect outputs would challenge the overestimation finding.
Figures




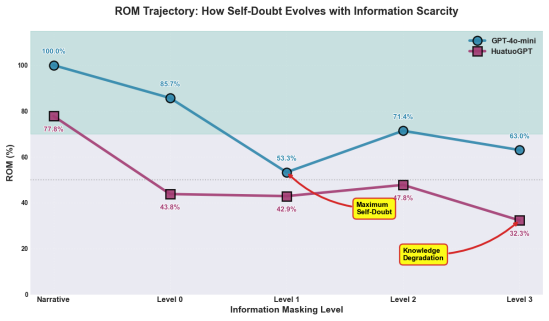
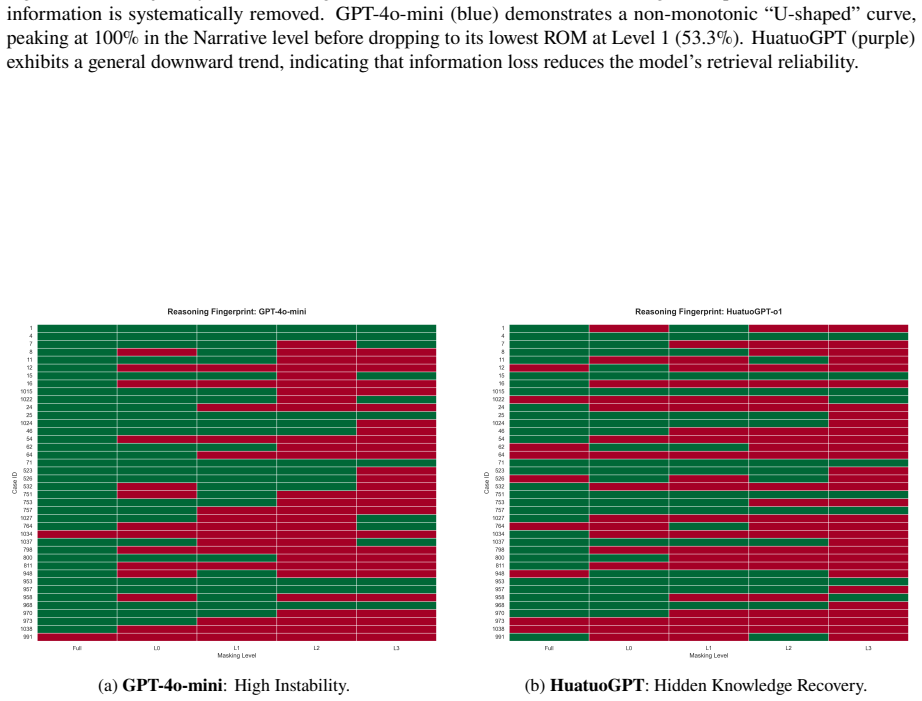
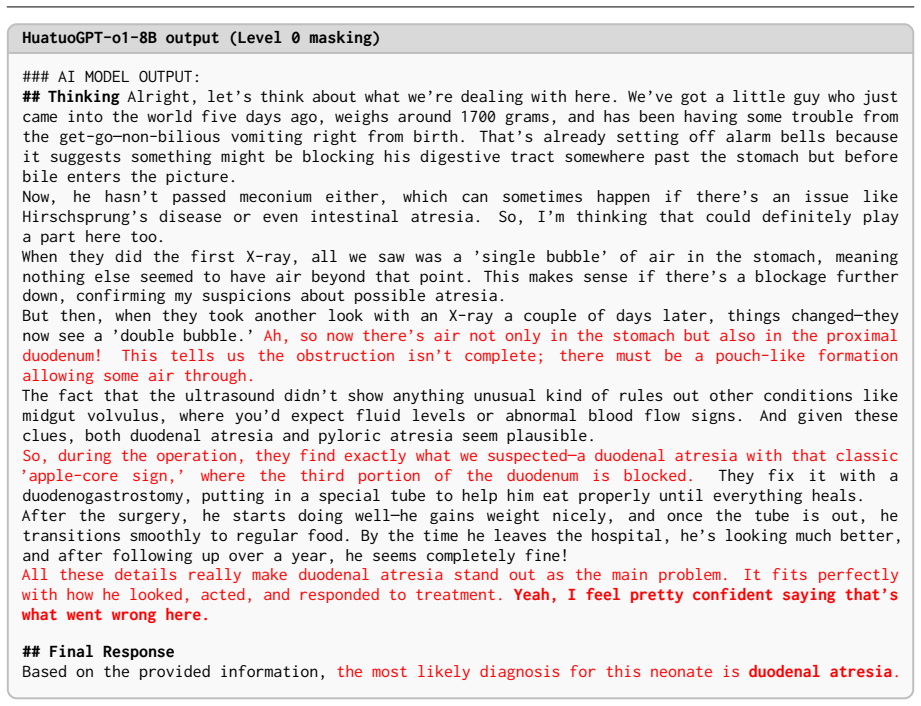

read the original abstract
Large Language Models (LLMs) achieve strong results on many medical benchmarks, but their clinical reasoning remains difficult to evaluate reliably. A central risk is an evaluation illusion: fluent and well-structured explanations can appear clinically convincing even when the final diagnosis is incorrect. We introduce CLExEval, a human-in-the-loop framework for evaluating LLM clinical reasoning under progressive information masking. CLExEval combines 5,600 expert-physician annotations with 200 clinical reasoning traces derived from 40 rare diagnostic cases. Our analysis identifies three recurring failure patterns: (i) verbosity bias, where GPT-4o-mini's diagnostic accuracy drops from 95.0% to 32.5% under information scarcity; (ii) a hidden knowledge paradox, where a specialist model reaches 92.5% maximum diagnostic potential but fails to retrieve that knowledge reliably in verbose contexts; and (iii) a 68.6% reasoning-to-output mismatch, where correct diagnoses appear in reasoning traces but are not reflected in final answers. We further evaluate the LLM-as-a-Judge paradigm on a human-verified failure set (n = 142). GPT-4o-mini approved 47.9% of clinically incorrect outputs, while HuatuoGPT-o1 approved all validly scored failures and showed a positive self-preference bias. These results suggest that standalone automated clinical evaluations can substantially overestimate clinical reliability without expert-grounded validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CLExEval, a human-in-the-loop framework for evaluating LLM clinical reasoning via progressive information masking. It derives 200 reasoning traces from 40 rare diagnostic cases, collects 5,600 expert-physician annotations, and reports three failure patterns: verbosity bias (GPT-4o-mini accuracy falling from 95.0% to 32.5%), a hidden knowledge paradox (specialist model at 92.5% potential but unreliable retrieval), and 68.6% reasoning-to-output mismatch. It further tests the LLM-as-Judge paradigm on a human-verified failure set (n=142), finding GPT-4o-mini approves 47.9% of incorrect outputs and HuatuoGPT-o1 shows self-preference bias. The central claim is that standalone automated clinical evaluations substantially overestimate reliability without expert-grounded validation.
Significance. If the empirical results hold, the work is significant for demonstrating concrete limitations of automated LLM evaluation in clinical domains through large-scale physician annotations. The progressive masking approach and identification of specific patterns (verbosity bias, mismatch) provide actionable insights. Credit is due for the scale of the annotation effort (5,600 annotations) and the grounding in external expert judgments rather than self-referential metrics.
major comments (2)
- [Case Selection / Dataset] The central claim that automated evaluations overestimate reliability generalizes from the 40 rare diagnostic cases; however, the manuscript provides no selection criteria, prevalence matching, or control cohort of common diagnoses to establish representativeness (see Case Selection and Dataset sections). If rare cases systematically differ in retrieval demands or failure modes, the observed patterns (68.6% mismatch, 47.9% judge approval) may not extend to general LLM clinical reasoning.
- [Abstract / Results] Abstract and Results: The quantitative claims (95.0% to 32.5% accuracy drop, 68.6% mismatch, 47.9% approval rate) are presented without statistical tests, confidence intervals, inter-annotator agreement, or data exclusion criteria. This absence is load-bearing because the support for the overestimation conclusion cannot be verified from the reported figures alone.
minor comments (1)
- [Abstract] The abstract packs many quantitative results without a brief methods overview; adding one sentence on annotation protocol or masking schedule would improve standalone readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. Below we provide point-by-point responses to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Case Selection / Dataset] The central claim that automated evaluations overestimate reliability generalizes from the 40 rare diagnostic cases; however, the manuscript provides no selection criteria, prevalence matching, or control cohort of common diagnoses to establish representativeness (see Case Selection and Dataset sections). If rare cases systematically differ in retrieval demands or failure modes, the observed patterns (68.6% mismatch, 47.9% judge approval) may not extend to general LLM clinical reasoning.
Authors: Our study intentionally focuses on rare diagnostic cases to identify failure modes in LLM clinical reasoning that may not be evident in more common scenarios. The cases were chosen to represent challenging diagnostic situations with high uncertainty. We will revise the manuscript to include explicit selection criteria for the 40 cases and add a dedicated limitations section addressing the generalizability of our findings to common diagnoses. We do not claim that the specific failure rates apply universally but rather that the evaluation framework reveals important limitations in automated assessments. revision: yes
-
Referee: [Abstract / Results] Abstract and Results: The quantitative claims (95.0% to 32.5% accuracy drop, 68.6% mismatch, 47.9% approval rate) are presented without statistical tests, confidence intervals, inter-annotator agreement, or data exclusion criteria. This absence is load-bearing because the support for the overestimation conclusion cannot be verified from the reported figures alone.
Authors: We agree that providing statistical support for the quantitative results is essential. In the revised manuscript, we will add confidence intervals for all reported percentages, include statistical tests where appropriate for comparing accuracies, report inter-annotator agreement for the physician annotations, and specify any data exclusion criteria used. These changes will allow readers to better assess the robustness of our conclusions. revision: yes
Circularity Check
Empirical study with external physician annotations; no circularity in derivation chain
full rationale
The paper presents an empirical framework (CLExEval) that collects 5,600 physician annotations on 200 reasoning traces from 40 cases and reports observed failure patterns (verbosity bias, knowledge paradox, reasoning-to-output mismatch) plus LLM-as-Judge results. No mathematical derivation, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described method. All central claims rest on direct human annotations rather than reducing to the paper's own inputs by construction. Representativeness concerns are a validity issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert physicians provide accurate and unbiased evaluations of clinical reasoning correctness
Reference graph
Works this paper leans on
-
[1]
Nievas Offidani, Mauro and Delrieux, Claudio , title =. 2023 , publisher =. doi:10.5281/zenodo.10079370 , url =
-
[2]
and Gulamali, Freya and Joshi, Shalmali , title =
Agrawal, Monica and Chen, Irene Y. and Gulamali, Freya and Joshi, Shalmali , title =. npj Digital Medicine , volume =. 2025 , month =. doi:10.1038/s41746-025-01963-x , url =
-
[4]
Bedi, Suhana and Jiang, Yixing and Chung, Philip and Koyejo, Sanmi and Shah, Nigam , title =. JAMA Network Open , volume =. 2025 , month =. doi:10.1001/jamanetworkopen.2025.26021 , url =
-
[6]
Wu, Weiyi and Xu, Xinwen and Gao, Chongyang and Diao, Xingjian and Li, Siting and Salas, Lucas A. and Gui, Jiang. Assessing and Mitigating Medical Knowledge Drift and Conflicts in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.38
-
[7]
LLME val- M ed: A Real-world Clinical Benchmark for Medical LLM s with Physician Validation
Zhang, Ming and Shen, Yujiong and Li, Zelin and Sha, Huayu and Hu, Binze and Wang, Yuhui and Huang, Chenhao and Liu, Shichun and Tong, Jingqi and Jiang, Changhao and Chai, Mingxu and Xi, Zhiheng and Dou, Shihan and Gui, Tao and Zhang, Qi and Huang, Xuanjing. LLME val- M ed: A Real-world Clinical Benchmark for Medical LLM s with Physician Validation. Findi...
-
[8]
Applied Sciences , VOLUME =
Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter , TITLE =. Applied Sciences , VOLUME =. 2021 , NUMBER =
2021
-
[9]
2025 , eprint=
Timely Clinical Diagnosis through Active Test Selection , author=. 2025 , eprint=
2025
-
[10]
Advances in Neural Information Processing Systems , volume =
Simulating Viva Voce Examinations to Evaluate Clinical Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2025 , url =
2025
-
[11]
Advances in Neural Information Processing Systems , volume =
Wang, Bowen and Chang, Jiuyang and Qian, Yiming and Chen, Guoxin and Chen, Junhao and Jiang, Zhouqiang and Zhang, Jiahao and Nakashima, Yuta and Nagahara, Hajime , title =. Advances in Neural Information Processing Systems , volume =. 2024 , address =. doi:10.52202/079017-2386 , note =
-
[12]
Nature Communications , volume =
Qiu, Pengcheng and Wu, Chaoyi and Liu, Shuyu and Fan, Yanjie and Zhao, Weike and Chen, Zhuoxia and Gu, Hongfei and Peng, Chuanjin and Zhang, Ya and Wang, Yanfeng and Xie, Weidi , title =. Nature Communications , volume =. 2025 , month =
2025
-
[13]
Advances in Neural Information Processing Systems , volume =
Ruhrberg Estévez, Silas and Astorga, Nicolás and van der Schaar, Mihaela , title =. Advances in Neural Information Processing Systems , volume =. 2025 , note =
2025
-
[14]
Rahul K. Arora and Jason Wei and Rebecca Soskin Hicks and Preston Bowman and Joaquin Quiñonero-Candela and Foivos Tsimpourlas and Michael Sharman and Meghan Shah and Andrea Vallone and Alex Beutel and Johannes Heidecke and Karan Singhal , year=. 2505.08775 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Evaluation of
Wang, Xinran and Long, Ziwen and Zhu, Boran and Cao, Yan and Tang, Hanfei and He, Ke and Zhang, Shu , journal=. Evaluation of. 2026 , doi=
2026
-
[16]
2026 , doi=
Bianchi, Owen and Willey, Maya and Alvarado, Chelsea X and Danek, Benjamin and Khani, Marzieh and Kuznetsov, Nicole and Dadu, Anant and Shah, Syed and Koretsky, Mathew J and Makarious, Mary B and others , journal=. 2026 , doi=
2026
-
[17]
JAMA Network Open , volume=
Large language model performance and clinical reasoning tasks , author=. JAMA Network Open , volume=. 2026 , doi=
2026
-
[18]
npj Digital Medicine , year=
ClinicRealm: Re-evaluating large language models with conventional machine learning for non-generative clinical prediction tasks , author=. npj Digital Medicine , year=
-
[19]
Evaluation of causal reasoning for large language models in contextualized clinical scenarios of laboratory test interpretation , author=. npj Digital Medicine , year=. doi:10.1038/s41746-026-02632-3 , url=
-
[20]
npj Digital Medicine , year=
Rethinking scale in ophthalmic artificial intelligence: from bigger models to smarter clinical reasoning , author=. npj Digital Medicine , year=
-
[21]
Benchmarking Large Language Models on Answering and Explaining Challenging Medical Questions , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2025 , address=. doi:10.18653/v1/2025.naacl-long.182 , url=
-
[22]
JAMA , volume=
Accuracy of a generative artificial intelligence model in a complex diagnostic challenge , author=. JAMA , volume=
-
[23]
JAMA Internal Medicine , volume=
Clinical reasoning of a generative artificial intelligence model compared with physicians , author=. JAMA Internal Medicine , volume=
-
[24]
NEJM AI , volume=
Assessment of large language models in clinical reasoning: a novel benchmarking study , author=. NEJM AI , volume=. 2025 , doi=
2025
-
[25]
2022 , address=
Pal, Ankit and Umapathi, Logesh Kumar and Sankarasubbu, Malaikannan , booktitle=. 2022 , address=
2022
-
[26]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[27]
, author=
Bridging the Gap Between Consumers' Medication Questions and Trusted Answers. , author=. MedInfo , volume=
-
[28]
Fleming, Scott L and Lozano, Alejandro and Haberkorn, William J and Jindal, Jenelle A and Reis, Eduardo and Thapa, Rahul and Blankemeier, Louis and Genkins, Julian Z and Steinberg, Ethan and Nayak, Ashwin and others , booktitle=. 2024 , address=. doi:10.1609/aaai.v38i20.30205 , url=
-
[29]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang and Kameron C. Black and Gloria Geng and Danny Park and James Zou and Andrew Y. Ng and Jonathan H. Chen , title =. NEJM AI , volume =. 2025 , doi =. https://ai.nejm.org/doi/pdf/10.1056/AIdbp2500144 , abstract =
-
[30]
Bavaresco, Anna and Bernardi, Raffaella and Bertolazzi, Leonardo and Elliott, Desmond and Fern. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=. 2025 , address=. doi:10.18653/v1/2025.acl-short.20 , url=
-
[31]
The Knowledge-Reasoning Dissociation: Fundamental Limitations of
Jullien, Ma. The Knowledge-Reasoning Dissociation: Fundamental Limitations of. 2025 , eprint=. doi:10.48550/arXiv.2508.10777 , url=
-
[32]
Diekmann, Yella and Fensore, Chase and Carrillo-Larco, Rodrigo and Rosales, Eduard Castejon and Shiromani, Sakshi and Pai, Rima and Shah, Megha and Ho, Joyce , booktitle=. 2025 , address=. doi:10.18653/v1/2025.bionlp-1.19 , url=
-
[33]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[34]
Ji, Ziwei and Yu, Tiezheng and Xu, Yan and Lee, Nayeon and Ishii, Etsuko and Fung, Pascale , booktitle=. Towards Mitigating. 2023 , address=. doi:10.18653/v1/2023.findings-emnlp.123 , url=
-
[35]
Faithful logical reasoning via symbolic chain-of-thought , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , address=. doi:10.18653/v1/2024.acl-long.720 , url=
-
[36]
II-Medical-8B: Medical Reasoning Model , author=
-
[37]
MedGemma Technical Report , author=. arXiv preprint arXiv:2507.05201 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[39]
Educational and Psychological Measurement , volume =
Jacob Cohen , title =. Educational and Psychological Measurement , volume =. 1960 , doi =
1960
-
[40]
Computing
Krippendorff, Klaus , year=. Computing
-
[41]
Tukey , journal =
John W. Tukey , journal =. Comparing Individual Means in the Analysis of Variance , urldate =
-
[42]
Discovering Statistics Using
Field, Andy , year=. Discovering Statistics Using
-
[43]
and Pierson, Emma and Koh, Pang Wei and Tsvetkov, Yulia , booktitle =
Li, Shuyue Stella and Balachandran, Vidhisha and Feng, Shangbin and Ilgen, Jonathan S. and Pierson, Emma and Koh, Pang Wei and Tsvetkov, Yulia , booktitle =. MediQ: Question-Asking LLMs and a Benchmark for Reliable Interactive Clinical Reasoning , url =. doi:10.52202/079017-0908 , editor =
-
[45]
He, Zexue and Wang, Yu and Yan, An and Liu, Yao and Chang, Eric and Gentili, Amilcare and McAuley, Julian and Hsu, Chun-Nan. M ed E val: A Multi-Level, Multi-Task, and Multi-Domain Medical Benchmark for Language Model Evaluation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.540
-
[46]
Tao and Min Woo Sun and Alejandro Lozano and James Zou , journal =
Kevin Wu and Eric Wu and Rahul Thapa and Kevin Wei and Angela Zhang and Arvind Suresh and Jacqueline J. Tao and Min Woo Sun and Alejandro Lozano and James Zou , journal =
-
[47]
Yu Sun and Xingyu Qian and Weiwen Xu and Hao Zhang and Chenghao Xiao and Long Li and Yu Rong and Wenbing Huang and Qifeng Bai and Tingyang Xu , journal =
-
[48]
A Survey of Large Language Models
A Survey of Large Language Models , author =. arXiv preprint arXiv:2303.18223 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Zhuohan Xie and Rui Xing and Yuxia Wang and Jiahui Geng and Hasan Iqbal and Dhruv Sahnan and Iryna Gurevych and Preslav Nakov , booktitle =. 2025 , address =. doi:10.18653/v1/2025.findings-naacl.158 , pages =
-
[51]
2025 , url =
Zhuohan Xie and Daniil Orel and Rushil Thareja and Dhruv Sahnan and Hachem Madmoun and Fan Zhang and Debopriyo Banerjee and Georgi Georgiev and Xueqing Peng and Lingfei Qian and Jimin Huang and Jinyan Su and Aaryamonvikram Singh and Rui Xing and Rania Elbadry and Chen Xu and Haonan Li and Fajri Koto and Ivan Koychev and Tanmoy Chakraborty and Yuxia Wang a...
2025
-
[52]
arXiv preprint arXiv:2506.01793 , year=
Human-Centric Evaluation for Foundation Models , author=. arXiv preprint arXiv:2506.01793 , year=
-
[53]
arXiv preprint arXiv:2505.23802 , year=
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks , author=. arXiv preprint arXiv:2505.23802 , year=
-
[54]
Frontiers in Artificial Intelligence , year =
Moëll, Birger and Aronsson, Fredrik and Akbar, Sanian , title =. Frontiers in Artificial Intelligence , year =. doi:10.3389/frai.2025.1616145 , url =
-
[55]
2024 , note=
Smith, John and Doe, Jane and others , journal=. 2024 , note=
2024
-
[56]
Kang, Tian and others , journal=
-
[57]
and Alaa, Ahmed , journal=
Mehandru, Nikita and Golchini, Niloufar and Bamman, David and Zack, Travis and Molina, Melanie F. and Alaa, Ahmed , journal=
-
[58]
Qiu, Pengcheng and Wu, Chaoyi and Liu, Shuyu and Zhao, Weike and Chen, Zhuoxia and Gu, Hongfei and Peng, Chuanjin and Zhang, Ya and Wang, Yanfeng and Xie, Weidi , journal=
-
[59]
Kahn, Jessica N and Chen, Albert and others , journal=
-
[60]
Chest , year=
Clinical reasoning and artificial intelligence: can AI really think? , author=. Chest , year=
-
[61]
2024 , volume=
Jansen, Yannick and Spruit, Marco , journal=. 2024 , volume=
2024
-
[62]
2024 , doi=
Liao, Han and He, Tianle and Zhang, Zhaozhen and others , journal=. 2024 , doi=
2024
-
[63]
Rezaeihaghighi, Niloofar and Pakhchanian, Hakop and Khademian, Reza and Moshirpour, Mohammadreza , title=. Data in Brief , volume=. 2023 , publisher=. doi:10.1016/j.dib.2023.109403 , url=
-
[64]
Sim, Shamus Zi Yang and Chen, Tyrone , title =. eLife , volume =. 2025 , pages =. doi:10.7554/eLife.106187 , url =
-
[65]
Proceedings of EMNLP 2023 , year =
He, Zexue and others , title =. Proceedings of EMNLP 2023 , year =
2023
-
[66]
Journal of Medical Internet Research , volume =
Dennstädt, Florian and others , title =. Journal of Medical Internet Research , volume =. 2025 , pages =. doi:10.2196/69752 , url =
-
[67]
Shen, Jiaxin and Xu, Jinan and Hu, Huiqi and Lin, Luyi and Ma, Guoyang and Zheng, Fei and Meng, Fandong and Zhou, Jie and Han, Wenjuan. A Law Reasoning Benchmark for LLM with Tree-Organized Structures including Factum Probandum, Evidence and Experiences. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findin...
-
[68]
2013 , publisher=
Sandve, Geir Kjetil and Nekrutenko, Anton and Taylor, James and Hovig, Eivind , journal=. 2013 , publisher=
2013
-
[69]
Creswell, John W and Poth, Cheryl N , year=
-
[70]
and Levi, Antonia J
Stevens, Dannelle D. and Levi, Antonia J. , year=
-
[71]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen and Zhenyang Cai and Ke Ji and Xidong Wang and Wanlong Liu and Rongsheng Wang and Jianye Hou and Benyou Wang , year=. 2412.18925 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
ARABICNLP , year=
AraFinNLP 2024: The First Arabic Financial NLP Shared Task , author=. ARABICNLP , year=
2024
-
[73]
ArXiv , year=
CIDAR: Culturally Relevant Instruction Dataset For Arabic , author=. ArXiv , year=
-
[74]
2024 , url =
MAGNiTT , title =. 2024 , url =
2024
-
[75]
2023 , url =
McKinsey & Company , title =. 2023 , url =
2023
-
[76]
2025 , url=
Finance-Instruct-500k , author=. 2025 , url=
2025
-
[77]
ArXiv , year=
No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks , author=. ArXiv , year=
-
[78]
Xiao Zhang and Ruoyu Xiang and Chenhan Yuan and Duanyu Feng and Weiguang Han and Alejandro Lopez-Lira and Xiao-Yang Liu and Meikang Qiu and Sophia Ananiadou and Min Peng and Jimin Huang and Qianqian Xie , journal=. D. 2024 , url=
2024
-
[79]
Finetuned Language Models Are Zero-Shot Learners
Finetuned language models are zero-shot learners , author=. arXiv preprint arXiv:2109.01652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[81]
arXiv preprint arXiv:2306.05443 , year=
Pixiu: A large language model, instruction data and evaluation benchmark for finance , author=. arXiv preprint arXiv:2306.05443 , year=
-
[82]
Weinberger and Yoav Artzi , title =
Tianyi Zhang and Varsha Kishore and Felix Wu and Kilian Q. Weinberger and Yoav Artzi , title =. 8th International Conference on Learning Representations,. 2020 , url =
2020
-
[83]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[84]
2024 , month =
AI Mistral , title =. 2024 , month =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.