Nonlinearity-Aware LoRA: Structured Gate Adaptation under Low-Rank Constraints
Pith reviewed 2026-07-01 05:59 UTC · model grok-4.3
The pith
NA-LoRA corrects selection misalignment in gated Transformers by masking LoRA updates according to gate derivatives and scaling steps by activation homogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
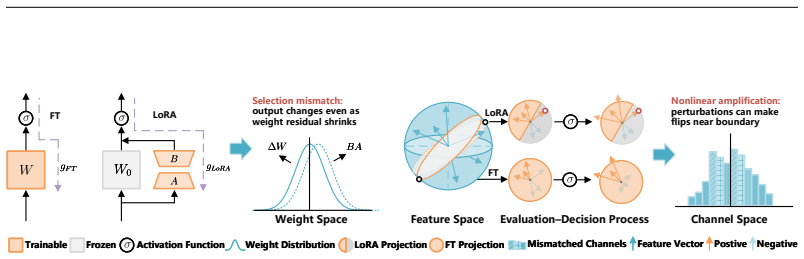
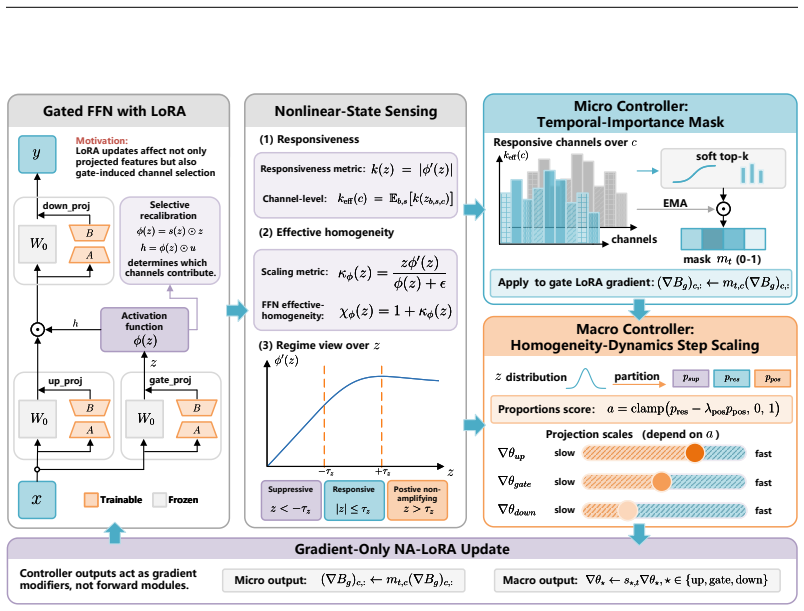
In gated FFNs a low-rank residual changes not only the projected features but also the nonlinear selection weights that decide channel contribution; this effect is formalized as selection misalignment and tied to local effective homogeneity of self-gated activations. NA-LoRA therefore allocates low-rank capacity only to gate channels whose nonlinear states remain responsive and shapes the temporal evolution of that selection via a derivative-based temporal-importance mask and an activation-specific step-scaling rule.
What carries the argument
Derivative-based temporal-importance mask on gate-related LoRA updates together with activation-specific step scaling, which together enforce nonlinearity-aware allocation of low-rank capacity.
If this is right
- Low-rank updates should be directed toward gate channels whose nonlinear responses remain sensitive rather than uniformly across all channels.
- When a coarse effective-homogeneity partition of activations is known, step sizes for the corresponding LoRA matrices should be scaled accordingly.
- The method adds no auxiliary loss and zero inference overhead, so the performance gains come solely from the structured adaptation during training.
- NA-LoRA remains competitive with or superior to other strong PEFT methods on both language-model fine-tuning and vision-language transfer tasks.
Where Pith is reading between the lines
- The same derivative-masking idea could be applied to other nonlinear components inside the Transformer, such as attention softmax or layer-norm gates.
- If selection misalignment is the dominant issue, replacing the hand-crafted mask with a learned importance predictor might further improve results.
- The approach suggests that any low-rank method applied to gated networks should at minimum track the derivative of the gate with respect to the update direction.
Load-bearing premise
The derivative mask and step-scaling rule reduce selection misalignment in practice rather than merely supplying extra degrees of freedom that happen to help the tested benchmarks.
What would settle it
An ablation that keeps the same number of trainable parameters but removes the derivative mask and step-scaling rule while still matching or exceeding NA-LoRA performance on the same tasks would falsify the claim that the mechanisms specifically address misalignment.
Figures
read the original abstract
Low-rank adaptation (LoRA) is commonly viewed as an update-space approximation to full fine-tuning, yet this view is incomplete for self-gated Transformer feed-forward networks. In gated FFNs, a low-rank residual can change not only projected features but also the nonlinear selection weights that determine which channels contribute to the output. We formalize this effect as selection misalignment and connect it to the local effective homogeneity of self-gated activations. This motivates a nonlinearity-aware principle for parameter-efficient fine-tuning: low-rank updates should allocate capacity to gate channels whose nonlinear states remain responsive and should shape the temporal evolution of selection. We propose NA-LoRA, a training-only method with two lightweight mechanisms: a derivative-based temporal-importance mask for gate-related LoRA updates and an activation-specific step-scaling rule when a meaningful coarse effective-homogeneity partition is available. NA-LoRA adds no auxiliary loss and incurs no inference-time overhead. Experiments on language-model fine-tuning and vision-language transfer benchmarks show that NA-LoRA consistently improves over vanilla LoRA and is competitive with or better than strong PEFT variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes 'selection misalignment' in low-rank adaptation of self-gated Transformer FFNs, where LoRA updates affect both projected features and nonlinear gate selection weights tied to local effective homogeneity. It proposes NA-LoRA, a training-only method using a derivative-based temporal-importance mask on gate LoRA updates and an activation-specific step-scaling rule (when a coarse homogeneity partition exists). The method adds no auxiliary loss or inference overhead. Experiments on LM fine-tuning and VLM transfer benchmarks are claimed to show consistent gains over vanilla LoRA and competitiveness with other PEFT variants.
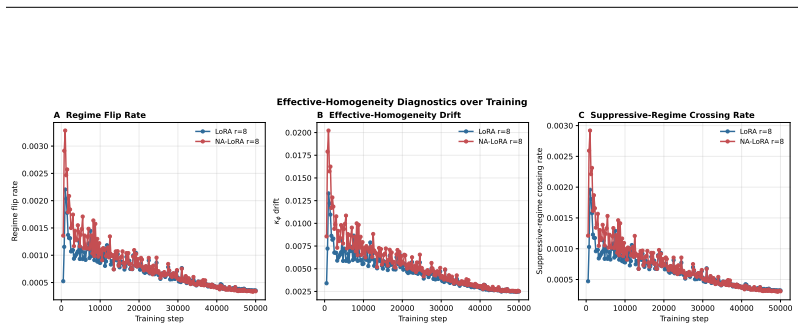
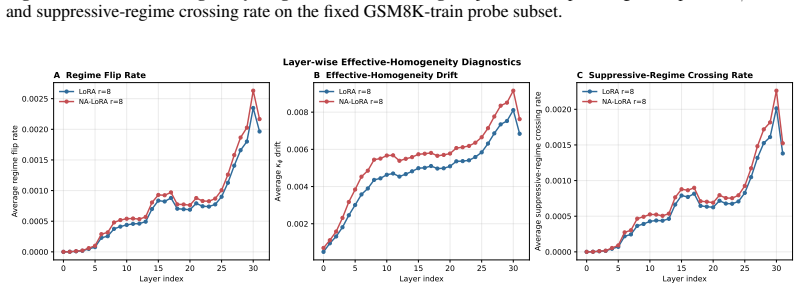
Significance. If the two mechanisms are shown to drive the gains specifically by mitigating selection misalignment (rather than incidental extra degrees of freedom), the work would strengthen the case for nonlinearity-aware PEFT design in gated architectures. The training-only, no-overhead nature and absence of auxiliary losses are practical strengths that would make adoption straightforward if the central claim holds.
major comments (2)
- [§4 (Experiments) and associated ablations] §4 (Experiments) and associated ablations: the manuscript reports consistent improvements but does not include control experiments (e.g., random masks of matched density/sparsity or uniform scaling baselines) that would distinguish whether gains arise from the derivative-based temporal-importance mask and step-scaling specifically reducing selection misalignment, or from any comparable modification to update magnitudes and hyperparameters.
- [§3 (formalization of selection misalignment)] §3 (formalization of selection misalignment): the connection between the derivative mask, step-scaling, and 'local effective homogeneity' is presented as motivation, but the paper does not provide a quantitative metric or falsifiable prediction showing that the proposed rules measurably reduce misalignment beyond what would be expected from modified training dynamics alone.
minor comments (2)
- [Abstract] Abstract: quantitative results, baseline names, and statistical significance are omitted, making it difficult to assess the magnitude of claimed improvements without reading the full experimental section.
- [§3] Notation: the precise definition of the temporal-importance mask (how the derivative is computed and thresholded) and the step-scaling rule should be stated with an equation early in §3 for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The points raised about control experiments and quantitative validation of misalignment reduction are fair and will be addressed through revisions to strengthen the empirical support for the proposed mechanisms.
read point-by-point responses
-
Referee: [§4 (Experiments) and associated ablations] §4 (Experiments) and associated ablations: the manuscript reports consistent improvements but does not include control experiments (e.g., random masks of matched density/sparsity or uniform scaling baselines) that would distinguish whether gains arise from the derivative-based temporal-importance mask and step-scaling specifically reducing selection misalignment, or from any comparable modification to update magnitudes and hyperparameters.
Authors: We agree that the current experiments and ablations do not include the suggested random-mask and uniform-scaling controls. These would help isolate whether the observed gains are specifically due to the nonlinearity-aware rules. In the revised manuscript we will add matched-density random masks and uniform scaling baselines on the same benchmarks to address this distinction. revision: yes
-
Referee: [§3 (formalization of selection misalignment)] §3 (formalization of selection misalignment): the connection between the derivative mask, step-scaling, and 'local effective homogeneity' is presented as motivation, but the paper does not provide a quantitative metric or falsifiable prediction showing that the proposed rules measurably reduce misalignment beyond what would be expected from modified training dynamics alone.
Authors: The formalization in §3 supplies the conceptual link to local effective homogeneity, yet we acknowledge the absence of an explicit quantitative metric or falsifiable test of misalignment reduction. We will introduce a simple metric based on pre- and post-adaptation gate responsiveness (e.g., derivative-weighted selection entropy) together with a corresponding prediction in the revised version. revision: yes
Circularity Check
No significant circularity; derivation introduces independent mechanisms validated by external benchmarks
full rationale
The paper formalizes selection misalignment from gated FFN behavior and motivates two training-only mechanisms (derivative-based temporal-importance mask and activation-specific step-scaling) without auxiliary loss. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or result to the inputs by construction. The central claims rest on experimental improvements over LoRA and PEFT variants on LM and VLM benchmarks, which constitute independent falsifiable evidence rather than definitional equivalence. This is the most common honest outcome for a method paper whose contributions are additive hyperparameters and empirical gains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report , author =. arXiv preprint arXiv:2303.08774 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , booktitle =
-
[3]
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , booktitle =
Aghajanyan, Armen and Gupta, Sonal and Zettlemoyer, Luke , editor =. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , booktitle =. doi:10.18653/v1/2021.acl-long.568 , urldate =
-
[4]
Simple, Scalable Adaptation for Neural Machine Translation , booktitle =
-
[5]
Language models are few-shot learners , booktitle =
-
[6]
AdaShift: Learning Discriminative Self-Gated Neural Feature Activation With an Adaptive Shift Factor , author =
-
[7]
IIEU: Rethinking Neural Feature Activation from Decision-Making , author =
-
[8]
Toward Principled Flexible Scaling for Self-Gated Neural Activation , author =
-
[9]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author =. arXiv preprint arXiv:2107.03374 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the IEEE , volume =
Remote sensing image scene classification: Benchmark and state of the art , author =. Proceedings of the IEEE , volume =
-
[11]
Describing textures in the wild , booktitle =
-
[12]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author =. arXiv preprint arXiv:2110.14168 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Nature Machine Intelligence , volume =
Parameter-efficient fine-tuning of large-scale pre-trained language models , author =. Nature Machine Intelligence , volume =
-
[14]
The llama 3 herd of models , author =. arXiv preprint arXiv:2407.21783 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Krona: Parameter efficient tuning with kronecker adapter , booktitle =
-
[16]
arXiv.org , urldate =
The Llama 3 Herd of Models , author =. arXiv.org , urldate =
-
[17]
LoRA+: Efficient Low Rank Adaptation of Large Models , booktitle =
Hayou, Soufiane and Ghosh, Nikhil and Yu, Bin , year = 2024, urldate =. LoRA+: Efficient Low Rank Adaptation of Large Models , booktitle =
2024
-
[18]
On the Effectiveness of Adapter-based Tuning for Pretrained Language Model Adaptation , booktitle =
-
[19]
GoRA: Gradient-driven Adaptive Low Rank Adaptation , booktitle =
He, Haonan and Ye, Peng and Ren, Yuchen and Yuan, Yuan and LuyangZhou and ShucunJu and Chen, Lei , year = 2025, urldate =. GoRA: Gradient-driven Adaptive Low Rank Adaptation , booktitle =
2025
-
[20]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume =
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author =. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume =
-
[21]
Training compute-optimal large language models , booktitle =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and. Training compute-optimal large language models , booktitle =
-
[22]
Detection of traffic signs in real-world images: The German Traffic Sign Detection Benchmark , booktitle =
-
[23]
Parameter-efficient transfer learning for NLP , booktitle =
-
[24]
LoRA: Low-Rank Adaptation of Large Language Models , booktitle =
Hu, Edward J and Wallis, Phillip and. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =
-
[25]
FedPara: Low-rank Hadamard Product for Communication-Efficient Federated Learning , booktitle =
-
[26]
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
A Rank Stabilization Scaling Factor for Fine-tuning with LoRA , author =. arXiv preprint arXiv:2312.03732 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author =. arXiv preprint arXiv:2001.08361 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[28]
Segment anything , booktitle =
-
[29]
VeRA: Vector-based Random Matrix Adaptation , booktitle =
-
[30]
3d object representations for fine-grained categorization , booktitle =
Krause, Jonathan and Stark, Michael and Deng, Jia and. 3d object representations for fine-grained categorization , booktitle =
-
[31]
The Power of Scale for Parameter-Efficient Prompt Tuning , booktitle =
Lester, Brian and. The Power of Scale for Parameter-Efficient Prompt Tuning , booktitle =
-
[32]
Measuring the Intrinsic Dimension of Objective Landscapes , booktitle =
-
[33]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , booktitle =
-
[34]
Realistic Unsupervised CLIP Fine-tuning with Universal Entropy Optimization , booktitle =
-
[35]
P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks , booktitle =
-
[36]
ACM Computing Surveys , volume =
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author =. ACM Computing Surveys , volume =
-
[37]
DoRA: Weight-Decomposed Low-Rank Adaptation , booktitle =
-
[38]
Decoupled Weight Decay Regularization , booktitle =
- [39]
-
[40]
Reading digits in natural images with unsupervised feature learning , booktitle =
-
[41]
Learning transferable visual models from natural language supervision , booktitle =
-
[42]
Journal of machine learning research , volume =
Exploring the limits of transfer learning with a unified text-to-text transformer , author =. Journal of machine learning research , volume =
-
[43]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , booktitle =
Rasley, Jeff and Rajbhandari, Samyam and Ruwase, Olatunji and He, Yuxiong , year = 2020, pages =. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , booktitle =
2020
-
[44]
High-resolution image synthesis with latent diffusion models , booktitle =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj. High-resolution image synthesis with latent diffusion models , booktitle =
-
[45]
Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks , booktitle =
-
[46]
On the importance of initialization and momentum in deep learning , booktitle =
-
[47]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author =. arXiv preprint arXiv:2307.09288 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , booktitle =
-
[49]
Improving Zero-Shot Generalization for CLIP with Synthesized Prompts , booktitle =
Wang, Zhengbo and Liang, Jian and He, Ran and Xu, Nan and Wang, Zilei and Tan, Tieniu , author+duplicate-1 =. Improving Zero-Shot Generalization for CLIP with Synthesized Prompts , booktitle =
-
[50]
A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation , booktitle =
-
[51]
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models , booktitle =
-
[52]
LoRA-GA: Low-Rank Adaptation with Gradient Approximation , booktitle =
-
[53]
Batched Low-Rank Adaptation of Foundation Models , booktitle =
-
[54]
Sun database: Large-scale scene recognition from abbey to zoo , booktitle =
-
[55]
WizardLM: Empowering large pre-trained language models to follow complex instructions , booktitle =
-
[56]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , booktitle =
Yu, Longhui and Jiang, Weisen and Shi, Han and Jincheng,. MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , booktitle =
-
[57]
Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , booktitle =
-
[58]
LLaMA-adapter: Efficient fine-tuning of large language models with zero-initialized attention , booktitle =
-
[59]
Riemannian Preconditioned LoRA for Fine-Tuning Foundation Models , booktitle =
-
[60]
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection , booktitle =
-
[61]
Judging llm-as-a-judge with mt-bench and chatbot arena , booktitle =
-
[62]
OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement , booktitle =
-
[63]
International Journal of Computer Vision , volume =
Learning to prompt for vision-language models , author =. International Journal of Computer Vision , volume =
-
[64]
LoRA-Pro: Are Low-Rank Adapters Properly Optimized? , booktitle =
-
[65]
AuroRA: Breaking Low-Rank Bottleneck of LoRA with Nonlinear Mapping , booktitle =
Dong, Haonan and Zhu, Wenhao and Song, Guojie and Wang, Liang , year = 2025, urldate =. AuroRA: Breaking Low-Rank Bottleneck of LoRA with Nonlinear Mapping , booktitle =
2025
-
[66]
BoRA: Towards More Expressive Low-Rank Adaptation with Block Diversity , booktitle =
Li, Shiwei and Luo, Xiandi and Wang, Haozhao and Tang, Xing and Cui, Ziqiang and Liu, Dugang and Li, Yuhua and Li, Yichen and He, Xiuqiang and Li, Ruixuan , year = 2026, urldate =. BoRA: Towards More Expressive Low-Rank Adaptation with Block Diversity , booktitle =
2026
-
[67]
Gradient Intrinsic Dimensionality Alignment: Narrowing The Gap Between Low-Rank Adaptation and Full Fine-Tuning , booktitle =
Ye, Jingqi and He, Haonan and Li, Minglei and Han, Fujun and Chen, Tao and Ye, Peng , year = 2026, urldate =. Gradient Intrinsic Dimensionality Alignment: Narrowing The Gap Between Low-Rank Adaptation and Full Fine-Tuning , booktitle =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.