UniCoder: Unified Visual-to-Code Generation via Symbolic Rewards and Reference-Guided Code Optimization
Pith reviewed 2026-07-01 05:31 UTC · model grok-4.3
The pith
UniCoder's RL framework uses symbolic parsing for dense rewards and reference injection to let an 8B model match proprietary visual-to-code performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
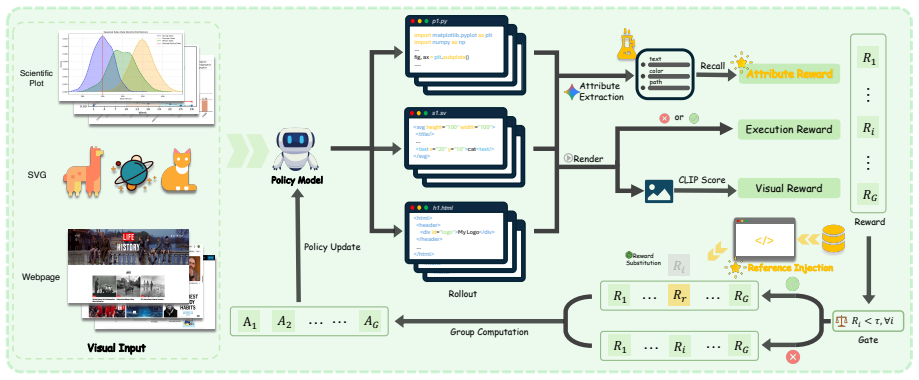
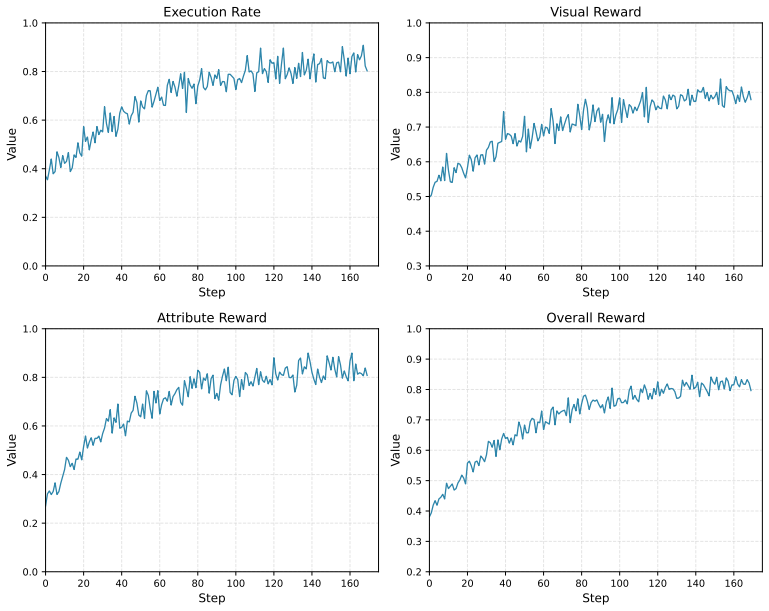
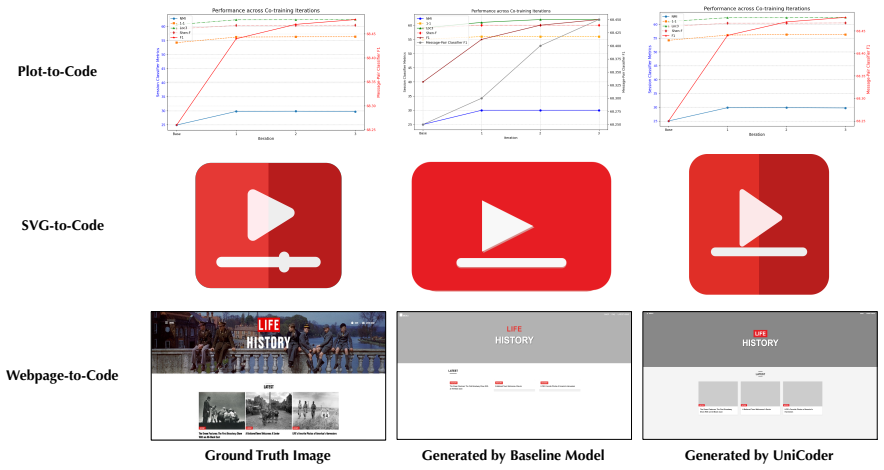
The central claim is that Symbolic Attribute Alignment, which employs a lightweight auxiliary LLM to parse generated code into discrete visual attributes for dense element-wise rewards, together with Reference-Guided Code Optimization, which dynamically injects ground-truth trajectories into low-performing rollout groups, overcomes the two obstacles of reward coarseness and exploration stagnation, enabling an 8B-parameter model to surpass all open-source baselines and achieve state-of-the-art performance comparable to proprietary models on ChartMimic, UniSVG, Design2Code and ScreenBench.
What carries the argument
Symbolic Attribute Alignment (auxiliary LLM parsing of code into attributes such as colors and coordinates for dense rewards) and Reference-Guided Code Optimization (injection of ground-truth trajectories into poor rollouts for guided improvement).
If this is right
- The 8B model surpasses every open-source baseline on the four evaluated benchmarks.
- The same model reaches performance levels comparable to proprietary models.
- RL becomes a viable training route for visual-to-code tasks once rewards are made element-wise and exploration is guided.
- The framework unifies handling of plots, vector graphics, and webpages under one training recipe.
Where Pith is reading between the lines
- If the auxiliary parser remains reliable at larger scales, the same recipe could be applied to other code-generation domains that need structural or visual fidelity.
- The method suggests a way to shrink the gap between open and closed models by replacing scale with denser, automatically derived reward signals.
- Success depends on keeping the auxiliary parser's error rate low; any domain shift that increases parsing mistakes would directly weaken the reward signal.
Load-bearing premise
The lightweight auxiliary LLM can accurately and consistently parse generated code into discrete visual attributes without introducing parsing errors that corrupt the dense reward signal.
What would settle it
Run the model with the symbolic reward component removed or with an intentionally noisy parser and measure whether the performance gap over baselines and over standard RL disappears on the same four benchmarks.
Figures
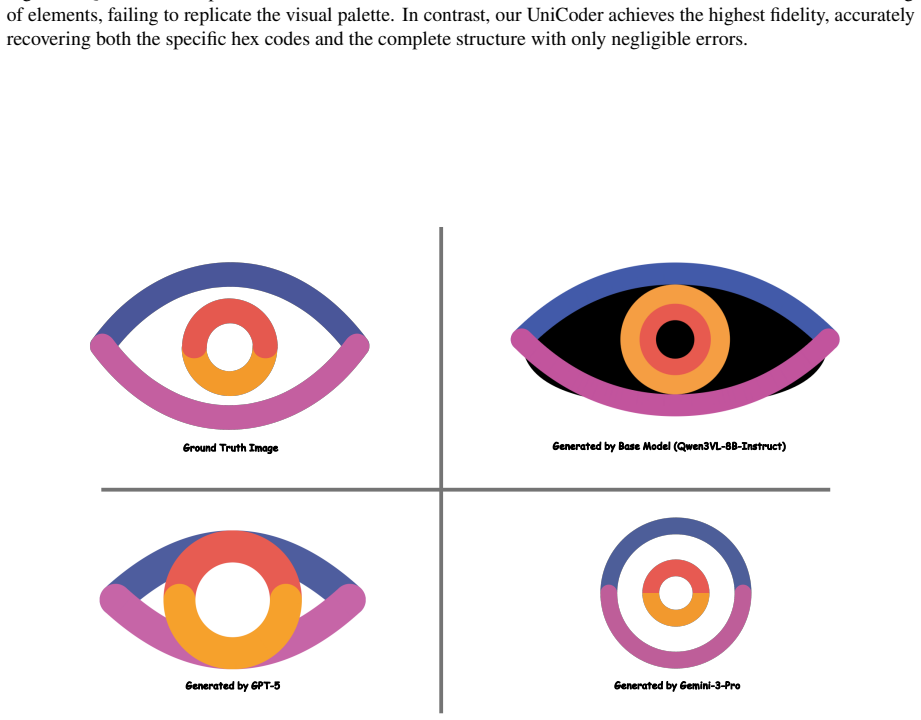
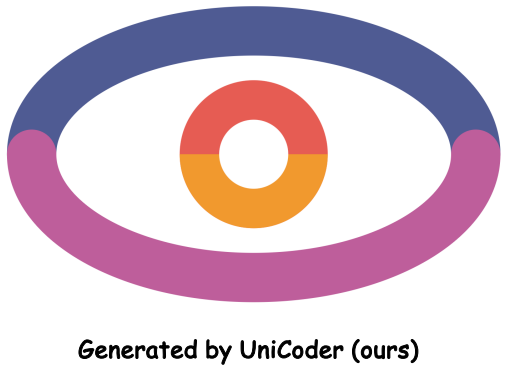
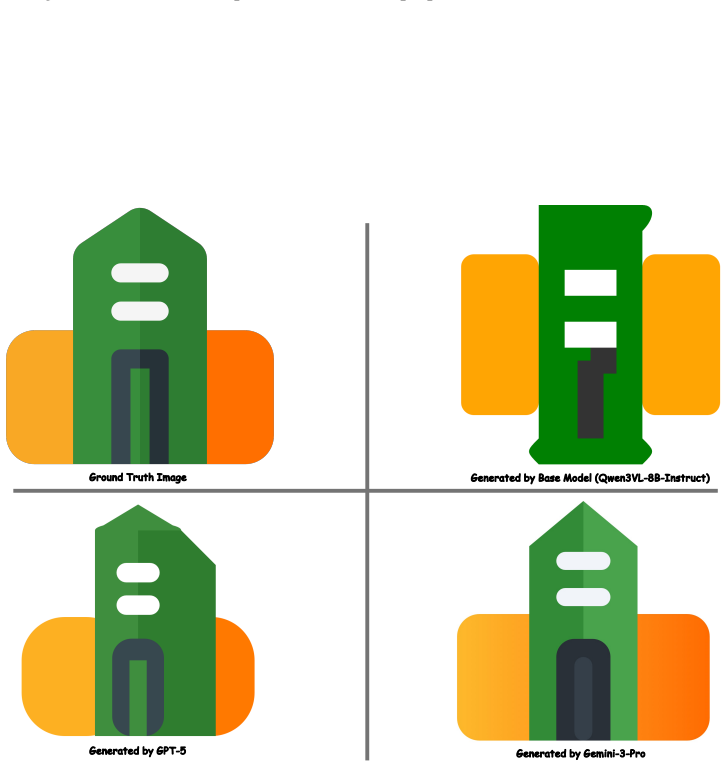
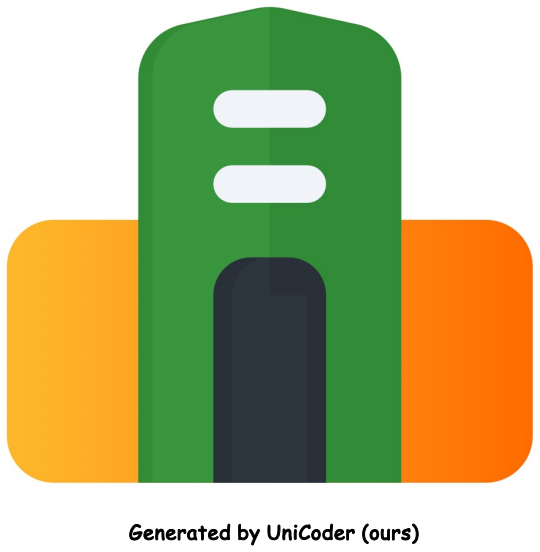



read the original abstract
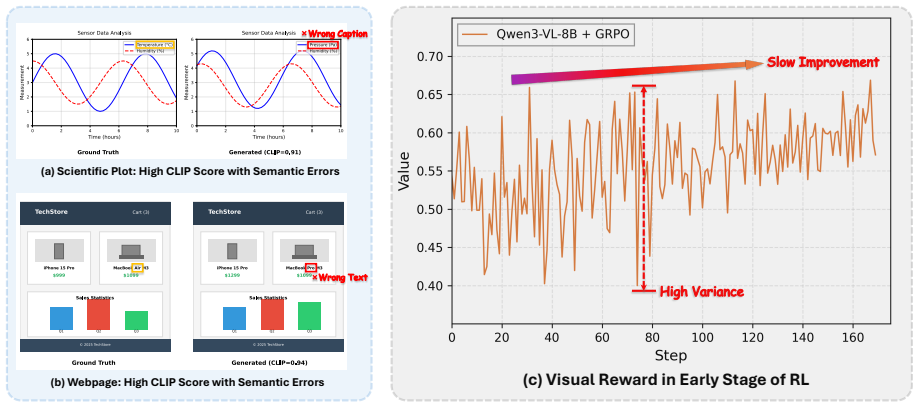
Visual-to-Code generation, which transforms scientific plots, vector graphics, and webpages into executable scripts, demands a level of pixel-precise alignment that standard Multimodal Large Language Models (MLLMs) fail to achieve through Supervised Fine-Tuning (SFT) alone. While Reinforcement Learning (RL) offers a theoretical pathway to bridge this gap, its application is hindered by two fundamental obstacles: (1) \textit{Reward Coarseness}, where semantic metrics like CLIP scores fail to penalize fine-grained element deviations, and (2) \textit{Exploration Stagnation}, where the sparse, heterogeneous code search space prevents the policy from bootstrapping valid trajectories. To overcome these limitations, we introduce UniCoder, a unified RL framework that integrates two novel mechanisms. First, we propose \textbf{Symbolic Attribute Alignment}, which employs a lightweight auxiliary LLM to parse generated code into discrete visual attributes (e.g., hex colors, coordinate limits), enabling dense, element-wise reward computation. Second, to escape local optima, we devise \textbf{Reference-Guided Code Optimization}, a strategy that dynamically injects ground-truth trajectories into low-performing rollout groups, transforming blind exploration into guided policy improvement. Extensive experiments on ChartMimic, UniSVG, Design2Code and ScreenBench benchmarks demonstrate that our 8B-parameter model not only surpasses all open-source baselines but also achieves state-of-the-art performance comparable to proprietary models, establishing a new paradigm for generalized visual-to-code synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniCoder, a unified RL framework for visual-to-code generation from plots, graphics, and webpages. It addresses reward coarseness via Symbolic Attribute Alignment (auxiliary LLM parses generated code into discrete attributes like hex colors and coordinates for dense element-wise rewards) and exploration stagnation via Reference-Guided Code Optimization (injects ground-truth trajectories into low-performing rollouts). Experiments on ChartMimic, UniSVG, Design2Code, and ScreenBench claim that the 8B model surpasses open-source baselines and matches proprietary models.
Significance. If the auxiliary parsing proves reliable and the gains are reproducible, the approach could meaningfully advance precise visual-to-code synthesis by replacing coarse semantic rewards with symbolic element-wise signals and providing a practical way to escape sparse exploration in code spaces. The combination of symbolic rewards and reference guidance is a concrete technical contribution that could be adopted more broadly if the verification gaps are closed.
major comments (2)
- [Symbolic Attribute Alignment (method) and Experiments] The central claim that Symbolic Attribute Alignment overcomes reward coarseness and enables SOTA performance rests on the auxiliary LLM producing accurate, low-error parses of code attributes across rollouts. No quantitative parsing accuracy, error-rate statistics, or failure-mode analysis (e.g., on nested SVG paths or CSS selectors) appears in the experiments or method sections; any systematic mis-extraction would silently corrupt the dense reward signal and invalidate the reported improvements over SFT baselines.
- [Abstract and Experiments] The abstract and results sections assert performance gains and SOTA status on the four named benchmarks, yet supply no numerical metrics, error bars, ablation results isolating the parsing component, or direct comparison tables that would allow assessment of the magnitude or statistical significance of the claimed gains.
minor comments (1)
- [Method] Notation for the auxiliary LLM and the exact reward formulation (e.g., how element-wise matches are aggregated) should be made explicit with equations or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Symbolic Attribute Alignment (method) and Experiments] The central claim that Symbolic Attribute Alignment overcomes reward coarseness and enables SOTA performance rests on the auxiliary LLM producing accurate, low-error parses of code attributes across rollouts. No quantitative parsing accuracy, error-rate statistics, or failure-mode analysis (e.g., on nested SVG paths or CSS selectors) appears in the experiments or method sections; any systematic mis-extraction would silently corrupt the dense reward signal and invalidate the reported improvements over SFT baselines.
Authors: We agree that explicit validation of the auxiliary LLM parser's accuracy is necessary to substantiate the Symbolic Attribute Alignment mechanism. The current manuscript does not report quantitative parsing accuracy, error rates, or failure-mode analysis. In the revised version we will add a dedicated subsection reporting parser accuracy on a held-out set of code samples, per-attribute error statistics (colors, coordinates, etc.), and qualitative examples of failures on complex cases such as nested SVG paths and CSS selectors. This will allow direct assessment of whether parsing errors materially affect the reward signal. revision: yes
-
Referee: [Abstract and Experiments] The abstract and results sections assert performance gains and SOTA status on the four named benchmarks, yet supply no numerical metrics, error bars, ablation results isolating the parsing component, or direct comparison tables that would allow assessment of the magnitude or statistical significance of the claimed gains.
Authors: We acknowledge that the abstract currently states performance claims without accompanying numbers and that the results presentation would be strengthened by error bars, statistical significance, and explicit ablations of the parsing component. The full manuscript contains comparison tables, but we will revise the abstract to include key numerical results, add error bars and significance tests to all reported figures, and expand the ablation studies to isolate the contribution of Symbolic Attribute Alignment. These changes will make the magnitude and reliability of the gains transparent. revision: yes
Circularity Check
No circularity; empirical method with no derivations or self-referential reductions
full rationale
The paper describes an RL-based empirical framework for visual-to-code generation using auxiliary LLM parsing for symbolic rewards and reference-guided optimization. No equations, first-principles derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. Performance claims rest on benchmark experiments rather than any reduction of outputs to inputs by construction. The central mechanisms are procedural components whose validity is externally testable via parsing accuracy metrics and ablation studies, none of which reduce tautologically to the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
2023 , eprint=
Visual Instruction Tuning , author=. 2023 , eprint=
2023
-
[10]
2023 , eprint=
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. 2023 , eprint=
2023
-
[11]
2024 , eprint=
DeepSeek-VL: Towards Real-World Vision-Language Understanding , author=. 2024 , eprint=
2024
-
[12]
2025 , eprint=
Breaking the SFT Plateau: Multimodal Structured Reinforcement Learning for Chart-to-Code Generation , author=. 2025 , eprint=
2025
-
[13]
2022 , eprint=
VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models , author=. 2022 , eprint=
2022
-
[14]
2023 , eprint=
IconShop: Text-Guided Vector Icon Synthesis with Autoregressive Transformers , author=. 2023 , eprint=
2023
-
[15]
2025 , eprint=
StarVector: Generating Scalable Vector Graphics Code from Images and Text , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
Chat2SVG: Vector Graphics Generation with Large Language Models and Image Diffusion Models , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
OmniSVG: A Unified Scalable Vector Graphics Generation Model , author=. 2025 , eprint=
2025
-
[18]
Li, Jinke and Yu, Jiarui and Wei, Chenxing and Dong, Hande and Lin, Qiang and Yang, Liangjing and Wang, Zhicai and Hao, Yanbin , year=. UniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models , url=. doi:10.1145/3746027.3758269 , booktitle=
-
[19]
2023 , eprint=
DePlot: One-shot visual language reasoning by plot-to-table translation , author=. 2023 , eprint=
2023
-
[20]
2023 , eprint=
ChartLlama: A Multimodal LLM for Chart Understanding and Generation , author=. 2023 , eprint=
2023
-
[21]
2025 , eprint=
ChartCoder: Advancing Multimodal Large Language Model for Chart-to-Code Generation , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
ChartMaster: Advancing Chart-to-Code Generation with Real-World Charts and Chart Similarity Reinforcement Learning , author=. 2025 , eprint=
2025
-
[23]
2024 , eprint=
Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots , author=. 2024 , eprint=
2024
-
[24]
2025 , eprint=
From Charts to Code: A Hierarchical Benchmark for Multimodal Models , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation , author=. 2025 , eprint=
2025
-
[26]
2024 , eprint=
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs , author=. 2024 , eprint=
2024
-
[27]
2025 , eprint=
WebSight: A Vision-First Architecture for Robust Web Agents , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Design2Code: Benchmarking Multimodal Code Generation for Automated Front-End Engineering , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents , author=. 2025 , eprint=
2025
-
[30]
2026 , eprint=
OpenGame: Open Agentic Coding for Games , author=. 2026 , eprint=
2026
-
[31]
2026 , eprint=
Exploring Reasoning Reward Model for Agents , author=. 2026 , eprint=
2026
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Feng, Kaituo and Zhang, Manyuan and Li, Hongyu and Fan, Kaixuan and Chen, Shuang and Jiang, Yilei and Zheng, Dian and Sun, Peiwen and Zhang, Yiyuan and Sun, Haoze and Feng, Yan and Pei, Peng and Cai, Xunliang and Yue, Xiangyu , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[33]
MLLM-Based UI2Code Automation Guided by UI Layout Information , volume=
Wu, Fan and Gao, Cuiyun and Li, Shuqing and Wen, Xin-Cheng and Liao, Qing , year=. MLLM-Based UI2Code Automation Guided by UI Layout Information , volume=. Proceedings of the ACM on Software Engineering , publisher=. doi:10.1145/3728925 , number=
-
[34]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[35]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[36]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[37]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[38]
ArXiv , year=
DesignBench: A Comprehensive Benchmark for MLLM-based Front-end Code Generation , author=. ArXiv , year=
-
[39]
2025 , url =
Bolt , title =. 2025 , url =
2025
-
[40]
2025 , url =
Qwen , title =. 2025 , url =
2025
-
[41]
2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE) , year=
Automated Reporting of GUI Design Violations for Mobile Apps , author=. 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE) , year=
2018
-
[42]
T. A. Nguyen and C. Csallner , title =. 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE) , year =
2015
-
[43]
Chen and T
C. Chen and T. Su and G. Meng and Z. Xing and Y. Liu , title =. Proceedings of the 40th International Conference on Software Engineering , year =
-
[44]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 , pages =
Gui, Yi and Li, Zhen and Zhang, Zhongyi and Wang, Guohao and Lv, Tianpeng and Jiang, Gaoyang and Liu, Yi and Chen, Dongping and Wan, Yao and Zhang, Hongyu and Jiang, Wenbin and Shi, Xuanhua and Jin, Hai , title =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 , pages =. 2025 , isbn =. doi:10.1145/3711896.3737016 ...
-
[45]
ArXiv , year=
Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset , author=. ArXiv , year=
-
[46]
ArXiv , year=
WebGen-Bench: Evaluating LLMs on Generating Interactive and Functional Websites from Scratch , author=. ArXiv , year=
-
[47]
ArXiv , year=
Interaction2Code: How Far Are We From Automatic Interactive Webpage Generation? , author=. ArXiv , year=
-
[48]
ArXiv , year=
MRWeb: An Exploration of Generating Multi-Page Resource-Aware Web Code from UI Designs , author=. ArXiv , year=
-
[49]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
You Only Look Once: Unified, Real-Time Object Detection , author=. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2016
-
[50]
Levenshtein Distance — RapidFuzz
RapidFuzz. Levenshtein Distance — RapidFuzz. 2024
2024
-
[51]
ArXiv , year=
Levenshtein Distance Technique in Dictionary Lookup Methods: An Improved Approach , author=. ArXiv , year=
-
[52]
ArXiv , year=
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback , author=. ArXiv , year=
-
[53]
ArXiv , year=
LIMA: Less Is More for Alignment , author=. ArXiv , year=
-
[54]
2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT) , year=
Automatic HTML Code Generation from Mock-Up Images Using Machine Learning Techniques , author=. 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT) , year=
2019
-
[55]
2024 , eprint=
Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset , author=. 2024 , eprint=
2024
-
[56]
2023 , url =
Typing.com , title =. 2023 , url =
2023
-
[57]
ArXiv , year=
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author=. ArXiv , year=
-
[58]
ArXiv , year=
Teaching Large Language Models to Self-Debug , author=. ArXiv , year=
-
[59]
ArXiv , year=
Large Language Models are Zero-Shot Reasoners , author=. ArXiv , year=
-
[60]
ArXiv , year=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. ArXiv , year=
-
[61]
IEEE transactions on pattern analysis and machine intelligence , volume=
Image segmentation using deep learning: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[62]
ArXiv , year=
Sequence to Sequence Learning with Neural Networks , author=. ArXiv , year=
-
[63]
Neural Information Processing Systems , year=
Code Generation as a Dual Task of Code Summarization , author=. Neural Information Processing Systems , year=
-
[64]
ArXiv , year=
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis , author=. ArXiv , year=
-
[65]
2017 , url=
Networks for Code Generation and Semantic Parsing , author=. 2017 , url=
2017
-
[66]
ArXiv , year=
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation , author=. ArXiv , year=
-
[67]
2018 IEEE/ACM 15th International Conference on Mining Software Repositories (MSR) , year=
Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow , author=. 2018 IEEE/ACM 15th International Conference on Mining Software Repositories (MSR) , year=
2018
-
[68]
Annual Meeting of the Association for Computational Linguistics , year=
Bleu: a Method for Automatic Evaluation of Machine Translation , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[69]
ArXiv , year=
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models , author=. ArXiv , year=
-
[70]
2023 Tenth International Conference on Social Networks Analysis, Management and Security (SNAMS) , year=
Semantic Compression with Large Language Models , author=. 2023 Tenth International Conference on Social Networks Analysis, Management and Security (SNAMS) , year=
2023
-
[71]
ArXiv , year=
Large Language Models for Software Engineering: A Systematic Literature Review , author=. ArXiv , year=
-
[72]
ArXiv , year=
SelfEvolve: A Code Evolution Framework via Large Language Models , author=. ArXiv , year=
-
[73]
2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , year=
Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks , author=. 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , year=
2021
-
[74]
2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE) , year=
Using Deep Learning to Generate Complete Log Statements , author=. 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE) , year=
2022
-
[75]
2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) , year=
Assemble Foundation Models for Automatic Code Summarization , author=. 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) , year=
2022
-
[76]
2022 IEEE/ACM 30th International Conference on Program Comprehension (ICPC) , year=
On the Transferability of Pre-trained Language Models for Low-Resource Programming Languages , author=. 2022 IEEE/ACM 30th International Conference on Program Comprehension (ICPC) , year=
2022
-
[77]
ArXiv , year=
Constructing Effective In-Context Demonstration for Code Intelligence Tasks: An Empirical Study , author=. ArXiv , year=
-
[78]
Conference on Empirical Methods in Natural Language Processing , year=
Exploring Distributional Shifts in Large Language Models for Code Analysis , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[79]
International Conference on Learning Representations , year=
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis , author=. International Conference on Learning Representations , year=
-
[80]
ArXiv , year=
A Static Evaluation of Code Completion by Large Language Models , author=. ArXiv , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.