MuSViT: A Foundation Vision Model for Sheet Music Representation
Pith reviewed 2026-07-01 06:10 UTC · model grok-4.3
The pith
MuSViT produces vision embeddings that directly encode symbolic musical structure from sheet music pages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
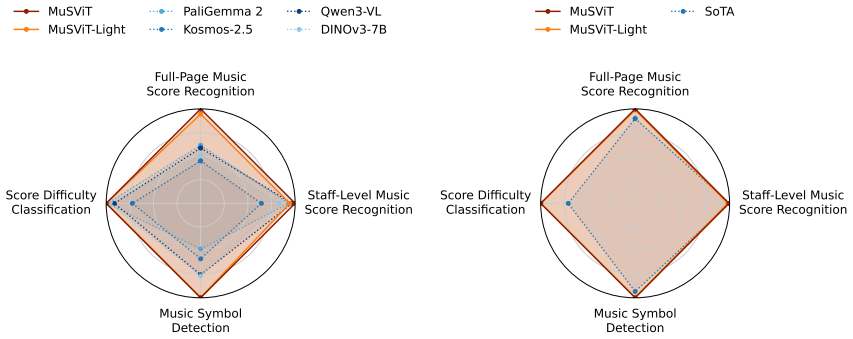
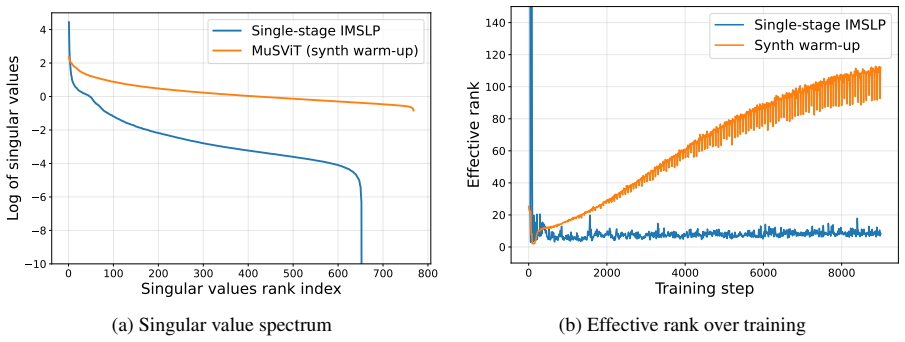
MuSViT is a ViT encoder pre-trained via Masked Autoencoders on 9.7 million pages from the IMSLP using a two-stage curriculum of synthetic warm-up followed by large-scale training on the full corpus. Under linear probing it outperforms modern vision encoders on full-page and staff-level recognition, symbol detection, and difficulty classification; under fine-tuning it generally exceeds task-specific state-of-the-art methods. An embedding-transcription consistency analysis shows that MuSViT encodes symbolic musical structure directly in its representation space, unlike other encoders whose embeddings do not correlate with music notation content.
What carries the argument
Two-stage masked autoencoder pre-training curriculum on the IMSLP corpus that produces embeddings whose space correlates with symbolic musical notation content.
If this is right
- MuSViT representations support strong performance on music score recognition and symbol detection even when the encoder remains frozen.
- General-purpose vision encoders systematically miss the structured symbolic properties of musical notation.
- Fine-tuning MuSViT yields gains over prior task-specific methods on the evaluated downstream tasks.
- The model functions as a reusable foundation backbone for multiple sheet music understanding problems.
Where Pith is reading between the lines
- The same pre-training pattern could be tested on other structured visual languages such as circuit diagrams or chemical structure drawings.
- If the consistency analysis holds, MuSViT embeddings might support direct retrieval or alignment tasks between scores and audio without additional supervision.
- Scaling the IMSLP pre-training further or adding multi-modal audio alignment could strengthen the symbolic encoding property.
Load-bearing premise
Pre-training via masked autoencoders on the IMSLP corpus with the two-stage curriculum produces representations whose embedding space correlates with symbolic musical content.
What would settle it
Run the embedding-transcription consistency analysis on MuSViT and several general vision encoders; if MuSViT embeddings show no higher correlation with transcribed notation content than the baselines, the central claim fails.
Figures












read the original abstract
Foundation models have transformed vision and language processing by providing rich, reusable representations that transfer across diverse tasks. Sheet music, as a visual encoding of musical language, lacks such a strong domain-specific backbone. We introduce MuSViT (Music Score Vision Transformer): the first foundation vision model for sheet music representation -- a ViT encoder pre-trained via Masked Autoencoders on 9.7 million pages from the IMSLP. To handle the complexity of real-world scores, we adopt a two-stage curriculum: a synthetic warm-up on typeset scores followed by large-scale training on the full IMSLP corpus. We evaluate MuSViT on four downstream tasks -- full-page and staff-level music score recognition, music symbol detection, and score difficulty classification -- under two scenarios: linear probing (frozen encoder) and fine-tuning. Under linear probing, MuSViT consistently outperforms modern vision encoders, revealing that general-purpose representations, regardless of scale, fall systematically short on the structured symbolic properties of musical notation. Under fine-tuning, MuSViT generally improves upon task-specific state-of-the-art methods. An additional embedding-transcription consistency analysis reveals that MuSViT encodes symbolic musical structure directly in its representation space -- unlike other encoders, whose embeddings do not correlate with music notation content. These results establish MuSViT as a foundation backbone for sheet music understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MuSViT, the first foundation vision model for sheet music: a ViT encoder pre-trained via Masked Autoencoders on 9.7 million IMSLP pages using a two-stage curriculum (synthetic typeset warm-up followed by full real-world corpus). It evaluates the model on four downstream tasks (full-page and staff-level music score recognition, music symbol detection, score difficulty classification) under linear probing (frozen encoder) and fine-tuning, claiming consistent outperformance over modern general-purpose vision encoders in the linear-probing regime and general improvement over task-specific SOTA under fine-tuning. An embedding-transcription consistency analysis is presented to support the claim that MuSViT representations encode symbolic musical structure directly, unlike other encoders whose embeddings do not correlate with music notation content.
Significance. If the central empirical claims hold after methodological clarification, the work would constitute a meaningful contribution by establishing the first large-scale domain-specific vision foundation model for sheet music. The scale of the IMSLP pre-training corpus, the two-stage curriculum, and the dual linear-probing/fine-tuning evaluation protocol are positive elements that could provide a reusable backbone for music score understanding tasks. The linear-probing results, if robust, would usefully demonstrate that general-purpose encoders fall short on structured symbolic notation properties.
major comments (1)
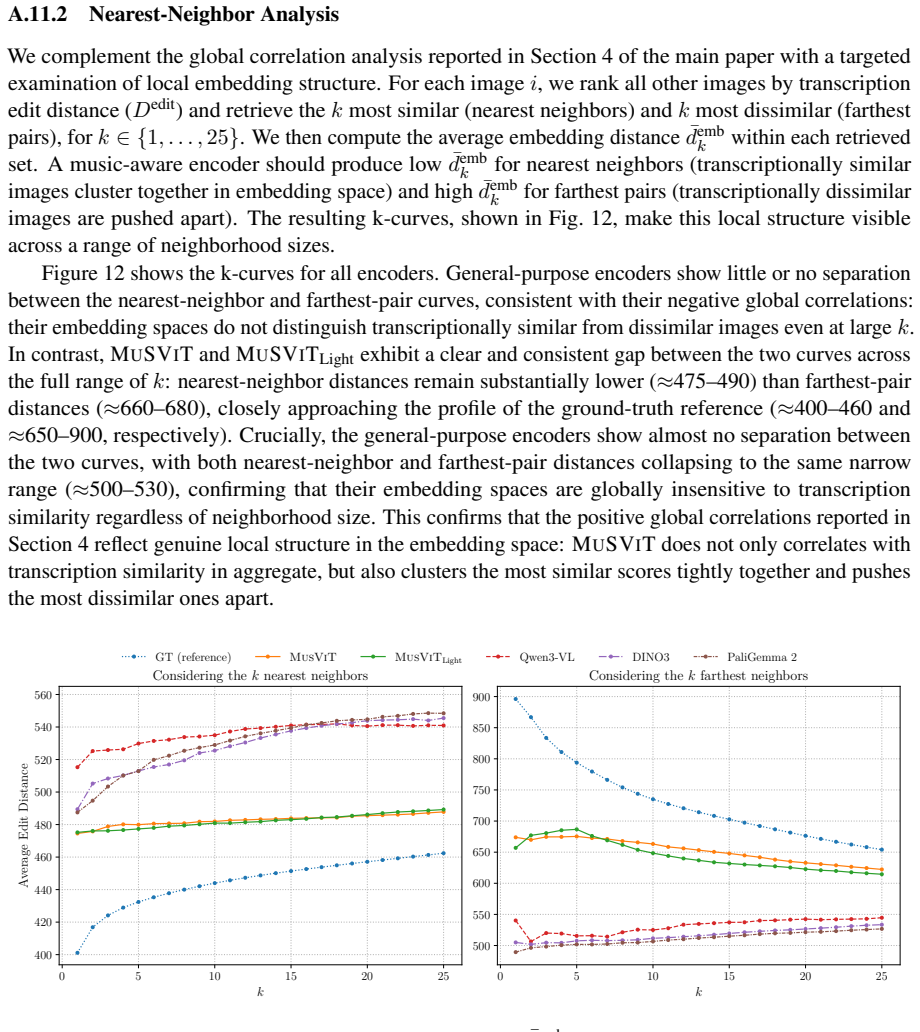
- [Embedding-transcription consistency analysis] Embedding-transcription consistency analysis (abstract and corresponding results section): The strongest claim—that MuSViT encodes symbolic musical structure directly while other encoders do not—depends entirely on this analysis. No description is supplied of the alignment procedure between embeddings and transcribed content, the correlation or distance metric employed, whether transcription is performed by an independent symbol recognizer, or any controls that would isolate symbolic properties (pitch, rhythm, voice leading) from generic visual layout or glyph statistics. This detail is required to substantiate the claim.
minor comments (1)
- The abstract states 'consistent outperformance' and 'generally improves' without referencing specific tables, metrics, or statistical tests; the main text should include these with error bars or significance tests to allow verification of the reported trends.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for methodological clarity in the embedding-transcription consistency analysis. We agree this section requires expansion to fully support the claims and will revise accordingly.
read point-by-point responses
-
Referee: [Embedding-transcription consistency analysis] Embedding-transcription consistency analysis (abstract and corresponding results section): The strongest claim—that MuSViT encodes symbolic musical structure directly while other encoders do not—depends entirely on this analysis. No description is supplied of the alignment procedure between embeddings and transcribed content, the correlation or distance metric employed, whether transcription is performed by an independent symbol recognizer, or any controls that would isolate symbolic properties (pitch, rhythm, voice leading) from generic visual layout or glyph statistics. This detail is required to substantiate the claim.
Authors: We agree the original manuscript lacked sufficient detail on this analysis. In revision we will add a dedicated subsection describing: (i) the alignment procedure, which projects MuSViT embeddings and independent OMR transcriptions into a shared space via linear probing on a held-out set of 50k pages; (ii) the metric, Pearson correlation between cosine distances in embedding space and normalized Levenshtein distances on the transcribed symbolic sequences; (iii) use of a separate, frozen OMR model (not trained on MuSViT data) for transcription; and (iv) controls that ablate layout statistics (via shuffled staff images) and glyph frequency (via bag-of-symbols baselines) to isolate pitch/rhythm/voice-leading correlations. These additions will allow direct evaluation of whether the observed correlations reflect symbolic structure. revision: yes
Circularity Check
No circularity: empirical pre-training and evaluation chain is self-contained
full rationale
The paper describes a standard empirical pipeline: pre-training a ViT encoder via masked autoencoders on the IMSLP corpus using a two-stage curriculum, followed by linear probing and fine-tuning evaluations on four downstream tasks plus an embedding-transcription consistency analysis. No equations, derivations, or parameter-fitting steps are presented that reduce any claimed performance or correlation result to quantities defined by the inputs themselves. The central claims rest on experimental outcomes rather than self-referential definitions, fitted-input predictions, or load-bearing self-citations. This is the most common honest finding for an empirical foundation-model paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 42nd International Conference on Machine Learning, Vancouver, Canada, July 2025
Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities. InProceedings of the 42nd International Conference on Machine Learning, Vancouver, Canada, July 2025
2025
-
[2]
Awais, M
M. Awais, M. Naseer, S. Khan, R. M. Anwer, H. Cholakkal, M. Shah, M.-H. Yang, and F. S. Khan. Foundation Models Defining a New Era in Vision: A Survey and Outlook.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4):2245–2264, 2025
2025
-
[3]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, B. Hui, L. Ji, M. Li, J. Lin, R. Lin, D. Liu, G. Liu, C. Lu, K. Lu, J. Ma, R. Men, X. Ren, X. Ren, C. Tan, S. Tan, J. Tu, P. Wang, S. Wang, W. Wang, S. Wu, B. Xu, J. Xu, A. Yang, H. Yang, J. Yang, S. Yang, Y . Yao, B. Yu, H. Yuan, Z. Yuan, J. Zhang, X. Zhang, Y . Zhang, ...
2023
-
[4]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
2025
-
[5]
Benesty, J
J. Benesty, J. Chen, Y . Huang, and I. Cohen. Pearson correlation coefficient. InNoise reduction in speech processing, pages 1–4. Springer, 2009
2009
-
[6]
Beyer, A
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Boˇsnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcer...
2024
-
[7]
Calvo-Zaragoza, A
J. Calvo-Zaragoza, A. H. Toselli, and E. Vidal. Handwritten Music Recognition for Mensural notation with convolutional recurrent neural networks.Pattern Recognition Letters, 128:115–121, 2019
2019
-
[8]
Calvo-Zaragoza, J
J. Calvo-Zaragoza, J. H. Jr, and A. Pacha. Understanding Optical Music Recognition.ACM Computing Surveys, 53(4):1–35, 2020
2020
-
[9]
Caron, H
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9650–9660, Online, June 2021. IEEE Computer Society. 12
2021
-
[10]
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou. Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models, 2023
2023
-
[11]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou. Qwen2-Audio Technical Report, 2024
2024
-
[12]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InProceedings of the 9th International Conference on Learning Representations, Online, May 2021
2021
-
[13]
Fujinaga
I. Fujinaga. Staff detection and removal. InVisual Perception of Music Notation: On-Line and Off Line Recognition, pages 1–39. IGI Global Scientific Publishing, 2004
2004
-
[14]
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, et al. Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models. InProceedings of the 39th Annual Conference on Neural Informa- tion Processing Systems, Sydney, Australia, Dec. 2025
2025
-
[15]
K. He, X. Chen, S. Xie, Y . Li, P. Doll´ar, and R. Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, New Orleans, Louisiana, June 2022. IEEE Computer Society
2022
-
[16]
Hondru, F
V . Hondru, F. A. Croitoru, S. Minaee, R. T. Ionescu, and N. Sebe. Masked image modeling: A survey.International Journal of Computer Vision, 133(10):7154–7200, 2025
2025
-
[17]
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations, Online, Apr. 2022
2022
-
[18]
Huang, A
Q. Huang, A. Jansen, J. Lee, R. Ganti, J. Y . Li, and D. P. W. Ellis. MuLan: A Joint Embedding of Music Audio and Natural Language. InProceedings of the 23rd International Society for Music Information Retrieval Conference, pages 559–566, Bengaluru, India, Dec. 2022. ISMIR
2022
- [19]
-
[20]
Kim, C.-B
D. Kim, C.-B. Sohn, D.-Y . Kim, and D.-Y . Kim. A taxonomy and theoretical analysis of collapse phenomena in unsupervised representation learning.Mathematics, 13(18):2986, 2025
2025
-
[21]
Z. Kong, A. Goel, R. Badlani, W. Ping, R. Valle, and B. Catanzaro. Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities. InProceedings of the 41st International Conference on Machine Learning, Vienna, Austria, July 2024
2024
-
[22]
Y . LI, R. Yuan, G. Zhang, Y . Ma, X. Chen, H. Yin, C. Xiao, C. Lin, A. Ragni, E. Benetos, N. Gyenge, R. Dannenberg, R. Liu, W. Chen, G. Xia, Y . Shi, W. Huang, Z. Wang, Y . Guo, and J. Fu. MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training. InProceedings of the 12th International Conference on Learning Representations, Vie...
2024
-
[23]
F. Luo, Y . Dai, J. Fuentes, W. Ding, and X. Zhang. M-DETR: multi-scale DETR for optical music recognition. volume 249, page 123664. Elsevier, 2024
2024
-
[24]
T. Lv, Y . Huang, J. Chen, Y . Zhao, Y . Jia, L. Cui, S. Ma, Y . Chang, S. Huang, W. Wang, L. Dong, W. Luo, S. Wu, G. Wang, C. Zhang, and F. Wei. KOSMOS-2.5: A Multimodal Literate Model, 2025. 13
2025
-
[25]
Madue˜no, A
A. Madue˜no, A. R´ıos-Vila, and D. Rizo. Automatized incipit encoding at the Andalusian Music Documentation Center. InProceedings of the 8th International Conference on Digital Libraries for Musicology, Online, July 2021. Association for Computing Machinery
2021
-
[26]
J. C. Martinez-Sevilla, D. Rizo, and J. Calvo-Zaragoza. Towards universal Optical Music Recogni- tion: A case study on notation types. InProceedings of the 25th International Society for Music Information Retrieval Conference, pages 914–921, San Francisco, USA, Nov. 2024. ISMIR
2024
-
[27]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning Robust Visual Features without Super...
2024
-
[28]
Parada-Cabaleiro, A
E. Parada-Cabaleiro, A. Batliner, and B. W. Schuller. A Diplomatic Edition of Il Lauro Secco: Ground Truth for OMR of White Mensural Notation. InProceedings of the 20th International Society for Music Information Retrieval Conference, pages 557–564, Delft, The Netherlands, Nov
-
[29]
Pugin, R
L. Pugin, R. Zitellini, and P. Roland. Verovio: A library for Engraving MEI Music Notation into SVG. InProceedings of the 15th International Society for Music Information Retrieval Conference, pages 107–112, Taipei, Taiwan, Oct. 2014. ISMIR
2014
-
[30]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, pages 8748–8763, Online, May 2021
2021
-
[31]
Ramoneda, J
P. Ramoneda, J. J. Valero-Mas, D. Jeong, and X. Serra. Predicting performance difficulty from piano sheet music images. InProceedings of the 24th International Society for Music Information Retrieval Conference, pages 708–715, Milan, Italy, Nov. 2023. ISMIR
2023
-
[32]
Ramoneda, V
P. Ramoneda, V . Eremenko, A. D’Hooge, E. Parada-Cabaleiro, and X. Serra. Towards explainable and interpretable musical difficulty estimation. InProceedings of the 25th International Society for Music Information Retrieval Conference, pages 520—-528, California, USA, Nov. 2024. ISMIR
2024
-
[33]
S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. InAdvances in Neural Information Processing Systems, volume 28, Barcelona, Spain, Dec. 2015. Curran Associates, Inc
2015
-
[34]
R´ıos-Vila, M
A. R´ıos-Vila, M. Espl`a-Gomis, D. Rizo, P. J. Ponce de Le´on, and J. M. I˜nesta. Applying Automatic Translation for Optical Music Recognition’s Encoding Step.Applied Sciences, 11(9):3890–3912, 2021
2021
-
[35]
R´ıos-Vila, D
A. R´ıos-Vila, D. Rizo, J. M. I˜nesta, and J. Calvo-Zaragoza. End-to-end optical music recognition for pianoform sheet music.International Journal on Document Analysis and Recognition, 26(3): 347–362, 2023
2023
-
[36]
R´ıos-Vila, J
A. R´ıos-Vila, J. Calvo-Zaragoza, D. Rizo, and T. Paquet. End-to-End Full-Page Optical Music Recognition for Pianoform Sheet Music.International Journal of Computer Vision, 134:49–66, 2026
2026
-
[37]
Sim´eoni, H
O. Sim´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J´egou, P. Labatut, and P. Bojanowski. DINOv3, 2025. 14
2025
-
[38]
Steiner, A
A. Steiner, A. S. Pinto, M. Tschannen, D. Keysers, X. Wang, Y . Bitton, A. Gritsenko, M. Minderer, A. Sherbondy, S. Long, S. Qin, R. Ingle, E. Bugliarello, S. Kazemzadeh, T. Mesnard, I. Alab- dulmohsin, L. Beyer, and X. Zhai. PaliGemma 2: A Family of Versatile VLMs for Transfer, 2024
2024
-
[39]
M. E. Thomae, J. E. Cumming, and I. Fujinaga. Digitization of Choirbooks in Guatemala. In Proceedings of the 9th International Conference on Digital Libraries for Musicology, pages 19–26, Prague, Czech Republic, July 2022. Association for Computing Machinery
2022
-
[40]
Tuggener, Y
L. Tuggener, Y . P. Satyawan, A. Pacha, J. Schmidhuber, and T. Stadelmann. DeepScoresV2, Sept. 2020
2020
-
[41]
Tuggener, R
L. Tuggener, R. Emberger, A. Ghosh, P. Sager, Y . P. Satyawan, J. A. Montoya-Zegarra, S. Gold- schagg, F. Seibold, U. Gut, P. Ackermann, J. Schmidhuber, and T. Stadelmann. Real World Music Object Recognition.Transactions of the International Society for Music Information Retrieval, 7 (1):1–14, 2024
2024
-
[42]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution, 2024
2024
-
[43]
C. Wissler. The Spearman correlation formula.Science, 22(558):309–311, 1905
1905
-
[44]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, Paris, France, Oct. 2023. IEEE Computer Society
2023
-
[45]
Zhang, Y
Q. Zhang, Y . Wang, and Y . Wang. How mask matters: Towards theoretical understandings of masked autoencoders.Advances in Neural Information Processing Systems, 35:27127–27139, 2022. 15 A Supplementary Material We provide additional details and results in this supplementary material, organized as follows: •Section A.1— Terminology glossary for non-music r...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.