Z-1: Efficient Reinforcement Learning for Vision-Language-Action Models
Pith reviewed 2026-07-01 05:02 UTC · model grok-4.3
The pith
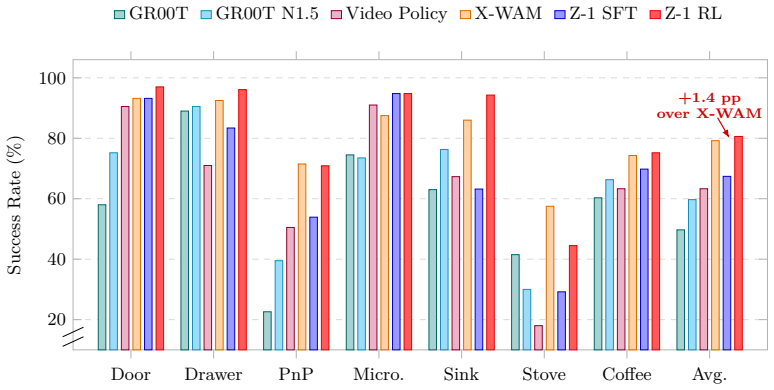
Z-1 applies group relative policy optimization after supervised fine-tuning to raise vision-language-action model success from 67.4 to 80.6 percent on 24 RoboCasa tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
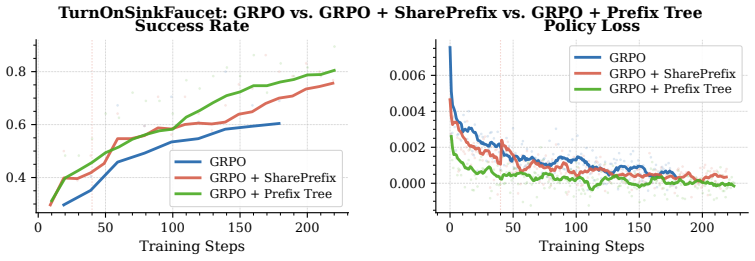
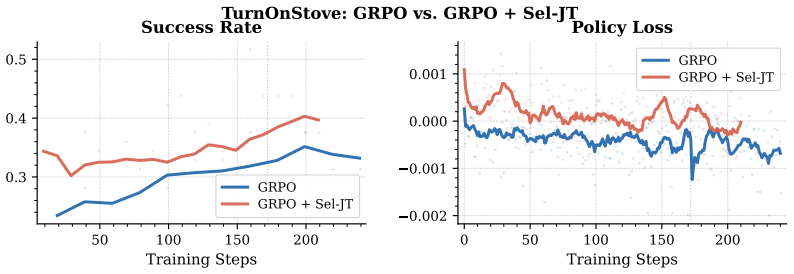
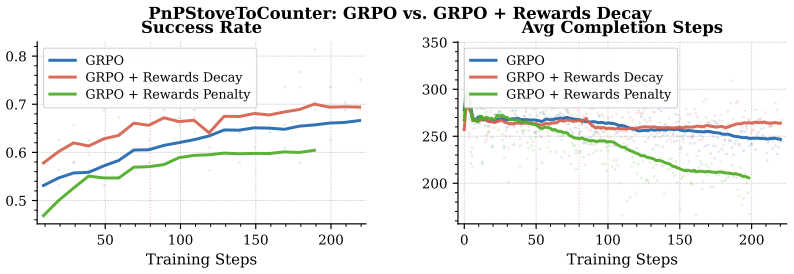
Z-1 is a reinforcement learning post-training framework for flow-based vision-language-action models. Built on top of π0.5, it applies task-wise Group Relative Policy Optimization across 24 RoboCasa tasks using only public demonstrations. With shared-prefix rollout construction, tree-structured trajectory branching, completion-aware reward calibration, and selective joint training of VLM and Action Expert, Z-1 reaches an average success rate of 80.6 percent, a 13.2 point gain over its supervised fine-tuning baseline and better than published state-of-the-art models.
What carries the argument
Group Relative Policy Optimization (GRPO) applied task-wise together with shared-prefix rollout construction, tree-structured trajectory branching, completion-aware reward calibration, and selective joint training of the vision-language model and action expert.
If this is right
- Flow-based vision-language-action policies can be improved substantially through online reinforcement learning without additional private demonstrations.
- Systematic group relative policy optimization with the listed efficiency techniques enables stable training on continuous robot control tasks.
- Selective joint training of the vision-language and action components preserves gains while reducing optimization cost.
- Public demonstration sets become sufficient for high performance when paired with this post-training recipe.
Where Pith is reading between the lines
- The same post-training structure could be tested on other vision-language-action architectures beyond the flow-based family used here.
- If the rollout and reward techniques transfer, they may lower the compute barrier for applying reinforcement learning to new robot benchmarks.
- Results point to the possibility that reinforcement learning post-training can serve as a general next step after supervised fine-tuning for many continuous control policies.
Load-bearing premise
The measured performance gains are produced by the GRPO strategy and the listed rollout, branching, reward, and training techniques rather than by differences in evaluation protocol, random seeds, or unstated implementation choices.
What would settle it
Re-running the exact same evaluation protocol on the supervised fine-tuning baseline and the Z-1 model with identical random seeds and seeing whether the 13.2 percentage point gap persists would confirm or refute the contribution of the reinforcement learning post-training.
Figures
read the original abstract
Vision-Language-Action (VLA) models offer a promising framework for robotic manipulation by connecting language instructions, visual observations, and continuous control. However, most existing policies remain limited by behavior cloning or supervised fine-tuning (SFT) from fixed demonstrations, which provides limited opportunity to improve from the policy's own failures. In this paper, we present Z-1, a reinforcement learning (RL) post-training framework for flow-based VLA models. Built on top of $\pi_{0.5}$, Z-1 uses only publicly released RoboCasa demonstrations for SFT and then applies a task-wise Group Relative Policy Optimization (GRPO) strategy across $24$ standard RoboCasa tasks. To improve the efficiency and stability of online optimization, Z-1 combines shared-prefix rollout construction, tree-structured trajectory branching, completion-aware reward calibration, and selective joint training of VLM and Action Expert. Across all $24$ RoboCasa tasks, Z-1 achieves an average success rate of $80.6\%$, improving over its SFT initialization by $13.2\%$ points and outperforms the published sota models. These results show that systematic GRPO post-training can substantially improve flow-based VLA policies without additional private demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Z-1, an RL post-training framework for flow-based VLA models. Built on the π_{0.5} model after SFT using only public RoboCasa demonstrations, it applies a task-wise Group Relative Policy Optimization (GRPO) strategy across 24 RoboCasa tasks. The framework incorporates shared-prefix rollout construction, tree-structured trajectory branching, completion-aware reward calibration, and selective joint training of the VLM and Action Expert. The central empirical claim is an average success rate of 80.6%, representing a 13.2 percentage point improvement over the SFT initialization and outperforming published SOTA models.
Significance. If the performance gains hold under controlled and reproducible conditions, the work would demonstrate that targeted online RL post-training can substantially advance flow-based VLA policies without additional private data. The efficiency-focused GRPO techniques could provide a practical path for improving robotic manipulation policies beyond standard supervised fine-tuning.
major comments (3)
- [Experimental Setup (Section 4)] Experimental Setup (Section 4): The manuscript reports headline success rates (80.6% average, +13.2 pp over SFT) but supplies no error bars, standard deviations across random seeds, or statistical significance tests. This prevents verification of whether the reported lift is reliable or reproducible.
- [Experimental Setup (Section 4)] Experimental Setup (Section 4): No description is given of the precise evaluation protocol for the 24 RoboCasa tasks (success criteria, episode length limits, camera views) or whether the published SOTA numbers were re-evaluated under identical conditions versus taken from original papers. This directly affects attribution of gains to the GRPO components.
- [Section 4] Section 4: The paper describes the GRPO components (shared-prefix rollouts, tree branching, completion-aware reward calibration, selective joint training) but presents no ablation studies isolating their individual contributions. Without these, the central claim that these techniques produce the observed improvements cannot be substantiated.
minor comments (1)
- [Abstract] Abstract: The base model is denoted π_{0.5}; a short clarification of its architecture and training in the main text would improve accessibility.
Simulated Author's Rebuttal
We appreciate the referee's comments on the experimental setup and the need for greater rigor in reporting. We address each major comment below and outline the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: The manuscript reports headline success rates (80.6% average, +13.2 pp over SFT) but supplies no error bars, standard deviations across random seeds, or statistical significance tests. This prevents verification of whether the reported lift is reliable or reproducible.
Authors: We agree that the absence of error bars and statistical analysis limits the ability to assess reproducibility. The experiments were performed with a single random seed due to the substantial computational resources required for GRPO post-training of the VLA model (approximately 128 GPU-hours per task). In the revised manuscript, we will explicitly note the single-seed nature of the results and provide a discussion of potential sources of variance. We will also explore running a small number of additional seeds for a subset of tasks if resources permit. revision: partial
-
Referee: No description is given of the precise evaluation protocol for the 24 RoboCasa tasks (success criteria, episode length limits, camera views) or whether the published SOTA numbers were re-evaluated under identical conditions versus taken from original papers. This directly affects attribution of gains to the GRPO components.
Authors: We thank the referee for pointing out this omission. The evaluation protocol follows the standard RoboCasa benchmark settings: success is determined by task-specific criteria (e.g., object placement within tolerance), maximum episode length of 500 steps, and using the default camera views as in the original RoboCasa paper. The SOTA numbers are taken directly from the respective original publications, as re-implementing and re-evaluating all baselines under identical conditions was not feasible without their training code and models. We will add a dedicated paragraph in Section 4 detailing the evaluation protocol and clarifying the source of the SOTA comparisons. revision: yes
-
Referee: The paper describes the GRPO components (shared-prefix rollouts, tree branching, completion-aware reward calibration, selective joint training) but presents no ablation studies isolating their individual contributions. Without these, the central claim that these techniques produce the observed improvements cannot be substantiated.
Authors: We acknowledge that ablation studies would strengthen the attribution of gains to specific GRPO components. The current manuscript emphasizes the integrated framework and its overall performance. In the revised version, we will include ablations for the primary efficiency techniques, such as shared-prefix rollouts and tree-structured branching, on a representative subset of tasks. However, conducting exhaustive ablations across all 24 tasks and all components would require prohibitive additional compute; we will discuss this limitation and focus on the most impactful components. revision: partial
Circularity Check
No circularity: purely empirical results on fixed public benchmarks
full rationale
The paper reports measured success rates (80.6% average) from GRPO post-training on the 24 RoboCasa tasks using only publicly released demonstrations. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methods. All claims reduce to direct experimental outcomes on external fixed tasks rather than any self-referential reduction. This is the standard non-circular case for an applied RL paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task success rate constitutes a usable scalar reward for policy optimization in robotic manipulation.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2023 , eprint=
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author=. 2023 , eprint=
2023
-
[9]
2024 , eprint=
OpenVLA: An Open-Source Vision-Language-Action Model , author=. 2024 , eprint=
2024
-
[10]
2026 , eprint=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. 2026 , eprint=
2026
-
[11]
Physical Intelligence and Kevin Black and Noah Brown and James Darpinian and Karan Dhabalia and Danny Driess and Adnan Esmail and Michael Equi and Chelsea Finn and Niccolo Fusai and Manuel Y. Galliker and Dibya Ghosh and Lachy Groom and Karol Hausman and Brian Ichter and Szymon Jakubczak and Tim Jones and Liyiming Ke and Devin LeBlanc and Sergey Levine an...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
2026 , eprint=
A Survey of Large Language Models , author=. 2026 , eprint=
2026
-
[13]
2018 , eprint=
Behavioral Cloning from Observation , author=. 2018 , eprint=
2018
-
[14]
2023 , eprint=
Flow Matching for Generative Modeling , author=. 2023 , eprint=
2023
-
[15]
2023 , eprint=
StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models , author=. 2023 , eprint=
2023
-
[16]
2026 , eprint=
Vision-Language-Action (VLA) Models: Concepts, Progress, Applications and Challenges , author=. 2026 , eprint=
2026
- [17]
-
[18]
2026 , eprint=
ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning , author=. 2026 , eprint=
2026
-
[19]
2025 , eprint=
VLA-R1: Enhancing Reasoning in Vision-Language-Action Models , author=. 2025 , eprint=
2025
-
[20]
Physical Intelligence and Ali Amin and Raichelle Aniceto and Ashwin Balakrishna and Kevin Black and Ken Conley and Grace Connors and James Darpinian and Karan Dhabalia and Jared DiCarlo and Danny Driess and Michael Equi and Adnan Esmail and Yunhao Fang and Chelsea Finn and Catherine Glossop and Thomas Godden and Ivan Goryachev and Lachy Groom and Hunter H...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Physical Intelligence and Bo Ai and Ali Amin and Raichelle Aniceto and Ashwin Balakrishna and Greg Balke and Kevin Black and George Bokinsky and Shihao Cao and Thomas Charbonnier and Vedant Choudhary and Foster Collins and Ken Conley and Grace Connors and James Darpinian and Karan Dhabalia and Maitrayee Dhaka and Jared DiCarlo and Danny Driess and Michael...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2026 , eprint=
SOP: A Scalable Online Post-Training System for Vision-Language-Action Models , author=. 2026 , eprint=
2026
-
[23]
2024 , eprint=
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots , author=. 2024 , eprint=
2024
-
[24]
2024 , howpublished =
RoboCasa-Cosmos-Policy , author =. 2024 , howpublished =
2024
-
[25]
2023 , eprint=
RT-1: Robotics Transformer for Real-World Control at Scale , author=. 2023 , eprint=
2023
-
[26]
2024 , eprint=
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion , author=. 2024 , eprint=
2024
-
[27]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[28]
2026 , eprint=
Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising , author=. 2026 , eprint=
2026
-
[29]
2025 , eprint=
DepthVLA: Enhancing Vision-Language-Action Models with Depth-Aware Spatial Reasoning , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Video Generators are Robot Policies , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Diffusion Models: A Comprehensive Survey of Methods and Applications , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Robot Data Curation with Mutual Information Estimators , author=. 2025 , eprint=
2025
-
[38]
2026 , eprint=
TwinRL: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation , author=. 2026 , eprint=
2026
-
[39]
2025 , eprint=
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy , author=. 2025 , eprint=
2025
-
[40]
2026 , eprint=
TreeAdv: Tree-Structured Advantage Redistribution for Group-Based RL , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.