AxDafny: Agentic Verified Code Generation in Dafny
Pith reviewed 2026-07-01 04:58 UTC · model grok-4.3
The pith
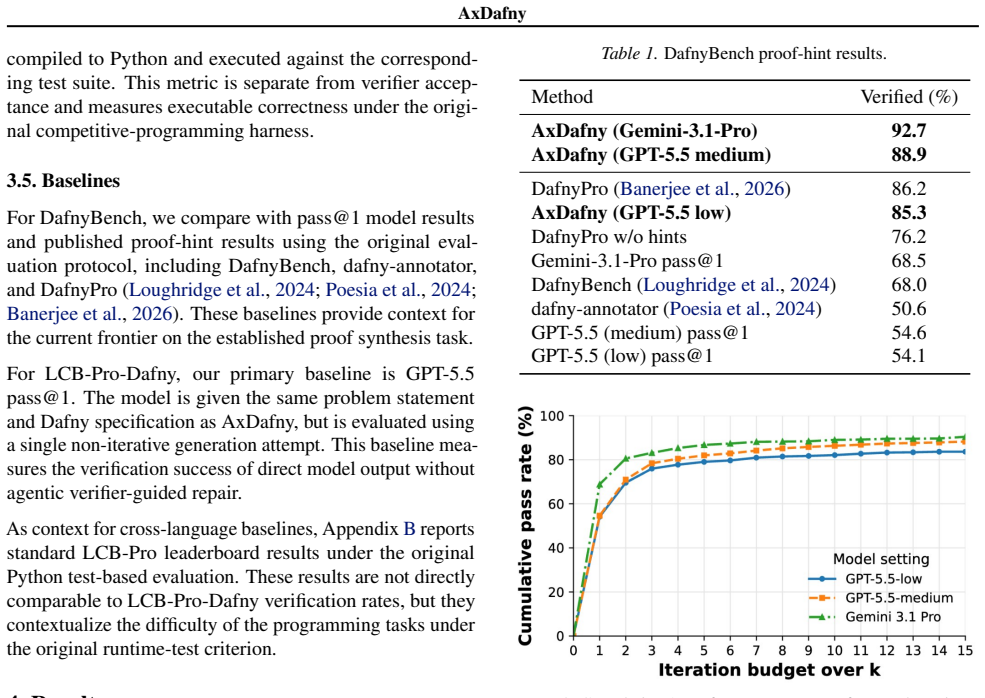
AxDafny uses a verifier-guided repair loop to generate verifiable Dafny code at 92.7 percent success on DafnyBench.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
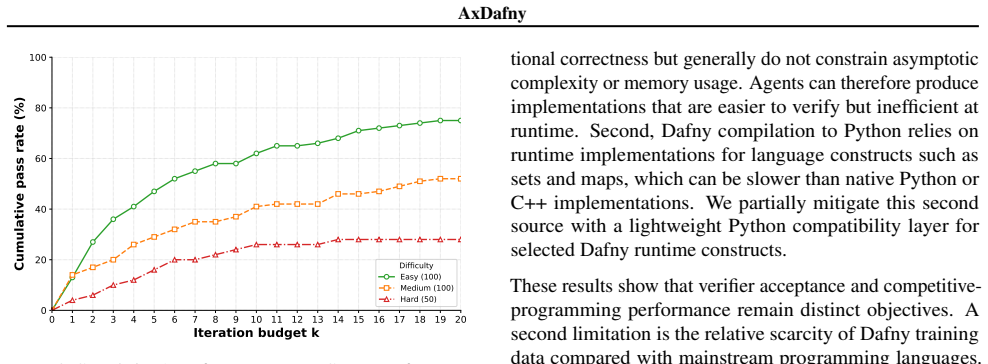
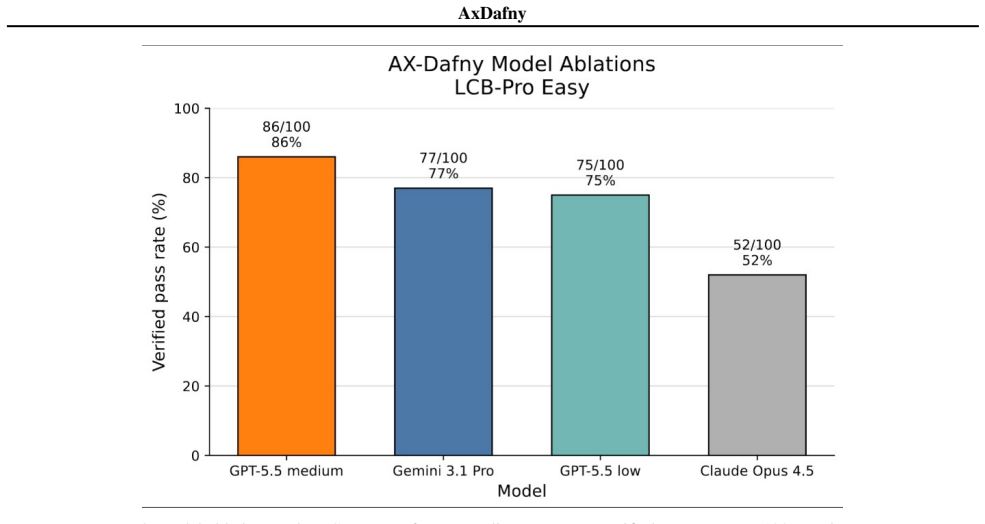
AxDafny is a verifier-guided repair framework that iteratively produces implementations, invariants, assertions, and termination arguments until the Dafny verifier accepts the full artifact. On DafnyBench this yields 92.7 percent verification success, exceeding the best previously reported proof-hint baseline by 6.5 percentage points. On the new LCB-Pro-Dafny benchmark of 250 problems the method substantially improves over baseline GPT-5.5 performance. The authors establish that verification success and runtime test performance measure different aspects of generated code.
What carries the argument
The verifier-guided iterative repair loop that generates and revises both the implementation and the required proof artifacts until the Dafny verifier accepts them.
If this is right
- Verified code generation becomes feasible for a wider range of programming tasks that require formal guarantees.
- Verification success and runtime testing can be treated as complementary rather than interchangeable evaluation criteria.
- Agentic repair methods can be applied to other formal verification languages that supply similar feedback.
- Competition-style problems with specifications provide a reproducible way to measure progress in verified synthesis.
Where Pith is reading between the lines
- If the repair loop generalizes beyond the tested models, similar agentic frameworks could lower the manual effort required for industrial formal verification.
- Future experiments could test whether the same loop produces comparable gains when paired with open-source models instead of GPT-5.5.
- Hybrid pipelines that run both verification and runtime tests on the same outputs might yield stronger overall correctness signals than either alone.
Load-bearing premise
That performance gains are produced by the repair loop rather than by unstated differences in base model, prompting strategy, or benchmark-specific tuning.
What would settle it
A controlled comparison that applies the identical base model and prompting strategy both with and without the AxDafny repair loop on DafnyBench and finds no meaningful difference in verification success rates.
Figures

read the original abstract
We study agentic code generation in Dafny, where a model must generate both executable code and the proof artifacts for verification. We present AxDafny, a verifier-guided repair framework that iteratively generates implementations, invariants, assertions, and termination arguments. We also introduce LiveCodeBench-Pro-Dafny (LCB-Pro-Dafny), a benchmark of 250 competition-style programming problems translated into Dafny with formal specifications and a verifier-based evaluation harness. On LCB-Pro-Dafny, AxDafny substantially improves verification success over baseline GPT-5.5 performance. On DafnyBench, AxDafny achieves 92.7\% verification success, outperforming the strongest previously reported proof-hint baseline by 6.5 percentage points. Lastly, we show that verification success and runtime test performance measure different aspects of generated code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AxDafny, a verifier-guided iterative repair framework for agentic generation of Dafny code, invariants, assertions, and termination arguments. It also presents the new LCB-Pro-Dafny benchmark (250 competition-style problems with formal specs) and reports that AxDafny improves verification success over a GPT-5.5 baseline on LCB-Pro-Dafny, achieves 92.7% success on DafnyBench (6.5 pp above the strongest prior proof-hint baseline), and that verification success and runtime tests capture distinct properties of generated code.
Significance. If the empirical gains are shown to arise specifically from the repair loop under matched base-model and prompting conditions, the work would provide a concrete, reproducible demonstration of verifier-in-the-loop agentic methods for verified programming and supply a new public benchmark with harness; these elements would be useful to the verified code generation community.
major comments (2)
- [Abstract] Abstract: the 6.5 pp gain on DafnyBench (92.7 % vs. prior proof-hint baseline) is presented as evidence for the AxDafny repair loop, yet the abstract supplies no statement that the identical base model, temperature, system prompt, or few-shot examples were used for both the AxDafny runs and the cited baseline; without this control the attribution cannot be isolated from model-version or prompting differences.
- [Abstract] Abstract / §3 (implied methods): the claim of substantial improvement over GPT-5.5 on LCB-Pro-Dafny likewise lacks any description of the baseline prompting strategy, number of repair iterations allowed, or error-analysis breakdown, making it impossible to assess whether the reported numerical lift is load-bearing for the framework or an artifact of unstated experimental choices.
minor comments (1)
- [Abstract] The abstract refers to "GPT-5.5" without clarifying whether this denotes a specific model version or a typo for an existing model; this should be standardized in the methods section.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying points where the abstract could more explicitly describe the experimental controls. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 6.5 pp gain on DafnyBench (92.7 % vs. prior proof-hint baseline) is presented as evidence for the AxDafny repair loop, yet the abstract supplies no statement that the identical base model, temperature, system prompt, or few-shot examples were used for both the AxDafny runs and the cited baseline; without this control the attribution cannot be isolated from model-version or prompting differences.
Authors: We agree that the abstract should state the matched conditions explicitly. The methods section details that the DafnyBench comparisons reuse the identical base model, temperature, system prompt, and few-shot examples from the cited proof-hint baseline, differing only by the addition of the verifier-guided repair loop. We will revise the abstract to include a short parenthetical clarification on these controls. revision: yes
-
Referee: [Abstract] Abstract / §3 (implied methods): the claim of substantial improvement over GPT-5.5 on LCB-Pro-Dafny likewise lacks any description of the baseline prompting strategy, number of repair iterations allowed, or error-analysis breakdown, making it impossible to assess whether the reported numerical lift is load-bearing for the framework or an artifact of unstated experimental choices.
Authors: We acknowledge the abstract is too terse on this point. Section 3 describes the LCB-Pro-Dafny baseline as single-pass generation with GPT-5.5 under the same prompt template (problem statement plus formal spec) and the same model settings; AxDafny adds up to five verifier-guided repair iterations. No separate error-analysis breakdown appears in the current manuscript. We will revise the abstract to note the matched base model and prompting plus the use of iterative repair, and we will add a concise error breakdown (or reference to an appendix table) in the revision. revision: yes
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper reports verification success rates (92.7% on DafnyBench, improvement over baseline on LCB-Pro-Dafny) as direct empirical outcomes from running AxDafny on fixed benchmarks. No equations, derivations, fitted parameters, or first-principles claims appear that could reduce to self-definitional inputs, fitted predictions, or self-citation chains. The central results are independent measurements on external benchmarks and do not rely on any load-bearing step that collapses by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
arXiv preprint arXiv:2406.08467 , year =
DafnyBench: A Benchmark for Formal Software Verification , author =. arXiv preprint arXiv:2406.08467 , year =
-
[10]
ICLR 2024 Conference , year =
Clover: Closed-loop verifiable code generation , author =. ICLR 2024 Conference , year =
2024
-
[11]
Towards AI-Assisted Synthesis of Verified Dafny Methods , author =. Proc. ACM Softw. Eng. , volume =. 2024 , doi =
2024
-
[12]
Logic for Programming, Artificial Intelligence, and Reasoning , pages =
Dafny: An Automatic Program Verifier for Functional Correctness , author =. Logic for Programming, Artificial Intelligence, and Reasoning , pages =
-
[13]
Program Proofs , author =
-
[14]
A Minimal Agent for Automated Theorem Proving
A Minimal Agent for Automated Theorem Proving , author =. arXiv preprint arXiv:2602.24273 , year =. 2602.24273 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , journal =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , journal =. 2024 , eprint =
2024
-
[16]
2026 , eprint =
DafnyPro: LLM-Assisted Automated Verification for Dafny Programs , author =. 2026 , eprint =
2026
-
[17]
2025 , eprint =
Specification-Guided Repair of Arithmetic Errors in Dafny Programs using LLMs , author =. 2025 , eprint =
2025
-
[18]
2025 , eprint =
ATLAS: Automated Toolkit for Large-Scale Verified Code Synthesis , author =. 2025 , eprint =
2025
-
[19]
2025 , eprint =
Inferring Multiple Helper Dafny Assertions with LLMs , author =. 2025 , eprint =
2025
-
[20]
2024 , eprint =
dafny-annotator: AI-Assisted Verification of Dafny Programs , author =. 2024 , eprint =
2024
-
[21]
arXiv preprint arXiv:2509.23061 , year =
Local Success Does Not Compose: Benchmarking Large Language Models for Compositional Formal Verification , author =. arXiv preprint arXiv:2509.23061 , year =
-
[22]
VeriEquivBench: An Equivalence Score for Ground-Truth-Free Evaluation of Formally Verifiable Code
VeriEquivBench: An Equivalence Score for Ground-Truth-Free Evaluation of Formally Verifiable Code , author =. International Conference on Learning Representations , year =. 2510.06296 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2024 , howpublished =
HumanEval-Dafny: Translating HumanEval to Dafny , author =. 2024 , howpublished =
2024
-
[24]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author =. arXiv preprint arXiv:2403.07974 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2506.11928 , year =
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming? , author =. arXiv preprint arXiv:2506.11928 , year =
-
[28]
2026 , howpublished =
LiveCodeBench-Pro: LLM Benchmarking Toolkit , author =. 2026 , howpublished =
2026
-
[29]
2026 , howpublished =
LiveCodeBench Pro Live Leaderboard , author =. 2026 , howpublished =
2026
-
[30]
2026 , howpublished =
LiveCodeBench Pro Benchmark Leaderboard , author =. 2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.