PointSplat: Compact Gaussian Splatting via Human-Centric Prediction
Pith reviewed 2026-07-01 05:23 UTC · model grok-4.3
The pith
PointSplat infers compact Gaussian primitives directly from 3D point sets for human rendering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
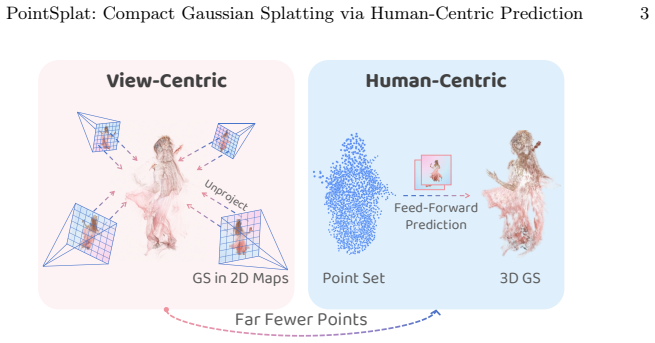
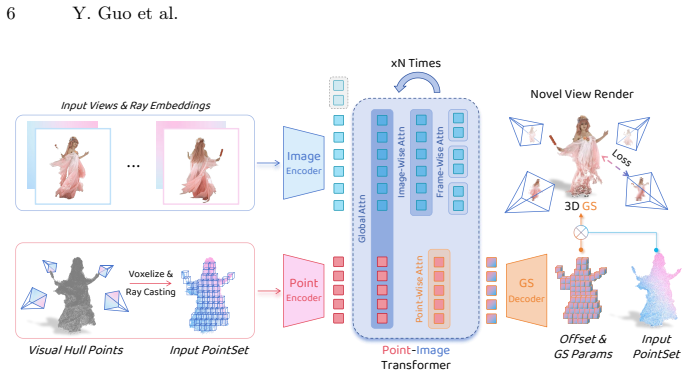
PointSplat directly infers Gaussian primitives from an input point set by first estimating a coarse geometric proxy and performing ray casting to prune redundant points and establish explicit 2D-3D correspondences, then employing a Point-Image Transformer to fuse appearance and geometry features and predict Gaussian attributes in a single forward pass, thereby restricting predictions to foreground regions of interest and yielding a more compact representation.
What carries the argument
Point-Image Transformer that fuses appearance and geometry features after ray-casting pruning on a coarse geometric proxy to predict Gaussian attributes from point sets.
If this is right
- The total number of Gaussians needed for high-fidelity human rendering drops because predictions are limited to foreground regions.
- Novel-view rendering quality rises relative to methods that encode the same content repeatedly across views.
- Performance holds across varying input view counts and image resolutions without retraining.
- Lower data volume supports real-time transmission in bandwidth-limited immersive systems.
Where Pith is reading between the lines
- The same pruning-plus-transformer pipeline could be tested on non-human scenes if foreground identification generalizes.
- Integration with existing point-cloud capture pipelines would allow end-to-end 3D content pipelines without intermediate multi-view encoding.
- Reduced Gaussian count per subject could lower memory and decode costs in downstream AR or VR viewers.
Load-bearing premise
Estimating a coarse geometric proxy followed by ray casting can reliably prune redundant points and establish 2D-3D correspondences without losing critical appearance or geometry details needed for accurate Gaussian attribute prediction.
What would settle it
Rendering quality that falls below view-centric baselines on the same input views and resolutions when the number of views is reduced would show the claimed robustness does not hold.
Figures






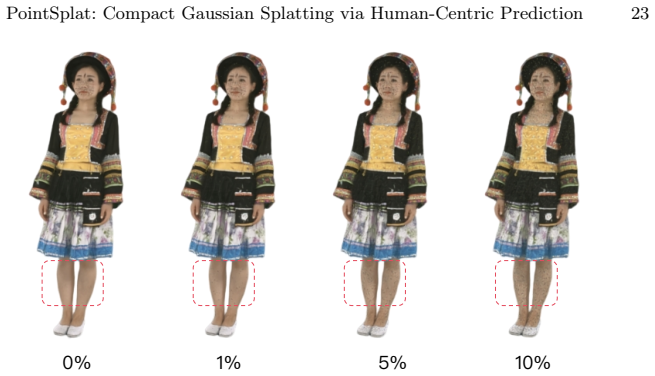
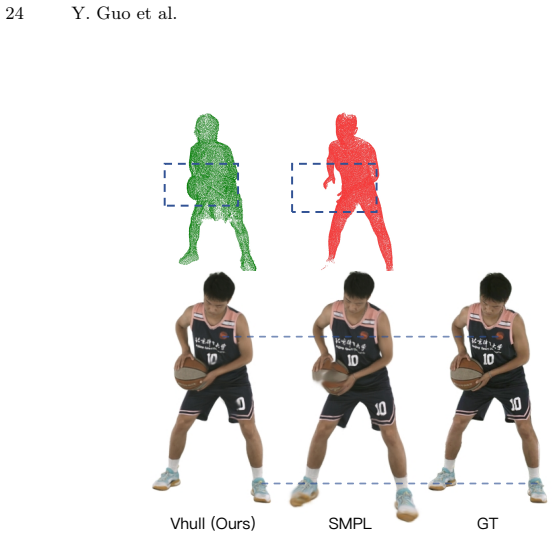
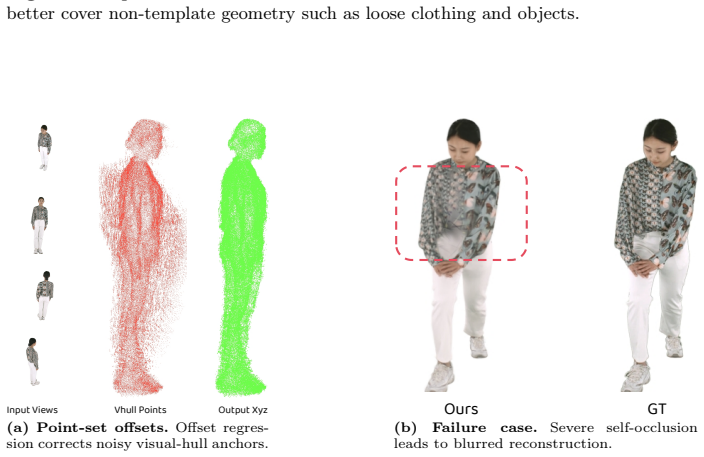
read the original abstract
Producing 3D human representations from input views on the fly is essential for immersive live streaming systems, where representation compactness is as critical as high fidelity given limited computational power and transmission bandwidth. Although recent feed-forward reconstruction methods achieve impressive quality through the view-centric prediction of 3D representations, they repeatedly encode the same subject content across multiple views, leading to significant inter-view redundancy. Our key insight is to perform predictions directly in 3D space, enabling the network to learn and produce a highly compact representation. To this end, we propose PointSplat, a novel human-centric approach that directly infers Gaussian primitives from an input point set. The proposed method first estimates a coarse geometric proxy and performs ray casting to prune redundant points and establish explicit 2D--3D correspondences. Subsequently, it employs a Point-Image Transformer to fuse appearance and geometry features, predicting Gaussian attributes in a single forward pass. This design restricts predictions to foreground regions of interest, substantially reducing the total number of Gaussians while improving novel-view rendering quality. Extensive experiments demonstrate that PointSplat achieves higher efficiency and quality while exhibiting strong robustness to variations in view count and image resolution across multiple datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PointSplat, a feed-forward human-centric method for compact 3D Gaussian splatting. It directly predicts Gaussian primitives from an input point set by first estimating a coarse geometric proxy, applying ray casting to prune redundant points and establish 2D-3D correspondences, then using a Point-Image Transformer to fuse appearance and geometry features and predict all Gaussian attributes in one forward pass. The design is claimed to restrict predictions to foreground regions, yielding fewer Gaussians, higher novel-view rendering quality, and robustness to changes in view count and image resolution across datasets.
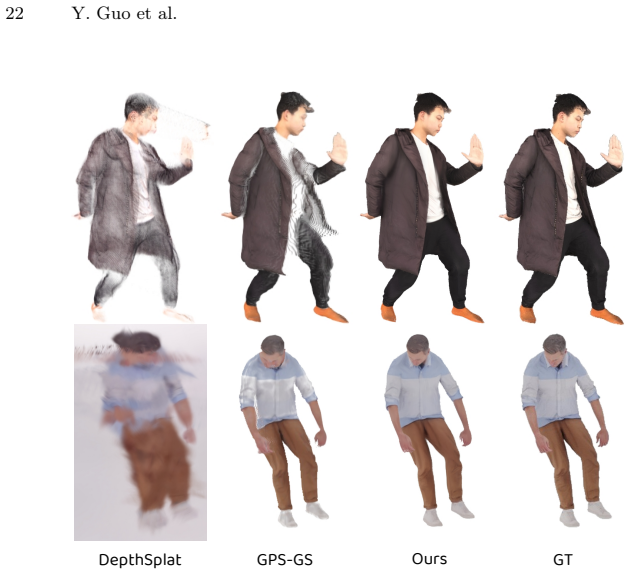
Significance. If the efficiency and quality claims are substantiated, the work could meaningfully advance real-time 3D human reconstruction for bandwidth-constrained applications such as live streaming by eliminating inter-view redundancy through explicit 3D-space prediction rather than repeated view-centric encoding.
major comments (1)
- [Method (pruning and correspondence stage)] The ray-casting pruning step after coarse proxy estimation is load-bearing for the dual claim of fewer Gaussians and improved quality, yet the manuscript provides no quantitative validation (e.g., fraction of points retained, PSNR change when the pruning module is disabled, or ablation across view counts) that critical geometry or appearance details are preserved; without such checks the central compactness-plus-quality result remains unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Method (pruning and correspondence stage)] The ray-casting pruning step after coarse proxy estimation is load-bearing for the dual claim of fewer Gaussians and improved quality, yet the manuscript provides no quantitative validation (e.g., fraction of points retained, PSNR change when the pruning module is disabled, or ablation across view counts) that critical geometry or appearance details are preserved; without such checks the central compactness-plus-quality result remains unverified.
Authors: We agree that the manuscript would be strengthened by explicit quantitative validation of the ray-casting pruning step. In the revised version we will add an ablation that reports (i) the fraction of points retained after pruning, (ii) the PSNR change when the pruning module is disabled, and (iii) performance across varying input view counts. These results will confirm that critical geometry and appearance details are preserved while the pruning contributes to the reported compactness and quality gains. revision: yes
Circularity Check
No significant circularity; architectural pipeline is self-contained
full rationale
The paper presents PointSplat as a feed-forward architecture that estimates a coarse geometric proxy, applies ray casting for pruning and correspondence, then uses a Point-Image Transformer to predict Gaussian attributes directly from the input point set. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that would reduce the claimed compactness or quality gains to the inputs by construction. The pruning step is described as an explicit design choice to restrict predictions to foreground regions rather than a derived necessity that loops back on itself. The derivation chain remains independent of the target results and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization (2016), arXiv:1607.06450
Pith/arXiv arXiv 2016
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Charatan, D., Li, S., Tagliasacchi, A., Sitzmann, V.: pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[3]
In: Proceedings of the The International Conference on Learning Representations (ICLR) (2025)
Chen, Y., Wu, Q., Li, M., Lin, W., Harandi, M., Cai, J.: Fast feedforward 3d gaus- sian splatting compression. In: Proceedings of the The International Conference on Learning Representations (ICLR) (2025)
2025
-
[4]
arXiv preprint arXiv:2403.14627 (2024)
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. arXiv preprint arXiv:2403.14627 (2024)
arXiv 2024
-
[5]
arXiv preprintarXiv:2307.10173(2023)
Cheng, W., Chen, R., Yin, W., Fan, S., Chen, K., He, H., Luo, H., Cai, Z., Wang, J., Gao, Y., Yu, Z., Lin, Z., Ren, D., Yang, L., Liu, Z., Loy, C.C., Qian, C., Wu, W., Lin, D., Dai, B., Lin, K.Y.: Dna-rendering: A diverse neural actor repository for high-fidelity human-centric rendering. arXiv preprintarXiv:2307.10173(2023)
arXiv 2023
-
[6]
In: Proceedings of the The International Conference on Learning Repre- sentations (ICLR) (2024)
Dao, T.: FlashAttention-2: Faster attention with better parallelism and work par- titioning. In: Proceedings of the The International Conference on Learning Repre- sentations (ICLR) (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Fridovich-Keil, S., Yu, A., Tancik, M., Chen, Q., Recht, B., Kanazawa, A.: Plenox- els: Radiance fields without neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[8]
Proceedings of the NeurIPS (NeurIPS) (2024)
Gao, R., Holynski, A., Henzler, P., Brussee, A., Martin-Brualla, R., Srinivasan, P.P., Barron, J.T., Poole, B.: Cat3d: Create anything in 3d with multi-view diffu- sion models. Proceedings of the NeurIPS (NeurIPS) (2024)
2024
-
[9]
Gortler, S.J., Grzeszczuk, R., Szeliski, R., Cohen, M.F.: The lumigraph. In: Pro- ceedings of the Annual Conference on Computer Graphics and Interactive Tech- niques (SIGGRAPH). pp. 43–54. SIGGRAPH ’96 (1996).https://doi.org/10. 1145/237170.237200
arXiv 1996
-
[10]
Henry, A., Dachapally, P.R., Pawar, S., Chen, Y.: Query-key normalization for transformers (2020), arXiv:2010.04245
arXiv 2020
-
[11]
arXiv preprint arXiv:2311.04400 (2023)
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023)
Pith/arXiv arXiv 2023
-
[12]
arXiv preprint (2023)
Hu, S., Liu, Z.: Gauhuman: Articulated gaussian splatting for real-time 3d human rendering. arXiv preprint (2023)
2023
-
[13]
ACM Transactions on Graphics (TOG)42(4), 1–12 (2023).https://doi.org/10
Işık, M., Rünz, M., Georgopoulos, M., Khakhulin, T., Starck, J., Agapito, L., Nießner, M.: Humanrf: High-fidelity neural radiance fields for humans in motion. ACM Transactions on Graphics (TOG)42(4), 1–12 (2023).https://doi.org/10. 1145/3592415 16 Y. Guo et al
2023
-
[14]
arXiv preprint arXiv:2505.23716 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. arXiv preprint arXiv:2505.23716 (2025)
arXiv 2025
-
[15]
In: Pro- ceedings of the The International Conference on Learning Representations (ICLR) (2025)
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: Lvsm: A large view synthesis model with minimal 3d inductive bias. In: Pro- ceedings of the The International Conference on Learning Representations (ICLR) (2025)
2025
-
[16]
In: Proceedings of the IEEE International Con- ference on Computer Vision (ICCV) (2025)
Jin, Y., Peng, S., Wang, X., Xie, T., Xu, Z., Yang, Y., Shen, Y., Bao, H., Zhou, X.: Diffuman4d: 4d consistent human view synthesis from sparse-view videos with spatio-temporal diffusion models. In: Proceedings of the IEEE International Con- ference on Computer Vision (ICCV) (2025)
2025
-
[17]
ACM Transactions on Graphics (TOG)42(4) (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (TOG)42(4) (2023)
2023
-
[18]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Kutulakos, K., Seitz, S.: A theory of shape by space carving. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). vol. 1, pp. 307–314 vol.1 (1999).https://doi.org/10.1109/ICCV.1999.791235
-
[19]
Lee, C.C., Tabatabai, A., Tashiro, K.: Free viewpoint video (fvv) survey and future research direction. APSIPA Transactions on Signal and Information Processing4, e15 (2015).https://doi.org/10.1017/ATSIP.2015.18
-
[20]
In: Proceedings of the Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH)
Levoy, M., Hanrahan, P.: Light field rendering. In: Proceedings of the Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH). pp. 31–42. SIGGRAPH ’96 (1996).https://doi.org/10.1145/237170.237199
-
[21]
arXiv preprint arXiv:2311.06214 (2023)
Li, J., Tan, H., Zhang, K., Xu, Z., Luan, F., Xu, Y., Hong, Y., Sunkavalli, K., Shakhnarovich, G., Bi, S.: Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. arXiv preprint arXiv:2311.06214 (2023)
arXiv 2023
-
[22]
arXiv preprint arXiv:2511.10647 (2025)
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
Pith/arXiv arXiv 2025
-
[23]
In: Proceedings of the ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia (SIGGRAPH Asia) (2022)
Lin, H., Peng, S., Xu, Z., Yan, Y., Shuai, Q., Bao, H., Zhou, X.: Efficient neural radiance fields for interactive free-viewpoint video. In: Proceedings of the ACM SIGGRAPH Conference and Exhibition on Computer Graphics and Interactive Techniques in Asia (SIGGRAPH Asia) (2022)
2022
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Lu, T., Yu, M., Xu, L., Xiangli, Y., Wang, L., Lin, D., Dai, B.: Scaffold-gs: Struc- tured 3d gaussians for view-adaptive rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20654– 20664 (2024)
2024
-
[25]
ACM Transactions on Graphics (TOG)38(4), 1–14 (2019)
Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: Practical view synthesis with pre- scriptive sampling guidelines. ACM Transactions on Graphics (TOG)38(4), 1–14 (2019)
2019
-
[26]
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: representing scenes as neural radiance fields for view synthesis. Commun. ACM65(1), 99–106 (2021).https://doi.org/10.1145/3503250
-
[27]
ACM Transactions on Graphics (TOG)41(4) (2022).https://doi.org/10.1145/3528223.3530127
Müller,T.,Evans,A.,Schied,C.,Keller,A.:Instantneuralgraphicsprimitiveswith a multiresolution hash encoding. ACM Transactions on Graphics (TOG)41(4) (2022).https://doi.org/10.1145/3528223.3530127
-
[28]
Ng, R., Levoy, M., Brédif, M., Duval, G., Horowitz, M., Hanrahan, P.: Light field photography with a hand-held plenoptic camera. Ph.D. thesis, Stanford university (2005) PointSplat: Compact Gaussian Splatting via Human-Centric Prediction 17
2005
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Peng, S., Zhang, Y., Xu, Y., Wang, Q., Shuai, Q., Bao, H., Zhou, X.: Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[31]
arXiv preprint arXiv:2503.10625 (2025)
Qiu, L., Li, P., Li, H., Zuo, Q., Gu, X., Dong, Y., Yuan, W., Peng, R., Zhu, S., Han, X., Chen, G., Dong, Z.: Lhm++: An efficient large human reconstruction model for pose-free images to 3d. arXiv preprint arXiv:2503.10625 (2025)
arXiv 2025
-
[32]
arXiv preprint arXiv:2403.17898 (2024)
Ren, K., Jiang, L., Lu, T., Yu, M., Xu, L., Ni, Z., Dai, B.: Octree-gs: Towards consistent real-time rendering with lod-structured 3d gaussians. arXiv preprint arXiv:2403.17898 (2024)
arXiv 2024
-
[33]
Renderpeople: Renderpeople.https://renderpeople.com/3d-people(2018)
2018
-
[34]
Szymanowicz, S., Zhang, J.Y., Srinivasan, P., Gao, R., Brussee, A., Holynski, A., Martin-Brualla, R., Barron, J.T., Henzler, P.: Bolt3D: Generating 3D Scenes in Seconds.In:ProceedingsoftheIEEEInternationalConferenceonComputerVision (ICCV) (2025)
2025
-
[35]
arXiv preprint arXiv:2402.05054 (2024)
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi- view gaussian model for high-resolution 3d content creation. arXiv preprint arXiv:2402.05054 (2024)
arXiv 2024
-
[36]
Team, T.H.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation (2025), arXiv:2501.12202
Pith/arXiv arXiv 2025
-
[37]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Wang, Q., Wang, Z., Genova, K., Srinivasan, P., Zhou, H., Barron, J.T., Martin- Brualla, R., Snavely, N., Funkhouser, T.: Ibrnet: Learning multi-view image-based rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[39]
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy (2023), arXiv:2312.14132
arXiv 2023
-
[40]
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π3: Scalable permutation-equivariant visual geometry learning (2025), arXiv:2507.13347
Pith/arXiv arXiv 2025
-
[41]
IEEE Transactions on Image Processing 13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861
Wang, Z., Bovik, A., Sheikh, H., Simoncelli, E.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing (TIP)13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861
-
[42]
arXiv preprint arXiv:2405.14832 (2024)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Xu, J., Torr, P., Cao, X., Yao, Y.: Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer. arXiv preprint arXiv:2405.14832 (2024)
arXiv 2024
-
[43]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Xiao, J., Zhang, Q., Nie, Y., Zhu, L., Zheng, W.S.: RoGSplat: Learning robust gen- eralizable human gaussian splatting from sparse multi-view images. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: Depth- splat: Connecting gaussian splatting and depth. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xu, Q., Xu, Z., Philip, J., Bi, S., Shu, Z., Sunkavalli, K., Neumann, U.: Point-nerf: Point-based neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5438–5448 (2022) 18 Y. Guo et al
2022
-
[46]
ACM Transactions on Graphics (TOG)43(6) (2024)
Xu, Z., Xu, Y., Yu, Z., Peng, S., Sun, J., Bao, H., Zhou, X.: Representing long volumetric video with temporal gaussian hierarchy. ACM Transactions on Graphics (TOG)43(6) (2024)
2024
-
[47]
In: Proceedings of the The International Conference on Learning Representations (ICLR) (2024)
Yang, Z., Yang, H., Pan, Z., Zhang, L.: Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting. In: Proceedings of the The International Conference on Learning Representations (ICLR) (2024)
2024
-
[48]
In: Proceedings of the European Conference on Computer Vision (ECCV) (2018)
Yao, Y., Luo, Z., Li, S., Fang, T., Quan, L.: Mvsnet: Depth inference for unstruc- tured multi-view stereo. In: Proceedings of the European Conference on Computer Vision (ECCV) (2018)
2018
-
[49]
Yinghao, X., Zifan, S., Wang, Y., Hansheng, C., Ceyuan, Y., Sida, P., Yujun, S., Gordon, W.: Grm: Large gaussian reconstruction model for efficient 3d reconstruc- tion and generation (2024), arXiv:2403.14621
arXiv 2024
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Yu, T., Zheng, Z., Guo, K., Liu, P., Dai, Q., Liu, Y.: Function4d: Real-time human volumetric capture from very sparse consumer rgbd sensors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[51]
ACM Transactions on Graphics (TOG)42(4) (2023).https://doi.org/10.1145/3592442
Zhang, B., Tang, J., Nießner, M., Wonka, P.: 3dshape2vecset: A 3d shape repre- sentation for neural fields and generative diffusion models. ACM Transactions on Graphics (TOG)42(4) (2023).https://doi.org/10.1145/3592442
-
[52]
In: Proceedings of the European Conference on Computer Vision (ECCV) (2024)
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: Gs- lrm: Large reconstruction model for 3d gaussian splatting. In: Proceedings of the European Conference on Computer Vision (ECCV) (2024)
2024
-
[53]
ACM Transactions on Graphics (TOG)43(4) (2024).https: //doi.org/10.1145/3658146
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high- quality 3d assets. ACM Transactions on Graphics (TOG)43(4) (2024).https: //doi.org/10.1145/3658146
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effec- tiveness of deep features as a perceptual metric. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
2018
-
[55]
Proceedings of the NeurIPS (NeurIPS) (2024)
Zhang, S., Fei, X., Liu, F., Song, H., Duan, Y.: Gaussian graph network: Learn- ing efficient and generalizable gaussian representations from multi-view images. Proceedings of the NeurIPS (NeurIPS) (2024)
2024
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Zheng, S., Zhou, B., Shao, R., Liu, B., Zhang, S., Nie, L., Liu, Y.: Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view syn- thesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Zheng, X., Liao, L., Li, X., Jiao, J., Wang, R., Gao, F., Wang, S., Wang, R.: Pku-dymvhumans: A multi-view video benchmark for high-fidelity dynamic human modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[58]
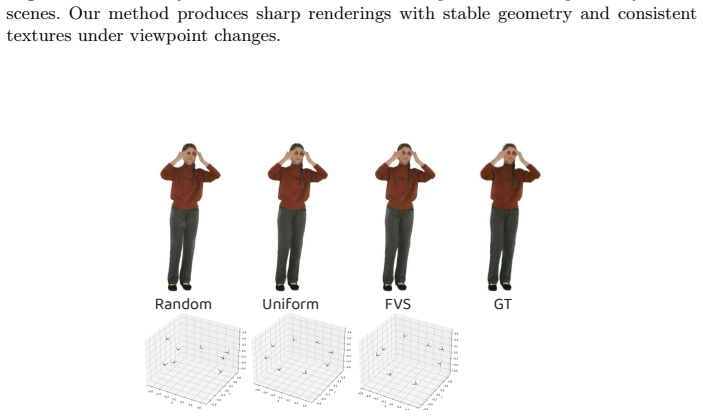
Random” indicates ran- domly sampled views. “Uniform
Ziwen, C., Tan, H., Zhang, K., Bi, S., Luan, F., Hong, Y., Fuxin, L., Xu, Z.: Long- lrm: Long-sequence large reconstruction model for wide-coverage gaussian splats. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2025) PointSplat: Compact Gaussian Splatting via Human-Centric Prediction 19 Supplementary Material A Method Det...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.