A Taxonomy of Single-Turn Textual Prompt Patterns
Pith reviewed 2026-07-02 20:17 UTC · model grok-4.3
The pith
A taxonomy organizes 30 unique and canonical prompt patterns for single-turn LLM text interactions along two dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
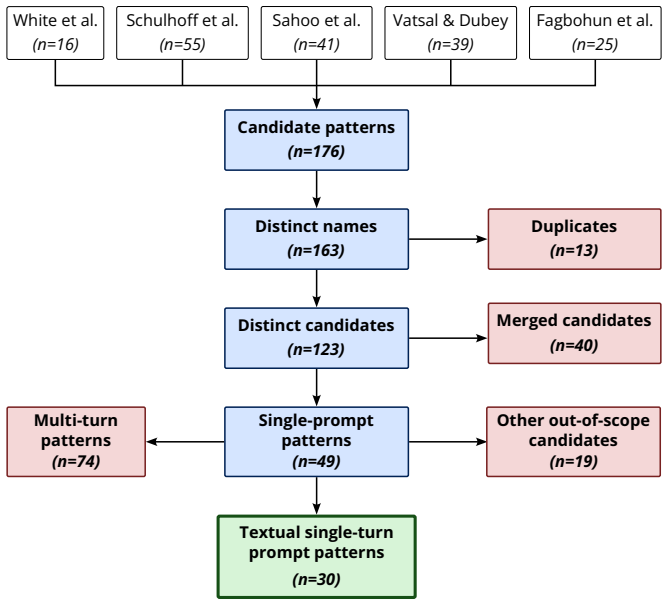
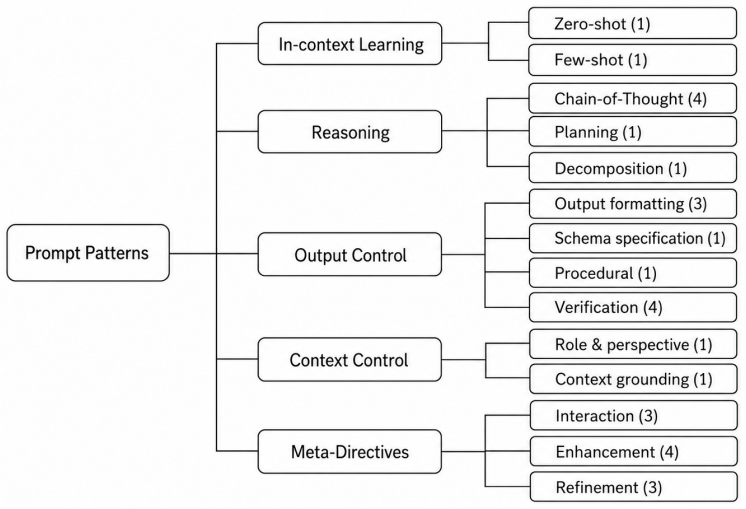
Following a reproducible method, the authors identified 30 unique and canonical prompt patterns for single-turn, text-based interactions with large language models, and organized them along two dimensions to form a taxonomy.
What carries the argument
The taxonomy of 30 canonical prompt patterns organized along two dimensions, extracted and validated from prior surveys and catalogs via a reproducible method.
If this is right
- Developers gain a reference set of standardized patterns instead of relying on ad hoc prompts.
- The two dimensions supply a framework for relating different prompt techniques to one another.
- Subsequent literature can align definitions with these 30 patterns to reduce inconsistency.
- Prompt management tools can adopt the taxonomy for consistent categorization and retrieval.
Where Pith is reading between the lines
- The taxonomy could serve as a basis for empirical studies comparing effectiveness across the 30 patterns.
- The reproducible extraction method could be reapplied to multi-turn or multimodal prompt interactions.
- Standardized patterns might support the design of automated prompt suggestion systems in IDEs.
Load-bearing premise
The patterns extracted from existing surveys and catalogs are sufficiently distinct and canonical to form a stable taxonomy without significant overlap or omission that would require revision of the two dimensions.
What would settle it
A new comprehensive survey that demonstrates substantial overlap among the 30 patterns or identifies key omitted patterns requiring changes to the two organizing dimensions.
Figures
read the original abstract
Large language models (LLMs) are now widely employed in software development and everyday use. Interacting with LLMs requires crafting prompts, which range from simple ad hoc sentences to extensive, detailed, and structured instructions. Knowledge about prompt engineering has been documented in several surveys and catalogs in the literature. However, the term ``prompt pattern'' is defined differently across sources, and existing works have classified prompt patterns in different ways. In this report, we present a taxonomy of prompt patterns for single-turn, text-based interactions. Following a reproducible method, we identified 30 unique and canonical prompt patterns, organized along two dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that, by following a reproducible method applied to existing surveys and catalogs, it has identified 30 unique and canonical single-turn textual prompt patterns for LLMs and organized them along two dimensions.
Significance. A stable, validated taxonomy of prompt patterns could reduce terminological fragmentation in prompt-engineering research and provide a shared reference for practitioners; however, the absence of methodological transparency prevents assessment of whether the claimed 30 patterns and two dimensions are reproducible or stable.
major comments (2)
- [Method] Method section: the abstract asserts a 'reproducible method' that yields exactly 30 unique canonical patterns, yet no selection criteria, deduplication rules, source-inclusion protocol, or inter-rater agreement statistics are supplied; without these, independent reproduction of the set of 30 patterns cannot be performed and the stability of the taxonomy cannot be evaluated.
- [Taxonomy] Taxonomy section: the two organizing dimensions are presented without explicit justification against alternative classifications in the cited surveys, nor is any overlap or coverage analysis (e.g., pairwise similarity or omission count) reported; this leaves open whether the dimensions are load-bearing or merely post-hoc.
minor comments (2)
- [Abstract] The abstract states that patterns are 'unique and canonical' but the body does not define 'canonical' operationally or contrast it with the source definitions that the introduction acknowledges differ across works.
- Table or figure presenting the 30 patterns should include source provenance and any merging decisions so readers can trace each pattern back to the input literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in methodological transparency and justification that limit the ability to assess reproducibility. We will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Method] Method section: the abstract asserts a 'reproducible method' that yields exactly 30 unique canonical patterns, yet no selection criteria, deduplication rules, source-inclusion protocol, or inter-rater agreement statistics are supplied; without these, independent reproduction of the set of 30 patterns cannot be performed and the stability of the taxonomy cannot be evaluated.
Authors: We agree that the Method section lacks the necessary detail. The abstract's reference to a 'reproducible method' reflects our internal consolidation process across the cited surveys, but this process was not documented with explicit criteria. In the revision we will expand the Method section with: (1) source-inclusion protocol, (2) deduplication rules that reduced the initial set to 30 canonical patterns, (3) selection criteria for uniqueness, and (4) any consistency checks performed. This will enable independent reproduction and stability evaluation. revision: yes
-
Referee: [Taxonomy] Taxonomy section: the two organizing dimensions are presented without explicit justification against alternative classifications in the cited surveys, nor is any overlap or coverage analysis (e.g., pairwise similarity or omission count) reported; this leaves open whether the dimensions are load-bearing or merely post-hoc.
Authors: We acknowledge the absence of explicit justification and coverage analysis. The two dimensions were chosen because they capture recurring distinctions in the surveyed literature, but this rationale was not articulated. In the revision we will add a subsection that (a) compares our dimensions against alternative classifications appearing in the cited works and (b) reports a mapping of all 30 patterns onto the dimensions, including overlap counts and any patterns that fall outside the chosen structure. This will demonstrate whether the dimensions are substantive. revision: yes
Circularity Check
No circularity in literature synthesis
full rationale
The paper constructs a taxonomy by synthesizing patterns from external surveys and catalogs via a described method. No equations, fitted parameters, self-definitional reductions, or load-bearing self-citations appear; the 30 patterns and two dimensions are outputs organized from independent sources rather than redefined or forced by the paper's own inputs. The work is self-contained as a classification exercise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing surveys and catalogs contain prompt patterns that admit a stable canonicalization into a small number of unique forms.
Reference graph
Works this paper leans on
-
[1]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M. Zhang. Large language models for software engineering: Survey and open problems. InInternational Conference on Software Engineering: Future of Software Engineering, ICSE-FoSE, pages 31–53. IEEE, 2023
2023
-
[2]
REALM: A dataset of real-world LLM use cases
JingwenCheng,KshitishGhate,WenyueHua,WilliamYangWang, HongShen, andFeiFang. REALM: A dataset of real-world LLM use cases. InFindings of the Association for Computational Linguistics, pages 8331–8341. ACL, 2025
2025
-
[3]
Unleashing the potential of prompt engineering for large language models.Patterns, 6(6):101260, 2025
Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, and Shengxin Zhu. Unleashing the potential of prompt engineering for large language models.Patterns, 6(6):101260, 2025
2025
-
[4]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
Jules White, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert, Ashraf Elnashar, JesseSpencer-Smith, andDouglasC.Schmidt. Apromptpatterncatalogtoenhancepromptengineering with chatgpt. Technical Report 2302.11382, arXiv, feb 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, YinhengLi,AayushGupta,HyoJungHan,SevienSchulhoff,PranavSandeepDulepet,SauravVidyadhara, Dayeon Ki, Sweta Agrawal, Chau Pham, Gerson Kroiz, Feileen Li, Hudson Tao, Ashay Srivastava, Hevander Da Costa, Saloni Gupta, Megan L. Rogers, Inna Goncearenco, Giuseppe Sarl...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications. Technical Report 2402.07927, arXiv, mar 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
A survey of prompt engineering methods in large language models for different nlp tasks
Shubham Vatsal and Harsh Dubey. A survey of prompt engineering methods in large language models for different nlp tasks. Technical Report 2407.12994, arXiv, jul 2024
-
[8]
Harrison, and Anton Dereventsov
Oluwole Fagbohun, Rachel M. Harrison, and Anton Dereventsov. An empirical categorization of prompting techniques for large language models: A practitioner’s guide. Technical Report 2402.14837, arXiv, feb 2024
-
[9]
From prompts to templates: A systematic prompt template analysis for real-world llmapps
Yuetian Mao, Junjie He, and Chunyang Chen. From prompts to templates: A systematic prompt template analysis for real-world llmapps. InInternational Conference on the Foundations of Software Engineering, FSE Companion ’25, pages 75–86. ACM, 2025. 23
2025
-
[10]
Language models are few-shot learners
TomBrown,BenjaminMann,NickRyder,MelanieSubbiah, JaredDKaplan, PrafullaDhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjam...
2020
-
[11]
Addison Wesley Professional, 1994
Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides.Design Patterns: Elements of Reusable Object-Oriented Software. Addison Wesley Professional, 1994
1994
-
[12]
Michael Hewing and Vincent Leinhos. The prompt canvas: A literature-based practitioner guide for creating effective prompts in large language models. Technical Report 2412.05127, arXiv, dec 2024
-
[13]
TELeR: A general taxonomy of LLM prompts for benchmarking complex tasks
Shubhra Kanti Karmaker Santu and Dongji Feng. TELeR: A general taxonomy of LLM prompts for benchmarking complex tasks. InFindings of the Association for Computational Linguistics, pages 14197–14203. ACL, 2023
2023
-
[14]
The perfect prompt: A prompt engineering cheat sheet.https://medium.com/ the-generator/the-perfect-prompt-prompt-engineering-cheat-sheet-d0b9c62a2bba , apr 2024
Maximilian Vogel. The perfect prompt: A prompt engineering cheat sheet.https://medium.com/ the-generator/the-perfect-prompt-prompt-engineering-cheat-sheet-d0b9c62a2bba , apr 2024
2024
-
[15]
How I Won Singapore’s GPT-4 Prompt En- gineering Competition
Sheila Teo. How I Won Singapore’s GPT-4 Prompt En- gineering Competition. https://towardsdatascience.com/ how-i-won-singapores-gpt-4-prompt-engineering-competition-34c195a93d41 , dec 2023
2023
-
[16]
NzubechukwuC.Ohalete, KevinB.Gittner, andLaurenM.Matheny. Costar-a: Apromptingframework for enhancing large language model performance on point-of-view questions. Technical Report 2510.12637, arXiv, oct 2025
-
[17]
Improving llm’s response with a new prompt framework rcfor
Tuan Pham and Tuan Nguyen Ngoc. Improving llm’s response with a new prompt framework rcfor. In Applying New Technology in Green Buildings, pages 666–670. IEEE, 2025
2025
-
[18]
Principled instructions are all you need for questioning llama-1/2, gpt-3.5/4
Sondos Mahmoud Bsharat, Aidar Myrzakhan, and Zhiqiang Shen. Principled instructions are all you need for questioning llama-1/2, gpt-3.5/4. Technical Report 2312.16171, arXiv, jan 2024
-
[19]
arXiv preprint arXiv:2311.09277 , year=
Yew Ken Chia, Guizhen Chen, Luu Anh Tuan, Soujanya Poria, and Lidong Bing. Contrastive chain-of-thought prompting. Technical Report 2311.09277, arXiv, nov 2023
-
[20]
Cumulative Reasoning with Large Language Models
Yifan Zhang, Jingqin Yang, Yang Yuan, and Andrew Chi-Chih Yao. Cumulative reasoning with large language models. Technical Report 2308.04371, arXiv, may 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Code prompting elicits conditional reasoning abilities in Text+Code LLMs
Haritz Puerto, Martin Tutek, Somak Aditya, Xiaodan Zhu, and Iryna Gurevych. Code prompting elicits conditional reasoning abilities in Text+Code LLMs. InEmpirical Methods in Natural Language Processing, pages 11234–11258. ACL, 2024
2024
-
[22]
Bounding the capabilities of large language models in open text generation with prompt constraints
Albert Lu, Hongxin Zhang, Yanzhe Zhang, Xuezhi Wang, and Diyi Yang. Bounding the capabilities of large language models in open text generation with prompt constraints. InFindings of the Association for Computational Linguistics, EACL, pages 1982–2008. ACL, 2023. 24
1982
-
[23]
Chatlaw: A multi-agent legal assistant based on a role-aligned mixture-of-experts architecture
Jiaxi Cui, Munan Ning, Zongjian Li, Hao Li, Yang Ya, Bohua Chen, Bin Ling, Yonghong Tian, and Li Yuan. Chatlaw: A multi-agent legal assistant based on a role-aligned mixture-of-experts architecture. Fundamental Research, 2026
2026
-
[24]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, AndyJones, NelsonElhage, TristanHume, AnnaChen, YuntaoBai, SamBowman, StanislavFort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Rcot: Detecting and rectifying factual inconsistency in reasoning by reversing chain-of-thought
Tianci Xue, Ziqi Wang, Zhenhailong Wang, Chi Han, Pengfei Yu, and Heng Ji. Rcot: Detecting and rectifying factual inconsistency in reasoning by reversing chain-of-thought. Technical Report 2305.11499, arXiv, oct 2023. 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.