Joint Medical Image Enhancement and Segmentation with Diffusion-based Symbiotic Information Interaction
Pith reviewed 2026-07-02 20:05 UTC · model grok-4.3
The pith
A diffusion model with symbiotic feature exchange lets medical image enhancement and segmentation improve each other during denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
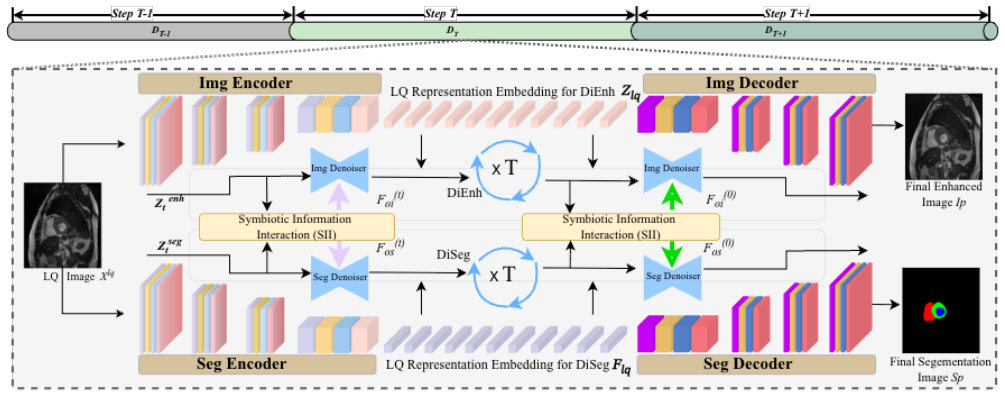
DiSIINet integrates an enhancement branch and a segmentation branch on a DDIM backbone; these branches interact through a Symbiotic Information Interaction module that performs dynamic feature-level exchange via cross-attention during the reverse diffusion process, so that the two tasks iteratively improve each other and yield better final outputs than sequential or independent pipelines.
What carries the argument
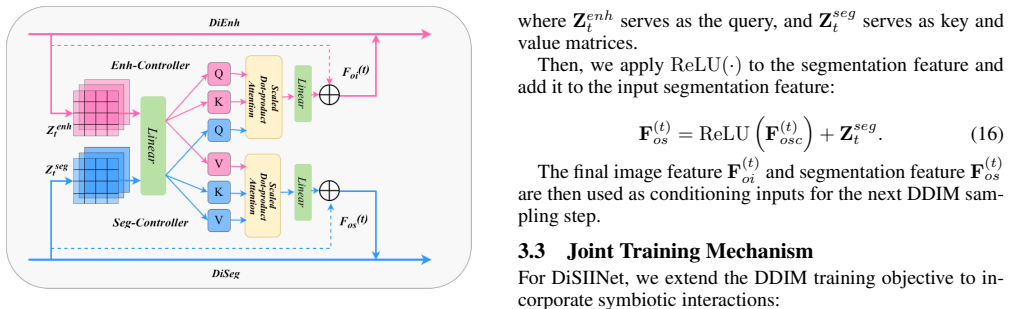
The Symbiotic Information Interaction (SII) module, which performs dynamic feature-level information exchange via cross-attention between the enhancement and segmentation branches during the reverse diffusion process.
If this is right
- Enhancement and segmentation tasks iteratively improve each other inside the shared diffusion process.
- Significant performance gains appear compared with sequential or independent enhancement-plus-segmentation pipelines.
- High-quality outputs are produced with efficient inference thanks to deterministic DDIM sampling.
- The joint model works across multi-modal datasets including MRI, CT, and ultrasound.
Where Pith is reading between the lines
- Lower-cost scanners might become sufficient for diagnostic use if the joint model compensates for their lower native quality.
- The same cross-task attention pattern could be tested on other paired medical imaging problems such as denoising paired with detection.
- Extending the interaction module to three or more tasks at once would be a direct next experiment.
Load-bearing premise
That the Symbiotic Information Interaction module enables effective dynamic feature-level information exchange via cross-attention during the reverse diffusion process such that the two tasks iteratively improve each other.
What would settle it
A controlled ablation on the same MRI, CT, and ultrasound test sets in which the SII module is removed and performance shows no measurable drop would falsify the claim that the symbiotic interaction is responsible for the gains.
Figures
read the original abstract
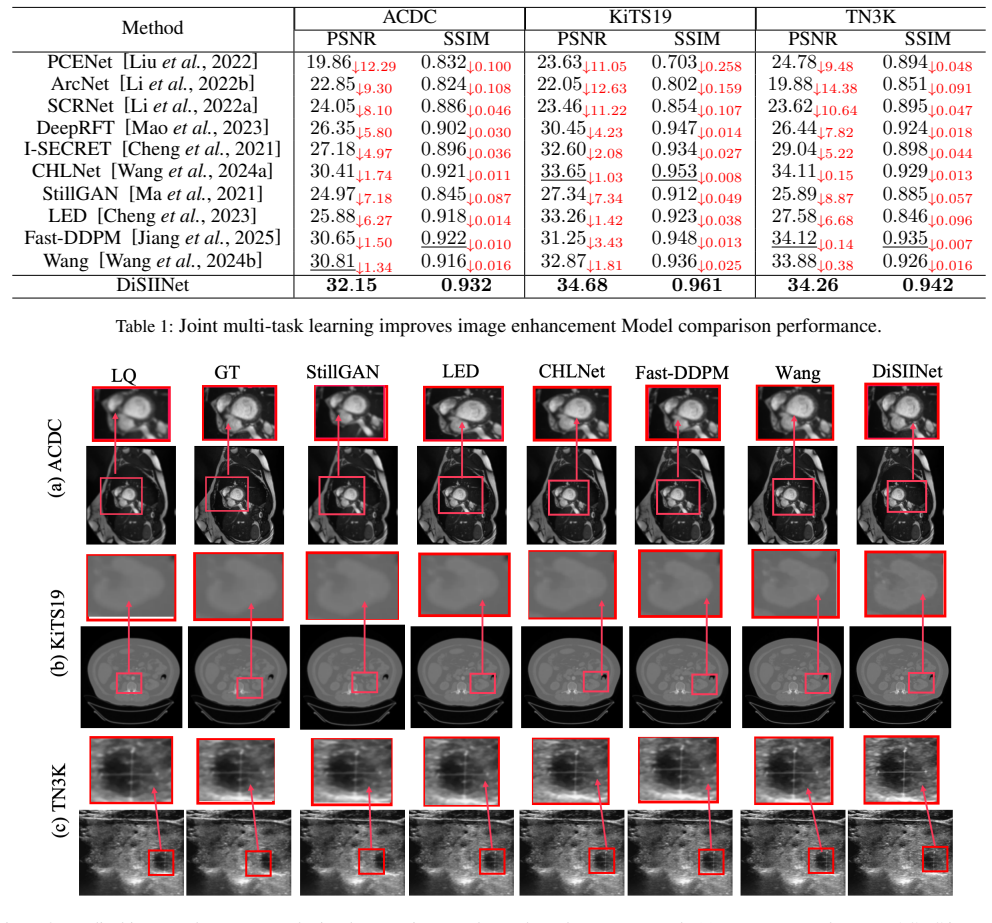
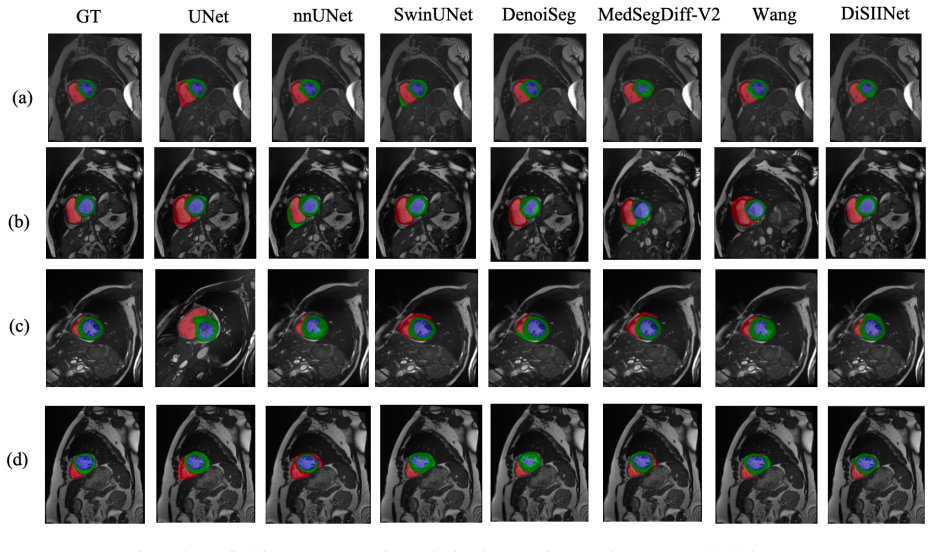
Image quality is critical for accurate medical diagnosis. However, MRI, CT, and ultrasound images are often of low resolution and quality due to cost constraints, complicating the visualization of key anatomical structures and lesions. While such limitations are common in practice, traditional methods treat image enhancement as a separate preprocessing step, failing to fully leverage its potential synergy with image segmentation. To address this, we propose DiSIINet (Diffusion-based Symbiotic Information Interaction Network), which is built on the principle that enhancement and segmentation should mutually reinforce each other in a unified model. Based on Denoising Diffusion Implicit Models (DDIM), DiSIINet integrates an enhancement branch and a segmentation branch. These branches interact through a novel Symbiotic Information Interaction (SII) module, which facilitates dynamic, feature-level information exchange via cross-attention during the reverse diffusion process. This design enables both tasks to iteratively improve each other. The DDIM backbone ensures high-quality output and efficient inference through deterministic sampling. Experiments on multi-modal medical datasets (MRI, CT, ultrasound) show that DiSIINet achieves significant performance improvements compared to sequential or independent enhancement and segmentation approaches. The code is available at: https://github.com/Reconsider80/DiSIINet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiSIINet, a diffusion-based symbiotic information interaction network for joint medical image enhancement and segmentation. It is built on DDIM and integrates an enhancement branch and a segmentation branch that interact through a Symbiotic Information Interaction (SII) module using cross-attention during the reverse diffusion process to enable iterative mutual improvement between the tasks. The authors claim that experiments on multi-modal medical datasets (MRI, CT, ultrasound) demonstrate significant performance improvements compared to sequential or independent enhancement and segmentation approaches.
Significance. If the empirical results hold, this approach could be significant for medical imaging applications by showing that joint modeling with symbiotic interaction can leverage synergies between enhancement and segmentation, leading to better performance than separate processing. The availability of code at the provided GitHub link supports potential reproducibility and adoption.
major comments (1)
- Abstract: The central claim of 'significant performance improvements' is asserted without any accompanying metrics, baseline comparisons, statistical tests, or specific dataset information. This makes it impossible to evaluate the strength of the evidence for the main contribution from the abstract alone.
minor comments (1)
- The title and abstract use 'Symbiotic Information Interaction' which is a novel term; ensure it is clearly defined in the introduction or method section.
Simulated Author's Rebuttal
We thank the referee for highlighting this issue with the abstract. We agree that the current version lacks sufficient quantitative support for the central claim and will revise accordingly.
read point-by-point responses
-
Referee: [—] Abstract: The central claim of 'significant performance improvements' is asserted without any accompanying metrics, baseline comparisons, statistical tests, or specific dataset information. This makes it impossible to evaluate the strength of the evidence for the main contribution from the abstract alone.
Authors: We agree that the abstract should provide concrete evidence to support the claim of significant improvements. The full manuscript contains detailed quantitative results (including metrics such as Dice coefficient, PSNR/SSIM, and comparisons against sequential and independent baselines on MRI, CT, and ultrasound datasets), but these were not summarized in the abstract due to length constraints. In the revised version, we will expand the abstract to include key performance numbers, specific dataset names, and baseline comparisons while preserving conciseness. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes DiSIINet as an architectural design combining DDIM with a novel SII cross-attention module for joint enhancement and segmentation. The central claim rests on empirical results across MRI/CT/ultrasound datasets showing gains over sequential baselines, with no equations, fitted parameters, or derivations presented that reduce the claimed improvements to self-referential definitions or self-citation chains. The SII module is introduced as a design choice enabling iterative improvement, not derived from prior self-cited uniqueness theorems or ansatzes. This is a standard empirical architecture paper whose performance claims are externally falsifiable via the released code and datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Bernardet al., 2018 ] Olivier Bernard, Alain Lalande, and Zotti. et al. Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: Is the problem solved?IEEE Transactions on Medical Imaging, 37(11):2514–2525,
2018
-
[2]
Denoiseg: joint denoising and segmentation
[Buchholzet al., 2020 ] Tim-Oliver Buchholz, Mangal Prakash, Deborah Schmidt, Alexander Krull, and Florian Jug. Denoiseg: joint denoising and segmentation. InEu- ropean Conference on Computer Vision, pages 324–337. Springer,
2020
-
[3]
Swin-unet: Unet-like pure transformer for medi- cal image segmentation
[Caoet al., 2022 ] Hu Cao, Yueyue Wang, Joy Chen, Dong- sheng Jiang, Xiaopeng Zhang, Qi Tian, and Manning Wang. Swin-unet: Unet-like pure transformer for medi- cal image segmentation. InECCVW. Springer,
2022
-
[4]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
[Chenet al., 2021 ] Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L Yuille, and Yuyin Zhou. Transunet: Transformers make strong encoders for medical image segmentation.arXiv preprint arXiv:2102.04306,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
I-secret: Importance- guided fundus image enhancement via semi-supervised contrastive constraining
[Chenget al., 2021 ] Pujin Cheng, Li Lin, Yijin Huang, Jun- yan Lyu, and Xiaoying Tang. I-secret: Importance- guided fundus image enhancement via semi-supervised contrastive constraining. InMedical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, P...
2021
-
[6]
[Chenget al., 2023 ] Puijin Cheng, Li Lin, Yijin Huang, Huaqing He, Wenhan Luo, and Xiaoying Tang. Learn- ing enhancement from degradation: A diffusion model for fundus image enhancement.arXiv preprint arXiv:2303.04603,
-
[7]
Corediff: Contextual error-modulated generalized diffusion model for low-dose ct denoising and generalization.IEEE Transactions on Medical Imaging, 43(2):745–759,
[Gaoet al., 2023 ] Qi Gao, Zilong Li, Junping Zhang, Yi Zhang, and Hongming Shan. Corediff: Contextual error-modulated generalized diffusion model for low-dose ct denoising and generalization.IEEE Transactions on Medical Imaging, 43(2):745–759,
2023
-
[8]
Multi-task learning for thyroid nodule segmentation with thyroid region prior
[Gonget al., 2021 ] Haifan Gong, Guanqi Chen, Ranran Wang, Xiang Xie, Mingzhi Mao, Yizhou Yu, Fei Chen, and Guanbin Li. Multi-task learning for thyroid nodule segmentation with thyroid region prior. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 257–261. IEEE,
2021
-
[9]
The state of the art in kidney and kidney tumor segmentation in contrast-enhanced ct imaging: Results of the kits19 challenge.Medical image analysis, 67:101821,
[Helleret al., 2021 ] Nicholas Heller, Fabian Isensee, Klaus H Maier-Hein, Xiaoshuai Hou, Chunmei Xie, Fengyi Li, Yang Nan, Guangrui Mu, Zhiyong Lin, Miofei Han, et al. The state of the art in kidney and kidney tumor segmentation in contrast-enhanced ct imaging: Results of the kits19 challenge.Medical image analysis, 67:101821,
2021
-
[10]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851,
[Hoet al., 2020 ] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851,
2020
-
[11]
nnu-net: a self-configuring method for deep learning- based biomedical image segmentation.Nature methods, 18(2):203–211,
[Isenseeet al., 2021 ] Fabian Isensee, Paul F Jaeger, Si- mon AA Kohl, Jens Petersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning- based biomedical image segmentation.Nature methods, 18(2):203–211,
2021
-
[12]
A comprehensive study on colorectal polyp segmentation with resunet++, condi- tional random field and test-time augmentation.IEEE Journal of Biomedical and Health Informatics,
[Jhaet al., 2021 ] Debesh Jha, Pia H Smedsrud, Dag Jo- hansen, Thomas De Lange, H ˚avard D Johansen, P ˚al Halvorsen, and Michael A Riegler. A comprehensive study on colorectal polyp segmentation with resunet++, condi- tional random field and test-time augmentation.IEEE Journal of Biomedical and Health Informatics,
2021
-
[13]
Fast-ddpm: Fast denoising diffusion probabilis- tic models for medical image-to-image generation.IEEE Journal of Biomedical and Health Informatics,
[Jianget al., 2025 ] Hongxu Jiang, Muhammad Imran, Teng Zhang, Yuyin Zhou, Muxuan Liang, Kuang Gong, and Wei Shao. Fast-ddpm: Fast denoising diffusion probabilis- tic models for medical image-to-image generation.IEEE Journal of Biomedical and Health Informatics,
2025
-
[14]
Jhaveri, and Thippa Reddy Gadekallu
[Liet al., 2025 ] Yinghua Li, Weiao Hao, Hao Zeng, Long- guang Wang, Jian Xu, Sidheswar Routray, Rutvij H. Jhaveri, and Thippa Reddy Gadekallu. Cross-scale tex- ture supplementation for reference-based medical image super-resolution.IEEE Journal of Biomedical and Health Informatics, pages 1–15,
2025
-
[15]
Ef- ficient and degradation-adaptive network for real-world image super-resolution
[Lianget al., 2022 ] Jie Liang, Hui Zeng, and Lei Zhang. Ef- ficient and degradation-adaptive network for real-world image super-resolution. InEuropean Conference on Com- puter Vision, pages 574–591. Springer,
2022
-
[16]
Diffbir: Toward blind image restoration with generative diffusion prior
[Linet al., 2024 ] Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diffbir: Toward blind image restoration with generative diffusion prior. InEuropean conference on computer vision, pages 430–448. Springer,
2024
-
[17]
When image denoising meets high-level vision tasks: A deep learning approach
[Liuet al., 2018 ] Ding Liu, Bihan Wen, Xianming Liu, Zhangyang Wang, and Thomas S Huang. When image denoising meets high-level vision tasks: A deep learning approach. InProceedings of the International Joint Con- ference on Artificial Intelligence, page 842–848,
2018
-
[18]
Degradation- invariant enhancement of fundus images via pyramid con- straint network
[Liuet al., 2022 ] Haofeng Liu, Heng Li, Huazhu Fu, Ruoxiu Xiao, Yunshu Gao, Yan Hu, and Jiang Liu. Degradation- invariant enhancement of fundus images via pyramid con- straint network. InInternational Conference on Med- ical Image Computing and Computer-Assisted Interven- tion, pages 507–516. Springer,
2022
-
[19]
Structure and illumination con- strained gan for medical image enhancement.IEEE Trans- actions on Medical Imaging, 40(12):3955–3967,
[Maet al., 2021 ] Yuhui Ma, Jiang Liu, Yonghuai Liu, Huazhu Fu, Yan Hu, Jun Cheng, Hong Qi, Yufei Wu, Jiong Zhang, and Yitian Zhao. Structure and illumination con- strained gan for medical image enhancement.IEEE Trans- actions on Medical Imaging, 40(12):3955–3967,
2021
-
[20]
Intriguing findings of frequency selection for image deblurring
[Maoet al., 2023 ] Xintian Mao, Yiming Liu, Fengze Liu, Qingli Li, Wei Shen, and Yan Wang. Intriguing findings of frequency selection for image deblurring. InProceed- ings of the AAAI Conference on Artificial Intelligence, vol- ume 37, pages 1905–1913,
2023
-
[21]
Improved denoising diffusion probabilis- tic models
[Nichol and Dhariwal, 2021] Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilis- tic models. InInternational Conference on Machine Learning (ICML), pages 8162–8171. PMLR,
2021
-
[22]
Content-aware local gan for photo-realistic super-resolution
[Parket al., 2023 ] JoonKyu Park, Sanghyun Son, and Ky- oung Mu Lee. Content-aware local gan for photo-realistic super-resolution. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 10585– 10594,
2023
-
[23]
High-resolution image synthesis with latent diffusion models
[Rombachet al., 2022 ] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695,
2022
-
[24]
U-net: Convolutional networks for biomedical image segmentation
[Ronnebergeret al., 2015 ] Olaf Ronneberger, Philipp Fis- cher, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI. Springer,
2015
-
[25]
Denoising diffusion implicit models
[Songet al., 2021 ] Jiaming Song, Chenlin Meng, and Ste- fano Ermon. Denoising diffusion implicit models. InInter- national Conference on Learning Representations (ICLR),
2021
-
[26]
Exploring clip for assessing the look and feel of images
[Wanget al., 2023 ] Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2555–2563,
2023
-
[27]
Ddm 2: Self-supervised diffusion mri denoising with generative diffusion models
[Xianget al., 2023 ] Tiange Xiang, Mahmut Yurt, Ali B Syed, Kawin Setsompop, and Akshay Chaudhari. Ddm 2: Self-supervised diffusion mri denoising with generative diffusion models. InThe Eleventh International Confer- ence on Learnin Representations.,
2023
-
[28]
[Xiaoet al., 2024 ] Jiahua Xiao, Jiawei Zhang, Dongqing Zou, Xiaodan Zhang, Jimmy Ren, and Xing Wei. Se- mantic segmentation prior for diffusion-based real-world super-resolution.arXiv preprint arXiv:2412.02960,
-
[29]
Synergy between semantic segmentation and image denoising via alternate boosting
[Xuet al., 2023 ] Shunxin Xu, Ke Sun, Dong Liu, Zhiwei Xiong, and Zheng-Jun Zha. Synergy between semantic segmentation and image denoising via alternate boosting. ACM Transactions on Multimedia Computing, Communi- cations and Applications, 19(2):1–23,
2023
-
[30]
Pixel-aware stable diffu- sion for realistic image super-resolution and personalized stylization
[Yanget al., 2024 ] Tao Yang, Rongyuan Wu, Peiran Ren, Xuansong Xie, and Lei Zhang. Pixel-aware stable diffu- sion for realistic image super-resolution and personalized stylization. InEuropean conference on computer vision, pages 74–91. Springer,
2024
-
[31]
Scaling vision transform- ers
[Zhaiet al., 2022 ] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transform- ers. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 12104–12113, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.