DriftScope: Measuring The Hidden Effects of Diffusion Model Adaptation
Pith reviewed 2026-07-02 19:23 UTC · model grok-4.3
The pith
Adapting pre-trained diffusion models damages semantically unrelated concepts that aggregate metrics cannot detect.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
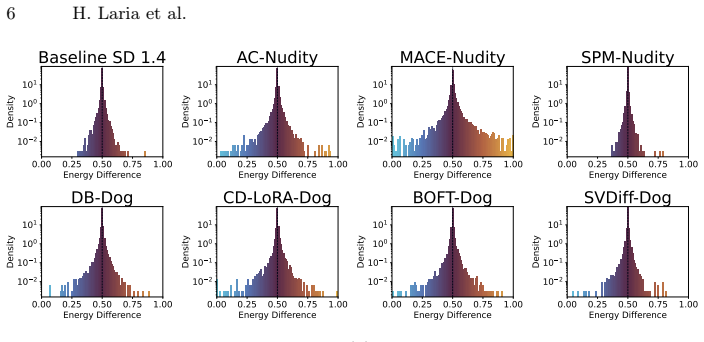
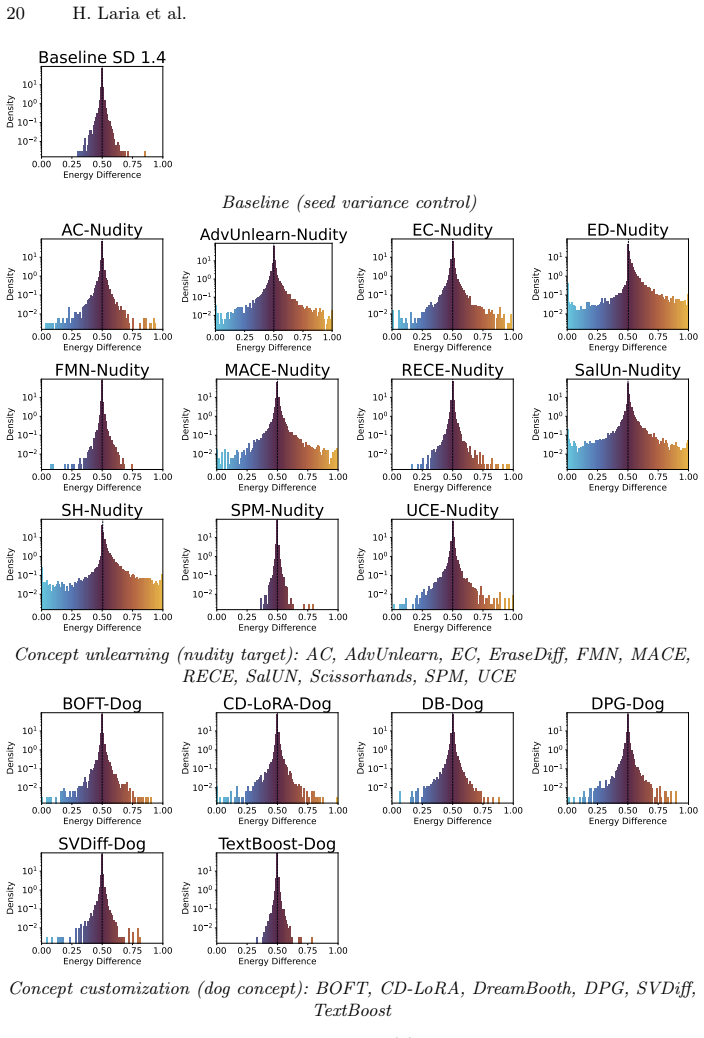
The central claim is that weight-level adaptation systematically damages semantically unrelated concepts in diffusion models, an effect invisible to aggregate metrics like FID and KID until the model is already broken, with specific classes showing worst-case zero-shot accuracy drops of up to 18.9 points; DriftScope is presented as a prompt-level tool to audit and rank these drifts at the token level without real data or model internals.
What carries the argument
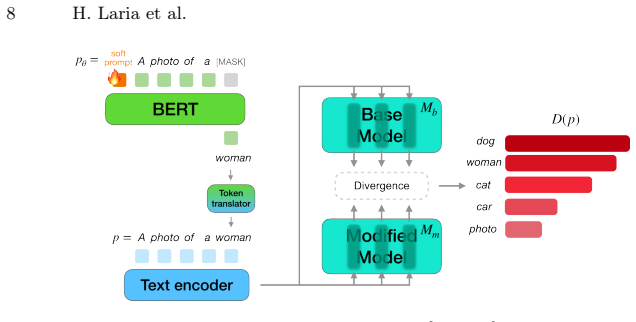
DriftScope, a prompt-level diagnostic tool that optimizes a soft prompt to attribute and rank drift at the token level between any two model checkpoints.
If this is right
- Adaptation can cause large drops in performance on unrelated classes even when aggregate quality metrics remain unchanged.
- Standard metrics like FID and KID are insufficient to guarantee that an adapted model has preserved its original capabilities.
- The observed damage pattern is consistent across different types of adaptation methods.
- Concept-level auditing is necessary to surface hidden effects before deploying adapted models.
Where Pith is reading between the lines
- Practitioners adapting models could routinely compare checkpoints with DriftScope to avoid releasing models with hidden defects on specific concepts.
- The findings suggest that weight modification in diffusion models has broad side effects that may require new regularization techniques during adaptation.
- Similar hidden drift could be present in other types of model fine-tuning beyond diffusion models.
- DriftScope might be extended to measure drift in non-visual concepts or across multiple adaptation steps.
Load-bearing premise
The combination of sparse autoencoder analysis and zero-shot classification accurately identifies true semantic damage to unrelated concepts caused by adaptation.
What would settle it
Running DriftScope on models adapted with different methods and verifying if the flagged concepts show corresponding drops in zero-shot classification accuracy while aggregate metrics do not.
Figures



read the original abstract
Adapting pre-trained text-to-image diffusion models, whether to learn new visual concepts or erase unwanted ones, is routinely evaluated on its intended effects alone. We argue this framing is incomplete. Through sparse autoencoder analysis and zero-shot classification, we demonstrate that adaptation systematically damages semantically unrelated concepts in ways that aggregate metrics structurally cannot surface: when damage is severe enough for FID and KID to respond, the model is already nearly unusable; when the model remains functional, FID and KID stay flat while specific classes silently suffer worst-case zero-shot accuracy drops of up to 18.9 points and concept-level distributions shift dramatically. This pattern appears at both ends of the adaptation spectrum (concept customization and concept unlearning), suggesting it is a systematic consequence of weight-level modification rather than an artifact of any particular method. To surface this hidden drift before deployment, we introduce DriftScope, a prompt-level diagnostic tool that takes any two model checkpoints and returns a ranked list of tokens whose visual concepts have shifted most between them. DriftScope optimizes a soft prompt to attribute drift at the token level without requiring access to real data or model internals. The result is an interpretable, concept-level audit that aggregate evaluation cannot provide.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adapting pre-trained text-to-image diffusion models for customization or unlearning systematically damages semantically unrelated concepts in ways missed by aggregate metrics like FID and KID. Using sparse autoencoder analysis and zero-shot classification, it reports worst-case accuracy drops of up to 18.9 points and concept-level distribution shifts; when damage is severe enough to affect FID/KID the model is already unusable, while functional models show flat aggregate scores. The pattern holds across both ends of the adaptation spectrum, which the authors interpret as evidence that the effect is inherent to weight-level modification. To detect this, the paper introduces DriftScope, a prompt-level diagnostic that ranks tokens by visual-concept drift between any two checkpoints without requiring real data or model internals.
Significance. If the empirical pattern and the diagnostic tool hold, the work identifies a structural limitation in current evaluation practices for diffusion-model adaptation and supplies a practical, interpretable audit method that operates at the token level. This could shift how practitioners assess safety and fidelity of customized or unlearned models before deployment.
major comments (1)
- [Abstract] Abstract: the claim that the observed drift 'is a systematic consequence of weight-level modification rather than an artifact of any particular method' rests on experiments with only two adaptation regimes (concept customization and concept unlearning). No controls are described that isolate the effect of the weight update itself from method-specific choices such as loss terms, learning-rate schedules, or prompt engineering; therefore the inference from the two observed cases to a general property of weight modification remains under-supported and load-bearing for the central thesis.
minor comments (1)
- The description of how DriftScope optimizes the soft prompt and attributes drift at the token level would benefit from an explicit algorithmic outline or pseudocode to clarify the optimization objective and stopping criteria.
Simulated Author's Rebuttal
We thank the referee for highlighting this important qualification on the scope of our central claim. We address the point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the observed drift 'is a systematic consequence of weight-level modification rather than an artifact of any particular method' rests on experiments with only two adaptation regimes (concept customization and concept unlearning). No controls are described that isolate the effect of the weight update itself from method-specific choices such as loss terms, learning-rate schedules, or prompt engineering; therefore the inference from the two observed cases to a general property of weight modification remains under-supported and load-bearing for the central thesis.
Authors: We agree that the generalization from two regimes to a property of weight-level modification in general is under-supported without additional isolating controls. The two regimes we studied (DreamBooth-style customization and negative-prompt unlearning) differ substantially in objective, loss formulation, learning-rate schedule, and prompt construction, yet produce qualitatively similar drift patterns; we view this as suggestive but not conclusive evidence. To address the concern, we will revise the abstract to replace the phrasing 'suggesting it is a systematic consequence of weight-level modification rather than an artifact of any particular method' with a more qualified statement that the pattern 'is observed across two distinct adaptation regimes and may indicate a broader effect of weight-level updates.' We will also add a dedicated limitations paragraph noting the absence of explicit controls that hold method-specific factors fixed and calling for future work with additional adaptation techniques. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's central claims rest on empirical observations from two adaptation regimes (customization and unlearning) plus a new diagnostic tool (DriftScope) that optimizes soft prompts for token-level drift attribution. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described methodology. The inference that observed drift is a general property of weight-level modification is an empirical generalization rather than a reduction to inputs by construction; the diagnostic is presented as independent of the adaptation process itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PromptHero.https://prompthero.com, accessed: 2026
2026
-
[2]
Nature Communications (2024)
Biroli, G., Bonnaire, T., de Bortoli, V., Mézard, M.: Dynamical regimes of diffusion models. Nature Communications (2024)
2024
-
[3]
arXiv preprint arXiv:2506.19708 (2025)
Bohacek, M., Fel, T., Agrawala, M., Lubana, E.S.: Uncovering conceptual blindspots in generative image models using sparse autoencoders. arXiv preprint arXiv:2506.19708 (2025)
-
[4]
In: European Conference on Computer Vision
Bossard, L., Guillaumin, M., Van Gool, L.: Food-101 – mining discriminative com- ponents with random forests. In: European Conference on Computer Vision. pp. 446–461. Springer (2014)
2014
-
[5]
pub/2024/model-diffing/index.html(2024), anthropic Interpretability Team
Bricken, T., et al.: Stage-wise model diffing.https://transformer- circuits. pub/2024/model-diffing/index.html(2024), anthropic Interpretability Team
2024
-
[6]
Advances in neural information processing systems (2025)
Carnemolla, S., Pennisi, M., Samarasinghe, S., Bellitto, G., Palazzo, S., Giordano, D., Shah, M., Spampinato, C.: Dexter: Diffusion-guided explanations with textual reasoning for vision models. Advances in neural information processing systems (2025)
2025
-
[7]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin,J.,Chang,M.W.,Lee,K.,Toutanova,K.:Bert:Pre-trainingofdeepbidirec- tional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Dunlap, L., Gonzalez, J.E., Darrell, T., Heilbron, F.C., Sivic, J., Russell, B.: Dis- covering divergent representations between text-to-image models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17516–17525 (2025)
2025
-
[9]
In: International Conference on Learning Representations (ICLR) (2023)
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image generation using textual inversion. In: International Conference on Learning Representations (ICLR) (2023)
2023
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., Bau, D.: Erasing concepts from diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2426–2436 (2023)
2023
-
[11]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Han, L., Li, Y., Zhang, H., Milanfar, P., Metaxas, D., Yang, F.: Svdiff: Compact parameter space for diffusion fine-tuning. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 7323–7334 (2023)
2023
-
[12]
In: European Con- ference on Computer Vision
He, J., Wang, Z., Wang, L., Liu, T.I., Fang, Y., Sun, Q., Ma, K.: Multiscale sliced Wasserstein distances as perceptual color difference measures. In: European Con- ference on Computer Vision. pp. 1–18 (2024),http://arxiv.org/abs/2407.10181
-
[13]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[14]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Kaushik, A.R., Devulapally, N.K., Lokhande, V.S., Ratha, N., Govindaraju, V.: Forget less by learning together through concept consolidation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 265–275 (2026)
2026
-
[15]
Krizhevsky, A.: Learning multiple layers of features from tiny images. Tech. rep., University of Toronto (2009)
2009
-
[16]
CVPR (2023)
Kumari, N., Zhang, B., Zhang, R., Shechtman, E., Zhu, J.Y.: Multi-concept cus- tomization of text-to-image diffusion. CVPR (2023)
2023
-
[17]
arXiv preprint arXiv:2410.14159 (2024) DriftScope 17
Laria, H., Gomez-Villa, A., Wang, K., Raducanu, B., van de Weijer, J.: Assessing open-world forgetting in generative image model customization. arXiv preprint arXiv:2410.14159 (2024) DriftScope 17
-
[18]
Lindsey, J., et al.: Crosscoders: A sparse autoencoder architecture for comparing model representations.https://transformer-circuits.pub/2024/crosscoders/ index.html(2025), anthropic Interpretability Team
2024
-
[19]
In: The Twelfth International Conferenceon LearningRepresentations(2024),https://openreview.net/forum? id=TOWdQQgMJY
Liu, Q., Kortylewski, A., Bai, Y., Bai, S., Yuille, A.: Discovering failure modes of text-guided diffusion models via adversarial search. In: The Twelfth International Conferenceon LearningRepresentations(2024),https://openreview.net/forum? id=TOWdQQgMJY
2024
-
[20]
In: ICLR (2024)
Liu, W., Qiu, Z., Feng, Y., Xiu, Y., Xue, Y., Yu, L., Feng, H., Liu, Z., Heo, J., Peng, S., Wen, Y., Black, M.J., Weller, A., Schölkopf, B.: Parameter-efficient orthogonal finetuning via butterfly factorization. In: ICLR (2024)
2024
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lu, S., Wang, Z., Li, L., Liu, Y., Kong, A.W.K.: Mace: Mass concept erasure in diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6430–6440 (2024)
2024
-
[22]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Lyu, M., Yang, Y., Hong, H., Chen, H., Jin, X., He, Y., Xue, H., Han, J., Ding, G.: One-dimensional adapter to rule them all: Concepts, diffusion models and erasing applications. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2023
-
[23]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(5), 5513–5533 (2022)
Masana, M., Liu, X., Twardowski, B., Menta, M., Bagdanov, A.D., Van De Weijer, J.: Class-incremental learning: survey and performance evaluation on image classi- fication. IEEE Transactions on Pattern Analysis and Machine Intelligence45(5), 5513–5533 (2022)
2022
-
[24]
In: 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing
Nilsback, M.E., Zisserman, A.: Automated flower classification over a large number of classes. In: 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing. pp. 722–729. IEEE (2008)
2008
-
[25]
arXiv preprint arXiv:2412.12594 (2024)
Qi, Z., Liu, B., Zhang, S., Li, B., Xu, Z., Xiong, H., Xie, Z.: A simple and efficient baseline for zero-shot generative classification. arXiv preprint arXiv:2412.12594 (2024)
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[27]
In: Proceedings of the 2020 conference on empirical methods in natural language pro- cessing (EMNLP)
Shin, T., Razeghi, Y., Logan IV, R.L., Wallace, E., Singh, S.: Autoprompt: Elic- iting knowledge from language models with automatically generated prompts. In: Proceedings of the 2020 conference on empirical methods in natural language pro- cessing (EMNLP). pp. 4222–4235 (2020)
2020
-
[28]
Transac- tions on Machine Learning Research (2024)
Smith, J.S., Hsu, Y.C., Zhang, L., Hua, T., Kira, Z., Shen, Y., Jin, H.: Continual diffusion: Continual customization of text-to-image diffusion with c-lora. Transac- tions on Machine Learning Research (2024)
2024
-
[29]
In: ICML
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: ICML. pp. 2256–2265. PMLR (2015)
2015
-
[30]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[31]
Advances in neural information processing systems 36, 29292–29322 (2023)
Tong, S., Jones, E., Steinhardt, J.: Mass-producing failures of multimodal sys- tems with language models. Advances in neural information processing systems 36, 29292–29322 (2023)
2023
-
[32]
Laria et al
Tsai, Y.L., Hsu, C.Y., Xie, C., Lin, C.H., Chen, J.Y., Li, B., Chen, P.Y., Yu, C.M., Huang, C.Y.: Ring-a-bell! how reliable are concept removal methods for diffusion models? In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=lm7MRcsFiS 18 H. Laria et al
2024
-
[33]
In: European Conference on Computer Vision
Wu, J., Harandi, M.: Scissorhands: Scrub data influence via connection sensitivity in networks. In: European Conference on Computer Vision. pp. 367–384. Springer (2024)
2024
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence
Wu, J., Le, T., Hayat, M., Harandi, M.: Erasing undesirable influence in diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence. pp. 28263–28273 (2025)
2025
-
[35]
ArXivabs/2303.15342 (2023),https://api.semanticscholar.org/CorpusID:257766772
Zajac, M., Deja, K., Kuzina, A., Tomczak, J.M., Trzcinski, T., Shkurti, F., Milo’s, P.: Exploring continual learning of diffusion models. ArXivabs/2303.15342 (2023),https://api.semanticscholar.org/CorpusID:257766772
-
[36]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, Z., Kou, T., Wang, S., Li, C., Sun, W., Wang, W., Li, X., Wang, Z., Cao, X., Min, X., et al.: Q-eval-100k: Evaluating visual quality and alignment level for text-to-vision content. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10621–10631 (2025) DriftScope 19 A Full SAE Drift Score Distributions Figure 5...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.