Personalization as Inverse Planning: Learning Latent Design Intents for Agentic Slide Generation via Structural Denoising
Pith reviewed 2026-07-02 13:08 UTC · model grok-4.3
The pith
Page-level slide personalization reduces to recovering latent design intents by treating it as inverse planning solved through structural denoising with multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
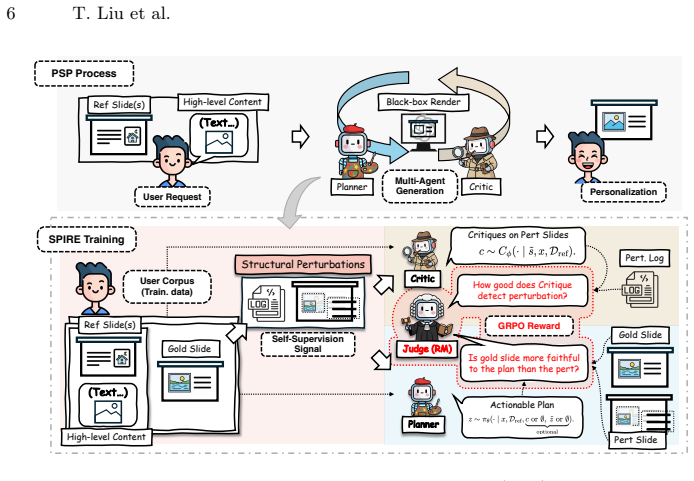
We formulate PSP as an inverse planning problem and propose SPIRE to solve it approximately by intentionally corrupting visual structures of clean slides, creating a verifiable denoising task solved by two collaborative agents via RL; structural denoising is a consistent surrogate for PSP, and the multi-agent formulation strictly reduces policy gradient variance.
What carries the argument
Structural denoising created by corrupting slide visuals, solved collaboratively by two agents in RL to recover latent design intents.
If this is right
- Latent design intents for themes and layouts can be learned end-to-end without specifying or controlling the execution tools.
- The multi-agent RL formulation provides strictly lower policy gradient variance than single-agent alternatives.
- SPIRE approximates the intractable PSP problem while remaining verifiable through the denoising objective.
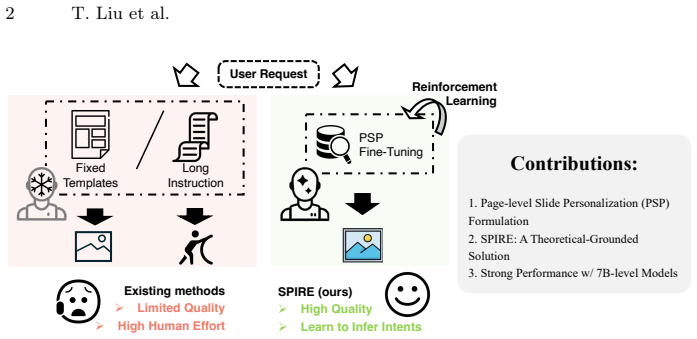
- Experiments confirm superiority over prior template-based or instruction-based agent methods for page-level personalization.
Where Pith is reading between the lines
- The same corruption-and-denoise pattern could extend to other agentic creative tasks where execution environments are unknown in advance.
- Verification through structural consistency might reduce reliance on explicit user feedback loops in personalization systems.
- If the learned intents prove transferable, the method could support cross-tool slide generation without retraining per software.
Load-bearing premise
Intentionally corrupting the visual structures of clean slides creates a verifiable denoising task whose solution corresponds to recovering latent design intents without knowledge of the executing tools.
What would settle it
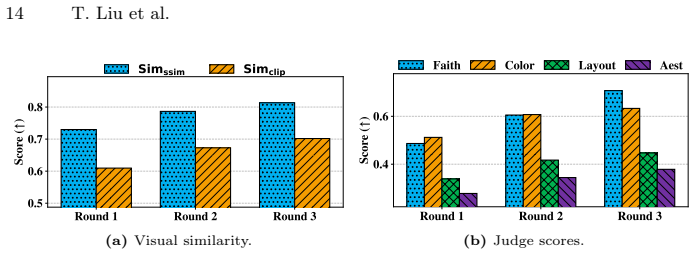
A test set of slides with known ground-truth intents where the agents' denoised outputs fail to match the original designs would falsify the consistency of the surrogate.
Figures



read the original abstract
Slide design requires personalizing both deck themes and page layouts. Yet, current AI agent-based methods struggle with fine-grained, page-level design. Solely relying on prespecified templates or user verbose instructions, they fail to capture latent design intents, leaving Page-level Slide Personalization (PSP) unresolved. To close this gap, this work formulates PSP as an inverse planning problem. We propose to learn a design intent without assuming any knowledge of the specific executing tools (e.g., PowerPoint, Beamer) being used. However, relinquishing control over these tools makes the problem intractable to optimize end-to-end. To overcome this, we propose SPIRE, a principled framework to solve PSP approximately. By intentionally corrupting the visual structures of clean slides, SPIRE creates a verifiable task to denoise the corruption, whereby two agents learn to collaboratively refine executable designs via reinforcement learning (RL). We present a proof that structural denoising is a consistent surrogate for PSP, and that the multi-agent formulation strictly reduces policy gradient variance in RL. Extensive experiments demonstrate the superiority of SPIRE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates Page-level Slide Personalization (PSP) as an inverse planning problem and introduces the SPIRE framework. SPIRE intentionally corrupts visual structures of clean slides to create a denoising task solved collaboratively by two agents via reinforcement learning, without assuming knowledge of executing tools such as PowerPoint. It asserts a proof that structural denoising is a consistent surrogate for PSP and that the multi-agent RL formulation strictly reduces policy gradient variance, with experiments claimed to demonstrate superiority over prior methods.
Significance. If the consistency proof and variance-reduction result hold with verifiable derivations, and if experiments confirm recovery of latent intents, the work could offer a tool-agnostic approach to agentic design personalization that addresses limitations of template-based or instruction-heavy methods. The multi-agent RL variance claim, if rigorously established, would also be of independent interest in RL.
major comments (2)
- [Abstract] Abstract: The central claim rests on the assertion that 'We present a proof that structural denoising is a consistent surrogate for PSP', yet the manuscript supplies no derivation steps, equations, or intermediate results showing that the optimal policy under the denoising objective recovers the original latent design intents (rather than any of the other structures that could satisfy the corruption loss). Without this, the many-to-one mapping concern cannot be ruled out.
- [Abstract] Abstract: The claim that 'the multi-agent formulation strictly reduces policy gradient variance in RL' is load-bearing for the proposed solution but is stated without the underlying RL formulation, the single-agent baseline comparison, or the variance-reduction derivation. This prevents assessment of whether the reduction is strict and holds under the inverse-planning objective.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the experimental metrics and baselines used to claim superiority, to allow readers to gauge the strength of the empirical support.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need for explicit derivations of our central theoretical claims. We agree that the consistency proof and variance-reduction result require fuller presentation to allow verification. Below we respond to each major comment and commit to revisions that will include the requested steps, equations, and comparisons without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim rests on the assertion that 'We present a proof that structural denoising is a consistent surrogate for PSP', yet the manuscript supplies no derivation steps, equations, or intermediate results showing that the optimal policy under the denoising objective recovers the original latent design intents (rather than any of the other structures that could satisfy the corruption loss). Without this, the many-to-one mapping concern cannot be ruled out.
Authors: We accept that the abstract states the existence of the proof without supplying its steps. The full manuscript contains a consistency argument in the theoretical analysis section, but it is presented at a high level. In the revision we will add a dedicated subsection that spells out the full derivation: starting from the inverse-planning objective, showing the equivalence between recovering latent intents and minimizing the expected corruption loss, and proving that the optimal denoising policy is unique (under the structural assumptions of the slide representation) rather than admitting arbitrary many-to-one solutions. This will directly address the many-to-one mapping concern. revision: yes
-
Referee: [Abstract] Abstract: The claim that 'the multi-agent formulation strictly reduces policy gradient variance in RL' is load-bearing for the proposed solution but is stated without the underlying RL formulation, the single-agent baseline comparison, or the variance-reduction derivation. This prevents assessment of whether the reduction is strict and holds under the inverse-planning objective.
Authors: We agree that the variance-reduction claim needs the supporting RL formulation and derivation to be verifiable. The manuscript defines the collaborative two-agent policy gradient in Section 4, but the explicit single-agent baseline and the variance expressions are only sketched. In the revision we will expand this section to include: (i) the precise single-agent and multi-agent policy-gradient estimators, (ii) the variance formulas for each, and (iii) the algebraic steps establishing that the multi-agent formulation yields a strictly lower variance under the same inverse-planning objective. A direct comparison table will also be added. revision: yes
Circularity Check
No circularity detected from available text
full rationale
The abstract asserts a proof that structural denoising is a consistent surrogate for PSP and that multi-agent RL reduces policy gradient variance, but supplies no equations, derivations, self-citations, or load-bearing steps that can be inspected for reduction to inputs by construction. No self-definitional mappings, fitted inputs renamed as predictions, or uniqueness theorems imported from prior author work are present. The derivation chain cannot be walked beyond the high-level claim, so no circular steps are identifiable; the result is treated as self-contained pending full text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Liu et al
Anthropic: Claude sonnet 4: Hybrid reasoning model with superior intelligence for high-volume use cases, and 200k context window.https://www.anthropic.com/ claude/sonnet(2025) 16 T. Liu et al
2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025)
2025
-
[3]
In: Proceedings of The 5th New Frontiers in Summarization Workshop
Cao, J., Zhang, X., Li, R., Wei, J., Li, C., Joty, S., Carenini, G.: Multi2: Multi- agent test-time scalable framework for multi-document processing. In: Proceedings of The 5th New Frontiers in Summarization Workshop. pp. 135–156 (2025)
2025
-
[4]
arXiv preprint arXiv:2306.03082 (2023)
Chen, L., Chen, J., Goldstein, T., Huang, H., Zhou, T.: Instructzero: Efficient instruction optimization for black-box large language models. arXiv preprint arXiv:2306.03082 (2023)
-
[5]
In: Findings of the Association for Computational Linguistics: ACL 2023
Chen, Z., Liu, G., Zhang, B.W., Yang, Q., Wu, L.: Altclip: Altering the language encoder in clip for extended language capabilities. In: Findings of the Association for Computational Linguistics: ACL 2023. pp. 8666–8682 (2023)
2023
-
[6]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
A Survey on Code Generation with LLM-based Agents
Dong, Y., Jiang, X., Qian, J., Wang, T., Zhang, K., Jin, Z., Li, G.: A survey on code generation with llm-based agents. arXiv preprint arXiv:2508.00083 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[9]
In: Proceedings of the AAAI Confer- ence on Artificial Intelligence
Fu, T.J., Wang, W.Y., McDuff, D., Song, Y.: Doc2ppt: Automatic presentation slides generation from scientific documents. In: Proceedings of the AAAI Confer- ence on Artificial Intelligence. vol. 36, pp. 634–642 (2022)
2022
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ge, J., Wang, Z.Z., Zhou, X., Peng, Y.H., Subramanian, S., Tan, Q., Sap, M., Suhr, A., Fried, D., Neubig, G., et al.: Autopresent: Designing structured visuals from scratch. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2902–2911 (2025)
2025
-
[11]
arXiv preprint arXiv:2412.06771 (2024)
Hahn, M., Zeng, W., Kannen, N., Galt, R., Badola, K., Kim, B., Wang, Z.: Proactive agents for multi-turn text-to-image generation under uncertainty. arXiv preprint arXiv:2412.06771 (2024)
-
[12]
Advances in Neural Information Processing Systems37, 86309–86345 (2024)
Hu, W., Shu, Y., Yu, Z., Wu, Z., Lin, X., Dai, Z., Ng, S.K., Low, B.K.H.: Local- ized zeroth-order prompt optimization. Advances in Neural Information Processing Systems37, 86309–86345 (2024)
2024
-
[13]
In: IJCAI
Hu, Y., Wan, X.: Ppsgen: Learning to generate presentation slides for academic papers. In: IJCAI. pp. 2099–2105 (2013)
2099
-
[14]
arXiv preprint arXiv:2601.15286 (2026)
Jaiswal, S., Prabhudesai, M., Bhardwaj, N., Qin, Z., Zadeh, A., Li, C., Fragki- adaki, K., Pathak, D.: Iterative refinement improves compositional image genera- tion. arXiv preprint arXiv:2601.15286 (2026)
-
[15]
DECKBench: Benchmarking Multi-Agent Frameworks for Academic Slide Generation and Editing
Jang, D., Heisler, M.L., Xing, L., Li, Y., Wang, E., Xiong, Y., Zhang, Y., Fan, Z.: Deckbench: Benchmarking multi-agent frameworks for academic slide generation and editing. arXiv preprint arXiv:2602.13318 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Talk to Your Slides: High-Efficiency Slide Editing via Language-Driven Structured Data Manipulation
Jung, K., Cho, H., Yun, J., Yang, S., Jang, J., Choo, J.: Talk to your slides: Language-driven agents for efficient slide editing. arXiv preprint arXiv:2505.11604 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Lan, G.: First-order and stochastic optimization methods for machine learning, vol. 1. Springer (2020) 17
2020
-
[18]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Li, C., Xue, M., Zhang, Z., Yang, J., Zhang, B., Yu, B., Hui, B., Lin, J., Wang, X., Liu, D.: Start: Self-taught reasoner with tools. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 13523– 13564 (2025)
2025
-
[19]
arXiv preprint arXiv:2502.11560 (2025)
Li, W., Wang, X., Li, W., Jin, B.: A survey of automatic prompt engineering: An optimization perspective. arXiv preprint arXiv:2502.11560 (2025)
-
[20]
arXiv preprint arXiv:2512.04529 (2025)
Liang, X., Zhang, X., Xu, Y., Sun, S., You, C.: Slidegen: Collaborative multimodal agents for scientific slide generation. arXiv preprint arXiv:2512.04529 (2025)
-
[21]
arXiv preprint arXiv:2510.05571 (2025)
Liu, C., Yang, Y., Zhou, K., Zhang, Z., Fan, Y., Xie, Y., Qi, P., Wang, X.E.: Presenting a paper is an art: Self-improvement aesthetic agents for academic pre- sentations. arXiv preprint arXiv:2510.05571 (2025)
-
[22]
In: ACM SIGGRAPH 2024 Conference Papers
Ma, J., Liang, J., Chen, C., Lu, H.: Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–12 (2024)
2024
-
[23]
arXiv preprint arXiv:2508.06916 (2025)
Ma, S., Guo, Y., Su, J., Huang, Q., Zhou, Z., Wang, Y.: Talk2image: A multi-agent system for multi-turn image generation and editing. arXiv preprint arXiv:2508.06916 (2025)
-
[24]
arXiv preprint arXiv:2405.13095 (2024)
Maheshwari, H., Bandyopadhyay, S., Garimella, A., Natarajan, A.: Presentations are not always linear! gnn meets llm for document-to-presentation transformation with attribution. arXiv preprint arXiv:2405.13095 (2024)
-
[25]
Advances in Neural Information Processing Systems36, 53038–53075 (2023)
Malladi, S., Gao, T., Nichani, E., Damian, A., Lee, J.D., Chen, D., Arora, S.: Fine- tuning language models with just forward passes. Advances in Neural Information Processing Systems36, 53038–53075 (2023)
2023
-
[26]
In: Proceedings of the 18th Con- ference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)
Mondal, I., Shwetha, S., Natarajan, A., Garimella, A., Bandyopadhyay, S., Boyd- Graber, J.: Presentations by the humans and for the humans: Harnessing llms for generating persona-aware slides from documents. In: Proceedings of the 18th Con- ference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2664–2...
2024
-
[27]
OpenAI: Introducing chatgpt (2022),https://openai.com/blog/chatgpt
2022
-
[28]
OpenAI: Gpt-image-1.https://platform.openai.com/docs/models/gpt-image- 1(2025)
2025
-
[29]
OpenAI: Introducing gpt-5.https://openai.com/index/introducing- gpt- 5/ (2025)
2025
-
[30]
arXiv preprint arXiv:2505.21497 (2025)
Pang, W., Lin, K.Q., Jian, X., He, X., Torr, P.: Paper2poster: Towards multimodal poster automation from scientific papers. arXiv preprint arXiv:2505.21497 (2025)
-
[31]
arXiv preprint arXiv:2504.06838 (2025)
Park, S., Jeong, J., Kim, Y., Lee, J., Lee, N.: Zip: An efficient zeroth-order prompt tuning for black-box vision-language models. arXiv preprint arXiv:2504.06838 (2025)
-
[32]
In: Findings of the Association for Computational Linguistics: EMNLP 2025
Qi, Y., Tian, J., Liu, T., Li, R., Wei, T., Liu, H., Tang, X., Cheng, M., He, J.: Learning to instruct: Fine-tuning a task-aware instruction optimizer for black-box llms. In: Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 7707–7733 (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qu, Y., Fang, S., Wang, Y., Wang, X., Chen, Z., Xie, H., Zhang, Y.: Igd: In- structional graphic design with multimodal layer generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18218–18228 (2025)
2025
-
[34]
Interna- tional journal of surgical pathology14(4), 285–305 (2006)
Rojo, M.G., García, G.B., Mateos, C.P., García, J.G., Vicente, M.C.: Critical com- parison of 31 commercially available digital slide systems in pathology. Interna- tional journal of surgical pathology14(4), 285–305 (2006)
2006
-
[35]
An overview of gradient descent optimization algorithms
Ruder, S.: An overview of gradient descent optimization algorithms. arXiv preprint arXiv:1609.04747 (2016) 18 T. Liu et al
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., Wu, C.: Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Sun, E., Hou, Y., Wang, D., Zhang, Y., Wang, N.X.: D2s: Document-to-slide gener- ation via query-based text summarization. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 1405–1418 (2021)
2021
-
[39]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Tang, W., Xiao, J., Jiang, W., Xiao, X., Wang, Y., Tang, X., Li, Q., Ma, Y., Liu, J., Tang,S.,etal.:Slidecoder:Layout-awarerag-enhancedhierarchicalslidegeneration from design. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 9026–9050 (2025)
2025
-
[40]
Anatomical sciences ed- ucation9(6), 583–602 (2016)
Trelease, R.B.: From chalkboard, slides, and to e-learning: How computing tech- nologies have transformed anatomical sciences education. Anatomical sciences ed- ucation9(6), 583–602 (2016)
2016
-
[41]
arXiv preprint arXiv:2504.05306 (2025)
Venkatesh, K., Dunlop, C., Yanardag, P.: Crea: A collaborative multi-agent frame- work for creative image editing and generation. arXiv preprint arXiv:2504.05306 (2025)
- [42]
-
[43]
arXiv preprint arXiv:2602.01511 , year=
Xu, R., Liu, T., Dong, Z., You, T., Hong, I., Yang, C., Zhang, L., Zhao, T., Wang, H.: Alternating reinforcement learning for rubric-based reward modeling in non- verifiable llm post-training. arXiv preprint arXiv:2602.01511 (2026)
-
[44]
arXiv preprint arXiv:2505.21660 (2025)
Xu, X., Xu, X., Chen, S., Chen, H., Zhang, F., Chen, Y.C.: Pregenie: An agen- tic framework for high-quality visual presentation generation. arXiv preprint arXiv:2505.21660 (2025)
-
[45]
arXiv preprint arXiv:2502.15412 (2025)
Xu, Y., Ma, X., Qiu, J., Zhao, H.: Textual-to-visual iterative self-verification for slide generation. arXiv preprint arXiv:2502.15412 (2025)
-
[46]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al.: Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Zelikman, E., Harik, G., Shao, Y., Jayasiri, V., Haber, N., Goodman, N.D.: Quiet- star: Language models can teach themselves to think before speaking. arXiv preprint arXiv:2403.09629 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Advances in Neural Information Processing Systems35, 15476–15488 (2022)
Zelikman, E., Wu, Y., Mu, J., Goodman, N.: Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems35, 15476–15488 (2022)
2022
-
[50]
arXiv preprint arXiv:2512.20292 (2025)
Zeng, W., Ouyang, M., Cui, L., Ng, H.T.: Slidetailor: Personalized presentation slide generation for scientific papers. arXiv preprint arXiv:2512.20292 (2025)
-
[51]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Zhan, H., Chen, C., Ding, T., Li, Z., Sun, R.: Unlocking black-box prompt tun- ing efficiency via zeroth-order optimization. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 14825–14838 (2024)
2024
-
[52]
In: 19 Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Zhang, K., Li, J., Li, G., Shi, X., Jin, Z.: Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. In: 19 Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13643–13658 (2024)
2024
-
[53]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Zheng, H., Guan, X., Kong, H., Zhang, W., Zheng, J., Zhou, W., Lin, H., Lu, Y., Han, X., Sun, L.: Pptagent: Generating and evaluating presentations beyond text- to-slides. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 14413–14429 (2025)
2025
-
[54]
With more and more customers opting out of cookies, the amount of data for wisdom of crowd declines
Zhu, D., Meng, R., Song, Y., Wei, X., Li, S., Pfister, T., Yoon, J.: Paperbanana: Automating academic illustration for ai scientists. arXiv preprint arXiv:2601.23265 (2026) Supplementary Material of Personalization as Inverse Planning: Learning Latent Design Intents for Agentic Slide Generation via Structural Denoising Tianci Liu1,∗, Zihan Dong2, Linjun Z...
-
[55]
Title Suppressed Due to Excessive Length 33
GRAPHIC_COLOR: palette + color roles. Title Suppressed Due to Excessive Length 33
-
[56]
GRAPHIC_POSITION: alignment + margins + spacing rhythm
-
[57]
GRAPHIC_SIZE: relative visual weight + hierarchy
-
[58]
IMAGE_POSITION: anchoring + alignment + proximity to related text
-
[59]
IMAGE_SIZE: prominence + proportions + image-to-text balance
-
[60]
TEXT_COLOR: contrast + emphasis conventions
-
[61]
TEXT_POSITION: grid/columns + padding + wrap region
-
[62]
</think> ## STEP 3: FEEDBACK CHECKLIST Output a SINGLE <comment> block containing the feedback for ALL 8 aspects
TEXT_SIZE: typographic hierarchy + consistency. </think> ## STEP 3: FEEDBACK CHECKLIST Output a SINGLE <comment> block containing the feedback for ALL 8 aspects. Ensure every aspect from Step 2 is included in the list inside the block: <comment> <aspect>GRAPHIC_COLOR</aspect>: <current>...</current><target>...</target> ... <aspect>TEXT_SIZE</aspect>: <cur...
-
[63]
For position/size revisions, give concrete ratios/ percentages and specify the frame (of panel/of slide)
Use proportions only (no px/pt). For position/size revisions, give concrete ratios/ percentages and specify the frame (of panel/of slide). Prefer bbox x:.. y:.. w:.. h:.. when precision is needed; otherwise provide at least one clear numeric target (e.g., target margin/height/width) plus an alignment rule
-
[64]
Always output ALL 8 aspects, in the exact order above
-
[65]
Otherwise provide a specific revision to improve consistency
If acceptable, use <target>GOOD</target>. Otherwise provide a specific revision to improve consistency
-
[66]
Be concise: <current> and <target> should each be 1 short sentence
-
[67]
move a bit
Avoid vague revisions (e.g., "move a bit", "make bigger"). Always include at least one numeric target. User Prompt for Critique Generation (Spire) Evaluate the **Generated Slide** using the **Slide Request** below. Note: The request may include: (1) media image(s) to place in the slide, and (2) style reference slide(s) used as a STYLE GUIDE. Critique visu...
-
[68]
GRAPHIC_COLOR: [palette/contrast]
-
[69]
GRAPHIC_POSITION: [proportions with frames]
-
[70]
GRAPHIC_SIZE: [ratios]
-
[71]
IMAGE_POSITION: [zones]
-
[72]
IMAGE_SIZE: [ratios]
-
[73]
TEXT_COLOR: [contrast/emphasis]
-
[74]
TEXT_POSITION: [divisions]
-
[75]
Use simple language that a 10-year-old child can understand
TEXT_SIZE: [hierarchy ratios; **legibility floor: all font sizes >= 10% of container height**] </think> ## STEP 3: COMPLETE DESIGN PLAN <plan> Write one paragraph in this order to state the complete design plan: background -> containers (e.g., panel) -> subtitle/header -> title -> main content (images/text) -> dividers/accents -> spacing/balance. Use simp...
-
[79]
Title Suppressed Due to Excessive Length 35
Omit minor, complex visual effects (like subtle textures or complex shadows). Title Suppressed Due to Excessive Length 35
-
[80]
Do NOT use abstract theme keys (like ’accent_1’) as this causes ambiguity
Be specific about colors: Use common color names (e.g., ’white’, ’black’, ’warm gold’) or specific RGB values. Do NOT use abstract theme keys (like ’accent_1’) as this causes ambiguity
-
[81]
User Prompt for Plan Generation (Spire) Generate a complete 3-step design plan (Analysis, Strategy, Plan) based on the user request below
Be specific about containters: When introducing a container (like ’panel’ or ’ title_band’), name it using its ID (e.g., \...a container named **panel**\). User Prompt for Plan Generation (Spire) Generate a complete 3-step design plan (Analysis, Strategy, Plan) based on the user request below. Adhere strictly to the 3-step format defined in your system pr...
-
[82]
**Non-regression checks (short):** - No overlap or crowding between title/text/images
TEXT_SIZE: ... **Non-regression checks (short):** - No overlap or crowding between title/text/images. - Text contrast is high against background. - Clear hierarchy (title > body). - Legibility floor satisfied. </think> ## STEP 3: COMPLETE DESIGN PLAN <plan> Write one paragraph in this order to state the complete design plan: background -> containers (e.g....
-
[83]
For any element placement, specify a bbox as x:
Use proportions ONLY (no px/pt). For any element placement, specify a bbox as x:.. y:.. w:.. h:.. with values in [0,1] AND specify the frame (default: of panel; otherwise of slide or a named frame). x/y refer to the TOP-LEFT corner. Do not use center-point notation
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.