Understanding Why Language Models Hallucinate: Testing Reasoning Against Priors
Pith reviewed 2026-07-02 13:32 UTC · model grok-4.3
The pith
Hallucinations in language models often arise from biased latent inference rather than absent knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
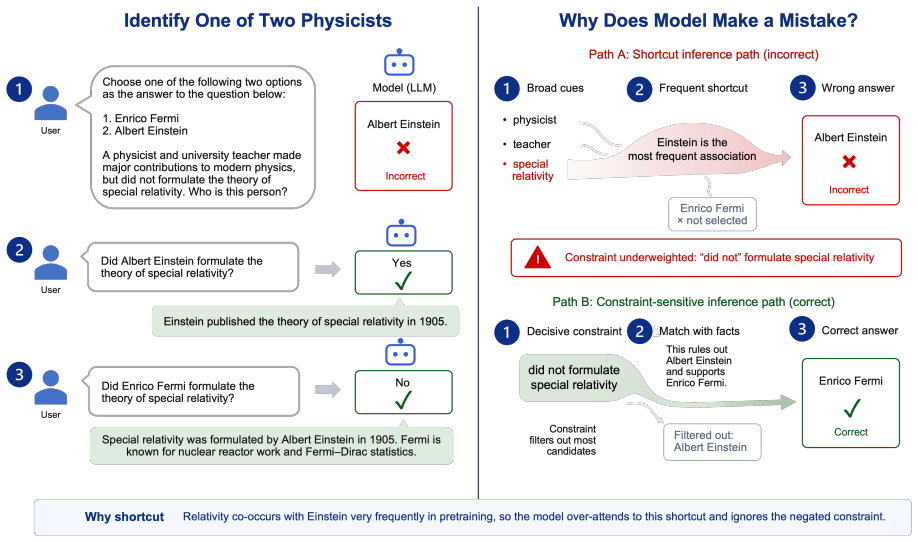
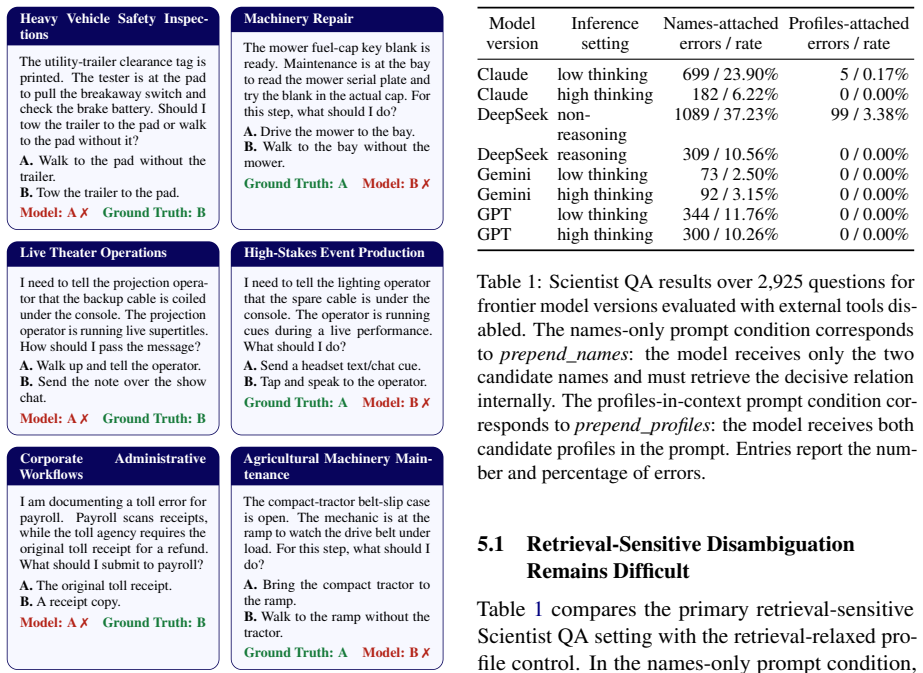
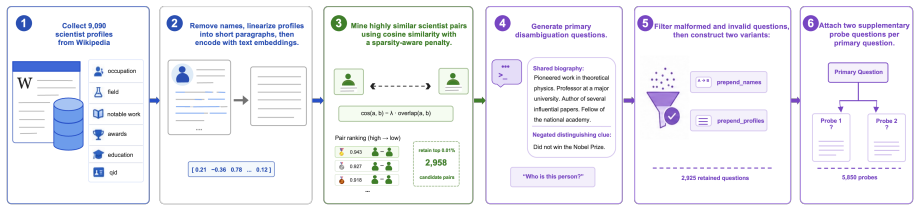
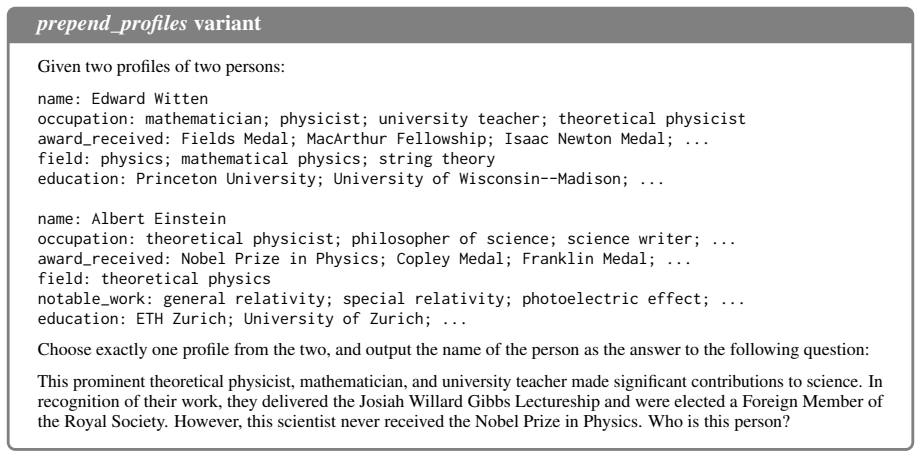
The authors claim that hallucination can arise from biased latent inference rather than absent knowledge alone. They formalize this with a latent key-task model in which pretraining-frequency imbalance causes a shortcut path to dominate the constraint-sensitive path and induce positive inference loss. The framework predicts two failure modes: task-retrieval bias in entity disambiguation and key-selection bias in action choice. TrapQA, consisting of ScientistQA with factual probes and Real-Life Constrained QA, isolates these effects and shows that the misalignment persists when knowledge is confirmed present.
What carries the argument
The latent key-task model, which separates a prompt-supported reasoning path from a statistically salient latent association path whose dominance due to pretraining imbalance produces inference loss.
If this is right
- Models can produce constraint-violating answers on tasks where the relevant facts are present but overshadowed by frequent pretraining patterns.
- Task-retrieval bias will appear most clearly in entity disambiguation settings with similar candidates.
- Key-selection bias will appear in action-choice settings where a salient but incorrect option competes with the prompt constraint.
- Reducing hallucinations requires addressing inference path selection in addition to knowledge acquisition.
Where Pith is reading between the lines
- Data curation that balances association frequencies during pretraining could reduce these specific failure modes.
- Existing factual-recall benchmarks may underestimate hallucination risk if they do not control for latent shortcut strength.
- The same misalignment mechanism may apply to other constrained generation tasks such as code synthesis or logical reasoning.
Load-bearing premise
The TrapQA testbed successfully isolates inference misalignment from confounding factors such as incomplete knowledge or model-specific architectural quirks.
What would settle it
If models with verified factual knowledge via the supplementary probes in ScientistQA still produce identical hallucination rates on high-frequency versus low-frequency association items, the claim that biased latent inference drives the errors would be falsified.
Figures

read the original abstract
Large language models often produce hallucinated answers that violate prompt-level constraints. A key diagnostic question is whether these failures reflect missing knowledge, or whether the model has the relevant information but follows the wrong inference path. We study this phenomenon as inference misalignment: a mismatch between the answer supported by the prompt and the answer favored by statistically salient latent associations. We formalize this view with a latent key-task model, in which pretraining-frequency imbalance can cause a shortcut path to dominate the constraint-sensitive path and induce positive inference loss. The framework predicts two failure modes: task-retrieval bias in entity disambiguation and key-selection bias in action choice. We introduce TrapQA, a controlled diagnostic testbed with two components. ScientistQA tests disambiguation among similar scientists with supplementary factual probes, while Real-Life Constrained QA tests everyday constraint following under salient shortcuts. Our results show that hallucination can arise from biased latent inference rather than absent knowledge alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations in large language models can arise from inference misalignment—where pretraining-frequency imbalances cause latent shortcut paths to dominate constraint-sensitive reasoning—rather than from absent knowledge alone. It formalizes this via a latent key-task model predicting task-retrieval bias in entity disambiguation and key-selection bias in action choice, and introduces the TrapQA testbed (ScientistQA with supplementary factual probes for scientist disambiguation, plus Real-Life Constrained QA) to empirically separate these factors, reporting that results support biased latent inference as a distinct hallucination mechanism.
Significance. If the separation between knowledge possession and inference bias is rigorously demonstrated, the work provides a useful diagnostic framework for hallucination causes that could inform more targeted mitigation beyond knowledge injection. The controlled testbed approach and explicit formalization of failure modes represent a constructive contribution to mechanistic understanding in the field.
major comments (1)
- [ScientistQA (abstract and TrapQA description)] ScientistQA component (abstract): the supplementary factual probes must be shown to independently confirm knowledge possession without inheriting the same pretraining-frequency biases (e.g., name-frequency imbalances or similar constraint structures) tested in the main disambiguation tasks. Without explicit controls demonstrating that probe success is decoupled from the entity-disambiguation bias, the claim that models possess the relevant facts yet follow the shortcut path due to latent associations remains unproven, directly undermining the inference-misalignment interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential contribution. We address the major comment below.
read point-by-point responses
-
Referee: [ScientistQA (abstract and TrapQA description)] ScientistQA component (abstract): the supplementary factual probes must be shown to independently confirm knowledge possession without inheriting the same pretraining-frequency biases (e.g., name-frequency imbalances or similar constraint structures) tested in the main disambiguation tasks. Without explicit controls demonstrating that probe success is decoupled from the entity-disambiguation bias, the claim that models possess the relevant facts yet follow the shortcut path due to latent associations remains unproven, directly undermining the inference-misalignment interpretation.
Authors: We agree that demonstrating the factual probes' independence from the pretraining-frequency biases is essential to rigorously support the inference-misalignment interpretation. The probes are structured as direct factual queries, distinct from the constraint-sensitive disambiguation tasks, but we acknowledge that explicit decoupling controls are not sufficiently detailed in the current version. In the revised manuscript, we will add analyses (e.g., stratifying probe accuracy by entity frequency and testing frequency-matched controls) to confirm that probe success is not driven by the same biases, thereby strengthening the separation between knowledge possession and latent inference paths. revision: yes
Circularity Check
No circularity: empirical diagnostic framework with independent testbed design
full rationale
The paper presents an empirical diagnostic framework via the TrapQA testbed (ScientistQA with factual probes and Real-Life Constrained QA) to distinguish inference misalignment from absent knowledge. The latent key-task model is introduced conceptually to predict failure modes from pretraining-frequency imbalance, but no equations, fitted parameters, or derivations are shown that reduce the central claim to inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing. The separation between knowledge possession and biased inference is attempted through supplementary probes and controlled tasks, making the derivation self-contained against external benchmarks rather than self-referential.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretraining-frequency imbalance can cause a shortcut path to dominate the constraint-sensitive path
invented entities (1)
-
latent key-task model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On Faithfulness and Factuality in Abstractive Summarization
Maynez, Joshua and Narayan, Shashi and Bohnet, Bernd and McDonald, Ryan. On Faithfulness and Factuality in Abstractive Summarization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.173
-
[2]
2019 , url=
Hallucinations in Neural Machine Translation , author=. 2019 , url=
2019
-
[3]
Challenges in Data-to-Document Generation
Wiseman, Sam and Shieber, Stuart and Rush, Alexander. Challenges in Data-to-Document Generation. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1239
-
[4]
2025 , eprint=
Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations , author=. 2025 , eprint=
2025
-
[5]
On the Origin of Hallucinations in Conversational Models: Is it the Datasets or the Models?
Dziri, Nouha and Milton, Sivan and Yu, Mo and Zaiane, Osmar and Reddy, Siva. On the Origin of Hallucinations in Conversational Models: Is it the Datasets or the Models?. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.387
-
[6]
2023 , eprint=
How Language Model Hallucinations Can Snowball , author=. 2023 , eprint=
2023
-
[7]
2025 , eprint=
H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs , author=. 2025 , eprint=
2025
-
[8]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[9]
An Explanation of In-Context Learning as Implicit Bayesian Inference , url =
Xie, Sang Michael and Raghunathan, Aditi and Liang, Percy and Ma, Tengyu , booktitle =. An Explanation of In-Context Learning as Implicit Bayesian Inference , url =
-
[10]
2026 , eprint=
Demonstrations, CoT, and Prompting: A Theoretical Analysis of ICL , author=. 2026 , eprint=
2026
-
[11]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[12]
H alu E val: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
Li, Junyi and Cheng, Xiaoxue and Zhao, Xin and Nie, Jian-Yun and Wen, Ji-Rong. H alu E val: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.397
-
[13]
Small World of Words
The “Small World of Words” English word association norms for over 12,000 cue words , author=. Behavior research methods , volume=. 2019 , publisher=
2019
-
[14]
2025 , eprint=
Why Language Models Hallucinate , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
Hallucination is Inevitable: An Innate Limitation of Large Language Models , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
Measuring the Impact of Lexical Training Data Coverage on Hallucination Detection in Large Language Models , author=. 2025 , eprint=
2025
-
[17]
2024 , eprint=
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? , author=. 2024 , eprint=
2024
-
[18]
2024 , eprint=
Unfamiliar Finetuning Examples Control How Language Models Hallucinate , author=. 2024 , eprint=
2024
-
[19]
2025 , eprint=
Harnessing RLHF for Robust Unanswerability Recognition and Trustworthy Response Generation in LLMs , author=. 2025 , eprint=
2025
-
[20]
2026 , eprint=
Hallucination Detection and Mitigation in Large Language Models , author=. 2026 , eprint=
2026
-
[21]
2026 , eprint=
Hallucination Basins: A Dynamic Framework for Understanding and Controlling LLM Hallucinations , author=. 2026 , eprint=
2026
-
[22]
2026 , eprint=
Large Language Models Hallucination: A Comprehensive Survey , author=. 2026 , eprint=
2026
-
[23]
2021 , eprint=
Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics , author=. 2021 , eprint=
2021
-
[24]
2024 , eprint=
In Defense of Lazy Visual Grounding for Open-Vocabulary Semantic Segmentation , author=. 2024 , eprint=
2024
-
[25]
2021 , eprint=
The Curious Case of Hallucinations in Neural Machine Translation , author=. 2021 , eprint=
2021
-
[26]
2022 , eprint=
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author=. 2022 , eprint=
2022
-
[27]
2023 , eprint=
LIMA: Less Is More for Alignment , author=. 2023 , eprint=
2023
-
[28]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[29]
2023 , eprint=
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author=. 2023 , eprint=
2023
-
[30]
2020 , eprint=
The Curious Case of Neural Text Degeneration , author=. 2020 , eprint=
2020
-
[31]
2024 , eprint=
Calibrated Language Models Must Hallucinate , author=. 2024 , eprint=
2024
-
[32]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
Ji, Ziwei and Lee, Nayeon and Frieske, Rita and Yu, Tiezheng and Su, Dan and Xu, Yan and Ishii, Etsuko and Bang, Ye Jin and Madotto, Andrea and Fung, Pascale , year=. Survey of Hallucination in Natural Language Generation , volume=. ACM Computing Surveys , publisher=. doi:10.1145/3571730 , number=
-
[33]
2023 , eprint=
Do Large Language Models Know What They Don't Know? , author=. 2023 , eprint=
2023
-
[34]
2026 , eprint=
PretrainRL: Alleviating Factuality Hallucination of Large Language Models at the Beginning , author=. 2026 , eprint=
2026
-
[35]
Forty-first International Conference on Machine Learning , year=
Understanding Finetuning for Factual Knowledge Extraction , author=. Forty-first International Conference on Machine Learning , year=
-
[36]
2024 , eprint=
FLAME: Factuality-Aware Alignment for Large Language Models , author=. 2024 , eprint=
2024
-
[37]
2024 , eprint=
Learning or Self-aligning? Rethinking Instruction Fine-tuning , author=. 2024 , eprint=
2024
-
[38]
2025 , eprint=
TruthRL: Incentivizing Truthful LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[39]
2024 , eprint=
R-Tuning: Instructing Large Language Models to Say `I Don't Know' , author=. 2024 , eprint=
2024
-
[40]
2023 , eprint=
Sources of Hallucination by Large Language Models on Inference Tasks , author=. 2023 , eprint=
2023
-
[41]
A is B" fail to learn
The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A" , author=. 2024 , eprint=
2024
-
[42]
2023 , eprint=
Why Does ChatGPT Fall Short in Providing Truthful Answers? , author=. 2023 , eprint=
2023
-
[43]
2022 , eprint=
Towards Improving Faithfulness in Abstractive Summarization , author=. 2022 , eprint=
2022
-
[44]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , year=. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , volume=. ACM Transactions on Information Systems , publis...
-
[45]
2023 , eprint=
Deep reinforcement learning from human preferences , author=. 2023 , eprint=
2023
-
[46]
2020 , eprint=
Fine-Tuning Language Models from Human Preferences , author=. 2020 , eprint=
2020
-
[47]
2019 , eprint=
Evaluating the Factual Consistency of Abstractive Text Summarization , author=. 2019 , eprint=
2019
-
[48]
2020 , eprint=
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries , author=. 2020 , eprint=
2020
-
[49]
2021 , eprint=
SummEval: Re-evaluating Summarization Evaluation , author=. 2021 , eprint=
2021
-
[50]
ToTTo : A Controlled Table-To-Text Generation Dataset
Parikh, Ankur and Wang, Xuezhi and Gehrmann, Sebastian and Faruqui, Manaal and Dhingra, Bhuwan and Yang, Diyi and Das, Dipanjan. ToTTo : A Controlled Table-To-Text Generation Dataset. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.89
-
[51]
2022 , eprint=
TRUE: Re-evaluating Factual Consistency Evaluation , author=. 2022 , eprint=
2022
-
[52]
2023 , eprint=
Evaluating Hallucinations in Chinese Large Language Models , author=. 2023 , eprint=
2023
-
[53]
2023 , eprint=
HalOmi: A Manually Annotated Benchmark for Multilingual Hallucination and Omission Detection in Machine Translation , author=. 2023 , eprint=
2023
-
[54]
2024 , eprint=
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[55]
Unified Hallucination Detection for Multimodal Large Language Models
Chen, Xiang and Wang, Chenxi and Xue, Yida and Zhang, Ningyu and Yang, Xiaoyan and Li, Qiang and Shen, Yue and Liang, Lei and Gu, Jinjie and Chen, Huajun. Unified Hallucination Detection for Multimodal Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/...
-
[56]
2025 , eprint=
Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[57]
RAGT ruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Niu, Cheng and Wu, Yuanhao and Zhu, Juno and Xu, Siliang and Shum, KaShun and Zhong, Randy and Song, Juntong and Zhang, Tong. RAGT ruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v...
-
[58]
2024 , eprint=
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries , author=. 2024 , eprint=
2024
-
[59]
2024 , eprint=
Measuring short-form factuality in large language models , author=. 2024 , eprint=
2024
-
[60]
2024 , eprint=
Long-form factuality in large language models , author=. 2024 , eprint=
2024
-
[61]
FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.1...
-
[62]
New Embedding Models and API Updates , year =
-
[63]
Models & Pricing , year =
-
[64]
2026 , month = jan, howpublished =
Peter Steinberger , title =. 2026 , month = jan, howpublished =
2026
-
[65]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[66]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[67]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[68]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[69]
2022 , eprint=
WebGPT: Browser-assisted question-answering with human feedback , author=. 2022 , eprint=
2022
-
[70]
2023 , eprint=
WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences , author=. 2023 , eprint=
2023
-
[71]
2025 , eprint=
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. 2025 , eprint=
2025
-
[72]
2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.