VLM-AR3L: Vision-Language Models for Absolute and Relative Rewards in Reinforcement Learning
Pith reviewed 2026-07-03 20:41 UTC · model grok-4.3
The pith
VLM-AR3L trains reinforcement learning agents with both absolute state scores and relative progress judgments generated by vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
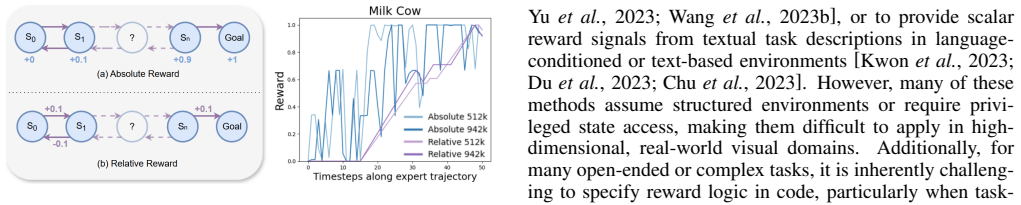
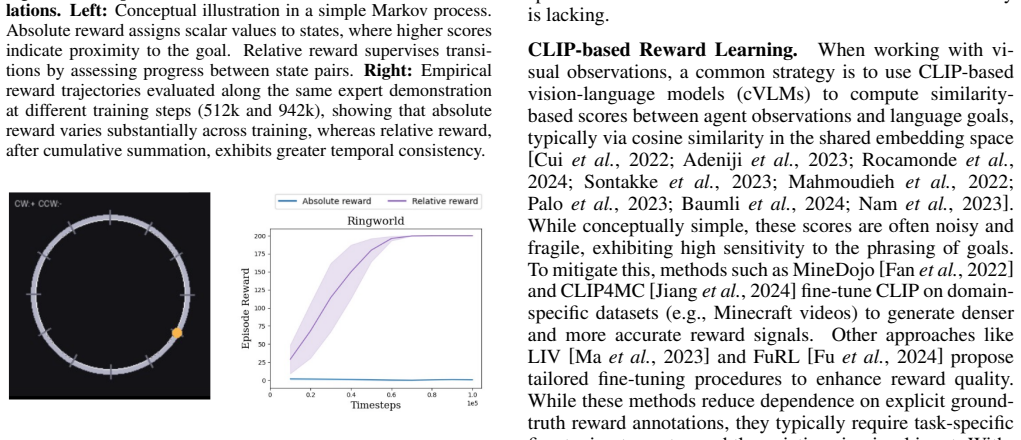
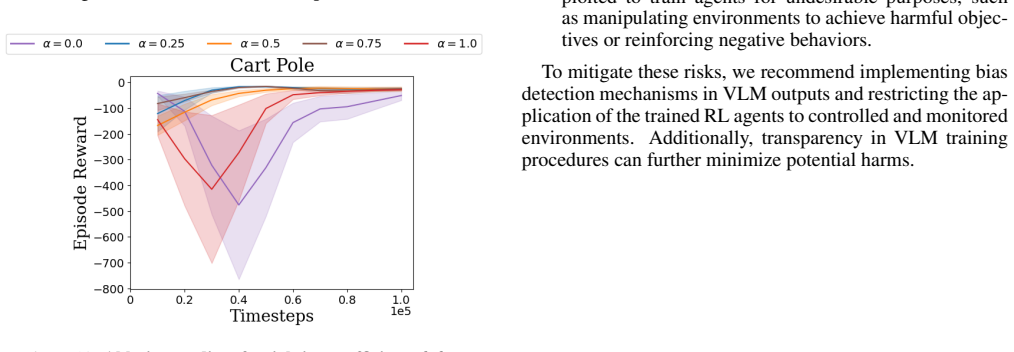
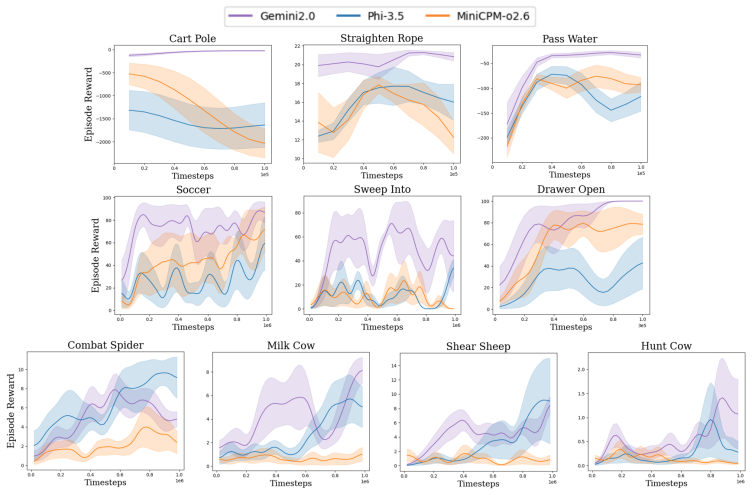
VLM-AR3L learns an absolute reward model that outputs scalar evaluations for individual states and a relative reward model that compares consecutive observations to determine progress or regression toward the task goal, both derived from preference labels supplied by a vision-language model. Their integration supplies the stability of direct state evaluation together with the robustness of comparative supervision, and this combined reward function produces higher-performing policies than prior VLM-based reward learning methods on benchmarks that include classic control, manipulation, and long-horizon open-world tasks.
What carries the argument
The dual reward architecture that fuses an absolute scalar state evaluator with a relative comparative progress detector, both trained on VLM-generated preference labels for a given natural language goal.
If this is right
- The combined absolute and relative signals produce more stable learning trajectories than either signal alone.
- The approach scales to long-horizon decision making where visual complexity makes hand-designed rewards impractical.
- Performance gains appear across classic control, robotic manipulation, and open-world embodied environments.
- Relative comparisons add robustness when absolute state values are noisy or hard to calibrate.
Where Pith is reading between the lines
- The same dual-signal structure could be tested with other multimodal models that accept both images and language.
- If the language goal is vague or changes over time, an online update mechanism for the VLM labels might be needed.
- In domains where visual observations are low-dimensional, the relative component may contribute less than the absolute one.
- Extending the method to multi-agent settings would require the VLM to judge joint observations against shared goals.
Load-bearing premise
VLM-generated preference labels correctly indicate whether one observation shows progress or regression toward the stated task goal, without systematic biases that would distort the learned reward models.
What would settle it
Training a reinforcement learning policy with VLM-AR3L rewards on a held-out Minecraft task and observing no performance gain or a clear drop relative to a strong baseline reward method would indicate the central claim does not hold.
Figures







read the original abstract
Designing effective reward functions remains a major challenge in reinforcement learning (RL), particularly in open-ended environments where task goals are abstract and difficult to quantify. In this work, we present VLM-AR3L, a framework that leverages Vision-Language Models (VLMs) to provide both absolute and relative rewards for RL. VLM-AR3L interprets an agent's visual observations in the context of a natural language task goal, and learns both absolute and relative rewards from VLM-generated preference labels. The absolute reward model predicts scalar evaluations for individual states, while the relative reward model compares consecutive observations to infer progress or regression toward the task goal. Their integration combines the stability of state-based evaluation with the robustness of comparative supervision. We evaluate VLM-AR3L across benchmarks spanning classic control, manipulation, and open-world embodied tasks, with a particular focus on Minecraft given its visual complexity and long-horizon decision-making requirements. Experimental results show that VLM-AR3L consistently outperforms prior VLM-based reward learning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VLM-AR3L, a framework that uses vision-language models to generate both absolute rewards (scalar state evaluations) and relative rewards (comparisons of consecutive observations for progress toward natural-language goals) to supervise RL agents. It integrates the two reward heads for stability and robustness, and reports consistent outperformance over prior VLM-based reward methods on classic control, manipulation, and especially Minecraft benchmarks.
Significance. If the empirical claims hold after proper validation, the work would be significant for reward learning in long-horizon, visually complex embodied settings. Combining absolute and relative VLM supervision is a reasonable architectural idea that could improve sample efficiency and stability over purely comparative or purely scalar approaches; the Minecraft focus is well-chosen given the domain's partial observability and horizon length.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that VLM-AR3L 'consistently outperforms prior VLM-based reward learning methods' is unsupported by any reported metrics, baselines, error bars, or statistical tests. Without these, the data-to-claim link cannot be evaluated and the outperformance assertion remains unevaluable.
- [Experiments] Experiments section (Minecraft results): the headline result requires that VLM-generated preference labels are free of systematic biases (e.g., over-weighting salient but irrelevant pixels or failing on partial observability across dozens of steps). No ablation, human validation of labels, or noise-injection study is described; if such biases exist, both reward heads are trained on corrupted signals and any reported gains could be artifacts rather than evidence for the absolute-relative integration.
minor comments (2)
- [Method] The manuscript would benefit from explicit equations defining the absolute reward head r_abs(s) and relative reward head r_rel(s_t, s_{t+1}) and how they are combined into the final reward signal.
- [Figures / Tables] Figure and table captions should include the exact number of seeds, evaluation episodes, and whether results are mean ± std.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We agree that the empirical claims require stronger quantitative support and validation of the VLM labels. Below we address each major comment and commit to revisions that will include the requested metrics, statistical tests, and label-quality analyses.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that VLM-AR3L 'consistently outperforms prior VLM-based reward learning methods' is unsupported by any reported metrics, baselines, error bars, or statistical tests. Without these, the data-to-claim link cannot be evaluated and the outperformance assertion remains unevaluable.
Authors: We acknowledge the need for more rigorous reporting. In the revised manuscript we will expand the Experiments section with tables reporting mean returns and standard deviations over at least 5 random seeds for all methods, explicit numerical comparisons against every baseline, error bars on all learning curves, and statistical significance tests (paired t-tests with p-values) to support the outperformance statements. The abstract will be updated to reference these quantitative results. revision: yes
-
Referee: [Experiments] Experiments section (Minecraft results): the headline result requires that VLM-generated preference labels are free of systematic biases (e.g., over-weighting salient but irrelevant pixels or failing on partial observability across dozens of steps). No ablation, human validation of labels, or noise-injection study is described; if such biases exist, both reward heads are trained on corrupted signals and any reported gains could be artifacts rather than evidence for the absolute-relative integration.
Authors: We agree this is an important concern. The revised version will add: (i) a human validation study on a random sample of VLM preference labels with inter-annotator agreement metrics, (ii) an ablation that injects controlled label noise and measures degradation in both reward heads, and (iii) a short discussion of how the joint absolute-relative objective provides robustness to label errors. These additions will directly address whether observed gains could be artifacts. revision: yes
Circularity Check
Empirical framework with no self-referential derivations or fitted predictions
full rationale
The manuscript describes an applied RL framework that trains separate absolute and relative reward heads from VLM-generated preference labels on visual observations. No equations, uniqueness theorems, or ansatzes are presented that reduce any claimed result to its own inputs by construction. Evaluation relies on external benchmarks (classic control, manipulation, Minecraft) rather than internal consistency checks. Self-citations, if present, are not load-bearing for the core method. This is a standard empirical contribution whose validity rests on experimental outcomes, not definitional closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year=
Reward Design with Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[2]
Proceedings of the 40th International Conference on Machine Learning , year =
Guiding Pretraining in Reinforcement Learning with Large Language Models , author =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[3]
Accelerating Reinforcement Learning of Robotic Manipulations via Feedback from Large Language Models , author=. 2023 , eprint=
work page 2023
-
[4]
Language to rewards for robotic skill synthesis,
Language to Rewards for Robotic Skill Synthesis , author=. arXiv preprint arXiv:2306.08647 , year=
-
[5]
Eureka: Human-Level Reward Design via Coding Large Language Models , author=. 2024 , eprint=
work page 2024
-
[6]
The Twelfth International Conference on Learning Representations , year=
Text2Reward: Reward Shaping with Language Models for Reinforcement Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[7]
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. 2023 , journal =
work page 2023
-
[8]
Robogen: Towards unleashing infinite data for automated robot learning via generative simulation , author=. arXiv preprint arXiv:2311.01455 , year=
-
[9]
Learning for Dynamics and Control Conference (L4DC) , year=
Can Foundation Models Perform Zero-Shot Task Specification for Robot Manipulation? , author=. Learning for Dynamics and Control Conference (L4DC) , year=
-
[10]
Language Reward Modulation for Pretraining Reinforcement Learning , author=. 2023 , eprint=
work page 2023
-
[11]
arXiv preprint arXiv:2306.00958 , year=
LIV: Language-Image Representations and Rewards for Robotic Control , author=. arXiv preprint arXiv:2306.00958 , year=
-
[12]
LiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers , author=. 2023 , eprint=
work page 2023
-
[13]
The Twelfth International Conference on Learning Representations , year=
Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[14]
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS) , year=
RoboCLIP: One Demonstration is Enough to Learn Robot Policies , author=. Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[15]
Proceedings of the 41st International Conference on Machine Learning , year =
FuRL: Visual-Language Models as Fuzzy Rewards for Reinforcement Learning , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[16]
Zero-Shot Reward Specification via Grounded Natural Language , author=. 2022 , url=
work page 2022
-
[17]
Towards A Unified Agent with Foundation Models , author=. 2023 , eprint=
work page 2023
-
[18]
Vision-Language Models as a Source of Rewards , author=. 2024 , eprint=
work page 2024
-
[19]
MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge , author =. Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
-
[20]
European Conference on Computer Vision (ECCV) , year=
Reinforcement Learning Friendly Vision-Language Model for Minecraft , author=. European Conference on Computer Vision (ECCV) , year=
-
[21]
Neural Information Processing Systems , author =
Video Prediction Models as Rewards for Reinforcement Learning , publisher =. Neural Information Processing Systems , author =. 2023 , eprint =
work page 2023
-
[22]
Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI Feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2310.00166 , year=
Motif: Intrinsic Motivation from Artificial Intelligence Feedback , author=. arXiv preprint arXiv:2310.00166 , year=
-
[24]
Online Preference-based Reinforcement Learning with Self-augmented Feedback from Large Language Model , author=. 2024 , eprint=
work page 2024
-
[25]
Proceedings of the 41st International Conference on Machine Learning , year =
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[26]
Real-World Offline Reinforcement Learning from Vision Language Model Feedback , author=. 2024 , eprint=
work page 2024
-
[27]
Preference VLM: Leveraging VLMs for Scalable Preference-Based Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[28]
VLP: Vision-Language Preference Learning for Embodied Manipulation , author=. 2025 , eprint=
work page 2025
-
[29]
International Conference on Machine Learning , year=
PEBBLE: Feedback-Efficient Interactive Reinforcement Learning via Relabeling Experience and Unsupervised Pre-training , author=. International Conference on Machine Learning , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in Neural Information Processing Systems , volume=. 2017 , publisher=
work page 2017
-
[31]
Advances in Neural Information Processing Systems , year=
Reward learning from human preferences and demonstrations in Atari , author=. Advances in Neural Information Processing Systems , year=
-
[32]
arXiv preprint arXiv:2111.03026 , year=
B-Pref: Benchmarking Preference-Based Reinforcement Learning , author=. arXiv preprint arXiv:2111.03026 , year=
-
[33]
Theory and application of reward shaping in reinforcement learning , year =
Laud, Adam Daniel , advisor =. Theory and application of reward shaping in reinforcement learning , year =
-
[34]
Silver, David and Huang, Aja and Maddison, Chris J. and Guez, Arthur and Sifre, Laurent and van den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and Dieleman, Sander and Grewe, Dominik and Nham, John and Kalchbrenner, Nal and Sutskever, Ilya and Lillicrap, Timothy and Leach, Madeleine and K...
-
[35]
Dota 2 with Large Scale Deep Reinforcement Learning , author=. 2019 , eprint=
work page 2019
-
[36]
Gupta, Abhishek and Pacchiano, Aldo and Zhai, Yuexiang and Kakade, Sham and Levine, Sergey , booktitle =. Unpacking Reward Shaping: Understanding the Benefits of Reward Engineering on Sample Complexity , year =
-
[37]
Scalable agent alignment via reward modeling: a research direction , author=. 2018 , eprint=
work page 2018
-
[38]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. https://arxiv.org/abs/1801.01290 , booktitle=
work page internal anchor Pith review Pith/arXiv arXiv
- [39]
-
[40]
Leslie Pack Kaelbling and Michael L. Littman and Anthony R. Cassandra , keywords =. Planning and acting in partially observable stochastic domains , journal =. 1998 , issn =. doi:https://doi.org/10.1016/S0004-3702(98)00023-X , url =
-
[41]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
work page 1952
-
[42]
Advances in Neural Information Processing Systems , title =
Bromley, Jane and Guyon, Isabelle and LeCun, Yann and S\". Advances in Neural Information Processing Systems , title =
- [43]
-
[44]
Conference on Robot Learning , year=
SoftGym: Benchmarking Deep Reinforcement Learning for Deformable Object Manipulation , author=. Conference on Robot Learning , year=
-
[45]
Conference on Robot Learning (CoRL) , year=
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning , author=. Conference on Robot Learning (CoRL) , year=
-
[46]
Google DeepMind , title =
-
[47]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author =. arXiv preprint , year =
-
[48]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding , author=. 2024 , eprint=
work page 2024
- [49]
-
[50]
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling , author=. 2025 , eprint=
work page 2025
- [51]
-
[52]
Proceedings of the 38th International Conference on Machine Learning , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.