Prototype Language Models
Pith reviewed 2026-07-02 16:11 UTC · model grok-4.3
The pith
Prototype language models match or exceed dense baselines on downstream tasks while localizing training data influence for 500x faster attribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
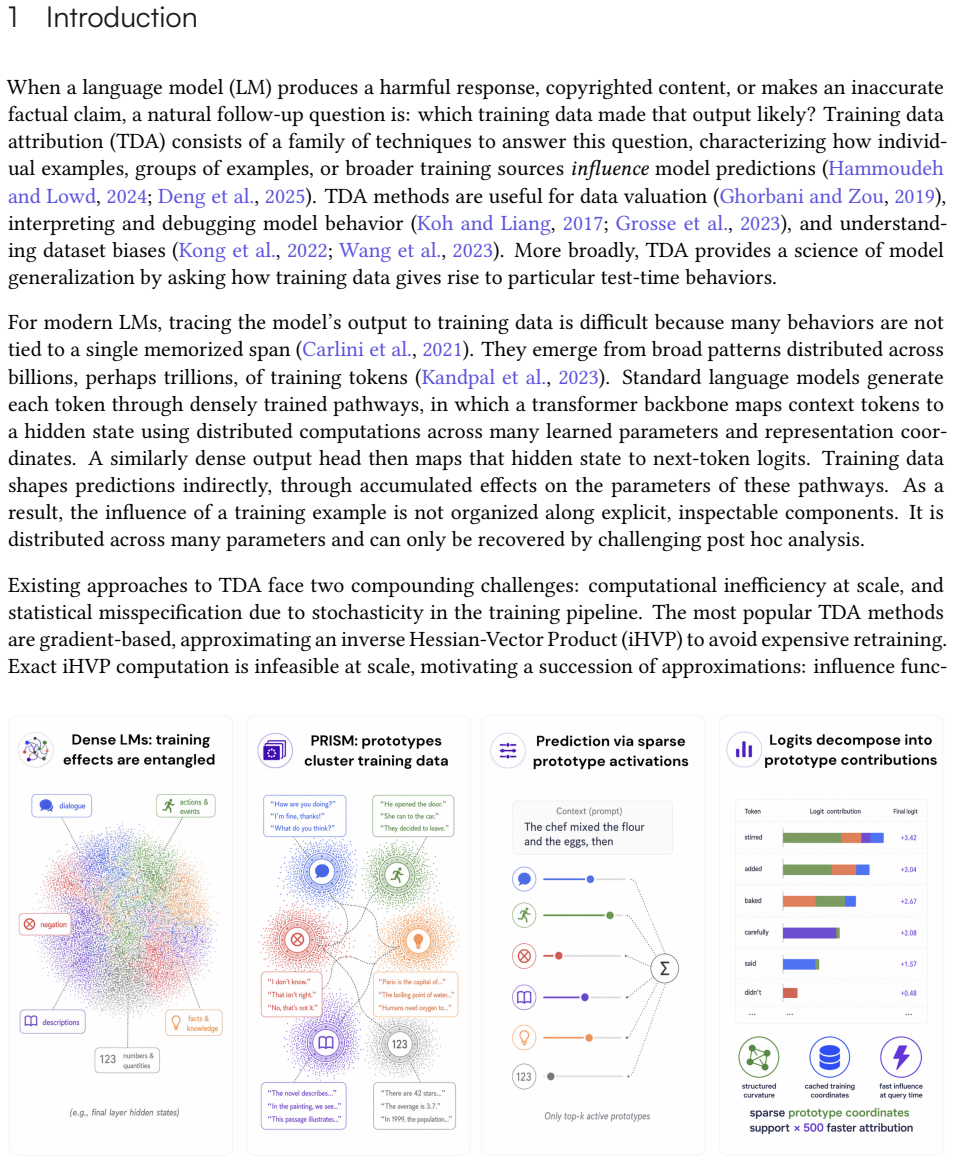
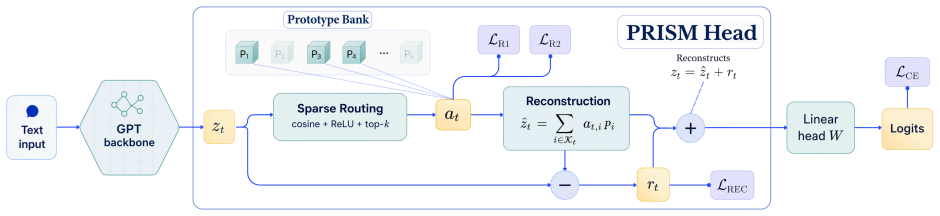
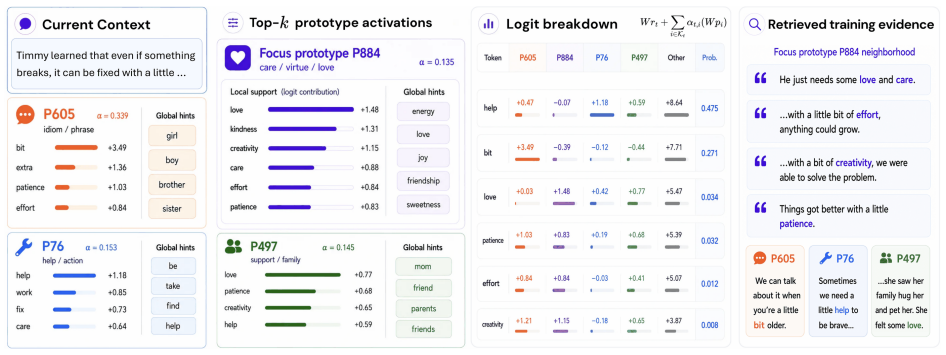
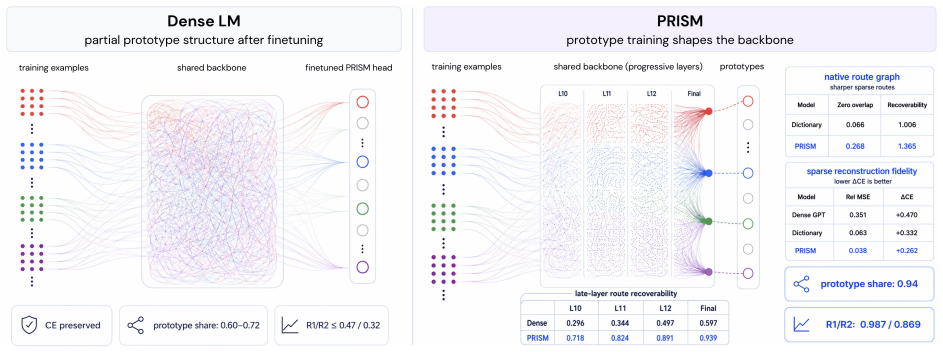
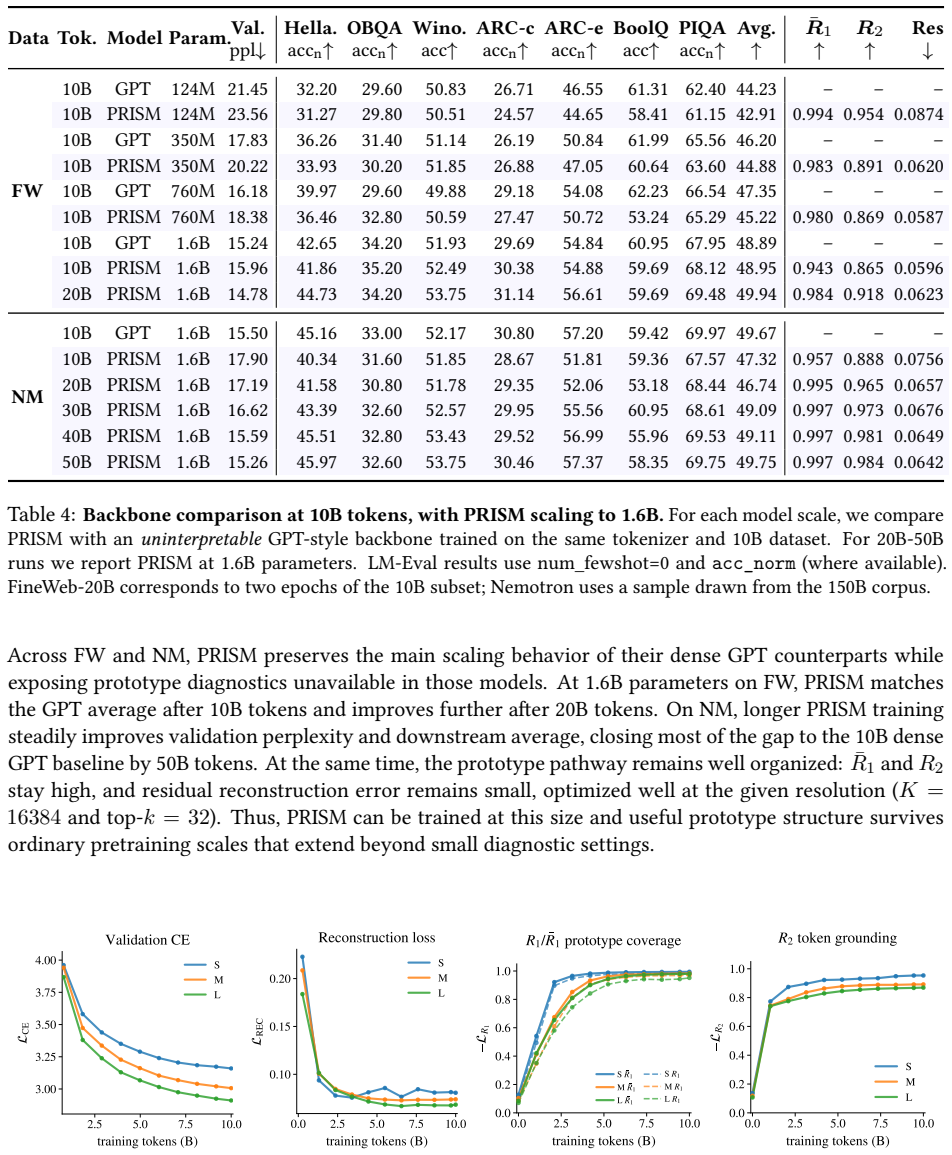
Forming each prediction via a sparse non-negative mixture of learned prototypes, trained with clustering objectives that anchor each prototype to coherent neighborhoods of training examples, yields language models whose downstream accuracy matches or stays within 2.5 percentage points of dense baselines while making the loss curvature more localized and thereby enabling training data attribution that is approximately 500 times faster than post-hoc methods at the same memory budget.
What carries the argument
Sparse non-negative mixture of learned prototypes, each anchored to training-example neighborhoods by clustering objectives during training.
If this is right
- Training data attribution becomes feasible at the scale of 1.6B-parameter models without post-hoc approximations.
- Linear controllers over prototype weights can raise downstream accuracy by roughly three points while preserving traceability to training neighborhoods.
- Targeted suppression of individual prototypes removes specific model behaviors without finetuning or measurable degradation in generation quality.
- The loss landscape curvature is localized enough to admit tractable Hessian computations that post-hoc methods cannot match at equal memory.
Where Pith is reading between the lines
- If prototype neighborhoods remain stable across continued training, the same architecture could support incremental data editing by adjusting only the relevant prototype coefficients.
- The approach may extend to multimodal settings where prototypes could be anchored to image-text pairs rather than text alone.
- Because prototypes are explicit and non-negative, they could serve as a natural interface for human-in-the-loop auditing that dense models lack.
Load-bearing premise
Clustering objectives will reliably tie each prototype to a coherent neighborhood of training examples so that prototype-level operations correspond to meaningful data subsets.
What would settle it
An experiment in which randomly initialized prototypes, after the same training procedure, produce attribution rankings that differ substantially from ground-truth influence scores on a held-out set of training examples.
Figures


read the original abstract
Knowing which training examples drive outputs is fundamental to auditing, correcting, and understanding language models, yet for modern LLMs this remains expensive, approximate, and largely post-hoc. Standard language models generate tokens through a dense network pathway, causing training data's influence to be distributed across parameters rather than organized along explicit, traceable components. We introduce a prototype language model architecture, Prototypes for Interpretable Sequence Modeling (PRISM), that forms each prediction via a sparse, non-negative mixture of learned prototypes, trained with clustering objectives that anchor each prototype to coherent neighborhoods of training examples. Across architectures from 130M to 1.6B parameters trained on up to 50B tokens, prototype language models either surpass or remain within 2.5 percentage points on average downstream accuracy of matched dense baselines. We show that sparse prototype structure localizes curvature in the loss landscape, yielding a more tractable Hessian and enabling training data attribution that is ~500x faster than post hoc baselines when consuming equivalent memory. Calibrating linear prototype controllers can improve downstream accuracy by roughly 3 points while tracing those corrections back to training neighborhoods, and targeted prototype suppression can remove model behaviors without finetuning or measurable loss in generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PRISM, a prototype language model in which each token prediction is formed as a sparse non-negative linear combination of learned prototypes. Prototypes are trained jointly with clustering objectives intended to anchor each prototype to coherent neighborhoods of training examples. Across model sizes 130M–1.6B trained on up to 50B tokens, the architecture matches or comes within 2.5 points of dense baselines on downstream tasks; the sparse structure is claimed to yield a more tractable Hessian that enables training-data attribution ~500× faster than post-hoc methods at equal memory, plus prototype-level calibration and suppression that improve accuracy or remove behaviors without full fine-tuning.
Significance. If the empirical parity and the attribution speedup both hold, the work would supply a concrete architectural route to localized, traceable influence of training data inside large language models, which is currently a major practical bottleneck for auditing and editing.
major comments (1)
- [Abstract] Abstract (and the training-procedure description): the central interpretability claim—that prototype suppression or controller calibration corresponds to operations on meaningful training-data subsets—rests on the unverified assertion that the clustering objectives produce coherent neighborhoods. No quantitative metric (e.g., intra-prototype example similarity, nearest-neighbor purity) or qualitative inspection is referenced to confirm that each prototype is anchored rather than a diffuse mixture; if the anchoring fails, the reported 500× attribution speedup does not deliver the claimed traceability benefit.
minor comments (2)
- The abstract reports aggregate accuracy deltas but supplies neither per-task numbers, error bars, nor the exact downstream benchmarks; these details are required to assess whether the “within 2.5 points” claim is robust.
- Notation for the sparse non-negative mixture and the clustering loss is introduced only at a high level; explicit equations and hyper-parameter schedules for the clustering term should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to substantiate the prototype anchoring claim. We agree this is central to the interpretability benefits and will strengthen the manuscript with explicit verification.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the training-procedure description): the central interpretability claim—that prototype suppression or controller calibration corresponds to operations on meaningful training-data subsets—rests on the unverified assertion that the clustering objectives produce coherent neighborhoods. No quantitative metric (e.g., intra-prototype example similarity, nearest-neighbor purity) or qualitative inspection is referenced to confirm that each prototype is anchored rather than a diffuse mixture; if the anchoring fails, the reported 500× attribution speedup does not deliver the claimed traceability benefit.
Authors: We agree that the current manuscript does not reference quantitative or qualitative evidence confirming prototype coherence. While the clustering objectives are designed to anchor prototypes to coherent neighborhoods, this remains an assertion without direct verification in the presented results. In the revised version we will add: (1) intra-prototype example similarity metrics computed on training data assigned to each prototype, (2) nearest-neighbor purity scores relative to prototype centroids, and (3) qualitative inspection of representative training subsets for a sample of prototypes. These additions will be placed in the training-procedure and experimental sections and referenced from the abstract, directly supporting the traceability interpretation of the attribution speedup. revision: yes
Circularity Check
No significant circularity; empirical claims are self-contained
full rationale
The provided abstract and context describe an empirical architecture paper introducing PRISM, with performance and speedup claims framed as measured outcomes from training runs across model scales. No equations, derivations, or load-bearing steps are presented that reduce any 'prediction' or result to fitted parameters by construction, nor are self-citations used to import uniqueness theorems or ansatzes. The clustering objectives are described as part of the training procedure itself rather than a post-training fit renamed as a result. The central claims (accuracy parity, ~500x attribution speedup) are therefore independent of the inputs and do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clustering objectives during training anchor each prototype to coherent neighborhoods of training examples
invented entities (1)
-
learned prototypes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 34th International Conference on Machine Learning , pages =
Understanding Black-box Predictions via Influence Functions , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[2]
Advances in Neural Information Processing Systems , volume =
Estimating Training Data Influence by Tracing Gradient Descent , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[3]
Advances in Neural Information Processing Systems , volume =
Representer Point Selection for Explaining Deep Neural Networks , author =. Advances in Neural Information Processing Systems , volume =. 2018 , url =
2018
-
[4]
Proceedings of the 36th International Conference on Machine Learning , pages =
Data Shapley: Equitable Valuation of Data for Machine Learning , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[6]
2025 , month = sep, doi =
A Survey of Data Attribution: Methods, Applications, and Evaluation in the Era of Generative AI , author =. 2025 , month = sep, doi =
2025
-
[7]
International Conference on Learning Representations , year =
Resolving Training Biases via Influence-based Data Relabeling , author =. International Conference on Learning Representations , year =
-
[8]
Advances in Neural Information Processing Systems , volume =
Error Discovery by Clustering Influence Embeddings , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[9]
Advances in Neural Information Processing Systems , volume =
Data Attribution for Text-to-Image Models by Unlearning Synthesized Images , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[11]
2024 , eprint =
Generalized Group Data Attribution , author =. 2024 , eprint =
2024
-
[12]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Optimizing Neural Networks with Kronecker-factored Approximate Curvature , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[13]
2022 , URL =
Scaling Up Influence Functions , author =. 2022 , URL =
2022
-
[14]
Studying Large Language Model Generalization with Influence Functions , journal =
Roger Grosse and Juhan Bae and Cem Anil and Nelson Elhage and Alex Tamkin and Amirhossein Tajdini and Benoit Steiner and Dustin Li and Esin Durmus and Ethan Perez and Evan Hubinger and Kamil. Studying Large Language Model Generalization with Influence Functions , journal =. 2023 , url =
2023
-
[15]
Proceedings of the 40th International Conference on Machine Learning (ICML) , series =
Sung Min Park and Kristian Georgiev and Andrew Ilyas and Guillaume Leclerc and Aleksander Madry , title =. Proceedings of the 40th International Conference on Machine Learning (ICML) , series =. 2023 , publisher =
2023
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Andrea Schioppa , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[17]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Better Training Data Attribution via Better Inverse Hessian-Vector Products , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Sang Keun Choe and Hwijeen Ahn and Juhan Bae and Kewen Zhao and Minsoo Kang and Youngseog Chung and Adithya Pratapa and Willie Neiswanger and Emma Strubell and Teruko Mitamura and Jeff Schneider and Eduard Hovy and Roger Grosse and Eric Xing , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
2025 , publisher =
Liu, Jiacheng and Blanton, Taylor and Elazar, Yanai and Min, Sewon and Chen, Yen-Sung and Chheda-Kothary, Arnavi and Tran, Huy and Bischoff, Byron and Marsh, Eric and Schmitz, Michael and others , booktitle =. 2025 , publisher =
2025
-
[21]
International Conference on Learning Representations (ICLR) , year =
Scalable Influence and Fact Tracing for Large Language Model Pretraining , author =. International Conference on Learning Representations (ICLR) , year =
-
[22]
2024 , eprint =
Revisiting Inverse Hessian Vector Products for Calculating Influence Functions , author =. 2024 , eprint =
2024
-
[24]
Scaling Inherently Interpretable Language Models , year =
-
[25]
International Conference on Learning Representations , year =
Samyadeep Basu and Phillip Pope and Soheil Feizi , title =. International Conference on Learning Representations , year =
-
[26]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Andrea Schioppa and Katja Filippova and Ivan Titov and Polina Zablotskaia , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[27]
2022 , eprint =
Adaptive Gradient Methods at the Edge of Stability , author =. 2022 , eprint =
2022
-
[28]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Juhan Bae and Nathan Ng and Alston Lo and Marzyeh Ghassemi and Roger Grosse , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , url =
2022
-
[29]
Proceedings of the 39th International Conference on Machine Learning (ICML) , series =
Andrew Ilyas and Sung Min Park and Logan Engstrom and Guillaume Leclerc and Aleksander Madry , title =. Proceedings of the 39th International Conference on Machine Learning (ICML) , series =. 2022 , publisher =
2022
-
[30]
Advances in Neural Information Processing Systems , year =
Training Data Attribution via Approximate Unrolling , author =. Advances in Neural Information Processing Systems , year =
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Final-Model-Only Data Attribution with a Unifying View of Gradient-Based Methods , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[32]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Distributional Training Data Attribution: What do Influence Functions Sample? , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[34]
Journal of Machine Learning Research , volume =
Underspecification Presents Challenges for Credibility in Modern Machine Learning , author =. Journal of Machine Learning Research , volume =. 2022 , url =
2022
-
[35]
Advances in Neural Information Processing Systems , year =
Enhancing Training Data Attribution with Representational Optimization , author =. Advances in Neural Information Processing Systems , year =
-
[36]
ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year=
Source-Aware Training Enables Knowledge Attribution in Language Models , author=. ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year=
2024
-
[37]
International Conference on Learning Representations , year =
Cite Pretrain: Retrieval-Free Knowledge Attribution for Large Language Models , author =. International Conference on Learning Representations , year =
-
[38]
Proceedings of the 2021 IEEE Symposium on Security and Privacy , pages =
Machine Unlearning , author =. Proceedings of the 2021 IEEE Symposium on Security and Privacy , pages =. 2021 , publisher =
2021
-
[39]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , url =
2022
-
[40]
2026 , eprint =
Natively Unlearnable Large Language Models , author =. 2026 , eprint =
2026
-
[42]
2024 , eprint =
Gradient Routing: Masking Gradients to Localize Computation in Neural Networks , author =. 2024 , eprint =
2024
-
[44]
and Zettlemoyer, Luke , booktitle =
Gururangan, Suchin and Lewis, Mike and Holtzman, Ari and Smith, Noah A. and Zettlemoyer, Luke , booktitle =. 2022 , publisher =
2022
-
[45]
Alignment Without Retraining: Auditing and Controlling Steerling-8B , year =
-
[46]
AI Communications , volume =
Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches , author =. AI Communications , volume =
-
[47]
AAAI Conference on Artificial Intelligence (AAAI) , year =
Oscar Li and Hao Liu and Chaofan Chen and Cynthia Rudin , title =. AAAI Conference on Artificial Intelligence (AAAI) , year =
-
[48]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Meike Nauta and Ron van Bree and Christin Seifert , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[49]
Interpretable Image Classification with Differentiable Prototypes Assignment (ProtoPool) , booktitle =
Dawid Rymarczyk and. Interpretable Image Classification with Differentiable Prototypes Assignment (ProtoPool) , booktitle =. 2022 , url =
2022
-
[50]
ProtoPShare: Prototypical Parts Sharing for Similarity Discovery in Interpretable Image Classification , booktitle =
Dawid Rymarczyk and. ProtoPShare: Prototypical Parts Sharing for Similarity Discovery in Interpretable Image Classification , booktitle =. 2021 , doi =
2021
-
[51]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Jon Donnelly and Alina Jade Barnett and Chaofan Chen , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[52]
Su , title =
Chaofan Chen and Oscar Li and Daniel Tao and Alina Barnett and Cynthia Rudin and Jonathan K. Su , title =. Advances in Neural Information Processing Systems , volume =. 2019 , url =
2019
-
[53]
Arik and Tomas Pfister , title =
Sercan O. Arik and Tomas Pfister , title =. Journal of Machine Learning Research , volume =. 2020 , url =
2020
-
[54]
Advances in Neural Information Processing Systems , volume =
Visual Correspondence-Based Explanations Improve AI Robustness and Human-AI Team Accuracy , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[56]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Evaluation and Improvement of Interpretability for Self-Explainable Part-Prototype Networks , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2023 , url =
2023
-
[57]
Scientific Reports , volume =
On the Interpretability of Part-Prototype Based Classifiers: A Human Centric Analysis , author =. Scientific Reports , volume =. 2023 , doi =
2023
-
[58]
Nature Machine Intelligence , volume =
Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead , author =. Nature Machine Intelligence , volume =
-
[60]
Proceedings of the 41st International Conference on Machine Learning , series =
Cynthia Rudin and Chudi Zhong and Lesia Semenova and Margo Seltzer and Ronald Parr and Jiachang Liu and Srikar Katta and Jon Donnelly and Harry Chen and Zachery Boner , title =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[61]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Jon Donnelly and Zhicheng Guo and Alina Jade Barnett and Hayden McTavish and Chaofan Chen and Cynthia Rudin , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2025 , url =
2025
-
[62]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = may, year =
Das, Anubrata and Gupta, Chitrank and Kovatchev, Venelin and Lease, Matthew and Li, Junyi Jessy , editor =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = may, year =
-
[63]
Journal of Machine Learning Research , volume =
Hong, Dat and Wang, Tong and Baek, Stephen , title =. Journal of Machine Learning Research , volume =. 2023 , url =
2023
-
[64]
Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =
Proto-lm: A Prototypical Network-Based Framework for Built-in Interpretability in Large Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =
2023
-
[65]
Forty-third International Conference on Machine Learning , year=
Prototype Transformer: Towards Language Model Architectures Interpretable by Design , author=. Forty-third International Conference on Machine Learning , year=
-
[66]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =
A Structural Probe for Finding Syntax in Word Representations , author =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2019 , publisher =
2019
-
[67]
International Conference on Learning Representations , year=
What do you learn from context? Probing for sentence structure in contextualized word representations , author=. International Conference on Learning Representations , year=
-
[68]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting Latent Predictions from Transformers with the Tuned Lens , author =. arXiv preprint arXiv:2303.08112 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
2020 , month = aug, url =
nostalgebraist , title =. 2020 , month = aug, url =
2020
-
[70]
Trenton Bricken and Adly Templeton and Joshua Batson and Brian Chen and Adam Jermyn and Tom Conerly and Nicholas L. Turner and Cem Anil and Carson Denison and Amanda Askell and Robert Lasenby and Yifan Wu and Shauna Kravec and Nicholas Schiefer and Tim Maxwell and Nicholas Joseph and Alex Tamkin and Karina Nguyen and Brayden McLean and Josiah E. Burke and...
2023
-
[71]
Toy Models of Superposition , journal =
Nelson Elhage and Tristan Hume and Catherine Olsson and Nicholas Schiefer and Tom Henighan and Shauna Kravec and Zac Hatfield. Toy Models of Superposition , journal =. 2022 , url =
2022
-
[72]
International Conference on Learning Representations (ICLR) , year =
Hoagy Cunningham and Aidan Ewart and Logan Riggs Smith and Robert Huben and Lee Sharkey , title =. International Conference on Learning Representations (ICLR) , year =
-
[73]
The Thirteenth International Conference on Learning Representations , year=
Scaling and evaluating sparse autoencoders , author=. The Thirteenth International Conference on Learning Representations , year=
-
[74]
International Conference on Learning Representations (ICLR) , year =
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[75]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[76]
and Kowal, Matthew and Boutin, Victor and Papadimitriou, Isabel and Wang, Binxu and Wattenberg, Martin and Ba, Demba E
Fel, Thomas and Lubana, Ekdeep Singh and Prince, Jacob S. and Kowal, Matthew and Boutin, Victor and Papadimitriou, Isabel and Wang, Binxu and Wattenberg, Martin and Ba, Demba E. and Konkle, Talia , booktitle =. Archetypal. 2025 , publisher =
2025
-
[77]
Olshausen and David J
Bruno A. Olshausen and David J. Field , title =. Vision Research , volume =. 1997 , doi =
1997
-
[78]
IEEE Transactions on Signal Processing , volume =
Michal Aharon and Michael Elad and Alfred Bruckstein , title =. IEEE Transactions on Signal Processing , volume =. 2006 , doi =
2006
-
[79]
Advances in Neural Information Processing Systems , volume =
van den Oord, Aaron and Vinyals, Oriol and Kavukcuoglu, Koray , title =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[80]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Esser, Patrick and Rombach, Robin and Ommer, Bjorn , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2021 , pages =
2021
-
[81]
Goodman , title =
Alex Tamkin and Mohammad Taufeeque and Noah D. Goodman , title =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , month =
2024
-
[82]
Proceedings of the 42nd International Conference on Machine Learning , series =
Automatically Interpreting Millions of Features in Large Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , publisher =
2025
-
[85]
Proceedings of the 41st International Conference on Machine Learning , pages =
A Multimodal Automated Interpretability Agent , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[86]
International Conference on Learning Representations (ICLR) , year =
Urvashi Khandelwal and Omer Levy and Dan Jurafsky and Luke Zettlemoyer and Mike Lewis , title =. International Conference on Learning Representations (ICLR) , year =
-
[87]
Proceedings of the 37th International Conference on Machine Learning , pages =
Retrieval Augmented Language Model Pre-Training , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[88]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[89]
Proceedings of the 39th International Conference on Machine Learning , series =
Improving Language Models by Retrieving from Trillions of Tokens , author =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
2022
-
[90]
Infini-gram: Scaling Unbounded
Liu, Jiacheng and Min, Sewon and Zettlemoyer, Luke and Choi, Yejin and Hajishirzi, Hannaneh , booktitle =. Infini-gram: Scaling Unbounded. 2024 , url =
2024
-
[91]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Interpretable Next-token Prediction via the Generalized Induction Head , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.