Talking Politics with Artificial Intelligence
Pith reviewed 2026-07-02 03:20 UTC · model grok-4.3
The pith
AI conversations serve as practical intermediaries for political questions rather than open forums for expression, turning more opinionated only after major events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
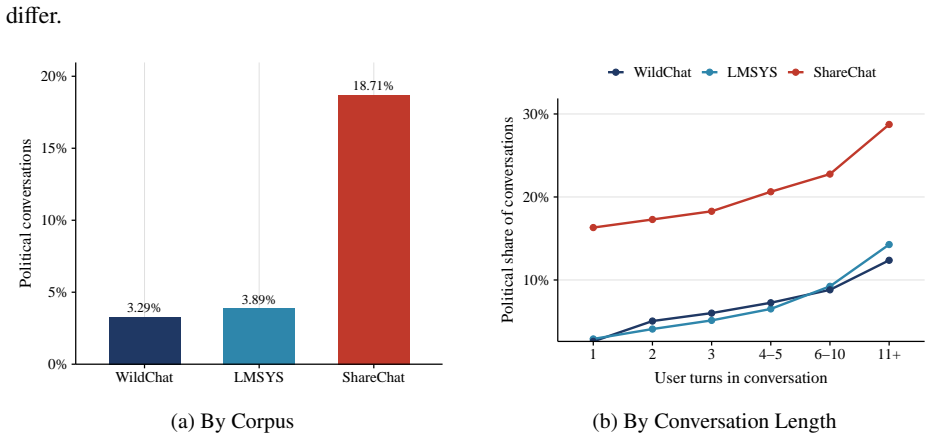
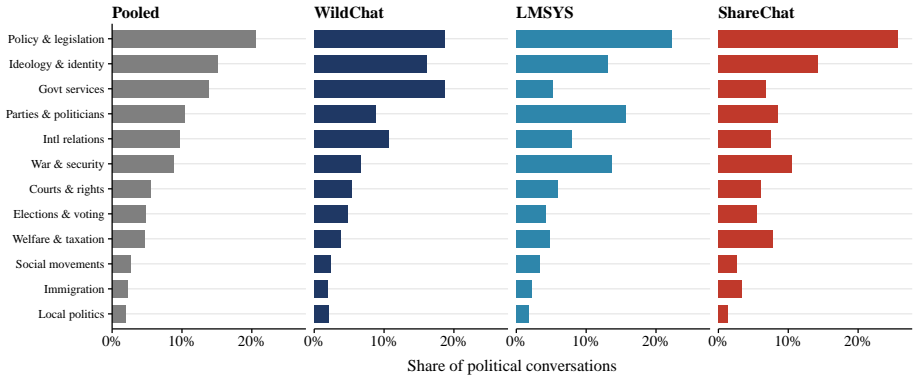
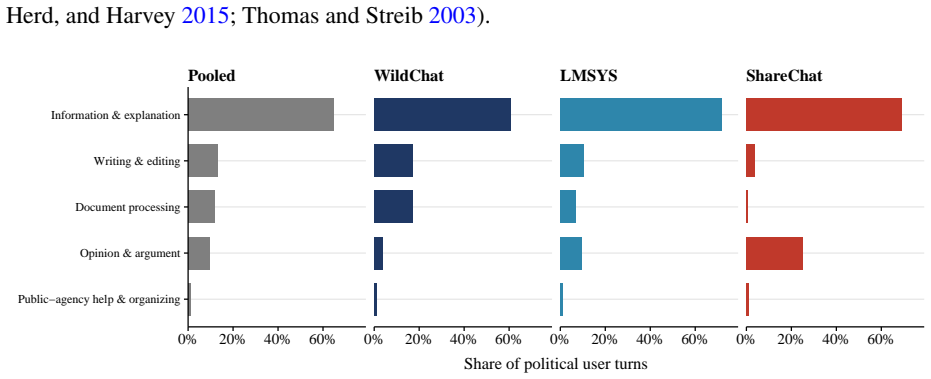
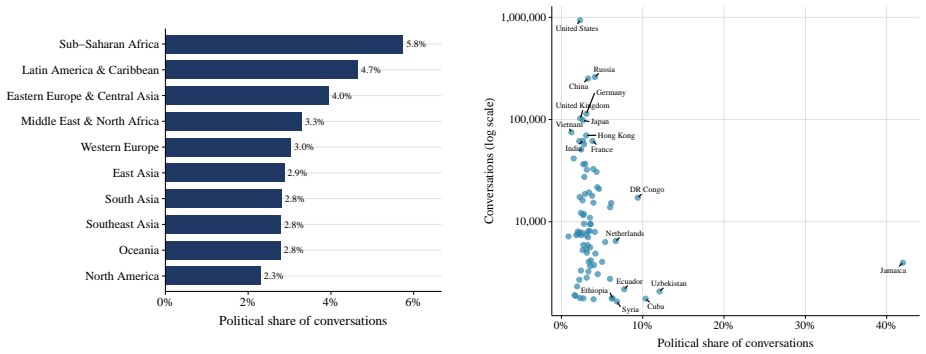
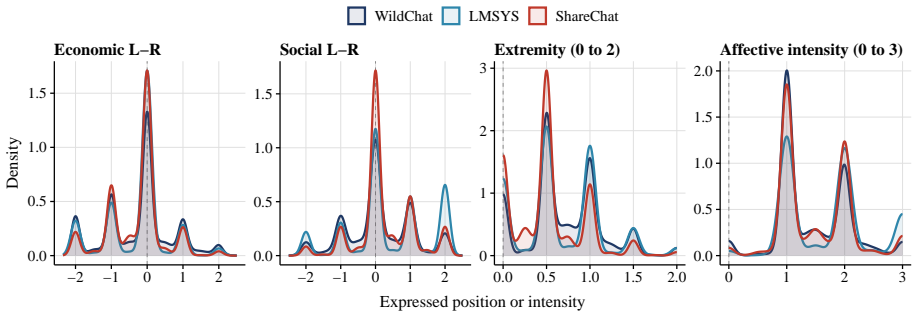
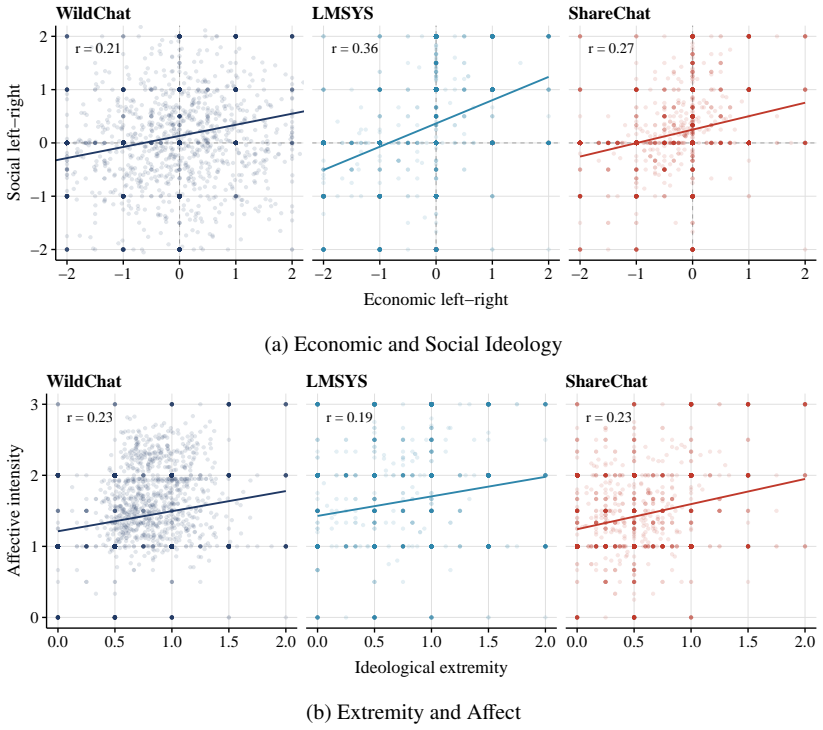
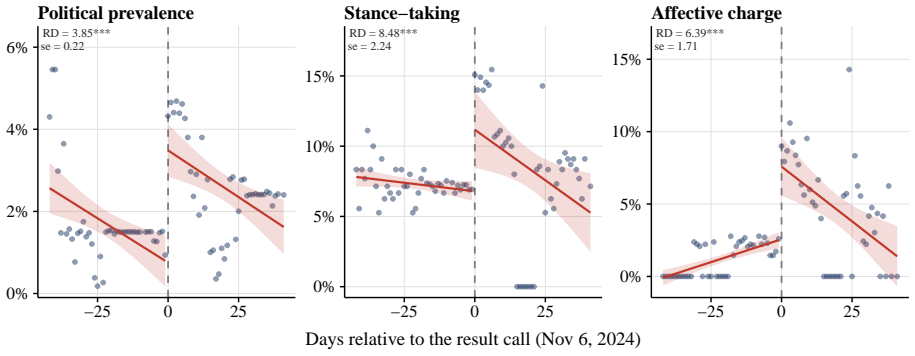
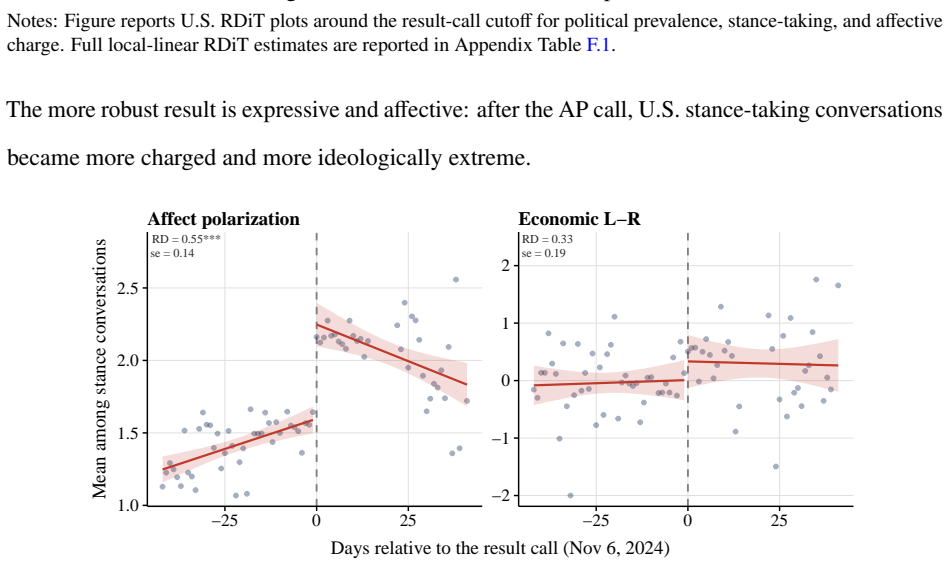
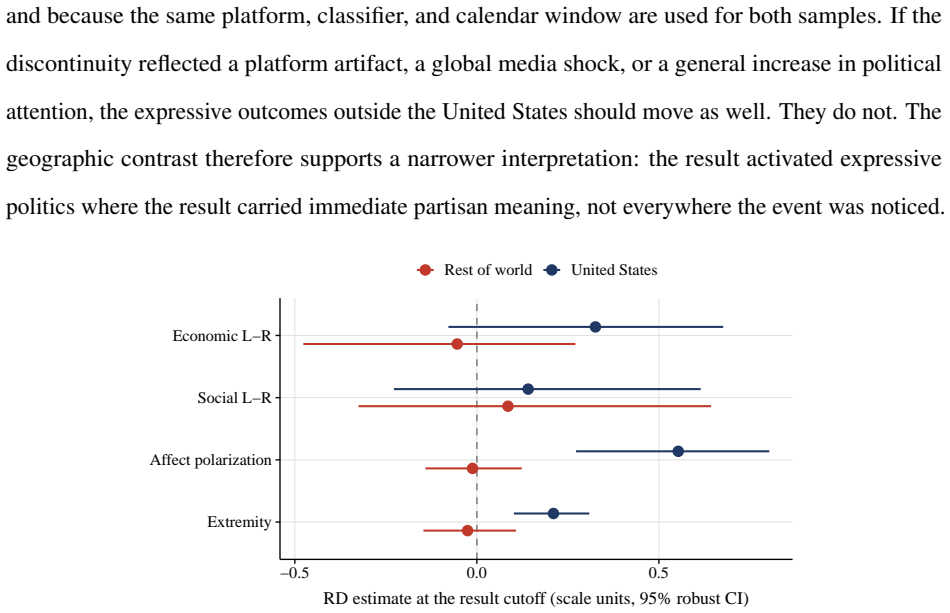
Using two validated classifiers on user messages from 4.30 million conversations, the paper identifies political content in 3.9 percent of exchanges, with most activity focused on information-seeking, text drafting, and document processing rather than opinion expression. The regression-discontinuity-in-time design around the 2024 U.S. presidential result call finds sharp rises in stance-taking, affective language, and ideological extremity among U.S. users post-call, with no parallel shift in non-U.S. conversations. The overall pattern leads to the claim that AI conversation functions less as a public square and more as a conversational political intermediary that absorbs routine demand and
What carries the argument
Two validated classifiers that tag political content, use case, and expressed ideology in user messages, combined with a regression-discontinuity-in-time design centered on the 2024 election result call.
If this is right
- Political content varies sharply by platform publicness and conversation depth.
- Users seek information, draft text, and process documents on political topics far more often than they state opinions.
- Major events such as election result calls increase stance-taking, affective language, and ideological extremity in affected users.
- AI conversation absorbs routine political demand and activates expressive features only when stakes become explicit.
Where Pith is reading between the lines
- The intermediary pattern could apply to other high-stakes triggers such as policy announcements or scandals, producing similar spikes in expressive language.
- Design choices on platforms might route routine queries differently from event-driven ones to match the observed split in behavior.
- If AI absorbs routine political talk, visible public discourse on social media may shrink relative to private or semi-private exchanges.
Load-bearing premise
The classifiers correctly tag political content, use cases, and ideologies across the datasets, and the time-discontinuity design isolates the election result call without interference from other events.
What would settle it
Reclassifying a fresh sample of conversations or documenting other simultaneous events around the 2024 result call that produce the same rise in expressive language among U.S. users would undermine the intermediary claim.
Figures
read the original abstract
Large language models (LLMs), a prominent form of artificial intelligence (AI), are becoming everyday interfaces for political questions, but most exchanges are dyadic rather than audiencefacing. This paper asks whether AI conversation functions as a new arena for political expression or as a conversational intermediary for routine political demand. Using 4.30 million humanAI conversations from three large public datasets, we apply two validated classifiers to user messages, identifying political content, use case, and expressed ideology. Political content appears in 3.9% of conversations, varies sharply by platform publicness and conversation depth, and is mostly practical: users ask for information, draft text, and process documents far more often than they state opinions. A regression-discontinuity-in-time design around the 2024 U.S. presidential result call shows that the call changed the expressive subset: among U.S. users, stance-taking, affective language, and ideological extremity rose; comparable conversations elsewhere did not. AI conversation is less a public square than a conversational political intermediary, absorbing routine demand and becoming expressive when major events make political stakes explicit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI conversations function primarily as a conversational intermediary absorbing routine political demand rather than as a public square for expression. Analyzing 4.3 million human-AI conversations across three public datasets, it reports that political content appears in only 3.9% of exchanges and is mostly practical (information requests, text drafting, document processing) rather than opinion-stating. Two validated classifiers identify political content, use case, and expressed ideology; a regression-discontinuity-in-time design around the 2024 U.S. presidential result call shows increases in stance-taking, affective language, and ideological extremity among U.S. users but not in comparable non-U.S. conversations.
Significance. If the measurement and identification strategies hold, the result offers a large-scale, falsifiable description of how LLMs mediate political talk, distinguishing routine practical use from event-triggered expressive use. This contributes to the literature on digital political behavior by providing quantitative evidence on the scale and triggers of political engagement with AI, with potential implications for platform design and democratic discourse studies.
major comments (2)
- [Abstract / Methods] Abstract and methods description: the claim that the two classifiers are 'validated' for identifying political content, practical vs. expressive use cases, and ideology across platforms and datasets provides no performance metrics (precision, recall, F1 by platform or depth), no inter-annotator agreement details, and no exclusion rules; these are load-bearing for the 3.9% prevalence figure and the subsequent use-case and ideology breakdowns.
- [Abstract / Results] Abstract and results description: the regression-discontinuity-in-time design around the 2024 result call reports no bandwidth choice, no placebo tests on pre-periods or non-U.S. samples, and no explicit checks ruling out contemporaneous confounders (e.g., media spikes); without these, the claim that the call isolated an increase in expressive language for U.S. users only cannot be fully assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our measurement strategies and identification approach. We will make revisions to provide the requested details on classifier validation and additional robustness checks for the regression-discontinuity design.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods description: the claim that the two classifiers are 'validated' for identifying political content, practical vs. expressive use cases, and ideology across platforms and datasets provides no performance metrics (precision, recall, F1 by platform or depth), no inter-annotator agreement details, and no exclusion rules; these are load-bearing for the 3.9% prevalence figure and the subsequent use-case and ideology breakdowns.
Authors: We agree that the absence of detailed performance metrics, inter-annotator agreement, and exclusion rules in the abstract and methods limits the ability to fully assess the classifiers. We will revise the manuscript to include these in a new methods subsection, reporting precision, recall, and F1 by platform and depth, inter-annotator agreement, and exclusion rules. This will support the prevalence and breakdown figures. revision: yes
-
Referee: [Abstract / Results] Abstract and results description: the regression-discontinuity-in-time design around the 2024 result call reports no bandwidth choice, no placebo tests on pre-periods or non-U.S. samples, and no explicit checks ruling out contemporaneous confounders (e.g., media spikes); without these, the claim that the call isolated an increase in expressive language for U.S. users only cannot be fully assessed.
Authors: We concur that the RD design would benefit from explicit reporting of bandwidth choice, placebo tests, and confounder checks. In the revision, we will detail the bandwidth selection, add placebo tests on pre-periods and non-U.S. samples, and include checks for media spikes using external data. These will be added to the results and appendix. revision: yes
Circularity Check
No circularity; empirical claims rest on external conversation data and RD-in-time identification
full rationale
The paper's derivation proceeds from 4.3 million external human-AI conversations, two validated classifiers applied to identify political content/use-case/ideology, and a regression-discontinuity-in-time design around the 2024 election result call. No equations, fitted parameters, or self-citations are described that reduce the central claim (AI as intermediary rather than public square) to the inputs by construction. The discontinuity isolates the event effect on U.S. users while showing no change elsewhere, providing independent empirical content. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic
https: //www.anthropic.com/research/economic-index-june-2026-report. Anthropic. 2026b.Anthropic Economic Index Report: Learning Curves.Anthropic. March 24,
2026
-
[2]
Bang, Yejin, Delong Chen, Nayeon Lee, and Pascale Fung
https://www.anthropic.com/research/economic-index-march-2026-report. Bang, Yejin, Delong Chen, Nayeon Lee, and Pascale Fung
2026
-
[3]
Measuring Political Bias in Large Language Models: What Is Said and How It Is Said
“Measuring Political Bias in Large Language Models: What Is Said and How It Is Said.” InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),11142– 11159. Bangkok, Thailand: Association for Computational Linguistics. https://aclanthology. org/2024.acl-long.600/. Bennett, W. Lance, and Shanto Iyengar
2024
-
[4]
“From Street-Level to System-Level Bureaucracies: How Information and Communication Technology Is Transforming Administrative Discretion and Constitutional Control.”Public Administration Review62 (2): 174–184. Burnham, Michael. 2024.Semantic Scaling: Bayesian Ideal Point Estimates with Large Language Models.ArXiv preprint. arXiv: 2405.02472[cs.CL]. https:...
-
[5]
Robust Nonparametric Confi- dence Intervals for Regression-Discontinuity Designs
“Robust Nonparametric Confi- dence Intervals for Regression-Discontinuity Designs.”Econometrica82 (6): 2295–2326. Cattaneo, Matias D., Nicolás Idrobo, and Rocío Titiunik. 2020.A Practical Introduction to Regres- sion Discontinuity Designs: Foundations.Cambridge: Cambridge University Press. Chadwick, Andrew. 2017.The Hybrid Media System: Politics and Power...
2020
-
[6]
How Susceptible Are Large Language Models to Ideological Manipulation?
“How Susceptible Are Large Language Models to Ideological Manipulation?” InProceedings of the 2024 Conference on 34 Empirical Methods in Natural Language Processing,17140–17161. Miami, Florida, USA: Association for Computational Linguistics. https://aclanthology.org/2024.emnlp-main.952/. Chong, Dennis, and James N. Druckman
2024
-
[7]
1996.What Americans Know about Politics and Why It Matters.New Haven, CT: Yale University Press
Delli Carpini, Michael X., and Scott Keeter. 1996.What Americans Know about Politics and Why It Matters.New Haven, CT: Yale University Press. Di Leo, Riccardo, Chen Zeng, Elias Dinas, and Reda Tamtam
1996
-
[8]
Regression Discontinuity in Time: Considerations for Empirical Applications
“Regression Discontinuity in Time: Considerations for Empirical Applications.”Annual Review of Resource Economics10:533–552. Herd, Pamela, and Donald P. Moynihan. 2018.Administrative Burden: Policymaking by Other Means.New York: Russell Sage Foundation. Heseltine, Michael, and Bernhard Clemm von Hohenberg
2018
-
[9]
Expressive Partisanship: Campaign Involvement, Political Emotion, and Partisan Identity
“Expressive Partisanship: Campaign Involvement, Political Emotion, and Partisan Identity.”American Political Science Review109 (1): 1–17. 35 Iyengar, Shanto, and Donald R. Kinder. 2010.News That Matters: Television and American Opinion. Updated. Chicago: University of Chicago Press. Iyengar, Shanto, Gaurav Sood, and Yphtach Lelkes
2010
-
[10]
The Two-Step Flow of Communication: An Up-To-Date Report on an Hypothe- sis
“The Two-Step Flow of Communication: An Up-To-Date Report on an Hypothe- sis.”Public Opinion Quarterly21 (1): 61–78. Katz, Elihu, and Paul F. Lazarsfeld. 1955.Personal Influence: The Part Played by People in the Flow of Mass Communications.Glencoe, IL: The Free Press. King, Gary, Jennifer Pan, and Margaret E. Roberts
1955
-
[11]
Persuading V oters Using Human– Artificial Intelligence Dialogues
“Persuading V oters Using Human– Artificial Intelligence Dialogues.”Nature648 (8093): 394–401. Lipka, Michael, and Kirsten Eddy. 2025.Relatively Few Americans Are Getting News from AI Chatbots like ChatGPT.Pew Research Center. Short Read, October 1,
2025
-
[12]
pewresearch.org/short-reads/2025/10/01/relatively-few-americans-are-getting-news-from- ai-chatbots-like-chatgpt/
https://www. pewresearch.org/short-reads/2025/10/01/relatively-few-americans-are-getting-news-from- ai-chatbots-like-chatgpt/. Lupia, Arthur, and Mathew D. McCubbins. 1998.The Democratic Dilemma: Can Citizens Learn What They Need to Know?New York: Cambridge University Press. Mansbridge, Jane
2025
-
[13]
The Agenda-Setting Function of Mass Media
“The Agenda-Setting Function of Mass Media.” Public Opinion Quarterly36 (2): 176–187. Meta. 2020.What Do People Actually See on Facebook in the US?Meta. Newsroom post, November 10, 2020; updated November 4,
2020
-
[14]
https://about.fb.com/news/2020/11/what-do-people- actually-see-on-facebook-in-the-us/. Meta. 2021.Reducing Political Content in Facebook Feed.Meta. Newsroom post, February 10,
2020
-
[15]
Mettler, Suzanne
https://about.fb.com/news/2021/02/reducing-political-content-in-news-feed/. Mettler, Suzanne. 2011.The Submerged State: How Invisible Government Policies Undermine American Democracy.Chicago: University of Chicago Press. Moynihan, Donald, Pamela Herd, and Hope Harvey
2021
-
[16]
Administrative Burden: Learning, Psychological, and Compliance Costs in Citizen-State Interactions
“Administrative Burden: Learning, Psychological, and Compliance Costs in Citizen-State Interactions.”Journal of Public Admin- istration Research and Theory25 (1): 43–69. Mutz, Diana C. 2006.Hearing the Other Side: Deliberative versus Participatory Democracy. Cambridge: Cambridge University Press. 36 O’Hagan, Sean, and Aaron Schein. 2023.Measurement in the...
-
[17]
How to Train Your Stochastic Parrot: Large Language Models for Political Texts
“How to Train Your Stochastic Parrot: Large Language Models for Political Texts.”Political Science Research and Methods 13 (2): 264–281. Page, Benjamin I., and Robert Y . Shapiro. 1992.The Rational Public: Fifty Years of Trends in Americans’ Policy Preferences.Chicago: University of Chicago Press. Pangakis, Nicholas, Samuel Wolken, and Neil Fasching. 2023...
-
[18]
Election Outcomes and Affective Polarization in the United States
“Election Outcomes and Affective Polarization in the United States.”Political Research Quarterly79 (2): 399–409. Popkin, Samuel L. 1994.The Reasoning Voter: Communication and Persuasion in Presidential Campaigns.2nd ed. Chicago: University of Chicago Press. Prior, Markus. 2007.Post-Broadcast Democracy: How Media Choice Increases Inequality in Political In...
1994
-
[19]
Roberts, Margaret E
https: //www.nature.com/articles/s41599-024-03609-x. Roberts, Margaret E. 2018.Censored: Distraction and Diversion Inside China’s Great Firewall. Princeton, NJ: Princeton University Press. Ross Arguedas, Amy
2018
-
[20]
Emerging Uses of AI Chatbots for News and What It Means for Journalism
“Emerging Uses of AI Chatbots for News and What It Means for Journalism.” InDigital News Report 2026.Oxford: Reuters Institute for the Study of Journalism, University of Oxford. https://reutersinstitute.politics.ox.ac.uk/digital-news-report/2026/ emerging-uses-ai-chatbots-news-and-what-it-means-journalism. Scheufele, Dietram A., and David Tewksbury
2026
-
[21]
Are LLMs (Really) Ideological? An IRT-Based Analysis and Alignment Tool for Perceived Socio- Economic Bias in LLMs
“Are LLMs (Really) Ideological? An IRT-Based Analysis and Alignment Tool for Perceived Socio- Economic Bias in LLMs.” InProceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM2),99–120. Vienna, Austria and virtual meeting: Association for Computa- tional Linguistics. https://aclanthology.org/2025.gem-1.9/. Wyatt, Robert O., Elihu Kat...
2025
-
[22]
ShareChat: A Dataset of Chatbot Conversations in the Wild
“Bridging the Spheres: Political and Personal Conversation in Public and Private Spaces.”Journal of Communication50 (1): 71–92. Yan, Yueru, Tuc Nguyen, Bo Su, Melissa Lieffers, and Thai Le. 2025.ShareChat: A Dataset of Chatbot Conversations in the Wild.ArXiv preprint. arXiv: 2512.17843 [cs.CL]. https: //arxiv.org/abs/2512.17843. Yang, Eddie
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
The Limits of AI for Authoritarian Control
“The Limits of AI for Authoritarian Control.” Early View,American Journal of Political Science. 37 Zaller, John R. 1992.The Nature and Origins of Mass Opinion.Cambridge: Cambridge University Press. Zhao, Wenting, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng
1992
-
[24]
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversa- tion Dataset
“LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversa- tion Dataset.” InThe Twelfth International Conference on Learning Representations.https: //openreview.net/forum?id=BOfDKxfwt0. 38 Supplemental information A Data and corpora SI-1 B Measurement procedure SI-2 C Example political conversations SI-5 D Additional descriptive diagnostics SI-5 E Ideology di...
2024
-
[25]
Users could access the service without registration or payment, choose a single-model interface, compare two randomly assigned anonymous models, or compare two chosen models; the dataset includes conversations from these interfaces after users accepted the site’s terms of use (Zheng et al. 2024). This makes the corpus useful for checking whether political...
2024
-
[26]
SI-7 Table D.2: External Benchmarks Source Coverage Reported usage benchmark Comparison to this study OpenAI,How People Use ChatGPT (Chatterji et al
Dashes mark metadata not released in the corpus: LMSYS has no usable timestamp or country field, and ShareChat has no country field. SI-7 Table D.2: External Benchmarks Source Coverage Reported usage benchmark Comparison to this study OpenAI,How People Use ChatGPT (Chatterji et al. 2025; OpenAI
2025
-
[27]
Practical guidance, seeking information, and writing together account for about 77–80% of conversations; 49% of messages are asking, 40% doing, and 11% expressing
Consumer ChatGPT messages on Free, Plus, and Pro plans, May 2024–June 2025, with usage trends through July 2025 About 700 million weekly users and 18 billion messages per week by July 2025; non-work messages exceeded 70% of consumer usage. Practical guidance, seeking information, and writing together account for about 77–80% of conversations; 49% of messa...
2024
-
[28]
Facebook Feed content around the 2020 election and later updates to political-content ranking Meta reported that political content made up about 6% of what U.S
U.S. Facebook Feed content around the 2020 election and later updates to political-content ranking Meta reported that political content made up about 6% of what U.S. users saw in Feed in 2020 and less than 3% in its later updated analysis. The 3.3–3.9% political-conversation rates in WildChat and LMSYS are in the same broad order as a major public social ...
2020
-
[29]
Stance−taking rate (pct.) 2024 2025 10 20 30 1.25 1.50 1.75 0.5 0.6 0.7 0.8 0.9 Monthly value WildChat ShareChat Figure E.1: Ideology Over Time Notes: Months are shown when they contain at least 500 conversations and 50 political conversations; affective intensity and extremity means require at least 20 stance-taking conversations. WildChat has usable tim...
2024
-
[30]
The increase is not concentrated in an election residual
The figure is descriptive, but it is useful because it shows where the post-call non-election stance conversations appear. The increase is not concentrated in an election residual. It is distributed across policy, ideol- ogy and identity, welfare and taxation, government services, parties and politicians, immigration, and foreign affairs, consistent with ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.