ShareChat: A Dataset of Chatbot Conversations in the Wild
Pith reviewed 2026-05-21 16:36 UTC · model grok-4.3
The pith
ShareChat collects 142k chatbot conversations from public shares while preserving each platform's native features like citations and thinking traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
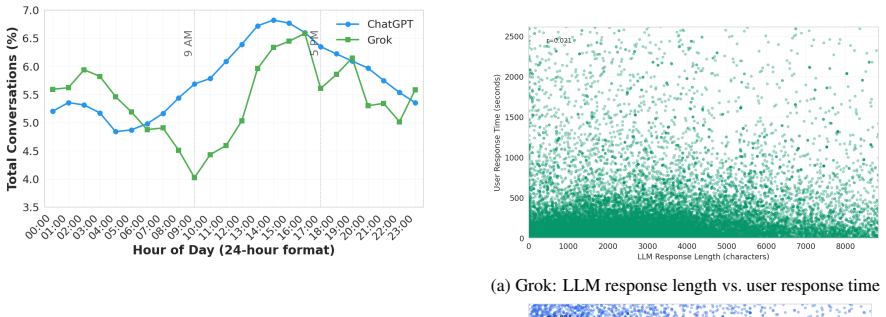
We present ShareChat, the first large-scale corpus of 142,808 conversations (660,293 turns) collected from publicly shared URLs on ChatGPT, Perplexity, Grok, Gemini, and Claude that preserves native platform affordances, including citations, thinking traces, and code artifacts, across 95 languages and the period from April 2023 to October 2025, complementing existing corpora that homogenize these interactions.
What carries the argument
Collection and extraction from publicly shared URLs on five major chatbot platforms while retaining native affordances such as citations, thinking traces, and code artifacts.
If this is right
- Cross-platform differences in how well conversations satisfy user intents can be measured directly.
- Citation strategies can be compared between search-augmented systems and others.
- Divergent response latency patterns can be tracked over time across platforms.
- Analyses requiring preserved platform elements become possible for the first time at this scale.
Where Pith is reading between the lines
- The dataset may over-represent successful or share-worthy interactions rather than average ones.
- Data spanning 95 languages could support studies of cultural differences in how users engage with AI.
- Ongoing collection would allow tracking of how user behavior changes as platforms update their designs.
- Platform developers could examine the data to identify which affordances most affect user satisfaction.
Load-bearing premise
Publicly shared URLs yield a representative sample of typical user interactions without major selection bias from what people choose to share.
What would settle it
A comparison finding that topics, lengths, or outcomes in ShareChat differ substantially from a random sample of private non-shared conversations on the same platforms.
Figures












read the original abstract
By evaluating Large Language Models (LLMs) through uniform, text-only interfaces, current academic benchmarks obscure how the unique designs and affordances of distinct commercial platforms shape real-world user behavior and system performance. To bridge this gap, we present ShareChat, the first large-scale corpus of 142,808 conversations (660,293 turns) collected from publicly shared URLs on ChatGPT, Perplexity, Grok, Gemini, and Claude. ShareChat preserves native platform affordances, including citations, thinking traces, and code artifacts, across 95 languages and the period from April 2023 to October 2025, complementing existing corpora that homogenize these interactions. To demonstrate the dataset's evaluative utility, we present three case studies: a conversation completeness analysis assessing cross-platform differences in intent satisfaction, a source grounding analysis comparing citation strategies between search-augmented systems, and a temporal analysis revealing divergent response latency dynamics. Together, these analyses demonstrate research questions that are inaccessible to single-platform or stripped-affordance corpora. The dataset is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ShareChat, a large-scale dataset of 142,808 conversations (660,293 turns) collected from publicly shared URLs on ChatGPT, Perplexity, Grok, Gemini, and Claude. It preserves native platform affordances including citations, thinking traces, and code artifacts across 95 languages from April 2023 to October 2025. The authors demonstrate evaluative utility via three case studies on cross-platform conversation completeness, source grounding in search-augmented systems, and temporal response latency dynamics.
Significance. If the collection process can be shown to yield a representative sample without material selection bias, the dataset would enable research on platform-specific LLM behaviors and affordances that homogenized text-only benchmarks cannot address. The public release, scale, and multilingual coverage constitute clear strengths for the field.
major comments (2)
- [Abstract] The abstract claims collection 'from publicly shared URLs' but supplies no details on URL discovery, scraping procedures, deduplication, or bias mitigation. This is load-bearing for the central claim of representativeness and for interpreting the three case studies as reflective of general platform usage rather than the sharing subpopulation.
- [Case Studies] No external anchor (e.g., comparison to platform telemetry, non-shared chat logs, or user surveys) is provided to quantify selection bias from voluntary public sharing. Without such validation, downstream analyses of completeness, grounding, and latency risk reflecting only shareable or positive outcomes.
minor comments (2)
- [Abstract] A per-platform and per-language breakdown of conversation counts would clarify balance and support claims of broad coverage.
- The time span ends in October 2025; confirm whether this reflects data collection up to manuscript submission or a projection.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight key areas for improving transparency and acknowledging limitations in our presentation of the ShareChat dataset. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract claims collection 'from publicly shared URLs' but supplies no details on URL discovery, scraping procedures, deduplication, or bias mitigation. This is load-bearing for the central claim of representativeness and for interpreting the three case studies as reflective of general platform usage rather than the sharing subpopulation.
Authors: We agree that the manuscript would benefit from greater detail on the collection process. In the revised version, we will expand the Methods section with a new subsection describing URL discovery (via public search indices and platform-native sharing mechanisms), scraping procedures (including ethical rate-limiting and compliance with platform terms), deduplication (using conversation IDs and content similarity thresholds), and bias mitigation steps (such as checks for language and temporal distribution). These additions will allow readers to better evaluate the dataset's scope and the interpretability of the case studies. revision: yes
-
Referee: [Case Studies] No external anchor (e.g., comparison to platform telemetry, non-shared chat logs, or user surveys) is provided to quantify selection bias from voluntary public sharing. Without such validation, downstream analyses of completeness, grounding, and latency risk reflecting only shareable or positive outcomes.
Authors: We acknowledge this limitation. As external researchers, we lack access to proprietary platform telemetry or non-shared logs, precluding direct quantitative anchors. We will add a dedicated Limitations subsection that explicitly discusses voluntary sharing bias, notes that shared conversations may skew toward shareable or positive outcomes, and frames the case studies as illustrative demonstrations of the dataset's research utility rather than claims of broad representativeness. The text will be revised to avoid overgeneralization while preserving the value of cross-platform analyses. revision: partial
- Direct quantitative validation of selection bias via platform telemetry or non-shared chat logs, which remains inaccessible to independent researchers.
Circularity Check
No circularity: dataset paper with descriptive case studies only
full rationale
The paper collects public chatbot conversation URLs and presents the resulting corpus along with three descriptive case studies on completeness, grounding, and latency. No derivations, equations, predictions, parameter fittings, or first-principles results are claimed. The central contribution is the existence and availability of the collected data itself, which is supported by direct description of the collection process rather than any self-referential logic, self-citation chains, or fitted inputs renamed as outputs. All analyses remain observational and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Publicly shared URLs constitute a valid and representative sample of real-world chatbot usage.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present ShareChat, the first large-scale corpus of 142,808 conversations ... collected from publicly shared URLs on ChatGPT, Perplexity, Grok, Gemini, and Claude that preserves native platform affordances, including citations, thinking traces, and code artifacts
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Selection Bias. First, the reliance on publicly shared URLs introduces ... Self-Selection Bias ... the corpus is likely skewed towards interactions they deem successful, interesting, or novel.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
NanoCP: Request-Level Dynamic Context Parallelism for Data-Expert Parallel Decoding
NanoCP introduces request-level dynamic context parallelism to decouple MoE communication from KV cache placement in hybrid data-expert parallel serving, reporting up to 3.27x higher request rates and 2.12x lower P99 ...
-
Opal: Private Memory for Personal AI
Opal enables private long-term memory for personal AI by decoupling reasoning to a trusted enclave with a lightweight knowledge graph and piggybacking reindexing on ORAM accesses.
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Technical report, Anthropic. Model card. Anthropic. 2024. The claude 3 model family: Opus, sonnet, haiku. https://www.anthropic.com/cl aude-3-model-card. Model card. Anthropic. 2025. System card: Claude opus 4 & claude sonnet 4. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jacob Sanders, and 1 others. 2022. Training a helpful and harmless a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Infinity instruct: Scaling instruction selection and synthesis to enhance language models.arXiv preprint arXiv:2506.11116. Jim McCambridge, John Witton, and Diana R Elbourne
-
[3]
Journal of Clinical Epidemiology, 67(3):267–277
Systematic review of the hawthorne effect. Journal of Clinical Epidemiology, 67(3):267–277. OpenAI Research. 2025. Chatgpt usage and adoption patterns at work. Technical report, OpenAI. Techni- cal report. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, and 1 others. 2022. Training language models to follow instruction...
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. Wildchat: 1m chatgpt interaction logs in the wild.arXiv preprint arXiv:2405.01470. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric P Xing...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Identify Distinct Goals: Focus on information seeking, task requests, or problem-solving goals
-
[6]
Maintain Order: The first item in your list must correspond to the user's first real request, and so on
-
[7]
Ignore Noise: Skip purely social turns (e.g., "Hello", "Thank you", "Okay") unless they are the only message. You are an internal tool that classifies a message from a user to an AI chatbot, based on the context of the previous messages before it. Based on the last user message of this conversation transcript and taking into account the examples further b...
work page 2025
-
[8]
**Identify Distinct Goals:** Focus on information seeking, task requests, or problem-solving goals
-
[9]
**Maintain Order:** The first item in your list must correspond to the user's first real request, and so on
-
[10]
**Ignore Noise:** Skip purely social turns (e.g., "Hello", "Thank you", "Okay") unless they are the only message. ### OUTPUT FORMAT Respond with a raw JSON object enclosed strictly within <output> tags. The JSON must have exactly one field: "intentions" (a list of strings). ### EXAMPLE Input Turns: [ {"role": "user", "content": "Hi, I need help with Pytho...
-
[12]
Ensure the JSON is valid
-
[13]
End with the closing tag </output>. Prompt B: Conversation Completeness Labeling ### SYSTEM ROLE You are an expert Quality Assurance Evaluator for AI conversations. ### TASK Determine if the specific **User Intention** was satisfied by the LLM based on the conversation history. ### CRITERIA - **Verdict: "yes"** if:
-
[14]
The LLM provided the correct information, code, or creative output requested
- [15]
-
[16]
The interaction reached a logical conclusion where the goal was met. - **Verdict: "partial"** if:
-
[17]
The LLM started addressing the request but the conversation ended before completion
-
[18]
The LLM provided some relevant information but missed key aspects of the request
-
[19]
The LLM gave a partial solution that requires additional steps the user would need to complete
-
[20]
The user asked follow-up questions indicating partial understanding/satisfaction. - **Verdict: "no"** if:
-
[21]
The LLM refused the request (unless it was a safety violation)
-
[22]
The LLM completely misunderstood the request or provided irrelevant information
-
[23]
The user expressed frustration or repeatedly asked the same thing without progress
-
[24]
The LLM asked for clarification but the conversation ended before any attempt to help. ### OUTPUT FORMAT Respond with a raw JSON object enclosed strictly within <output> tags. The JSON must have these fields: - "intention": (repeat the intention text) - "verdict": (value must be "yes", "partial", or "no") ### EXAMPLE Intention: "User wants to learn about ...
-
[25]
Start your response with the opening tag <output>
-
[26]
Ensure the JSON is valid. (a) Grok (b) Perplexity Figure 12: Distribution of source citations per conversa- tion for Grok and Perplexity. Extreme tails are omitted for visual clarity; the maximum observed source count is 83 for Grok and 1,059 for Perplexity
-
[27]
End with the closing tag </output>. A.7 Additional Source Grounding Analysis To understand the retrieval intensity of search- enabled platforms, we analyze the distribution of source counts per conversation. Figure 12 shows that Grok typically uses very few sources per con- versation, whereas Perplexity exhibits a long-tailed distribution in which many co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.