Dual-Confidence Contrastive Decoding for Retrieval-Augmented Generation
Pith reviewed 2026-07-02 13:20 UTC · model grok-4.3
The pith
Dual-confidence signals let contrastive decoding resolve conflicts among multiple retrieved documents in RAG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
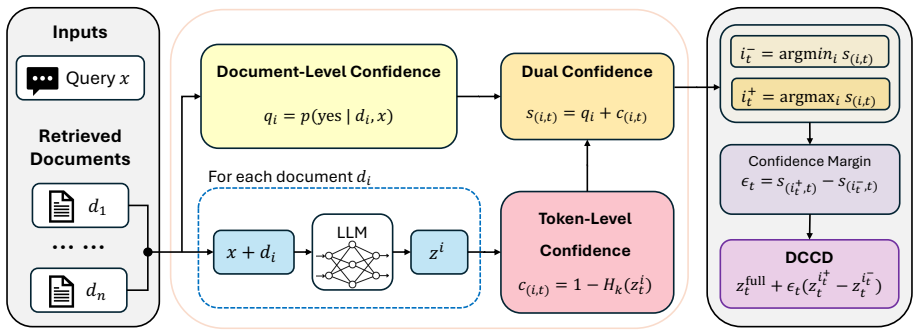
DCCD combines document-level confidence, which estimates whether a document appears sufficient for answering the question, with token-level confidence, which estimates whether that document supports a confident next-token prediction. DCCD selects positive and negative document-conditioned streams using these dual-confidence signals and scales a document-level contrast by their confidence margin.
What carries the argument
Dual document-level and token-level confidence scores that select streams and scale the contrast between them.
If this is right
- DCCD records the highest average performance among full-context and contrastive decoding baselines on both DRQA and standard multi-document QA tasks.
- The largest improvements appear on DRQA, the benchmark built around internally conflicting enterprise facts.
- Results indicate that source-aware, confidence-gated decoding is useful precisely when retrieved evidence contains internal contradictions.
Where Pith is reading between the lines
- The same dual signals could be applied to other generation settings where multiple passages must be reconciled, such as multi-source summarization.
- If the confidence estimates prove stable across model families, the approach could serve as a lightweight post-training intervention for existing RAG pipelines.
- Testing the method on documents with deliberately introduced partial overlaps would clarify how the two confidence levels interact when evidence is neither fully sufficient nor fully irrelevant.
Load-bearing premise
The proposed document-level score reliably indicates whether a document contains enough information to answer the question, and the token-level score reliably indicates support for a confident next-token prediction.
What would settle it
Run DCCD on a set of documents whose sufficiency for each question is known in advance by construction; if the confidence scores do not track actual answer accuracy better than uniform weighting, the method's premise does not hold.
Figures
read the original abstract
Retrieval-augmented generation (RAG) increasingly requires models to answer questions from multiple retrieved documents, where only some sources are relevant and the retrieved bundle may contain stale, noisy, or conflicting evidence. Existing contrastive decoding methods primarily focus on resolving conflicts between the model's internal memory and the retrieved context. In contrast, we study the complementary problem of intra-context conflict in multi-document RAG. To evaluate this setting, we introduce DRQA, a factual-conflict question answering benchmark derived from enterprise deep-research scenarios, where answers are grounded in synthetic enterprise-specific facts that are designed not to be recoverable from the model's internal memory. We further propose Dual-Confidence Contrastive Decoding (DCCD), a training-free decoding method that combines document-level confidence, which estimates whether a document appears sufficient for answering the question, with token-level confidence, which estimates whether that document supports a confident next-token prediction. DCCD selects positive and negative document-conditioned streams using these dual-confidence signals and scales a document-level contrast by their confidence margin. Across DRQA and standard multi-document QA benchmarks, DCCD achieves the best average performance among full-context and contrastive decoding baselines, with the largest gains on DRQA. These results highlight the importance of source-aware, confidence-gated decoding when retrieved evidence is internally conflicting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DRQA, a factual-conflict QA benchmark derived from enterprise scenarios with synthetic facts not recoverable from model memory, and proposes Dual-Confidence Contrastive Decoding (DCCD), a training-free method that combines document-level confidence (estimating document sufficiency for the question) with token-level confidence (estimating support for next-token prediction) to select positive/negative streams and scale document-level contrast. It claims DCCD achieves the best average performance among full-context and contrastive decoding baselines across DRQA and standard multi-document QA benchmarks, with largest gains on DRQA.
Significance. If the empirical claims hold after validation, the work is significant for addressing intra-context conflicts in multi-document RAG (complementary to model-context conflicts), introducing a useful new benchmark DRQA for evaluating such settings, and demonstrating a training-free, source-aware decoding approach. The emphasis on confidence-gated mechanisms for noisy or conflicting evidence is a practical contribution.
major comments (2)
- [Abstract / Method] Abstract / DCCD description: the central claim that document-level confidence reliably estimates whether a document is sufficient for answering the question (and token-level confidence indicates support for next-token prediction) is load-bearing for the intra-context conflict resolution argument, yet the provided description supplies no correlation analysis, ablation, or validation showing these estimators track the intended quantities rather than surface features such as length or lexical overlap.
- [Experiments] Experiments / Results: the claim of best average performance and largest gains on DRQA is presented without reported error bars, statistical significance tests, or ablation results on the dual-confidence components, making it impossible to assess whether gains are robust or driven by post-hoc choices.
minor comments (2)
- [Method] The description of how the confidence margin scales the contrast could be formalized with an equation for reproducibility.
- [Method] Clarify the exact form of the document-level and token-level confidence estimators (e.g., via pseudocode or explicit formulas) to aid implementation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important gaps in validation and statistical rigor that we will address through targeted revisions. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract / DCCD description: the central claim that document-level confidence reliably estimates whether a document is sufficient for answering the question (and token-level confidence indicates support for next-token prediction) is load-bearing for the intra-context conflict resolution argument, yet the provided description supplies no correlation analysis, ablation, or validation showing these estimators track the intended quantities rather than surface features such as length or lexical overlap.
Authors: We agree that explicit validation of the confidence estimators is necessary to substantiate the core claims. The current manuscript motivates the estimators from prior work on confidence scoring but does not include correlation studies or controlled ablations against length/overlap. In the revision we will add: (1) Pearson/Spearman correlations between document-level confidence and human-annotated sufficiency labels on a held-out subset of DRQA; (2) token-level confidence correlations with next-token prediction accuracy on positive vs. negative streams; and (3) length-controlled ablations that fix lexical overlap while varying sufficiency. These additions will directly test whether the signals capture the intended properties. revision: yes
-
Referee: [Experiments] Experiments / Results: the claim of best average performance and largest gains on DRQA is presented without reported error bars, statistical significance tests, or ablation results on the dual-confidence components, making it impossible to assess whether gains are robust or driven by post-hoc choices.
Authors: We acknowledge the absence of error bars, significance testing, and component ablations weakens the empirical claims. The revision will include: (1) mean and standard deviation across 5 random seeds for all methods on DRQA and the standard benchmarks; (2) paired t-tests or Wilcoxon tests with p-values comparing DCCD to the strongest baselines; and (3) ablations that isolate document-level confidence, token-level confidence, and the margin scaling term, reporting performance deltas. These results will be added to the main results table and a new ablation subsection. revision: yes
Circularity Check
No circularity: new decoding procedure with independent empirical claims
full rationale
The paper proposes DCCD as a training-free algorithm that defines document-level and token-level confidence signals to select positive/negative streams and scale contrast; these definitions are presented as the method itself rather than derived from fitted parameters or prior self-citations. No load-bearing step reduces by construction to its inputs (no self-definitional loops, no fitted-input-called-prediction, no uniqueness theorems imported from the same authors). Performance claims on DRQA and other benchmarks are framed as empirical results, not as logical necessities following from the definitions. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Large Language Models: A Survey
Rich knowledge sources bring complex knowl- edge conflicts: Recalibrating models to reflect con- flicting evidence. InProceedings of the 2022 Con- ference on Empirical Methods in Natural Language Processing, pages 2292–2307, Abu Dhabi, United Arab Emirates. Association for Computational Lin- guistics. Prafulla Kumar Choubey, Xiangyu Peng, Shilpa Bha- gava...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 6835–6855, Suzhou, China
CoCoA: Confidence- and context-aware adap- tive decoding for resolving knowledge conflicts in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 6835–6855, Suzhou, China. Association for Computational Linguistics. Youna Kim, Hyuhng Joon Kim, Cheonbok Park, Choonghyun Park, Hyunsoo Cho, ...
2025
-
[3]
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettle- moyer, and Mike Lewis
Curran Associates, Inc. Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettle- moyer, and Mike Lewis. 2023. Contrastive decod- ing: Open-ended text generation as optimization. In Proceedings of the 61st Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 12286–12...
2023
-
[4]
Lee’s Mar- ket reduced food waste by 8% in Q2 2024, saving $1.2M
Neural machine translation of rare words with subword units. InProceedings of the 54th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Lin- guistics. Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Wen-tau Yih. 2024. Tru...
-
[5]
Be realistic email conversations that mention the answer naturally to the question,→
-
[6]
type": "email
Follow this exact format for each email: { "type": "email", "id": "email_001", "from": "sender@company.com", "from_name": "Sender Name", "to": ["recipient@company.com"], "cc": [], "subject": "Email Subject", "date": "{formatted_date}T09:00:00-05:00" "body": "Email body content...", "folder": "inbox", "read": false, "attachments": [] }
-
[7]
Have the persona as the sender or one of the recipients
-
[8]
Be approximately {word_limit} words in total across all emails,→
-
[9]
Use realistic names, email addresses, and subjects based on the topic,→
-
[10]
Use sequential email IDs
-
[11]
Use realistic recent dates
-
[12]
Use folders from: inbox, sent, drafts, spam, trash
-
[13]
I think” or “from what I understand
Mark some emails as read and some as unread Consider generating: - Emails between team members discussing the topic - Emails from management asking for specific information - Internal announcements or updates Wrap the email content in a JSONL code block. 13 Format Phrase pool; two sampled per misinformation document email Use casual hedging such as “I thi...
-
[14]
Be a discussion between reasonable users on the topic and mention,→ the answer to the question inherently
-
[15]
Contain realistic messages to teams/channels
-
[16]
Contain all necessary team, channel, and user settings before posts,→
-
[18]
Use realistic names for people, teams, and channels
-
[19]
Contain a version object at the beginning of the file
-
[20]
Order objects as: version, teams, channels, users, posts
-
[21]
Company Context: - {company_info_key_1}: {company_info_value_1} -
Include user credential information and team membership Consider generating: - Chats between customers/partners and support/sales/product teams,→ - Chats between team members - Chats between employees and management Wrap the chat content in a JSONL code block. Company Context: - {company_info_key_1}: {company_info_value_1} - ... Return only the complete c...
-
[22]
Use proper markdown headings
-
[23]
Be approximately {word_limit} words in total
-
[24]
Include at least one table with relevant data
-
[25]
Use proper markdown formatting for lists, code blocks, blockquotes,,→ and links where appropriate
-
[26]
Use professional terminology and relevant examples
-
[27]
Use realistic names for people
-
[28]
Use a random name for the document author
-
[29]
Include a title and author at the beginning
-
[30]
verdict":
Never include file paths Company Context: - {company_info_key_1}: {company_info_value_1} - ... Return only the complete markdown content. A.3 LLM-as-Judge Verification Prompts Each generated misinformation, temporal, and noise document is independently checked by an LLM-as-judge using a fixed type-specific rubric. The judge returns structured JSON contain...
2000
-
[31]
Surface form does not matter if the meaning is equivalent
-
[32]
Numerical and date answers must match the reference at the level of detail provided
-
[33]
not specified
A refusal or "not specified" answer is incorrect unless the reference answer also says the information is unavailable
-
[34]
Extra context is acceptable only if the answer clearly commits to the correct value
-
[35]
correct": true_or_false,
If the answer gives a wrong primary value but mentions the correct value only incidentally, mark it incorrect. Return exactly one JSON object: {"correct": true_or_false, "reason": "<short reason>"} C.6 Hardware and Runtime All experiments can be run on a single NVIDIA H100 80GB GPU. Runtime depends on model size, dataset size, retrieval depth, and decodin...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.